Im ersten Teil dieses Blogs haben wir einige wichtige Konzepte im Zusammenhang mit einer guten PostgreSQL-Replikationsumgebung erwähnt. Lassen Sie uns nun sehen, wie Sie all diese Dinge mit ClusterControl auf einfache Weise kombinieren können. Dazu gehen wir davon aus, dass Sie ClusterControl installiert haben, aber wenn nicht, können Sie auf die offizielle Website gehen oder sich auf die offizielle Dokumentation beziehen, um es zu installieren.
Bereitstellen der PostgreSQL-Streaming-Replikation
Um ein Deployment eines PostgreSQL-Clusters von ClusterControl aus durchzuführen, wählen Sie die Option Deploy und folgen Sie den angezeigten Anweisungen.
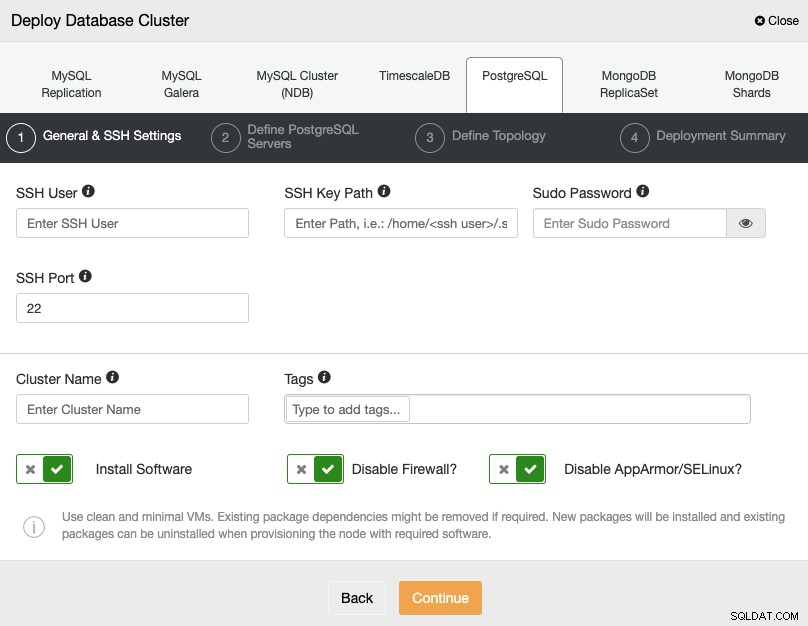
Bei der Auswahl von PostgreSQL müssen Sie den Benutzer, den Schlüssel oder das Passwort und angeben Port für die Verbindung per SSH mit Ihren Servern. Sie können Ihrem neuen Cluster auch einen Namen geben und angeben, ob ClusterControl die entsprechende Software und Konfigurationen für Sie installieren soll.
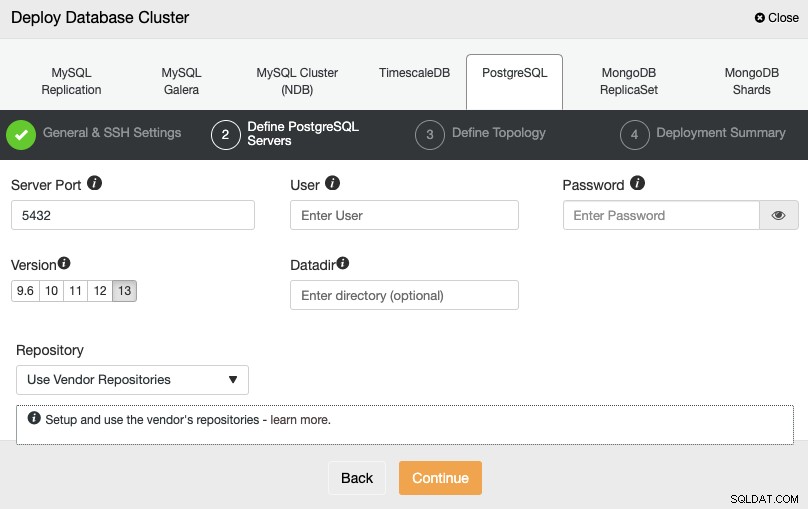
Nachdem Sie die SSH-Zugriffsinformationen eingerichtet haben, müssen Sie die Datenbankanmeldeinformationen definieren , Version und Datenverzeichnis (optional). Sie können auch angeben, welches Repository verwendet werden soll.
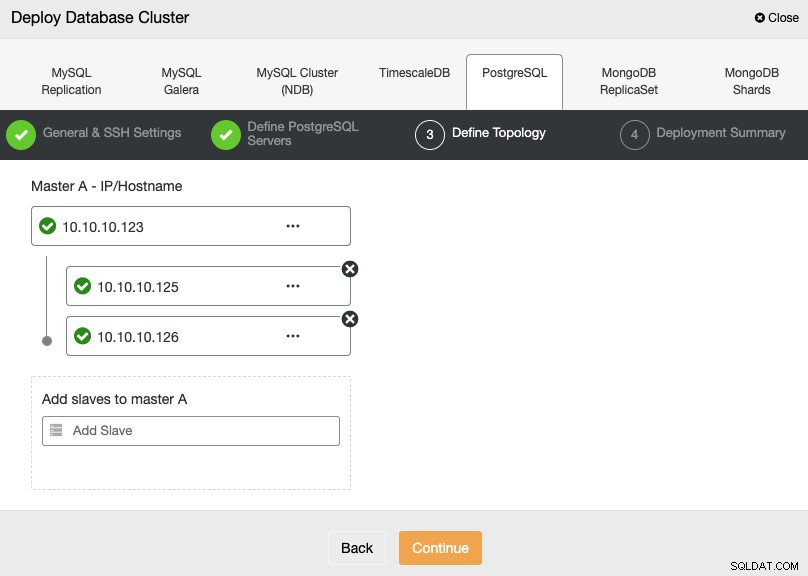
Im nächsten Schritt müssen Sie Ihre Server mithilfe der IP-Adresse oder des Hostnamens zu dem Cluster hinzufügen, den Sie erstellen werden.
Im letzten Schritt können Sie wählen, ob Ihre Replikation synchron oder Asynchron, und drücken Sie dann einfach auf Deploy.
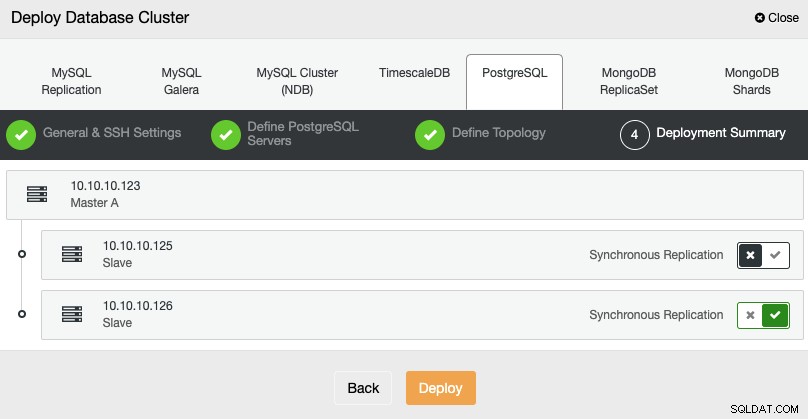
Sobald die Aufgabe abgeschlossen ist, sehen Sie Ihren neuen PostgreSQL-Cluster in der Hauptbildschirm von ClusterControl.

Jetzt haben Sie Ihren Cluster erstellt, Sie können verschiedene Aufgaben darauf ausführen, wie das Hinzufügen eines Load Balancers (HAProxy), eines Connection Poolers (PgBouncer) oder eines neuen synchronen oder asynchronen Replikations-Slaves.
Synchrone und asynchrone Replikations-Slaves hinzufügen
Gehen Sie zu ClusterControl -> Cluster-Aktionen -> Replikations-Slave hinzufügen.
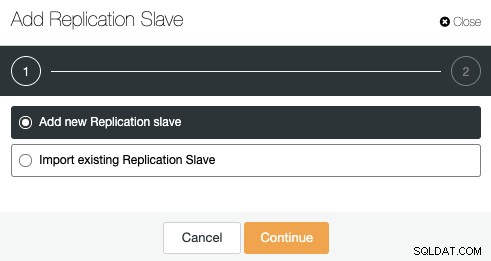
Sie können einen neuen Replikations-Slave hinzufügen oder sogar einen vorhandenen importieren. Lassen Sie uns die erste Option wählen und fortfahren.
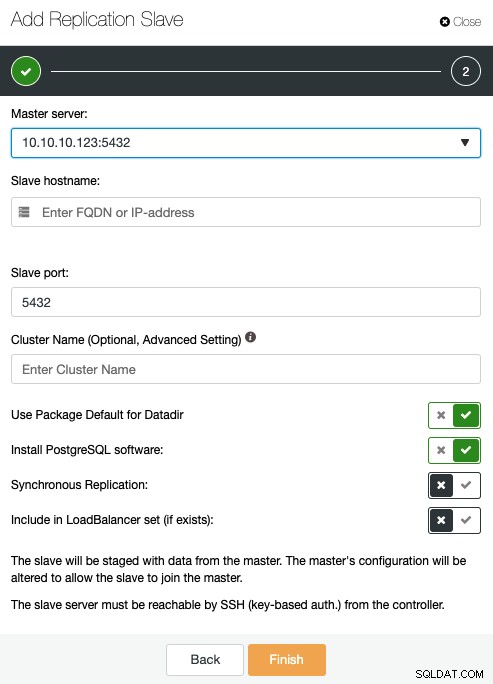
Hier müssen Sie den Master-Server, die IP-Adresse oder den Hostnamen angeben den neuen Replikations-Slave, Port, und wenn Sie ClusterControl installieren möchten, die Software installieren, oder diesen Knoten in einen bestehenden Load Balancer einbinden. Sie können die Replikation auch synchron oder asynchron konfigurieren.
Nun haben Sie Ihren PostgreSQL-Cluster mit den entsprechenden Replikaten eingerichtet. Lassen Sie uns sehen, wie Sie die Leistung verbessern können, indem Sie einen Verbindungspooler hinzufügen.
PgBouncer-Bereitstellung
Gehen Sie zu ClusterControl -> PostgreSQL-Cluster auswählen -> Cluster-Aktionen -> Load Balancer hinzufügen -> PgBouncer. Hier können Sie einen neuen PgBouncer-Knoten bereitstellen, der im ausgewählten Datenbankknoten bereitgestellt wird, oder sogar einen vorhandenen PgBouncer importieren.
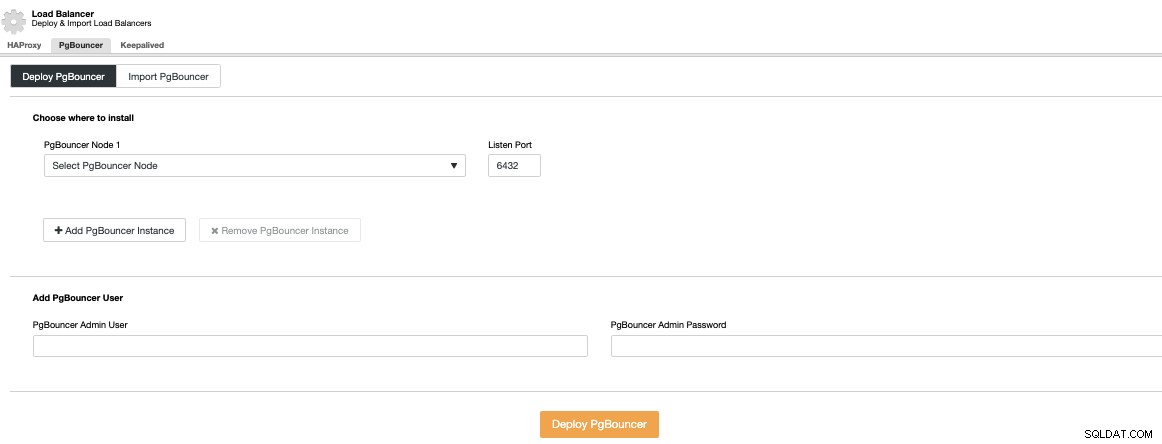
Sie müssen eine IP-Adresse oder einen Hostnamen, den Listen-Port und angeben PgBouncer-Anmeldeinformationen. Wenn Sie auf Deploy PgBouncer klicken, greift ClusterControl auf den Knoten zu, installiert und konfiguriert alles ohne manuellen Eingriff.
Sie können den Fortschritt im Aktivitätsbereich von ClusterControl überwachen. Wenn es fertig ist, müssen Sie den neuen Pool erstellen. Gehen Sie dazu zu ClusterControl -> Select the PostgreSQL Cluster -> Nodes -> PgBouncer node.
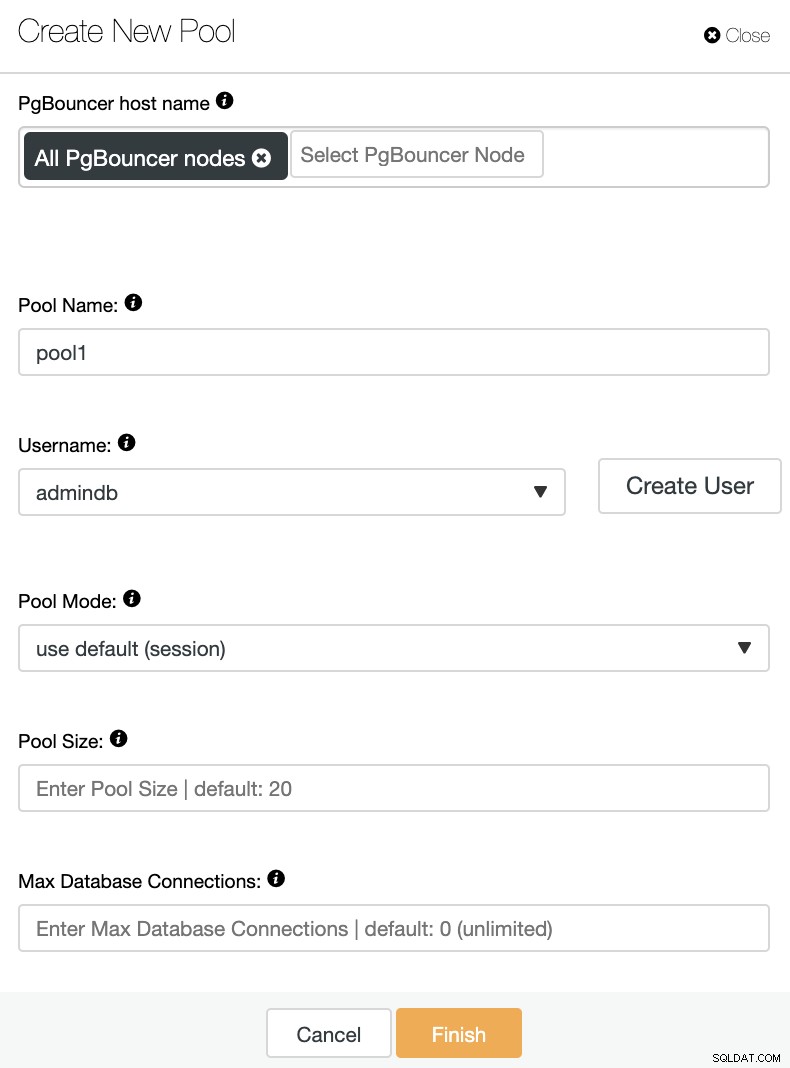
Sie müssen die folgenden Informationen hinzufügen:
-
PgBouncer-Hostname:Wählen Sie die Knotenhosts aus, um den Verbindungspool zu erstellen.
-
Poolname:Pool- und Datenbanknamen müssen identisch sein.
-
Benutzername: Wählen Sie einen Benutzer aus dem primären PostgreSQL-Knoten aus oder erstellen Sie einen neuen.
-
Pool-Modus:Dies kann sein:Sitzungs- (Standard), Transaktions- oder Statement-Pooling.
-
Pool-Größe:Maximale Größe der Pools für diese Datenbank. Der Standardwert ist 20.
-
Max Datenbankverbindungen:Konfigurieren Sie ein datenbankweites Maximum. Der Standardwert ist 0, was unbegrenzt bedeutet.
Nun sollten Sie den Pool im Node-Bereich sehen können.
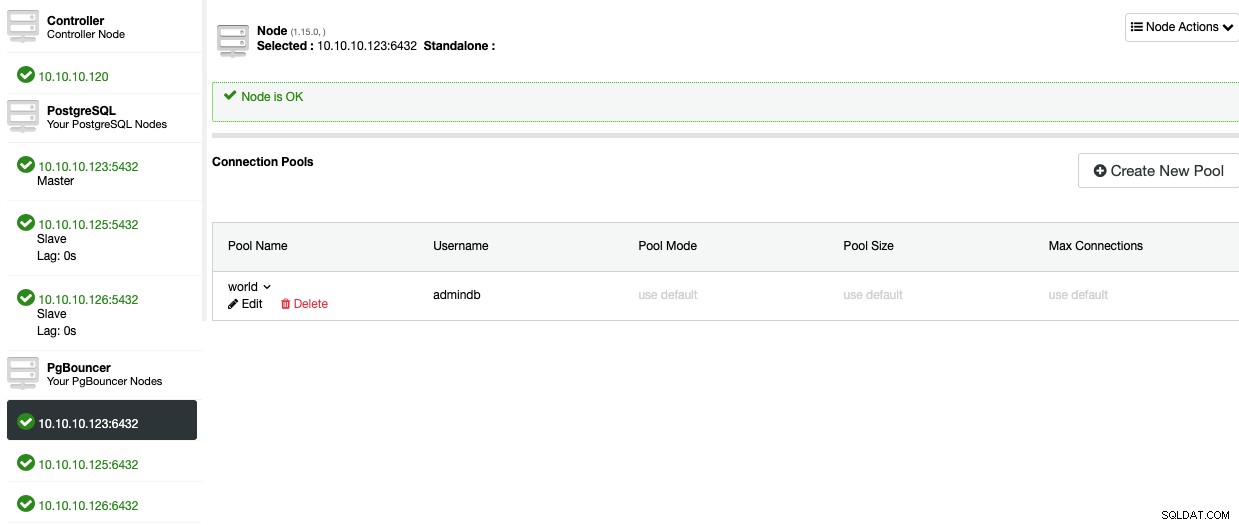
Um Hochverfügbarkeit zu Ihrer PostgreSQL-Datenbank hinzuzufügen, sehen wir uns an, wie man a Load-Balancer.
Load-Balancer-Bereitstellung
Um eine Load-Balancer-Bereitstellung durchzuführen, wählen Sie die Option „Load-Balancer hinzufügen“ im Menü „Cluster-Aktionen“ und vervollständigen Sie die angeforderten Informationen.
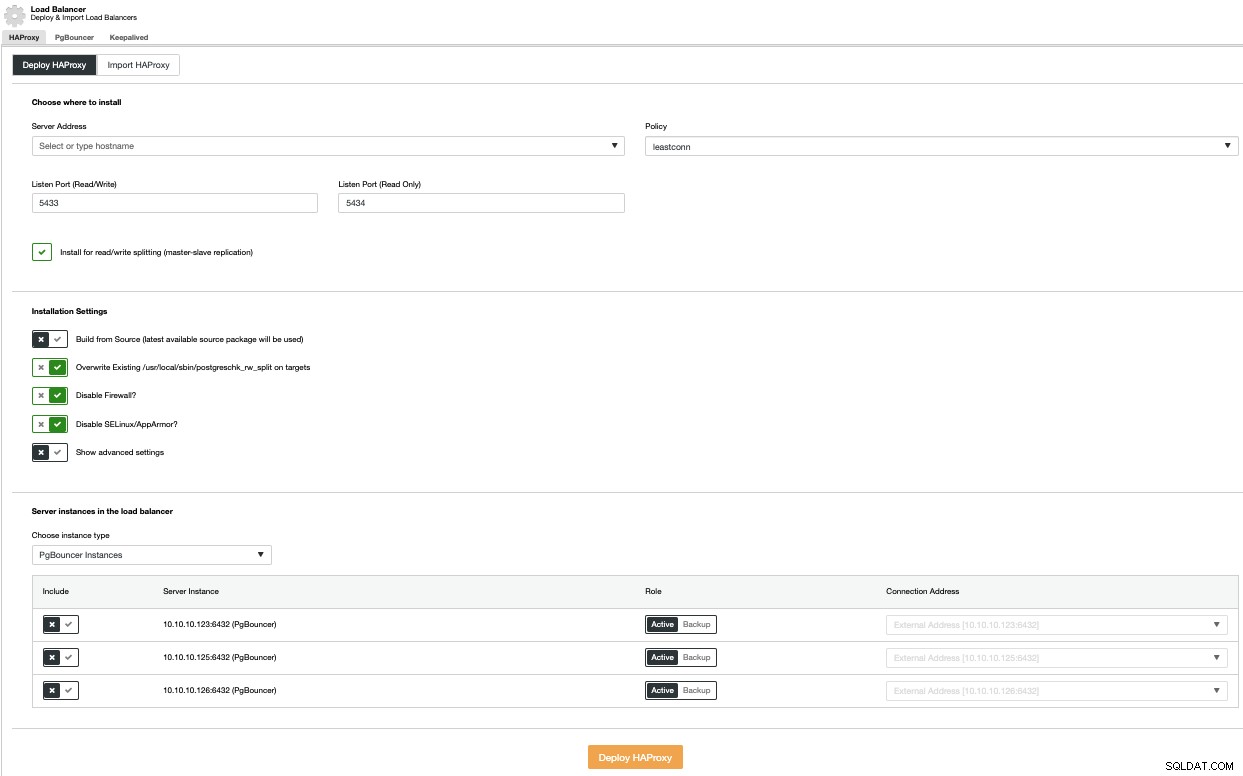
Sie müssen IP oder Hostname, Port, Richtlinie und die Knoten hinzufügen Sie werden verwenden. Wenn Sie PgBouncer verwenden, können Sie es im Kombinationsfeld für den Instanztyp auswählen.
Um einen Single Point of Failure zu vermeiden, sollten Sie mindestens zwei HAProxy-Knoten bereitstellen und Keepalived verwenden, wodurch Sie in Ihrer Anwendung eine virtuelle IP-Adresse verwenden können, die dem aktiven HAProxy-Knoten zugewiesen ist. Wenn dieser Knoten ausfällt, wird die virtuelle IP-Adresse zum sekundären Load Balancer migriert, sodass Ihre Anwendung weiterhin wie gewohnt funktionieren kann.
Keepalived-Bereitstellung
Um eine Keepalived-Bereitstellung durchzuführen, wählen Sie die Option „Load Balancer hinzufügen“ im Menü „Cluster-Aktionen“ und gehen Sie dann zum Keepalived-Tab.
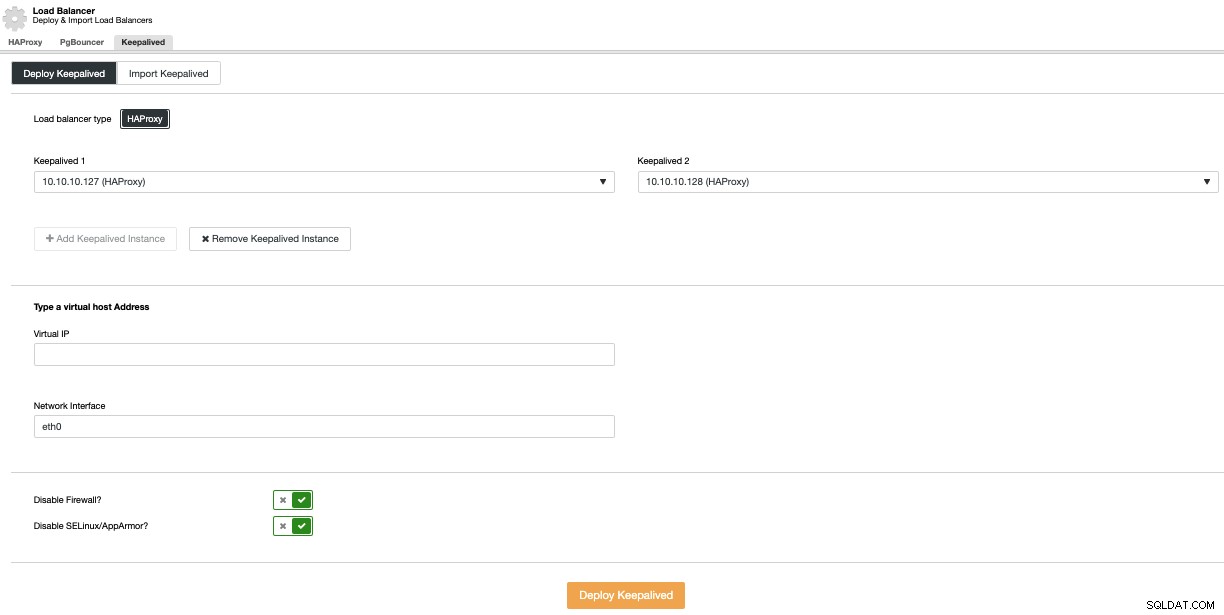
Wählen Sie hier die HAProxy-Knoten aus und geben Sie die entsprechende virtuelle IP-Adresse an verwendet werden, um auf die Datenbank (oder den Connection Pooler) zuzugreifen.
In diesem Moment sollten Sie die folgende Topologie haben:
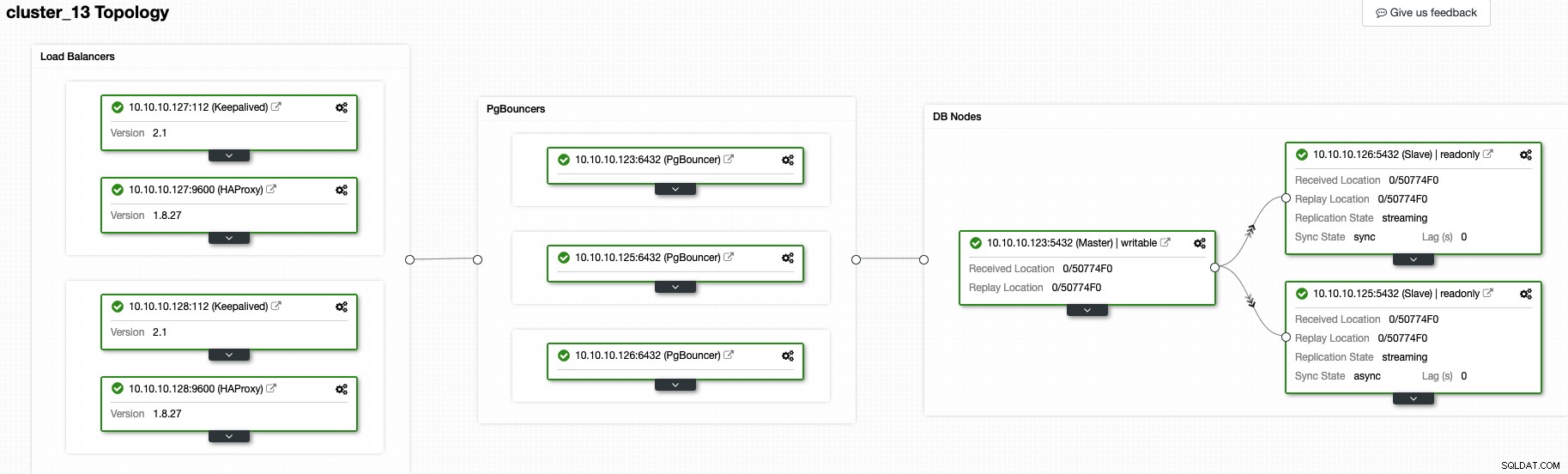
Und das bedeutet:HAProxy + Keepalived -> PgBouncer -> PostgreSQL-Datenbankknoten , das ist eine gute Topologie für Ihren PostgreSQL-Cluster.
Autorecovery-Funktion von ClusterControl
Im Falle eines Fehlers stuft ClusterControl den fortschrittlichsten Standby-Knoten zum Primärknoten hoch und benachrichtigt Sie über das Problem. Außerdem wird für den Rest des Standby-Knotens ein Failover durchgeführt, um vom neuen primären Server zu replizieren.
Standardmäßig ist HAProxy mit zwei verschiedenen Ports konfiguriert:Read-Write und Read-Only. Im Lese-Schreib-Port haben Sie Ihren primären Datenbank- (oder PgBouncer-) Knoten online und die restlichen Knoten offline, und im Nur-Lese-Port haben Sie sowohl den primären als auch den Standby-Knoten online.
Wenn HAProxy feststellt, dass einer Ihrer Knoten nicht erreichbar ist, markiert es ihn automatisch als offline und berücksichtigt ihn nicht beim Senden von Datenverkehr an ihn. Die Erkennung erfolgt durch Zustandsprüfungsskripte, die von ClusterControl zum Zeitpunkt der Bereitstellung konfiguriert werden. Diese prüfen, ob die Instanzen aktiv sind, ob sie gerade wiederhergestellt werden oder schreibgeschützt sind.
Wenn ClusterControl einen Standby-Knoten heraufstuft, markiert HAProxy den alten primären Knoten für beide Ports als offline und setzt den heraufgestuften Knoten im Lese-Schreib-Port online.
Wenn Ihr aktiver HAProxy, dem eine virtuelle IP-Adresse zugewiesen ist, mit der sich Ihre Systeme verbinden, ausfällt, migriert Keepalived diese IP-Adresse automatisch auf Ihren passiven HAProxy. Das bedeutet, dass Ihre Systeme dann normal weiter funktionieren können.
Fazit
Wie Sie sehen können, ist es einfach, eine gute PostgreSQL-Topologie zu haben, wenn Sie ClusterControl verwenden und die grundlegenden Best-Practice-Konzepte für die PostgreSQL-Replikation befolgen. Natürlich hängt die beste Umgebung von der Arbeitsbelastung, der Hardware, der Anwendung usw. ab, aber Sie können sie als Beispiel verwenden und die Teile nach Bedarf verschieben.