Die Speicherverwaltung in PostgreSQL ist wichtig, um die Leistung des Datenbankservers zu verbessern. Die PostgreSQL-Konfigurationsdatei (postgres.conf) verwaltet die Konfiguration des Datenbankservers. Es verwendet Standardwerte der Parameter, aber wir können diese Werte ändern, um die Arbeitslast und die Betriebsumgebung besser widerzuspiegeln.
In diesem Blog behandeln wir diese speicherbezogenen Parameter. Aber bevor wir beginnen, werfen wir einen Blick auf die Speicherarchitektur in PostgreSQL.
Speicherarchitektur
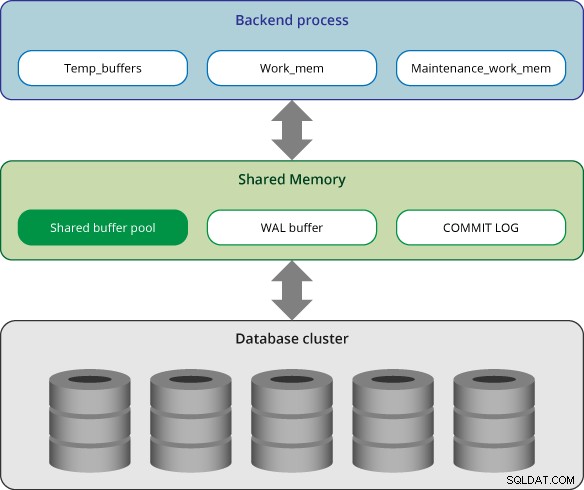
Arbeitsspeicher in PostgreSQL kann in zwei Kategorien eingeteilt werden:
- Lokaler Speicherbereich:Er wird von jedem Backend-Prozess für seinen eigenen Gebrauch zugewiesen.
- Gemeinsamer Speicherbereich:Er wird von allen Prozessen eines PostgreSQL-Servers verwendet.
Lokaler Speicherbereich
In PostgreSQL weist jeder Backend-Prozess lokalen Speicher für die Abfrageverarbeitung zu; Jeder Bereich ist in Unterbereiche unterteilt, deren Größe entweder fest oder variabel ist.
Die Unterbereiche sind wie folgt.
Work_mem
Der Ausführende verwendet diesen Bereich zum Sortieren von Tupeln nach ORDER BY- und DISTINCT-Operationen. Es verwendet es auch zum Verbinden von Tabellen durch Merge-Join- und Hash-Join-Operationen.
Maintenance_work_mem
Dieser Parameter wird für einige Arten von Wartungsvorgängen (VACUUM, REINDEX) verwendet.
Temp_buffers
Der Executor verwendet diesen Bereich zum Speichern temporärer Tabellen.
Gemeinsamer Speicherbereich
Der gemeinsam genutzte Speicherbereich wird vom PostgreSQL-Server beim Start zugewiesen. Dieser Bereich ist in mehrere Teilbereiche fester Größe unterteilt.
Gemeinsamer Pufferpool
PostgreSQL lädt Seiten innerhalb von Tabellen und Indizes aus dem persistenten Speicher in einen gemeinsam genutzten Pufferpool und bearbeitet sie dann direkt.
WAL-Puffer
PostgreSQL unterstützt den WAL-Mechanismus (Write ahead log), um sicherzustellen, dass nach einem Serverausfall keine Daten verloren gehen. WAL-Daten sind eigentlich ein Transaktionsprotokoll in PostgreSQL und WAL-Puffer ist ein Pufferbereich der WAL-Daten, bevor sie in einen dauerhaften Speicher geschrieben werden.
Commit-Protokoll
Das Festschreibungsprotokoll (CLOG) hält die Zustände aller Transaktionen und ist Teil des Parallelitätssteuermechanismus. Das Commit-Protokoll wird dem gemeinsam genutzten Speicher zugewiesen und während der gesamten Transaktionsverarbeitung verwendet.
PostgreSQL definiert die folgenden vier Transaktionszustände.
- IN_PROGRESS
- VERPFLICHTET
- ABGEBROCHEN
- UNTERVERPFLICHTET
Einstellung der PostgreSQL-Speicherparameter
Es gibt einige wichtige Parameter, die für die Speicherverwaltung in PostgreSQL empfohlen werden. Sie sollten Folgendes berücksichtigen.
Shared_buffers
Dieser Parameter gibt die Speichermenge an, die für gemeinsam genutzte Speicherpuffer verwendet wird. Der Parameter shared_buffers bestimmt, wie viel Speicher dem Server zum Zwischenspeichern von Daten zugewiesen wird. Der Standardwert von shared_buffers ist normalerweise 128 Megabyte (128 MB).
Der Standardwert dieses Parameters ist sehr niedrig, da auf einigen Plattformen wie älteren Solaris-Versionen und SGI große Werte eine invasive Aktion wie das Neukompilieren des Kernels erfordern. Selbst auf den modernen Linux-Systemen wird der Kernel wahrscheinlich nicht zulassen, dass shared_buffers auf über 32 MB gesetzt wird, ohne vorher die Kernel-Einstellungen anzupassen.
Der Mechanismus hat sich in PostgreSQL 9.4 und höher geändert, sodass Kernel-Einstellungen dort nicht angepasst werden müssen.
Wenn der Datenbankserver stark ausgelastet ist, verbessert die Einstellung eines hohen Werts die Leistung.
Wenn Sie einen dedizierten DB-Server mit 1 GB oder mehr RAM haben, ist ein vernünftiger Startwert für den Konfigurationsparameter shared_buffer 25 % des Arbeitsspeichers in Ihrem System.
Standardwert von shared_buffers =128 MB. Die Änderung erfordert einen Neustart des PostgreSQL-Servers.
Die allgemeine Empfehlung zum Setzen der shared_buffers lautet wie folgt.
- Legen Sie unter 2 GB Arbeitsspeicher den Wert von shared_buffers auf 20 % des gesamten Systemspeichers fest.
- Legen Sie unter 32 GB Arbeitsspeicher den Wert von shared_buffers auf 25 % des gesamten Systemspeichers fest.
- Legen Sie über 32 GB Arbeitsspeicher den Wert von shared_buffers auf 8 GB fest
Work_mem
Dieser Parameter gibt die Speichermenge an, die von internen Sortiervorgängen und Hash-Tabellen verwendet werden soll, bevor in temporäre Festplattendateien geschrieben wird. Wenn viele komplexe Sortiervorgänge stattfinden und Sie über genügend Arbeitsspeicher verfügen, ermöglicht die Erhöhung des work_mem-Parameters PostgreSQL, größere Sortiervorgänge im Arbeitsspeicher durchzuführen, die schneller sind als festplattenbasierte Äquivalente.
Beachten Sie, dass bei einer komplexen Abfrage möglicherweise viele Sortier- oder Hash-Vorgänge parallel ausgeführt werden. Jede Operation darf so viel Speicher verwenden, wie dieser Wert angibt, bevor sie beginnt, Daten in die temporären Dateien zu schreiben. Es besteht die Möglichkeit, dass mehrere Sitzungen solche Operationen gleichzeitig ausführen. Daher kann der verwendete Gesamtspeicher ein Vielfaches des Wertes des Parameters work_mem betragen.
Bitte denken Sie daran, wenn Sie den richtigen Wert auswählen. Sortieroperationen werden für ORDER BY-, DISTINCT- und Merge-Joins verwendet. Hash-Tabellen werden in Hash-Joins, Hash-basierter Verarbeitung von IN-Unterabfragen und Hash-basierter Aggregation verwendet.
Der Parameter log_temp_files kann verwendet werden, um Sortierungen, Hashes und temporäre Dateien zu protokollieren, was nützlich sein kann, um herauszufinden, ob Sortierungen auf die Festplatte übertragen werden, anstatt in den Speicher zu passen. Mit EXPLAIN ANALYZE-Plänen können Sie überprüfen, welche Sortierungen auf die Festplatte überlaufen. Wenn Sie beispielsweise in der Ausgabe von EXPLAIN ANALYZE die folgende Zeile sehen:„Sortiermethode:externe Zusammenführungsfestplatte:7528 KB “, würde ein work_mem von mindestens 8 MB die Zwischendaten im Speicher halten und die Antwortzeit auf Abfragen verbessern.
Der Standardwert von work_mem =4 MB.
Die allgemeine Empfehlung zum Festlegen von work_mem lautet wie folgt.
- Beginnen Sie mit einem niedrigen Wert:32–64 MB
- Suchen Sie dann in den Protokollen nach „temporären Datei“-Zeilen
- Auf das 2- bis 3-fache der größten temporären Datei einstellen
Wartung _work_mem
Dieser Parameter gibt die maximale Speichermenge an, die von Wartungsvorgängen wie VACUUM, CREATE INDEX und ALTER TABLE ADD FOREIGN KEY verwendet wird. Da jeweils nur eine dieser Operationen von einer Datenbanksitzung ausgeführt werden kann und bei einer PostgreSQL-Installation nicht viele davon gleichzeitig ausgeführt werden, ist es sicher, den Wert von maintenance_work_mem deutlich größer als work_mem festzulegen.
Das Festlegen eines höheren Werts kann die Leistung beim Vakuumieren und Wiederherstellen von Datenbank-Dumps verbessern.
Denken Sie daran, dass beim Ausführen von Autovacuum bis zu autovacuum_max_workers-mal dieser Speicher zugewiesen werden kann. Achten Sie also darauf, den Standardwert nicht zu hoch einzustellen.
Der Standardwert von maintenance_work_mem =64 MB.
Die allgemeine Empfehlung zum Festlegen von maintenance_work_mem lautet wie folgt.
- Stellen Sie den Wert auf 10 % des Systemspeichers ein, bis zu 1 GB
- Vielleicht können Sie es noch höher einstellen, wenn Sie VAKUUM-Probleme haben
Effective_cache_size
Die Effective_cache_size sollte auf eine Schätzung festgelegt werden, wie viel Speicher für das Festplatten-Caching durch das Betriebssystem und in der Datenbank selbst verfügbar ist. Dies ist eine Richtlinie dafür, wie viel Arbeitsspeicher Sie voraussichtlich in den Puffer-Caches des Betriebssystems und von PostgreSQL zur Verfügung haben, keine Zuordnung.
Der PostgreSQL-Abfrageplaner verwendet diesen Wert, um herauszufinden, ob die in Betracht gezogenen Pläne voraussichtlich in den Arbeitsspeicher passen oder nicht. Wenn es zu niedrig eingestellt ist, werden Indizes möglicherweise nicht zum Ausführen von Abfragen verwendet, wie Sie es erwarten würden. Da die meisten Unix-Systeme beim Caching ziemlich aggressiv sind, sind mindestens 50 % des verfügbaren RAM auf einem dedizierten Datenbankserver mit zwischengespeicherten Daten gefüllt.
Die allgemeine Empfehlung für Effective_Cache_Size lautet wie folgt.
- Setzen Sie den Wert auf die Menge an verfügbarem Dateisystem-Cache
- Wenn Sie es nicht wissen, setzen Sie den Wert auf 50 % des gesamten Systemspeichers
Der Standardwert von Effective_Cache_Size =4 GB.
Temp_buffers
Dieser Parameter legt die maximale Anzahl temporärer Puffer fest, die von jeder Datenbanksitzung verwendet werden. Die lokalen Sitzungspuffer werden nur für den Zugriff auf temporäre Tabellen verwendet. Die Einstellung dieses Parameters kann innerhalb einzelner Sitzungen geändert werden, jedoch nur vor der ersten Verwendung von temporären Tabellen innerhalb der Sitzung.
Die PostgreSQL-Datenbank verwendet diesen Speicherbereich zum Halten der temporären Tabellen jeder Sitzung, diese werden gelöscht, wenn die Verbindung geschlossen wird.
Der Standardwert von temp_buffer =8 MB.
Schlussfolgerung
Das Verständnis der Speicherarchitektur und die Abstimmung der entsprechenden Parameter ist wichtig, um die Leistung zu verbessern. Dies ist insbesondere für Systeme mit hoher Arbeitslast erforderlich. Weitere allgemeine Tipps zur Leistungsoptimierung finden Sie in diesem Leistungs-Spickzettel für PostgreSQL.