Die Replikation spielt eine entscheidende Rolle bei der Aufrechterhaltung einer hohen Verfügbarkeit. Server können ausfallen, das Betriebssystem oder die Datenbanksoftware müssen möglicherweise aktualisiert werden. Das bedeutet, Serverrollen neu zu ordnen und Replikationslinks zu verschieben, während die Datenkonsistenz über alle Datenbanken hinweg aufrechterhalten wird. Topologieänderungen sind erforderlich, und es gibt verschiedene Möglichkeiten, sie durchzuführen.
Bewerben eines Standby-Servers
Dies ist wohl die häufigste Operation, die Sie durchführen müssen. Dafür gibt es mehrere Gründe – zum Beispiel eine Datenbankwartung auf dem primären Server, die die Arbeitslast in nicht akzeptabler Weise beeinträchtigen würde. Aufgrund einiger Hardwarevorgänge kann es zu geplanten Ausfallzeiten kommen. Der Absturz des primären Servers, der ihn für die Anwendung unzugänglich macht. All dies sind Gründe, ein Failover durchzuführen, ob geplant oder nicht. In allen Fällen müssen Sie einen der Standby-Server zu einem neuen Primärserver machen.
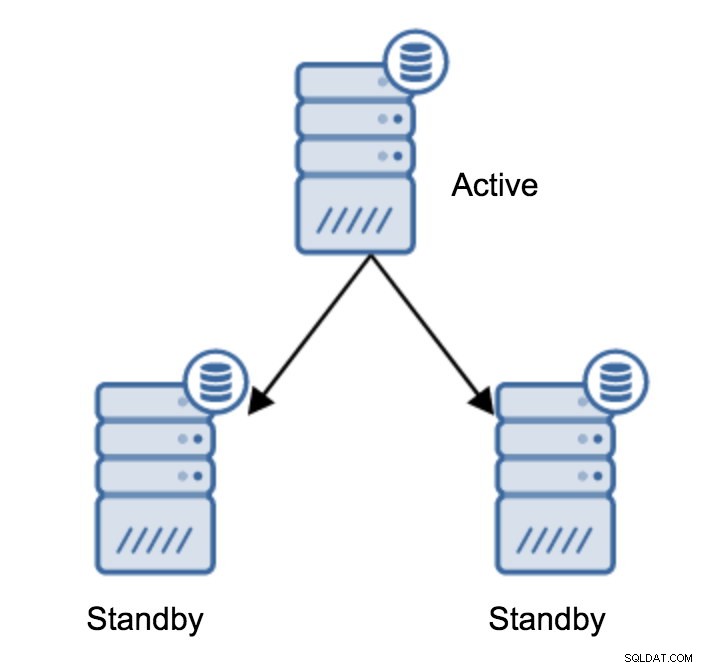
Um einen Standby-Server hochzustufen, müssen Sie Folgendes ausführen:
example@sqldat.com:~$ /usr/lib/postgresql/10/bin/pg_ctl promote -D /var/lib/postgresql/10/main/
waiting for server to promote.... done
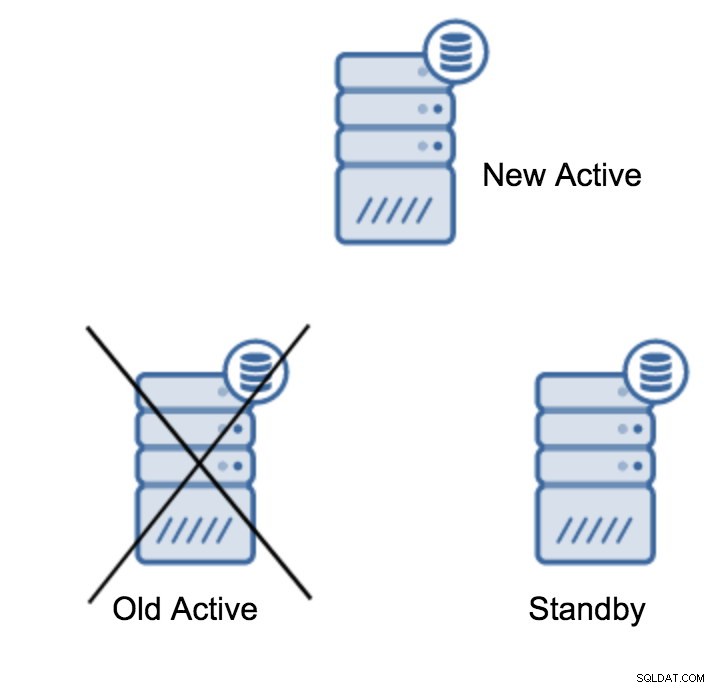
server promotedEs ist einfach, diesen Befehl auszuführen, aber stellen Sie zunächst sicher, dass Datenverluste vermieden werden. Wenn wir über ein „primärer Serverausfall“-Szenario sprechen, haben Sie möglicherweise nicht allzu viele Optionen. Wenn es sich um eine geplante Wartung handelt, kann man sich darauf vorbereiten. Sie müssen den Datenverkehr auf dem primären Server stoppen und dann überprüfen, ob der Standby-Server alle Daten empfangen und angewendet hat. Dies kann auf dem Standby-Server mit der folgenden Abfrage erfolgen:
postgres=# select pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn();
pg_last_wal_receive_lsn | pg_last_wal_replay_lsn
-------------------------+------------------------
1/AA2D2B08 | 1/AA2D2B08
(1 row)Sobald alles in Ordnung ist, können Sie den alten primären Server stoppen und den Standby-Server heraufstufen.
Laden Sie noch heute das Whitepaper PostgreSQL-Verwaltung und -Automatisierung mit ClusterControl herunterErfahren Sie, was Sie wissen müssen, um PostgreSQL bereitzustellen, zu überwachen, zu verwalten und zu skalierenLaden Sie das Whitepaper herunterReslave eines Standby-Servers von einem neuen Primärserver
Möglicherweise haben Sie mehr als einen Standby-Server, der Ihren primären Server ablöst. Schließlich sind Standby-Server nützlich, um schreibgeschützten Datenverkehr auszulagern. Nachdem Sie einen Standby-Server zu einem neuen primären Server hochgestuft haben, müssen Sie etwas mit den verbleibenden Standby-Servern unternehmen, die noch mit dem alten primären Server verbunden sind (oder versuchen, eine Verbindung herzustellen). Leider können Sie nicht einfach die recovery.conf ändern und sie mit dem neuen primären Server verbinden. Um sie zu verbinden, müssen Sie sie zuerst neu erstellen. Es gibt zwei Methoden, die Sie hier ausprobieren können:Standard-Basissicherung oder pg_rewind.
Wir werden nicht ins Detail gehen, wie man ein Basis-Backup erstellt – wir haben es in unserem vorherigen Blogbeitrag behandelt, der sich auf das Erstellen von Backups und deren Wiederherstellung auf PostgreSQL konzentrierte. Wenn Sie ClusterControl verwenden, können Sie damit auch ein Basis-Backup erstellen:
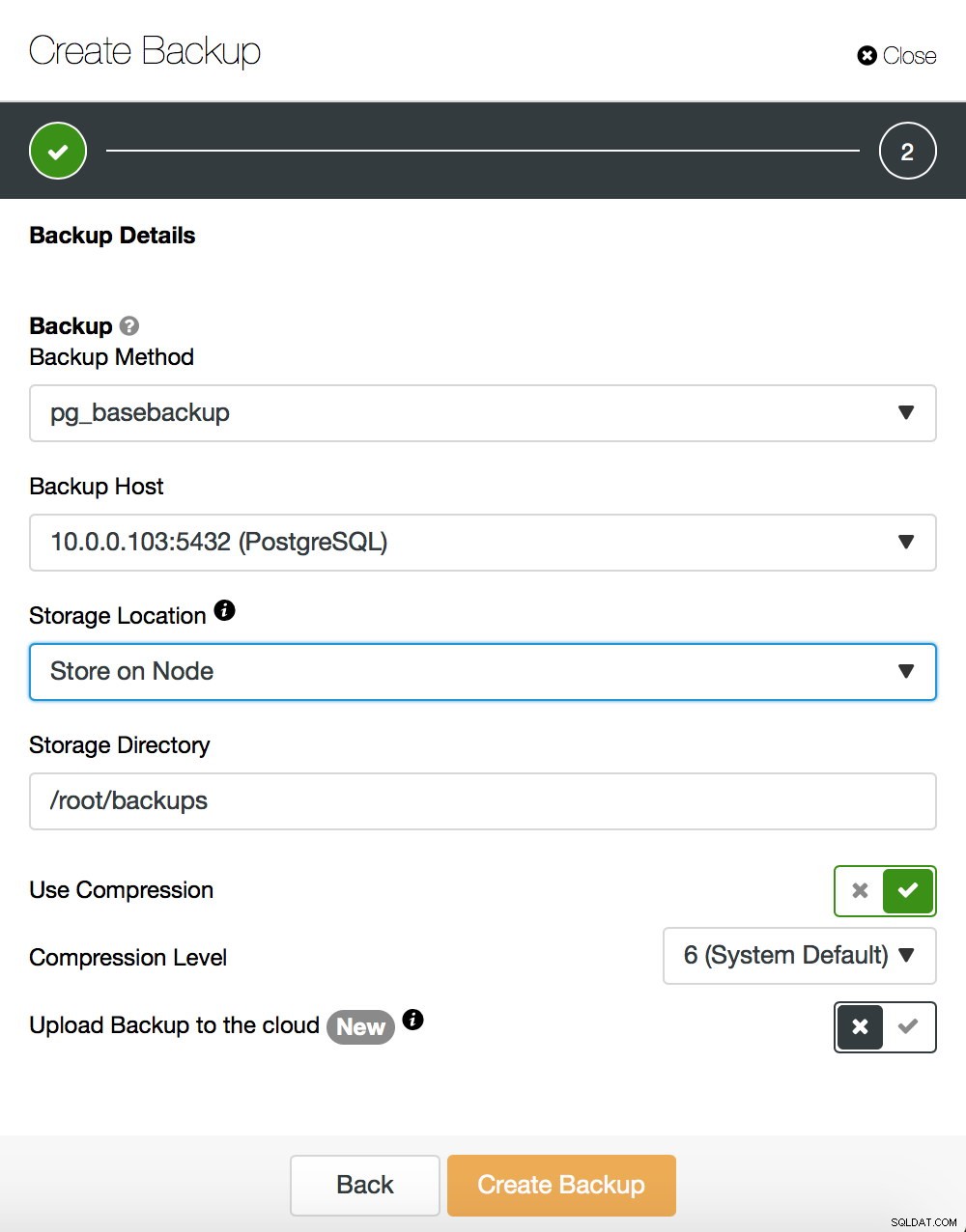
Lassen Sie uns andererseits ein paar Worte über pg_rewind sagen. Der Hauptunterschied zwischen beiden Methoden besteht darin, dass die Basissicherung eine vollständige Kopie des Datensatzes erstellt. Wenn wir über kleine Datensätze sprechen, kann das in Ordnung sein, aber bei Datensätzen mit einer Größe von Hunderten von Gigabyte (oder sogar noch größer) kann es schnell zu einem Problem werden. Letztendlich möchten Sie, dass Ihre Standby-Server schnell einsatzbereit sind, um Ihren aktiven Server zu entlasten und bei Bedarf einen anderen Standby-Server für ein Failover zu haben. Pg_rewind funktioniert anders - es kopiert nur die Blöcke, die geändert wurden. Anstatt alles zu kopieren, kopiert es nur Änderungen, was den Prozess erheblich beschleunigt. Nehmen wir an, Ihr neuer Master hat eine IP von 10.0.0.103. So können Sie pg_rewind ausführen. Bitte beachten Sie, dass der Zielserver gestoppt sein muss - PostgreSQL kann dort nicht ausgeführt werden.
example@sqldat.com:~$ /usr/lib/postgresql/10/bin/pg_rewind --source-server="user=myuser dbname=postgres host=10.0.0.103" --target-pgdata=/var/lib/postgresql/10/main --dry-run
servers diverged at WAL location 1/AA4F1160 on timeline 3
rewinding from last common checkpoint at 1/AA4F10F0 on timeline 3
Done!Dies führt zu einem Trockenlauf , den Prozess testen, aber keine Änderungen vornehmen. Wenn alles in Ordnung ist, müssen Sie es nur noch einmal ausführen, diesmal ohne den Parameter „--dry-run“. Sobald dies erledigt ist, besteht der letzte verbleibende Schritt darin, eine recovery.conf-Datei zu erstellen, die auf den neuen Master verweist. Das kann so aussehen:
standby_mode = 'on'
primary_conninfo = 'application_name=pgsql_node_0 host=10.0.0.103 port=5432 user=replication_user password=replication_password'
recovery_target_timeline = 'latest'
trigger_file = '/tmp/failover.trigger'Jetzt können Sie Ihren Standby-Server starten und er wird vom neuen aktiven Server replizieren.
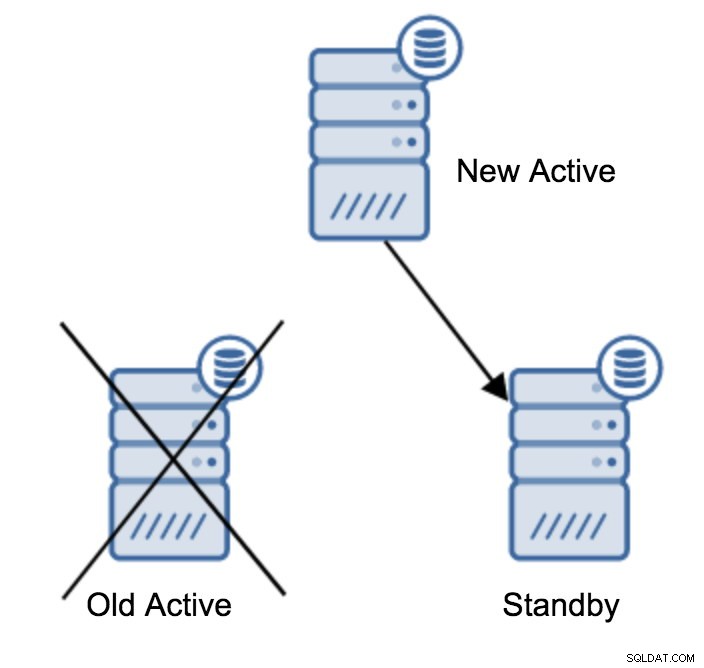
Verkettete Replikation
Es gibt zahlreiche Gründe, warum Sie möglicherweise eine verkettete Replikation erstellen möchten, obwohl dies normalerweise getan wird, um die Last auf dem primären Server zu reduzieren. Das Bereitstellen der WAL für Standby-Server fügt etwas Overhead hinzu. Es ist kein großes Problem, wenn Sie ein oder zwei Standby-Server haben, aber wenn wir über eine große Anzahl von Standby-Servern sprechen, kann dies zu einem Problem werden. Beispielsweise können wir die Anzahl der Standby-Server minimieren, die direkt vom aktiven Server replizieren, indem wir eine Topologie wie folgt erstellen:
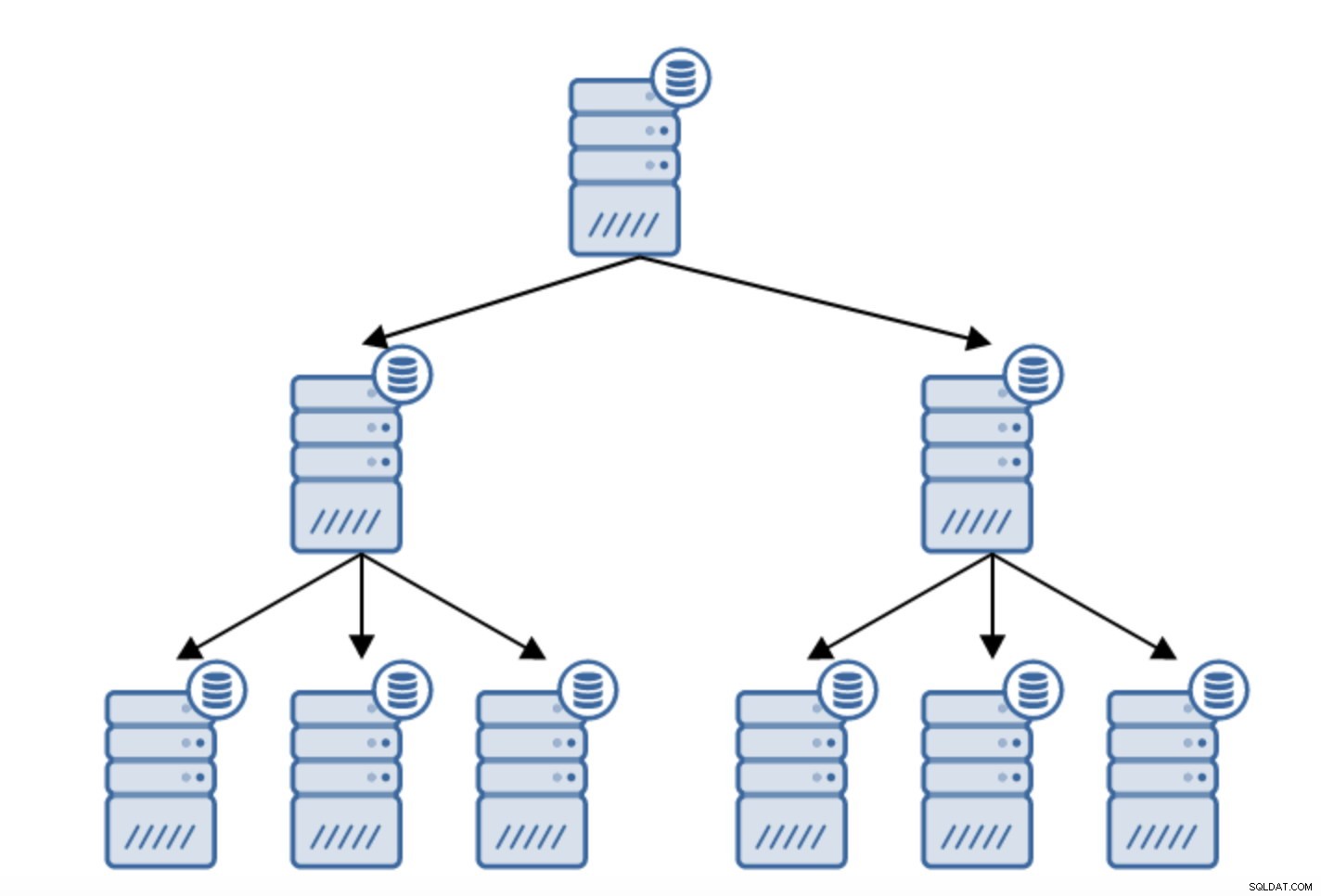
Der Wechsel von einer Topologie mit zwei Standby-Servern zu einer verketteten Replikation ist ziemlich einfach.
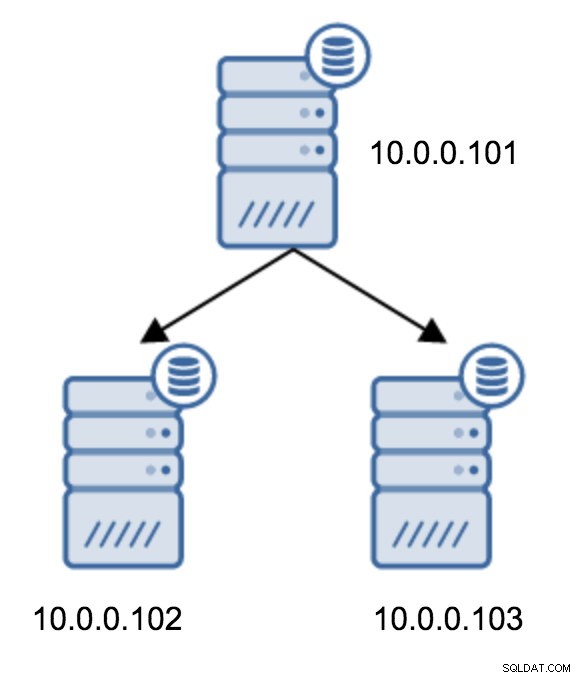
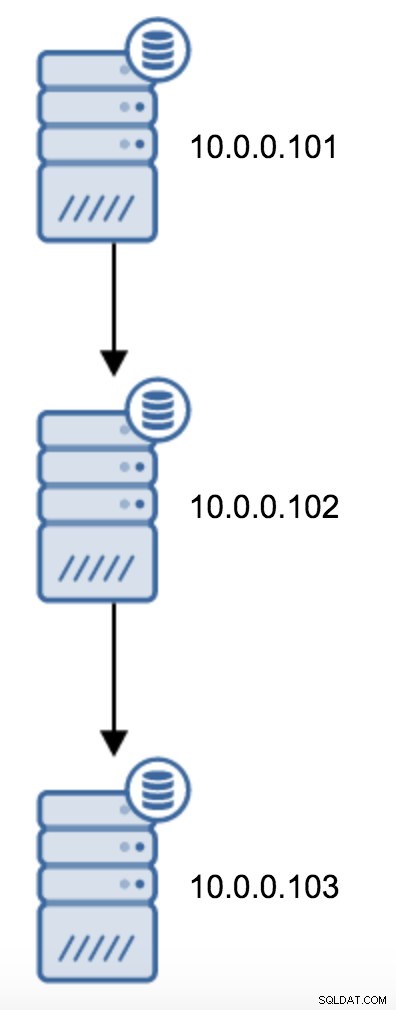
Sie müssten recovery.conf auf 10.0.0.103 ändern, auf 10.0.0.102 verweisen und dann PostgreSQL neu starten.
standby_mode = 'on'
primary_conninfo = 'application_name=pgsql_node_0 host=10.0.0.102 port=5432 user=replication_user password=replication_password'
recovery_target_timeline = 'latest'
trigger_file = '/tmp/failover.trigger'Nach dem Neustart sollte 10.0.0.103 beginnen, WAL-Updates anzuwenden.
Dies sind einige häufige Fälle von Topologieänderungen. Ein nicht diskutiertes, aber dennoch wichtiges Thema sind die Auswirkungen dieser Änderungen auf die Anwendungen. Wir werden das in einem separaten Beitrag behandeln, ebenso wie diese Topologieänderungen für die Anwendungen transparent gemacht werden können.



