Angenommen, Sie möchten alle Patienten finden, die noch nie gegen Grippe geimpft wurden. Oder in AdventureWorks2012 , könnte eine ähnliche Frage lauten:"Zeig mir alle Kunden, die noch nie eine Bestellung aufgegeben haben." Ausgedrückt mit NOT IN , ein Muster, das ich allzu oft sehe, das etwa so aussehen würde (ich verwende die vergrößerten Header- und Detailtabellen aus diesem Skript von Jonathan Kehayias (@SQLPoolBoy)):
SELECT CustomerID FROM Sales.Customer WHERE CustomerID NOT IN ( SELECT CustomerID FROM Sales.SalesOrderHeaderEnlarged );
Wenn ich dieses Muster sehe, zucke ich zusammen. Aber nicht aus Performance-Gründen – schließlich erstellt es in diesem Fall einen anständigen Plan:
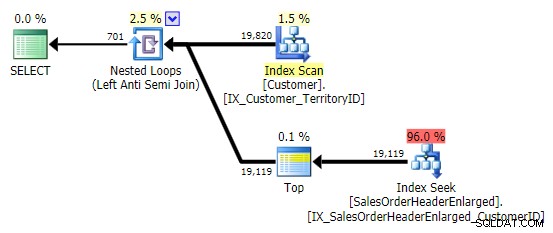
Das Hauptproblem besteht darin, dass die Ergebnisse überraschend sein können, wenn die Zielspalte NULL-fähig ist (SQL Server verarbeitet dies als Links-Anti-Semi-Join, kann Ihnen aber nicht zuverlässig sagen, ob eine NULL auf der rechten Seite gleich oder ungleich ist – die Referenz auf der linken Seite). Außerdem kann sich die Optimierung anders verhalten, wenn die Spalte NULL-fähig ist, selbst wenn sie eigentlich keine NULL-Werte enthält (Gail Shaw hat bereits 2010 darüber gesprochen).
In diesem Fall ist die Zielspalte nicht nullfähig, aber ich wollte diese potenziellen Probleme mit NOT IN erwähnen – Ich kann diese Probleme in einem zukünftigen Beitrag genauer untersuchen.
TL;DR-Version
Statt NOT IN , verwenden Sie einen korrelierten NOT EXISTS für dieses Abfragemuster. Stets. Andere Methoden können es in Bezug auf die Leistung aufnehmen, wenn alle anderen Variablen gleich sind, aber alle anderen Methoden führen entweder zu Leistungsproblemen oder anderen Herausforderungen.
Alternativen
Auf welche andere Weise können wir diese Abfrage also schreiben?
ÄUSSERE ANWENDUNG
Eine Möglichkeit, dieses Ergebnis auszudrücken, ist die Verwendung eines korrelierten OUTER APPLY .
SELECT c.CustomerID FROM Sales.Customer AS c OUTER APPLY ( SELECT CustomerID FROM Sales.SalesOrderHeaderEnlarged WHERE CustomerID = c.CustomerID ) AS h WHERE h.CustomerID IS NULL;
Logischerweise ist dies auch ein linker Anti-Semi-Join, aber dem resultierenden Plan fehlt der linke Anti-Semi-Join-Operator, und er scheint um einiges teurer zu sein als NOT IN gleichwertig. Dies liegt daran, dass es sich nicht mehr um einen linken Anti-Semi-Join handelt; es wird tatsächlich anders verarbeitet:ein äußerer Join bringt alle übereinstimmenden und nicht übereinstimmenden Zeilen ein, und *dann* wird ein Filter angewendet, um die Übereinstimmungen zu eliminieren:
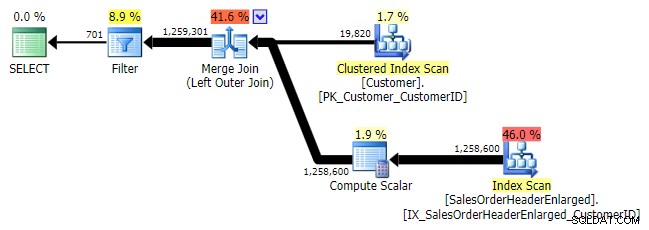
LEFT OUTER JOIN
Eine typischere Alternative ist LEFT OUTER JOIN wobei die rechte Seite NULL ist . In diesem Fall wäre die Abfrage:
SELECT c.CustomerID FROM Sales.Customer AS c LEFT OUTER JOIN Sales.SalesOrderHeaderEnlarged AS h ON c.CustomerID = h.CustomerID WHERE h.CustomerID IS NULL;
Dies gibt die gleichen Ergebnisse zurück; wie OUTER APPLY verwendet es jedoch die gleiche Technik, alle Zeilen zu verbinden und erst dann die Übereinstimmungen zu eliminieren:
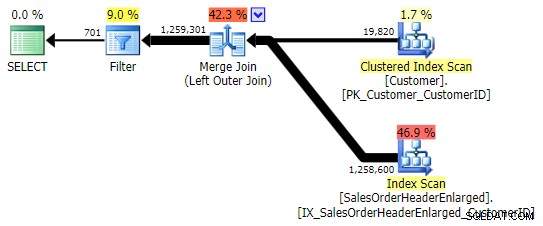
Sie müssen jedoch vorsichtig sein, welche Spalte Sie auf NULL prüfen . In diesem Fall Kundennummer ist die logische Wahl, weil es die Verbindungssäule ist; es ist auch indiziert. Ich hätte SalesOrderID auswählen können , das ist der Clusterschlüssel, also auch im Index von CustomerID . Aber ich hätte eine andere Spalte auswählen können, die sich nicht in dem für den Join verwendeten Index befindet (oder später daraus entfernt wird), was zu einem anderen Plan geführt hätte. Oder sogar eine NULL-fähige Spalte, was zu falschen (oder zumindest unerwarteten) Ergebnissen führt, da es keine Möglichkeit gibt, zwischen einer Zeile, die nicht existiert, und einer Zeile, die existiert, aber in der diese Spalte NULL . Und es ist für den Leser/Entwickler/Troubleshooter möglicherweise nicht offensichtlich, dass dies der Fall ist. Also werde ich auch diese drei WHERE testen Klauseln:
WHERE h.SalesOrderID IS NULL; -- clustered, so part of index WHERE h.SubTotal IS NULL; -- not nullable, not part of the index WHERE h.Comment IS NULL; -- nullable, not part of the index
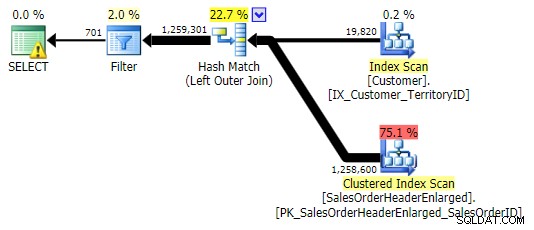
Die erste Variante erzeugt den gleichen Plan wie oben. Die anderen beiden wählen einen Hash-Join anstelle eines Merge-Joins und einen schmaleren Index im Customer Tabelle, obwohl die Abfrage am Ende genau die gleiche Anzahl von Seiten und Datenmengen ausliest. Während jedoch h.SubTotal Variation führt zu den richtigen Ergebnissen:
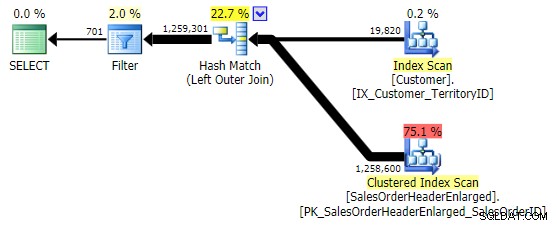
Der h.Kommentar Variation nicht, da sie alle Zeilen enthält, in denen h.Comment IS NULL ist , sowie alle Zeilen, die für keinen Kunden vorhanden waren. Ich habe den feinen Unterschied in der Anzahl der Zeilen in der Ausgabe hervorgehoben, nachdem der Filter angewendet wurde:
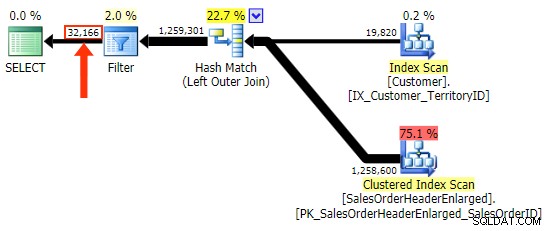
Abgesehen davon, dass ich bei der Spaltenauswahl im Filter vorsichtig sein muss, habe ich das andere Problem mit dem LEFT OUTER JOIN Form ist, dass es nicht selbstdokumentierend ist, genauso wie ein innerer Join in der "alten" Form von FROM dbo.table_a, dbo.table_b WHERE ... ist nicht selbstdokumentierend. Damit meine ich, dass es leicht ist, die Beitrittskriterien zu vergessen, wenn sie an WHERE gepusht werden Klausel oder damit es mit anderen Filterkriterien vermischt wird. Mir ist klar, dass dies ziemlich subjektiv ist, aber so ist es.
AUSSER
Wenn wir nur an der Join-Spalte interessiert sind (die sich per Definition in beiden Tabellen befindet), können wir EXCEPT verwenden – eine Alternative, die in diesen Gesprächen nicht oft aufzutauchen scheint (wahrscheinlich, weil Sie – normalerweise – die Abfrage erweitern müssen, um Spalten einzubeziehen, die Sie nicht vergleichen):
SELECT CustomerID FROM Sales.Customer AS c EXCEPT SELECT CustomerID FROM Sales.SalesOrderHeaderEnlarged;
Dies ergibt genau den gleichen Plan wie NOT IN Variante oben:
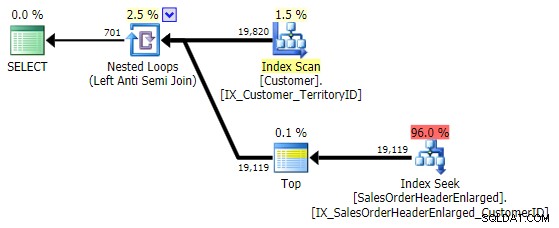
Beachten Sie Folgendes:EXCEPT enthält einen impliziten DISTINCT – Wenn Sie also Fälle haben, in denen Sie mehrere Zeilen mit demselben Wert in der "linken" Tabelle haben möchten, eliminiert dieses Formular diese Duplikate. In diesem speziellen Fall kein Problem, nur etwas, das man im Hinterkopf behalten sollte – genau wie UNION gegenüber UNION ALL .
EXISTIERT NICHT
Meine Vorliebe für dieses Muster ist definitiv NOT EXISTS :
SELECT CustomerID
FROM Sales.Customer AS c
WHERE NOT EXISTS
(
SELECT 1
FROM Sales.SalesOrderHeaderEnlarged
WHERE CustomerID = c.CustomerID
);
(Und ja, ich verwende SELECT 1 statt SELECT * … nicht aus Leistungsgründen, da es SQL Server egal ist, welche Spalte(n) Sie innerhalb von EXISTS verwenden und optimiert sie weg, sondern nur um die Absicht zu verdeutlichen:Dies erinnert mich daran, dass diese "Unterabfrage" eigentlich keine Daten zurückgibt.)
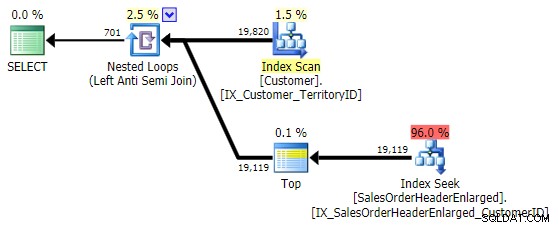
Seine Leistung ähnelt der von NOT IN und AUSSER , und es erstellt einen identischen Plan, ist aber nicht anfällig für potenzielle Probleme, die durch NULL-Werte oder Duplikate verursacht werden:
Leistungstests
Ich habe eine Vielzahl von Tests durchgeführt, sowohl mit einem kalten als auch mit einem warmen Cache, um zu bestätigen, dass meine langjährige Wahrnehmung von NICHT EXISTIERT die richtige Wahl zu sein, blieb wahr. Die typische Ausgabe sah so aus:
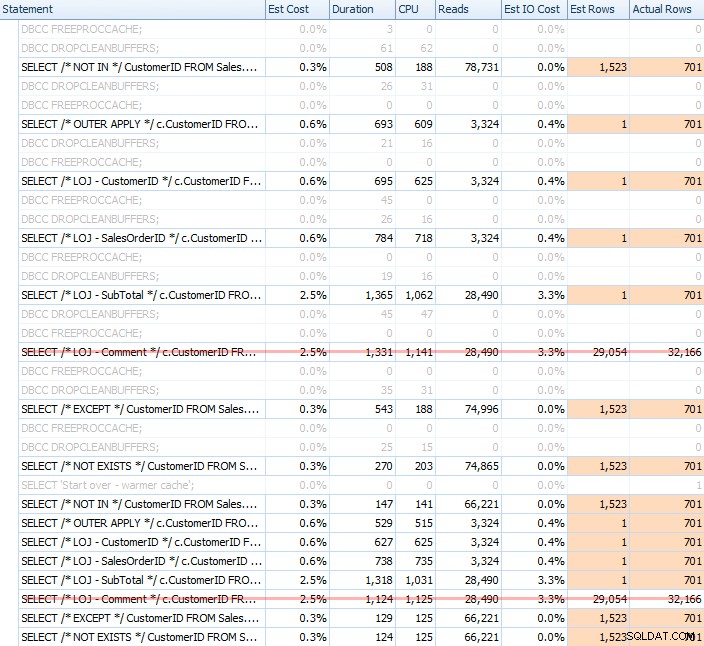
Ich nehme das falsche Ergebnis aus der Mischung heraus, wenn ich die durchschnittliche Leistung von 20 Läufen in einem Diagramm zeige (ich habe es nur eingefügt, um zu zeigen, wie falsch die Ergebnisse sind), und ich habe die Abfragen testübergreifend in unterschiedlicher Reihenfolge ausgeführt, um sicherzugehen dass eine Abfrage nicht konsequent von der Arbeit einer vorherigen Abfrage profitierte. Hier sind die Ergebnisse, die sich auf die Dauer konzentrieren:
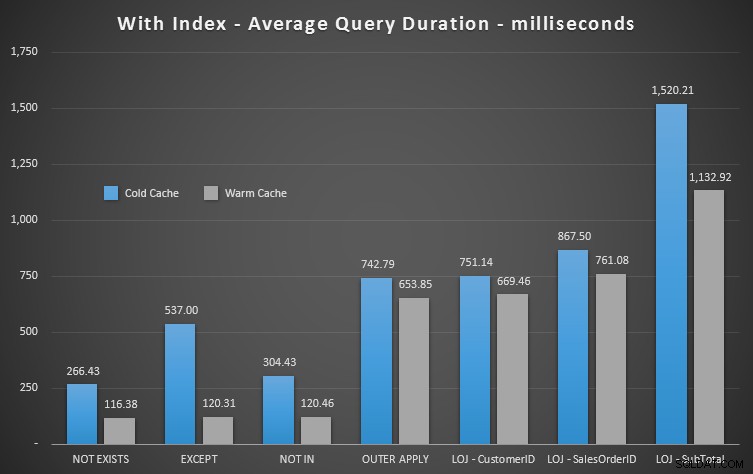
Wenn wir uns die Dauer ansehen und Reads ignorieren, ist NOT EXISTS Ihr Gewinner, aber nicht viel. EXCEPT und NOT IN sind nicht weit dahinter, aber auch hier müssen Sie mehr als nur die Leistung betrachten, um festzustellen, ob diese Optionen gültig sind, und in Ihrem Szenario testen.
Was ist, wenn es keinen unterstützenden Index gibt?
Die obigen Abfragen profitieren natürlich vom Index auf Sales.SalesOrderHeaderEnlarged.CustomerID . Wie ändern sich diese Ergebnisse, wenn wir diesen Index fallen lassen? Ich habe die gleichen Tests erneut ausgeführt, nachdem ich den Index gelöscht hatte:
DROP INDEX [IX_SalesOrderHeaderEnlarged_CustomerID] ON [Sales].[SalesOrderHeaderEnlarged];
Diesmal gab es viel weniger Abweichungen in Bezug auf die Leistung zwischen den verschiedenen Methoden. Zuerst zeige ich die Pläne für jede Methode (von denen die meisten, nicht überraschend, auf die Nützlichkeit des fehlenden Index hinweisen, den wir gerade gelöscht haben). Dann zeige ich ein neues Diagramm, das das Leistungsprofil sowohl mit einem kalten Cache als auch mit einem warmen Cache darstellt.
NOT IN, EXCEPT, NOT EXISTS (alle drei waren identisch)
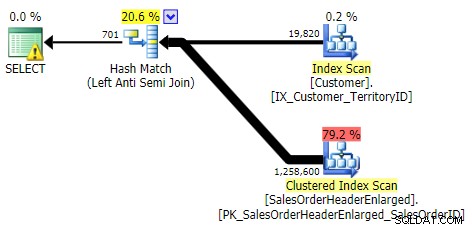
ÄUSSERE ANWENDUNG
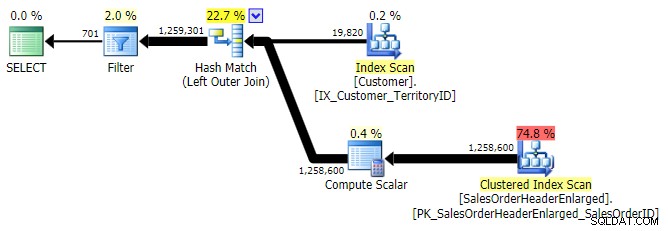
LEFT OUTER JOIN (alle drei waren bis auf die Zeilenanzahl identisch)
Leistungsergebnisse
Wir können sofort sehen, wie nützlich der Index ist, wenn wir uns diese neuen Ergebnisse ansehen. In allen außer einem Fall (dem linken äußeren Join, der sowieso außerhalb des Indexes liegt) sind die Ergebnisse deutlich schlechter, wenn wir den Index gelöscht haben:
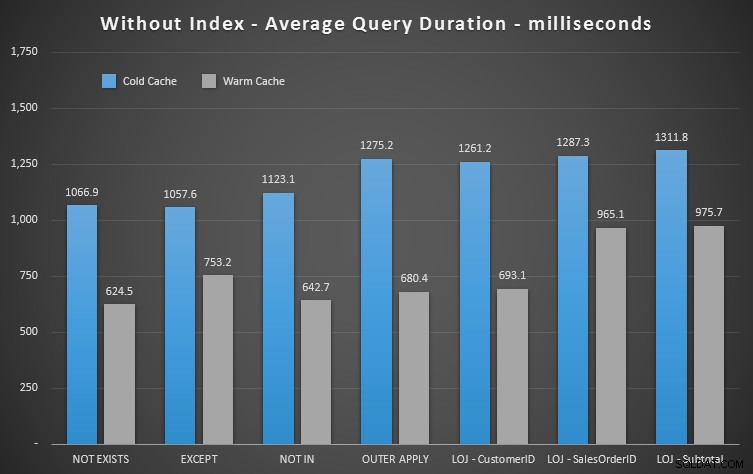
Wir können also sehen, dass NICHT VORHANDEN ist, obwohl es weniger spürbare Auswirkungen gibt ist immer noch Ihr knapper Gewinner in Bezug auf die Dauer. Und in Situationen, in denen die anderen Ansätze anfällig für Schema-Volatilität sind, ist dies auch die sicherste Wahl.
Schlussfolgerung
Das war nur eine wirklich langatmige Art, Ihnen zu sagen, dass für das Muster, alle Zeilen in Tabelle A zu finden, in denen eine Bedingung in Tabelle B nicht existiert, NOT EXISTS ist in der Regel die beste Wahl. Aber wie immer müssen Sie diese Muster in Ihrer eigenen Umgebung testen, indem Sie Ihr Schema, Ihre Daten und Ihre Hardware verwenden und mit Ihren eigenen Workloads mischen.