Eine Proxyebene kann sehr nützlich sein, um die Verfügbarkeit Ihrer Datenbankschicht zu erhöhen. Es kann die Codemenge auf der Anwendungsseite reduzieren, um Datenbankfehler und Änderungen der Replikationstopologie zu handhaben. In diesem Blogpost werden wir diskutieren, wie man einen HAProxy einrichtet, um auf PostgreSQL zu arbeiten.
Das Wichtigste zuerst – HAProxy arbeitet mit Datenbanken als Netzwerkschicht-Proxy. Es gibt kein Verständnis für die zugrunde liegende, manchmal komplexe Topologie. Alles, was HAProxy tut, ist, Pakete im Round-Robin-Verfahren an definierte Backends zu senden. Es untersucht weder Pakete noch versteht es das Protokoll, in dem Anwendungen mit PostgreSQL kommunizieren. Infolgedessen gibt es für den HAProxy keine Möglichkeit, eine Lese-/Schreibaufteilung auf einem einzelnen Port zu implementieren – dies würde das Analysieren von Abfragen erfordern. Solange Ihre Anwendung Lese- und Schreibvorgänge aufteilen und an verschiedene IPs oder Ports senden kann, können Sie die R/W-Aufteilung mit zwei Backends implementieren. Schauen wir uns an, wie es gemacht werden kann.
HAProxy-Konfiguration
Unten finden Sie ein Beispiel für zwei in HAProxy konfigurierte PostgreSQL-Backends.
listen haproxy_10.0.0.101_3307_rw
bind *:3307
mode tcp
timeout client 10800s
timeout server 10800s
tcp-check expect string master\ is\ running
balance leastconn
option tcp-check
option allbackups
default-server port 9201 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100
server 10.0.0.101 10.0.0.101:5432 check
server 10.0.0.102 10.0.0.102:5432 check
server 10.0.0.103 10.0.0.103:5432 check
listen haproxy_10.0.0.101_3308_ro
bind *:3308
mode tcp
timeout client 10800s
timeout server 10800s
tcp-check expect string is\ running.
balance leastconn
option tcp-check
option allbackups
default-server port 9201 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100
server 10.0.0.101 10.0.0.101:5432 check
server 10.0.0.102 10.0.0.102:5432 check
server 10.0.0.103 10.0.0.103:5432 checkWie wir sehen können, verwenden sie die Ports 3307 zum Schreiben und 3308 zum Lesen. In diesem Setup gibt es drei Server – eine aktive und zwei Standby-Replikate. Was wichtig ist, tcp-check wird verwendet, um den Zustand der Knoten zu verfolgen. HAProxy stellt eine Verbindung zu Port 9201 her und erwartet, dass eine Zeichenfolge zurückgegeben wird. Gesunde Mitglieder des Backends geben den erwarteten Inhalt zurück, diejenigen, die den String nicht zurückgeben, werden als nicht verfügbar markiert.
Xinetd-Setup
Da HAProxy Port 9201 überprüft, muss etwas darauf lauschen. Wir können xinetd verwenden, um dort zu lauschen und einige Skripte für uns auszuführen. Eine Beispielkonfiguration eines solchen Dienstes kann wie folgt aussehen:
# default: on
# description: postgreschk
service postgreschk
{
flags = REUSE
socket_type = stream
port = 9201
wait = no
user = root
server = /usr/local/sbin/postgreschk
log_on_failure += USERID
disable = no
#only_from = 0.0.0.0/0
only_from = 0.0.0.0/0
per_source = UNLIMITED
}Sie müssen sicherstellen, dass Sie die Zeile hinzufügen:
postgreschk 9201/tcpzu /etc/services.
Xinetd startet ein Postgreschk-Skript, das folgenden Inhalt hat:
#!/bin/bash
#
# This script checks if a PostgreSQL server is healthy running on localhost. It will
# return:
# "HTTP/1.x 200 OK\r" (if postgres is running smoothly)
# - OR -
# "HTTP/1.x 500 Internal Server Error\r" (else)
#
# The purpose of this script is make haproxy capable of monitoring PostgreSQL properly
#
export PGHOST='10.0.0.101'
export PGUSER='someuser'
export PGPASSWORD='somepassword'
export PGPORT='5432'
export PGDATABASE='postgres'
export PGCONNECT_TIMEOUT=10
FORCE_FAIL="/dev/shm/proxyoff"
SLAVE_CHECK="SELECT pg_is_in_recovery()"
WRITABLE_CHECK="SHOW transaction_read_only"
return_ok()
{
echo -e "HTTP/1.1 200 OK\r\n"
echo -e "Content-Type: text/html\r\n"
if [ "$1x" == "masterx" ]; then
echo -e "Content-Length: 56\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL master is running.</body></html>\r\n"
elif [ "$1x" == "slavex" ]; then
echo -e "Content-Length: 55\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL slave is running.</body></html>\r\n"
else
echo -e "Content-Length: 49\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL is running.</body></html>\r\n"
fi
echo -e "\r\n"
unset PGUSER
unset PGPASSWORD
exit 0
}
return_fail()
{
echo -e "HTTP/1.1 503 Service Unavailable\r\n"
echo -e "Content-Type: text/html\r\n"
echo -e "Content-Length: 48\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL is *down*.</body></html>\r\n"
echo -e "\r\n"
unset PGUSER
unset PGPASSWORD
exit 1
}
if [ -f "$FORCE_FAIL" ]; then
return_fail;
fi
# check if in recovery mode (that means it is a 'slave')
SLAVE=$(psql -qt -c "$SLAVE_CHECK" 2>/dev/null)
if [ $? -ne 0 ]; then
return_fail;
elif echo $SLAVE | egrep -i "(t|true|on|1)" 2>/dev/null >/dev/null; then
return_ok "slave"
fi
# check if writable (then we consider it as a 'master')
READONLY=$(psql -qt -c "$WRITABLE_CHECK" 2>/dev/null)
if [ $? -ne 0 ]; then
return_fail;
elif echo $READONLY | egrep -i "(f|false|off|0)" 2>/dev/null >/dev/null; then
return_ok "master"
fi
return_ok "none";Die Logik des Skripts geht wie folgt. Es gibt zwei Abfragen, die verwendet werden, um den Status des Knotens zu ermitteln.
SLAVE_CHECK="SELECT pg_is_in_recovery()"
WRITABLE_CHECK="SHOW transaction_read_only"Der erste prüft, ob sich PostgreSQL in der Wiederherstellung befindet – er ist „false“ für den aktiven Server und „true“ für Standby-Server. Die zweite prüft, ob sich PostgreSQL im schreibgeschützten Modus befindet. Der aktive Server gibt „off“ zurück, während Standby-Server „on“ zurückgeben. Basierend auf den Ergebnissen ruft das Skript die Funktion return_ok() mit einem richtigen Parameter auf („Master“ oder „Slave“, je nachdem, was erkannt wurde). Wenn die Abfragen fehlgeschlagen sind, wird eine „return_fail“-Funktion ausgeführt.
Die Return_ok-Funktion gibt eine Zeichenfolge basierend auf dem übergebenen Argument zurück. Wenn der Host ein aktiver Server ist, gibt das Skript „PostgreSQL-Master läuft“ zurück. Wenn es sich um einen Standby handelt, lautet die zurückgegebene Zeichenfolge:„PostgreSQL-Slave läuft“. Wenn der Status nicht eindeutig ist, wird zurückgegeben:„PostgreSQL läuft“. Hier endet die Schleife. HAProxy überprüft den Status, indem es sich mit xinetd verbindet. Letzteres startet ein Skript, das dann einen String zurückliefert, den HAProxy parst.
Wie Sie sich vielleicht erinnern, erwartet HAProxy die folgenden Zeichenfolgen:
tcp-check expect string master\ is\ runningfür das Write-Backend und
tcp-check expect string is\ running.für das schreibgeschützte Backend. Dadurch wird der aktive Server zum einzigen verfügbaren Host im Schreib-Backend, während im Lese-Backend sowohl aktive als auch Standby-Server verwendet werden können.
PostgreSQL und HAProxy in ClusterControl
Das obige Setup ist nicht komplex, aber es dauert einige Zeit, es einzurichten. ClusterControl kann verwendet werden, um all dies für Sie einzurichten.
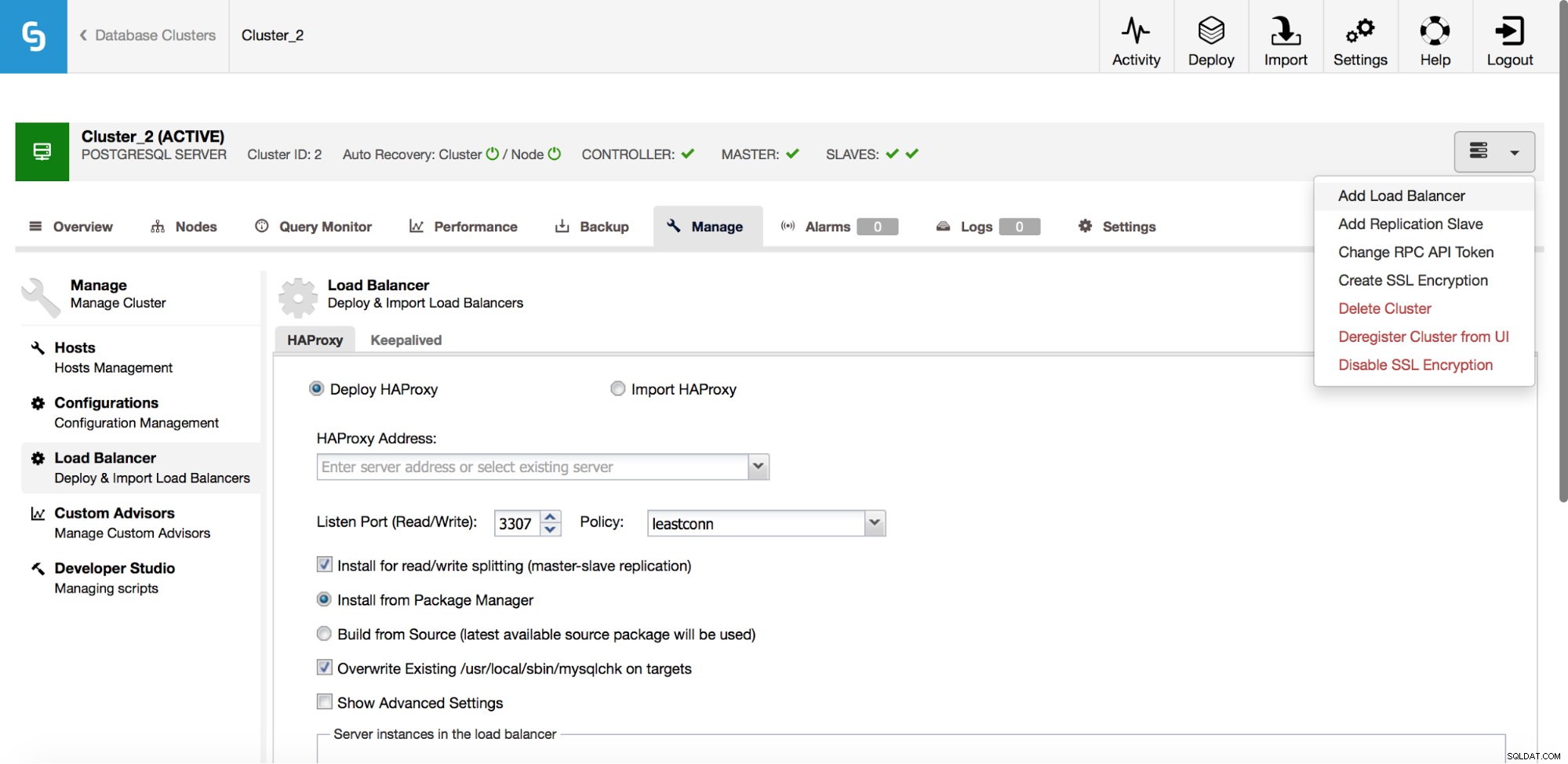
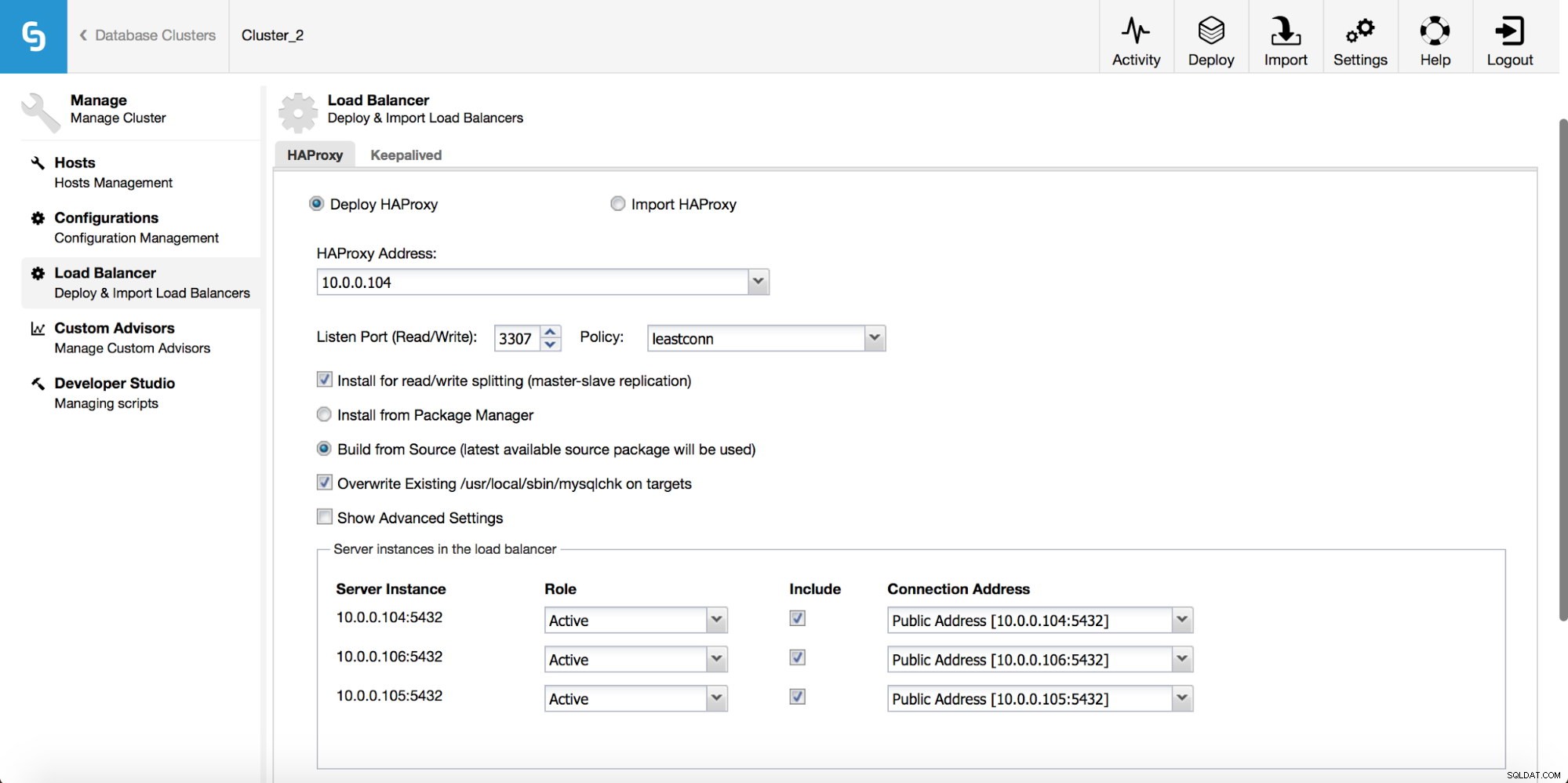
Im Drop-down-Menü des Cluster-Jobs haben Sie die Möglichkeit, einen Load Balancer hinzuzufügen. Dann wird eine Option zum Bereitstellen von HAProxy angezeigt. Sie müssen angeben, wo Sie es installieren möchten, und einige Entscheidungen treffen:aus den Repositories, die Sie auf dem Host konfiguriert haben, oder der neuesten Version, die aus dem Quellcode kompiliert wurde. Sie müssen auch konfigurieren, welche Knoten im Cluster Sie zu HAProxy hinzufügen möchten.
Sobald die HAProxy-Instanz bereitgestellt ist, können Sie auf der Registerkarte „Knoten“ auf einige Statistiken zugreifen:
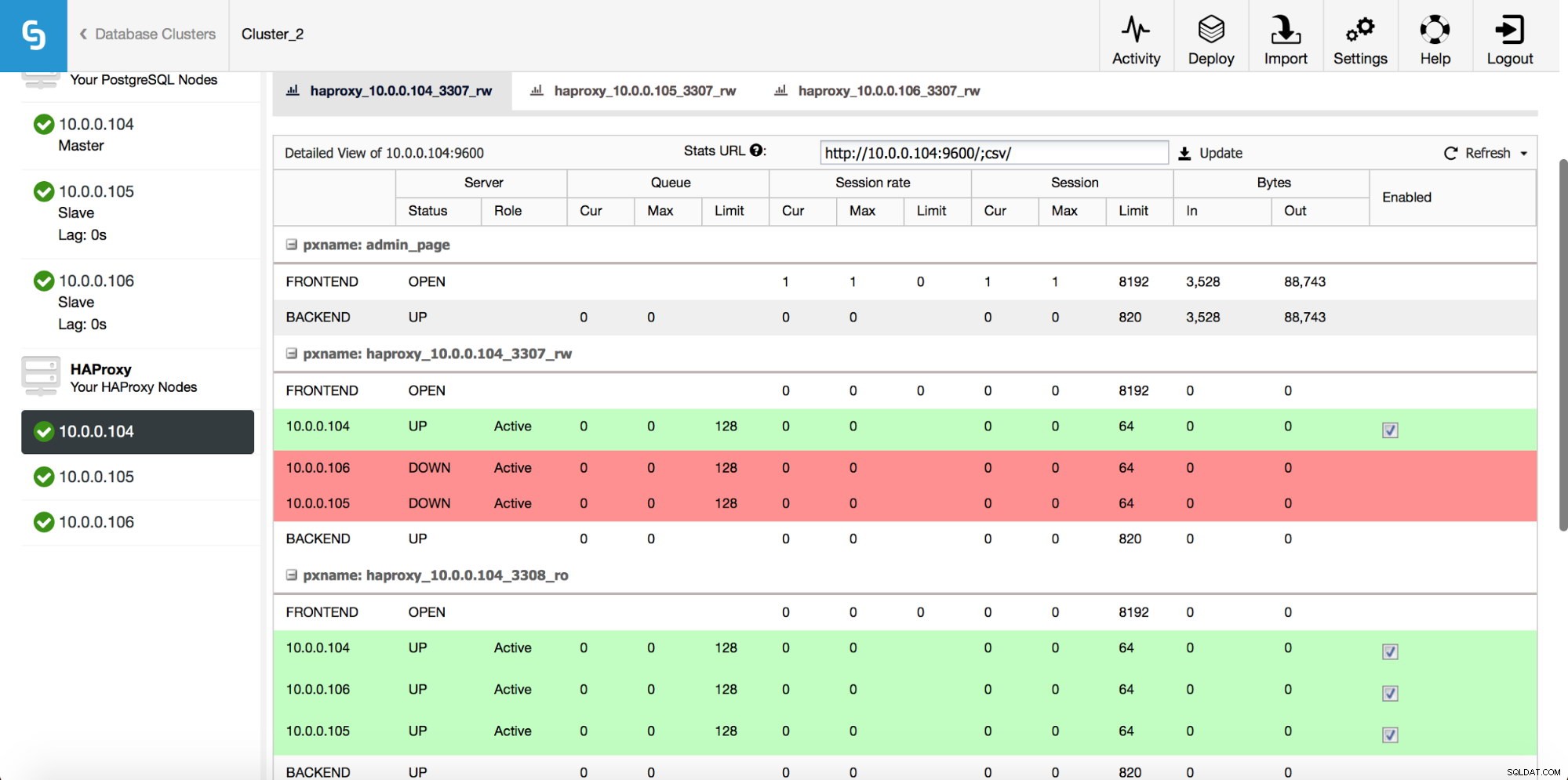
Wie wir sehen können, ist für das R/W-Backend nur ein Host (aktiver Server) als aktiv markiert. Für das schreibgeschützte Backend sind alle Knoten aktiv.
Laden Sie noch heute das Whitepaper PostgreSQL-Verwaltung und -Automatisierung mit ClusterControl herunterErfahren Sie, was Sie wissen müssen, um PostgreSQL bereitzustellen, zu überwachen, zu verwalten und zu skalierenLaden Sie das Whitepaper herunterKeepalived
HAProxy sitzt zwischen Ihren Anwendungen und Datenbankinstanzen und spielt somit eine zentrale Rolle. Es kann leider auch zu einem Single Point of Failure werden, bei einem Ausfall gibt es keinen Weg zu den Datenbanken. Um eine solche Situation zu vermeiden, können Sie mehrere HAProxy-Instanzen bereitstellen. Aber dann ist die Frage, wie man entscheidet, mit welchem Proxy-Host man sich verbindet. Wenn Sie HAProxy von ClusterControl bereitgestellt haben, ist es so einfach wie das Ausführen eines weiteren „Load Balancer hinzufügen“-Jobs, diesmal mit der Bereitstellung von Keepalived.
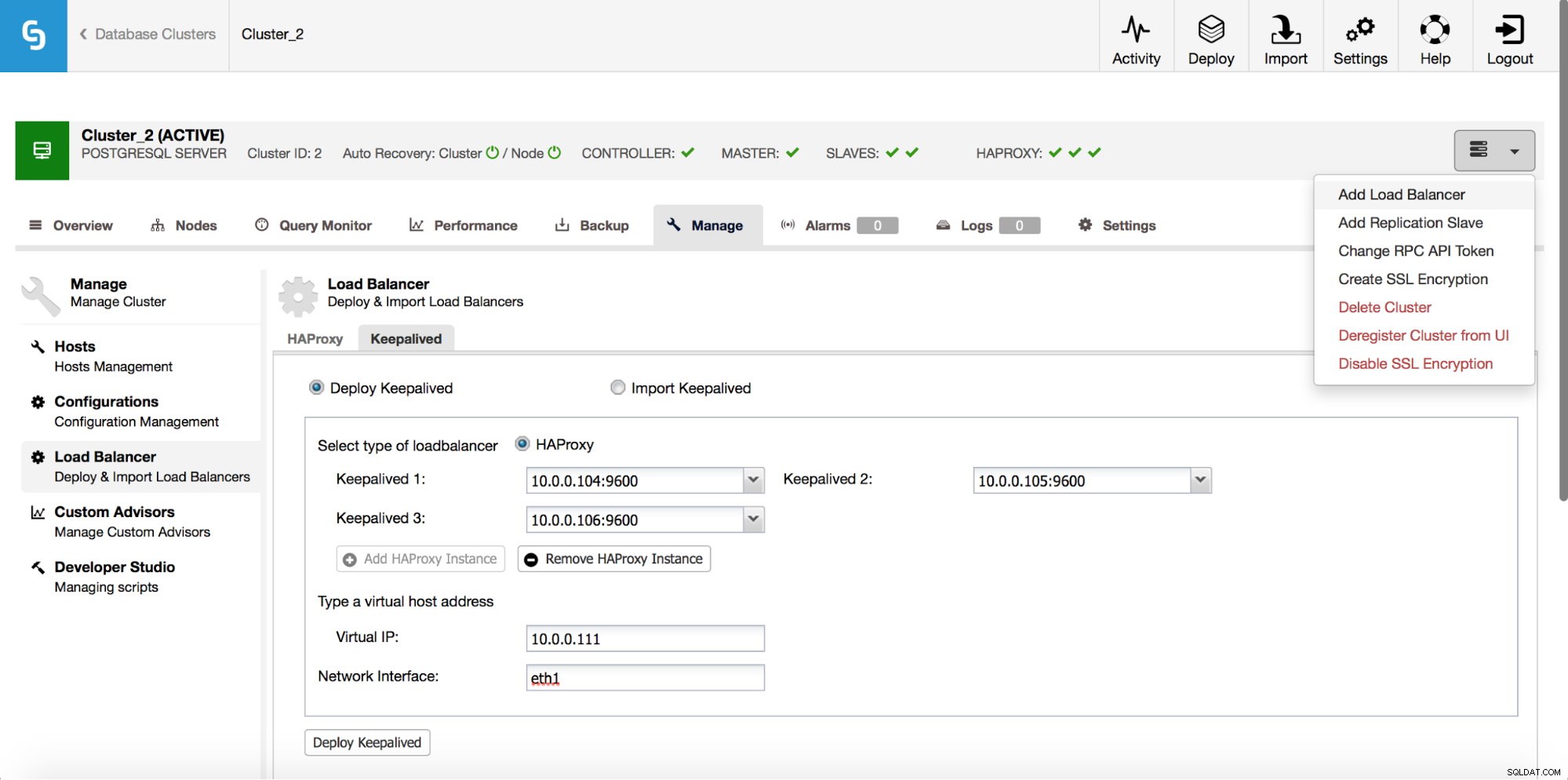
Wie wir im obigen Screenshot sehen können, können Sie bis zu drei HAProxy-Hosts auswählen und Keepalived wird auf ihnen bereitgestellt und überwacht ihren Zustand. Einem von ihnen wird eine virtuelle IP (VIP) zugewiesen. Ihre Anwendung sollte diese VIP verwenden, um eine Verbindung zur Datenbank herzustellen. Wenn der „aktive“ HAProxy nicht mehr verfügbar ist, wird VIP auf einen anderen Host verschoben.
Wie wir gesehen haben, ist es recht einfach, einen vollständigen Hochverfügbarkeits-Stack für PostgreSQL bereitzustellen. Probieren Sie es aus und lassen Sie uns wissen, wenn Sie Feedback haben.



