Die Verwendung der Replikation für Ihre PostgreSQL-Datenbanken kann nicht nur nützlich sein, um eine hochverfügbare und fehlertolerante Umgebung zu haben, sondern auch um die Leistung Ihres Systems zu verbessern, indem der Datenverkehr zwischen den Standby-Knoten ausgeglichen wird. In diesem ersten Teil des zweiteiligen Blogs werden wir einige Konzepte im Zusammenhang mit der PostgreSQL-Replikation sehen.
Replikationsmethoden in PostgreSQL
Es gibt verschiedene Methoden zum Replizieren von Daten in PostgreSQL, aber hier konzentrieren wir uns auf die beiden Hauptmethoden:Streaming-Replikation und logische Replikation.
Streaming-Replikation
Die PostgreSQL-Streaming-Replikation, die häufigste PostgreSQL-Replikation, ist eine physische Replikation, die die Änderungen Byte für Byte repliziert und eine identische Kopie der Datenbank auf einem anderen Server erstellt. Es basiert auf der Protokollversandmethode. Die WAL-Datensätze werden zur Anwendung direkt von einem Datenbankserver auf einen anderen verschoben. Wir können sagen, dass es sich um eine Art kontinuierliches PITR handelt.
Diese WAL-Übertragung wird auf zwei verschiedene Arten durchgeführt, durch Übertragung von WAL-Datensätzen jeweils eine Datei (WAL-Segment) (dateibasierter Protokollversand) und durch Übertragung von WAL-Datensätzen (eine WAL-Datei besteht aus WAL-Datensätze) on the fly (datensatzbasierter Protokollversand) zwischen einem primären Server und einem oder mehreren Standby-Servern, ohne darauf zu warten, dass die WAL-Datei gefüllt wird.
In der Praxis verbindet sich ein Prozess namens WAL-Empfänger, der auf dem Standby-Server läuft, über eine TCP/IP-Verbindung mit dem Primärserver. Auf dem primären Server existiert ein weiterer Prozess namens WAL-Sender, der für das Senden der WAL-Registrierungen an den Standby-Server zuständig ist, während sie auftreten.
Eine grundlegende Streaming-Replikation kann wie folgt dargestellt werden:
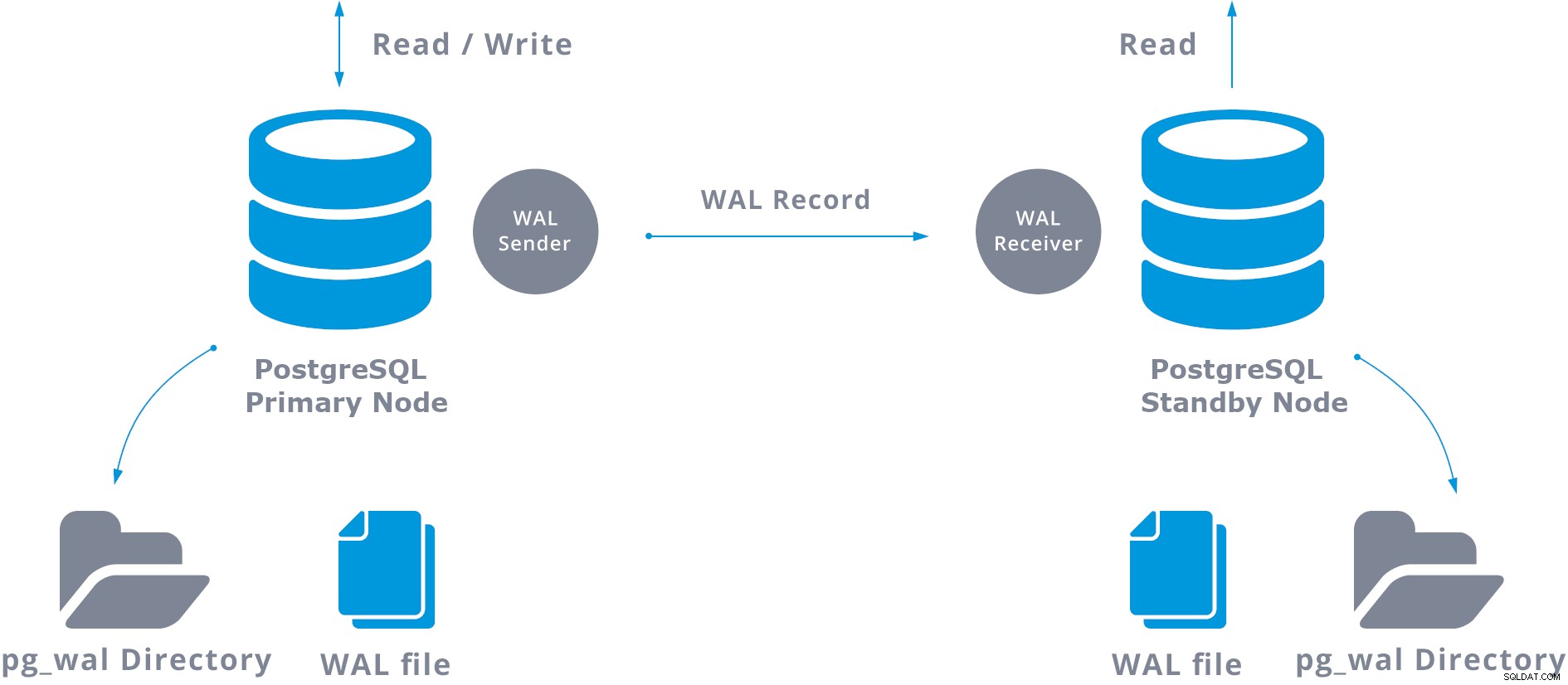
Beim Konfigurieren der Streaming-Replikation haben Sie die Möglichkeit, die WAL-Archivierung zu aktivieren. Dies ist nicht obligatorisch, aber für eine robuste Replikationskonfiguration äußerst wichtig, da verhindert werden muss, dass der Hauptserver alte WAL-Dateien wiederverwendet, die noch nicht auf den Standby-Server angewendet wurden. In diesem Fall müssen Sie das Replikat von Grund auf neu erstellen.
Logische Replikation
Die logische PostgreSQL-Replikation ist eine Methode zum Replizieren von Datenobjekten und deren Änderungen, basierend auf ihrer Replikationsidentität (normalerweise ein Primärschlüssel). Es basiert auf einem Publish-and-Subscribe-Modus, bei dem ein oder mehrere Abonnenten eine oder mehrere Publikationen auf einem Publisher-Knoten abonnieren.
Eine Veröffentlichung ist ein Satz von Änderungen, die aus einer Tabelle oder einer Gruppe von Tabellen generiert wurden. Der Knoten, in dem eine Veröffentlichung definiert ist, wird als Herausgeber bezeichnet. Ein Abonnement ist die Downstream-Seite der logischen Replikation. Der Knoten, an dem ein Abonnement definiert ist, wird als Abonnent bezeichnet und definiert die Verbindung zu einer anderen Datenbank und einem Satz von Veröffentlichungen (einer oder mehreren), die er abonnieren möchte. Abonnenten beziehen Daten aus den von ihnen abonnierten Publikationen.
Die logische Replikation basiert auf einer ähnlichen Architektur wie die physische Streaming-Replikation. Es wird durch die Prozesse "walsender" und "apply" implementiert. Der Walsender-Prozess startet die logische Dekodierung der WAL und lädt das standardmäßige Plug-in für die logische Dekodierung. Das Plugin wandelt die von WAL gelesenen Änderungen in das logische Replikationsprotokoll um und filtert die Daten gemäß der Veröffentlichungsspezifikation. Die Daten werden dann kontinuierlich unter Verwendung des Streaming-Replikationsprotokolls an den Apply-Worker übertragen, der die Daten lokalen Tabellen zuordnet und die einzelnen Änderungen, sobald sie empfangen werden, in einer korrekten Transaktionsreihenfolge anwendet.
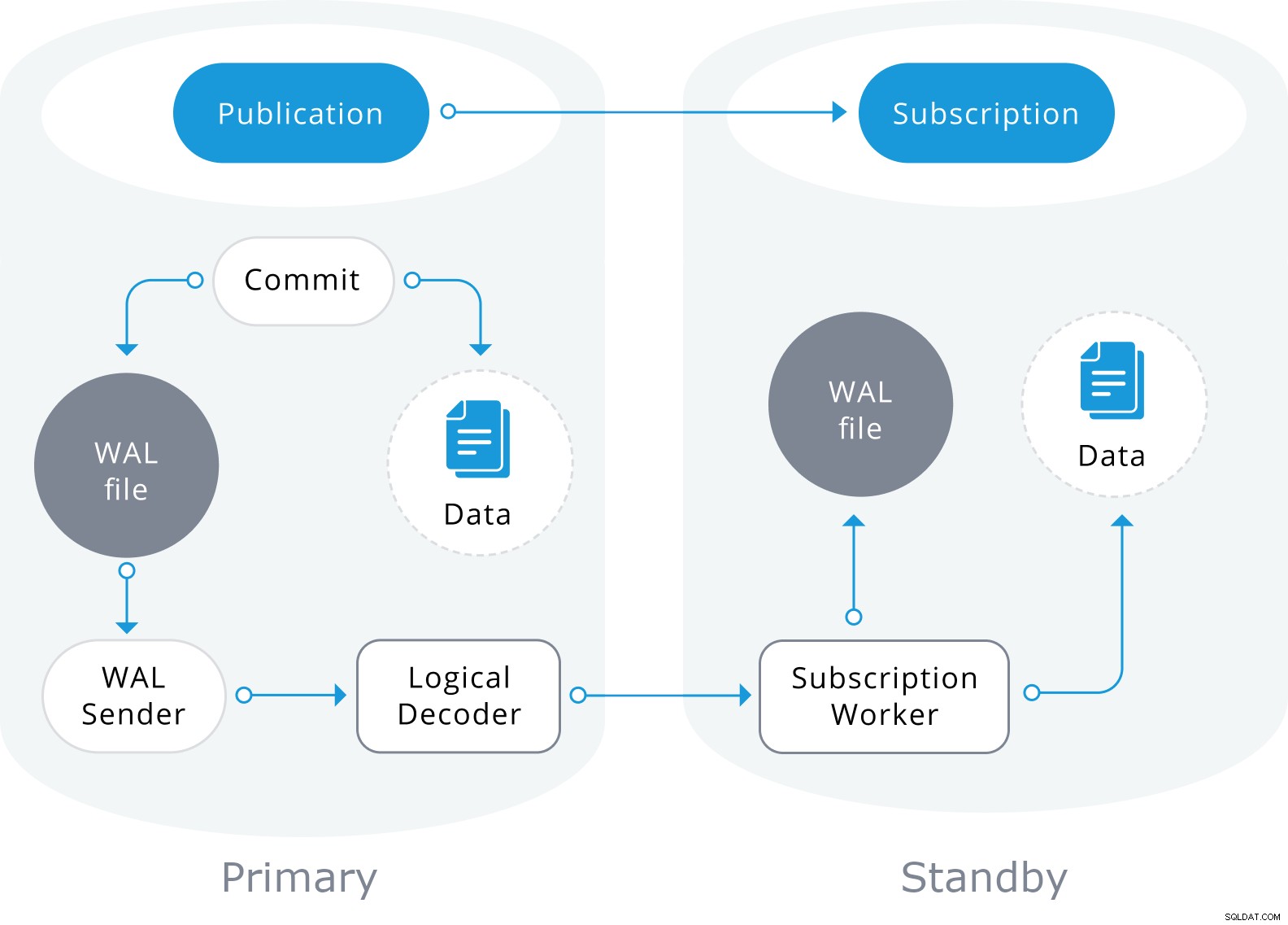
Die logische Replikation beginnt mit der Erstellung eines Snapshots der Daten in der Publisher-Datenbank und Kopieren Sie diese an den Abonnenten. Die Anfangsdaten in den vorhandenen abonnierten Tabellen werden in einer parallelen Instanz eines speziellen Typs von Anwendungsprozessen abgespeichert und kopiert. Dieser Prozess erstellt einen eigenen temporären Replikationsslot und kopiert die vorhandenen Daten. Sobald die vorhandenen Daten kopiert sind, wechselt der Worker in den Synchronisationsmodus, der sicherstellt, dass die Tabelle in einen synchronisierten Zustand mit dem Hauptanwendungsprozess gebracht wird, indem alle Änderungen, die während der anfänglichen Datenkopie unter Verwendung der standardmäßigen logischen Replikation vorgenommen wurden, gestreamt werden. Sobald die Synchronisierung abgeschlossen ist, wird die Steuerung der Replikation der Tabelle an den Hauptanwendungsprozess zurückgegeben, wo die Replikation normal fortgesetzt wird. Die Änderungen am Herausgeber werden in Echtzeit an den Abonnenten gesendet.
Replikationsmodi in PostgreSQL
Die Replikation in PostgreSQL kann synchron oder asynchron erfolgen.
Asynchrone Replikation
Dies ist der Standardmodus. Hier ist es möglich, einige Transaktionen im Primärknoten festzuschreiben, die noch nicht auf den Standby-Server repliziert wurden. Dies bedeutet, dass die Möglichkeit eines potenziellen Datenverlusts besteht. Diese Verzögerung im Commit-Prozess soll sehr gering sein, wenn der Standby-Server leistungsfähig genug ist, um mit der Last Schritt zu halten. Wenn dieses geringe Datenverlustrisiko im Unternehmen nicht akzeptabel ist, können Sie stattdessen die synchrone Replikation verwenden.
Synchrone Replikation
Jedes Commit einer Schreibtransaktion wartet auf die Bestätigung, dass das Commit auf die Write-Ahead-Log-On-Festplatte sowohl des Primär- als auch des Standby-Servers geschrieben wurde. Diese Methode minimiert die Möglichkeit eines Datenverlusts. Damit ein Datenverlust auftritt, müssen sowohl der Primär- als auch der Standby-Server gleichzeitig ausfallen.
Der Nachteil dieser Methode ist bei allen synchronen Methoden gleich, da sich bei dieser Methode die Antwortzeit für jede Schreibtransaktion erhöht. Dies liegt daran, dass gewartet werden muss, bis alle Bestätigungen vorliegen, dass die Transaktion festgeschrieben wurde. Glücklicherweise sind schreibgeschützte Transaktionen davon nicht betroffen, aber; nur die Schreibtransaktionen.
Hochverfügbarkeit für die PostgreSQL-Replikation
Hohe Verfügbarkeit ist eine Anforderung für viele Systeme, egal welche Technologie wir verwenden, und es gibt verschiedene Ansätze, um dies mit verschiedenen Tools zu erreichen.
Lastenausgleich
Load-Balancer sind Tools, mit denen Sie den Datenverkehr Ihrer Anwendung verwalten können, um das Beste aus Ihrer Datenbankarchitektur herauszuholen. Es ist nicht nur nützlich, um die Last unserer Datenbanken auszugleichen, es hilft auch, Anwendungen auf die verfügbaren/fehlerfreien Knoten umzuleiten und sogar Ports mit unterschiedlichen Rollen anzugeben.
HAProxy ist ein Load Balancer, der den Datenverkehr von einem Ursprung zu einem oder mehreren Zielen verteilt und für diese Aufgabe spezifische Regeln und/oder Protokolle definieren kann. Wenn eines der Ziele nicht mehr reagiert, wird es als offline markiert und der Datenverkehr wird an die restlichen verfügbaren Ziele gesendet. Wenn Sie nur einen Load Balancer-Knoten haben, wird ein Single Point of Failure generiert. Um dies zu vermeiden, sollten Sie mindestens zwei HAProxy-Knoten bereitstellen und Keepalived zwischen ihnen konfigurieren.
Keepalived ist ein Dienst, der es uns ermöglicht, eine virtuelle IP innerhalb einer Aktiv/Passiv-Gruppe von Servern zu konfigurieren. Diese virtuelle IP wird einem aktiven Server zugewiesen. Wenn dieser Server ausfällt, wird die IP automatisch auf den „sekundären“ passiven Server migriert, sodass dieser auf transparente Weise für die Systeme mit derselben IP weiterarbeiten kann.
Verbesserung der Leistung bei der PostgreSQL-Replikation
Leistung ist in jedem System immer wichtig. Sie müssen die verfügbaren Ressourcen gut nutzen, um die bestmögliche Reaktionszeit zu gewährleisten, und es gibt verschiedene Möglichkeiten, dies zu tun. Jede Verbindung zu einer Datenbank verbraucht Ressourcen, daher besteht eine der Möglichkeiten zur Verbesserung der Leistung Ihrer PostgreSQL-Datenbank darin, einen guten Verbindungspooler zwischen Ihrer Anwendung und den Datenbankservern zu haben.
Verbindungspooler
Ein Verbindungspooling ist eine Methode, einen Pool von Verbindungen zu erstellen und diese wiederzuverwenden, wodurch vermieden wird, ständig neue Verbindungen zur Datenbank zu öffnen, was die Leistung Ihrer Anwendungen erheblich steigern wird. PgBouncer ist ein beliebter Verbindungspooler, der für PostgreSQL entwickelt wurde.
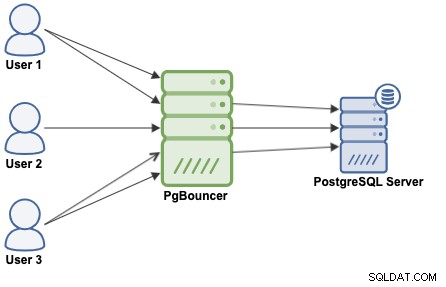
PgBouncer fungiert als PostgreSQL-Server, sodass Sie nur auf Ihre Datenbank zugreifen müssen Verwenden der PgBouncer-Informationen (IP-Adresse/Hostname und Port) und PgBouncer erstellt eine Verbindung zum PostgreSQL-Server oder verwendet eine wieder, falls vorhanden.
Wenn PgBouncer eine Verbindung erhält, führt es die Authentifizierung durch, die von der in der Konfigurationsdatei angegebenen Methode abhängt. PgBouncer unterstützt alle Authentifizierungsmechanismen, die der PostgreSQL-Server unterstützt. Danach sucht PgBouncer nach einer zwischengespeicherten Verbindung mit derselben Kombination aus Benutzername und Datenbank. Wenn eine zwischengespeicherte Verbindung gefunden wird, gibt es die Verbindung an den Client zurück, wenn nicht, erstellt es eine neue Verbindung. Abhängig von der PgBouncer-Konfiguration und der Anzahl aktiver Verbindungen kann es möglich sein, dass die neue Verbindung in die Warteschlange gestellt wird, bis sie erstellt werden kann, oder sogar abgebrochen wird.
Mit all diesen erwähnten Konzepten werden wir im zweiten Teil dieses Blogs sehen, wie Sie sie kombinieren können, um eine gute Replikationsumgebung in PostgreSQL zu haben.



