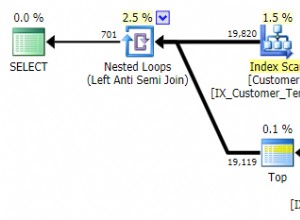
Vorausgesetzt mindestens Postgres 9.3.
Index
Zunächst hilft ein mehrspaltiger Index:
CREATE INDEX observations_special_idx
ON observations(station_id, created_at DESC, id)
created_at DESC passt etwas besser, aber ohne DESC würde der Index immer noch mit fast der gleichen Geschwindigkeit rückwärts gescannt werden .
Angenommen created_at ist NOT NULL definiert , ansonsten betrachten Sie DESC NULLS LAST im Index und Abfrage:
- PostgreSQL sortiert nach datetime asc, null zuerst?
Die letzte Spalte id ist nur nützlich, wenn Sie einen Nur-Index-Scan erhalten, was wahrscheinlich nicht funktioniert, wenn Sie ständig viele neue Zeilen hinzufügen. Entfernen Sie in diesem Fall id aus dem Index.
Einfachere Abfrage (immer noch langsam)
Vereinfachen Sie Ihre Abfrage, der innere Subselect hilft nicht:
SELECT id
FROM (
SELECT station_id, id, created_at
, row_number() OVER (PARTITION BY station_id
ORDER BY created_at DESC) AS rn
FROM observations
) s
WHERE rn <= #{n} -- your limit here
ORDER BY station_id, created_at DESC;
Sollte etwas schneller sein, aber immer noch langsam.
Schnelle Abfrage
- Angenommen, Sie haben relativ wenige Stationen und relativ viele Beobachtungen pro Station.
- Unter Annahme von
station_idid definiert alsNOT NULL.
wirklich zu sein schnell, benötigen Sie das Äquivalent eines losen Index-Scans (noch nicht in Postgres implementiert). Zugehörige Antwort:
- Optimieren Sie die GROUP BY-Abfrage, um den neuesten Datensatz pro Benutzer abzurufen
Wenn Sie eine separate Tabelle mit stations haben (was wahrscheinlich erscheint), können Sie dies mit JOIN LATERAL emulieren (Postgres 9.3+):
SELECT o.id
FROM stations s
CROSS JOIN LATERAL (
SELECT o.id
FROM observations o
WHERE o.station_id = s.station_id -- lateral reference
ORDER BY o.created_at DESC
LIMIT #{n} -- your limit here
) o
ORDER BY s.station_id, o.created_at DESC;
Wenn Sie keine Tabelle mit stations haben , das Nächstbeste wäre, eine zu erstellen und zu pflegen. Fügen Sie möglicherweise eine Fremdschlüsselreferenz hinzu, um die relationale Integrität zu erzwingen.
Wenn das keine Option ist, können Sie eine solche Tabelle im Handumdrehen destillieren. Einfache Optionen wären:
SELECT DISTINCT station_id FROM observations;
SELECT station_id FROM observations GROUP BY 1;
Aber beide würden einen sequentiellen Scan benötigen und langsam sein. Lassen Sie Postgres den obigen Index verwenden (oder einen beliebigen btree-Index mit station_id als führende Spalte) mit einem rekursiven CTE :
WITH RECURSIVE stations AS (
( -- extra pair of parentheses ...
SELECT station_id
FROM observations
ORDER BY station_id
LIMIT 1
) -- ... is required!
UNION ALL
SELECT (SELECT o.station_id
FROM observations o
WHERE o.station_id > s.station_id
ORDER BY o.station_id
LIMIT 1)
FROM stations s
WHERE s.station_id IS NOT NULL -- serves as break condition
)
SELECT station_id
FROM stations
WHERE station_id IS NOT NULL; -- remove dangling row with NULL
Verwenden Sie das als Drop-In-Ersatz für die stations Tabelle in der obigen einfachen Abfrage:
WITH RECURSIVE stations AS (
(
SELECT station_id
FROM observations
ORDER BY station_id
LIMIT 1
)
UNION ALL
SELECT (SELECT o.station_id
FROM observations o
WHERE o.station_id > s.station_id
ORDER BY o.station_id
LIMIT 1)
FROM stations s
WHERE s.station_id IS NOT NULL
)
SELECT o.id
FROM stations s
CROSS JOIN LATERAL (
SELECT o.id, o.created_at
FROM observations o
WHERE o.station_id = s.station_id
ORDER BY o.created_at DESC
LIMIT #{n} -- your limit here
) o
WHERE s.station_id IS NOT NULL
ORDER BY s.station_id, o.created_at DESC;
Dies sollte immer noch um Größenordnungen schneller sein als das, was Sie hatten .
SQL Fiddle here (9.6)
db<>fiddle here