PostgreSQL ist eine der Datenbanken, die über ClusterControl bereitgestellt werden können, zusammen mit MySQL, MariaDB und MongoDB. ClusterControl vereinfacht nicht nur die Bereitstellung des Datenbank-Clusters, sondern hat auch eine Skalierbarkeitsfunktion, falls Ihre Anwendung wächst und diese Funktionalität benötigt.
Durch die Skalierung Ihrer Datenbank läuft Ihre Anwendung viel reibungsloser und besser, falls die Anwendungslast oder der Datenverkehr zunimmt. In diesem Blogbeitrag werden wir die Schritte zur Bereitstellung und Skalierung von PostgreSQL v13 mit ClusterControl 1.8.2 überprüfen.
Bereitstellung der Benutzeroberfläche (UI)
Es gibt zwei Arten der Bereitstellung in ClusterControl, Web User Interface (UI) sowie Command Line Interface (CLI). Der Benutzer hat die Freiheit, je nach Vorlieben und Bedarf eine der Bereitstellungsoptionen auszuwählen. Beide Optionen sind einfach nachzuvollziehen und in unserer Dokumentation gut dokumentiert. In diesem Abschnitt werden wir den Bereitstellungsprozess mit der ersten Option – der Web-Benutzeroberfläche – durchgehen.
Der erste Schritt besteht darin, sich bei Ihrem ClusterControl anzumelden und auf Deploy:
zu klicken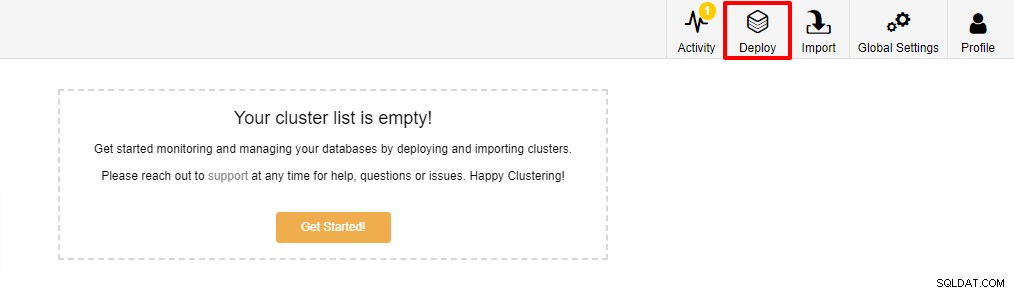
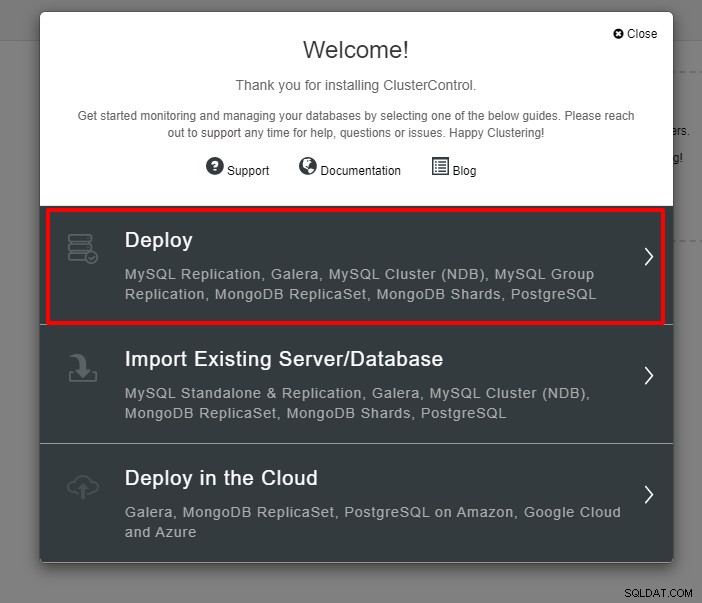
Der folgende Screenshot zeigt den nächsten Schritt der Bereitstellung , wählen Sie die Registerkarte PostgreSQL, um fortzufahren:
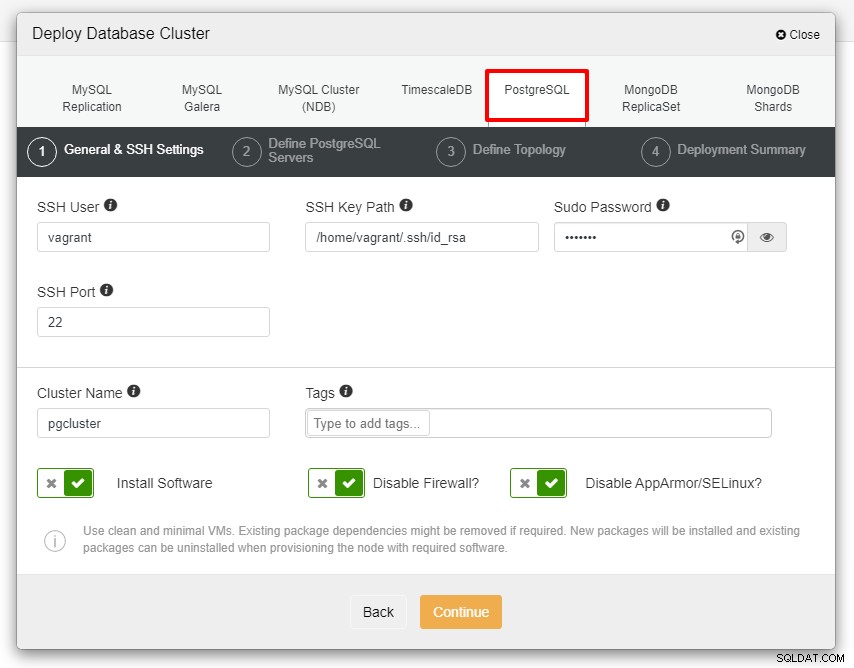
Bevor wir weitermachen, möchte ich Sie daran erinnern, dass die Verbindung zwischen der ClusterControl-Knoten und die Datenbankknoten müssen passwortlos sein. Vor der Bereitstellung müssen wir lediglich das ssh-keygen vom ClusterControl-Knoten generieren und es dann auf alle Knoten kopieren. Füllen Sie die Eingabe für den SSH-Benutzer, das Sudo-Passwort sowie den Clusternamen gemäß Ihren Anforderungen aus und klicken Sie auf Weiter.
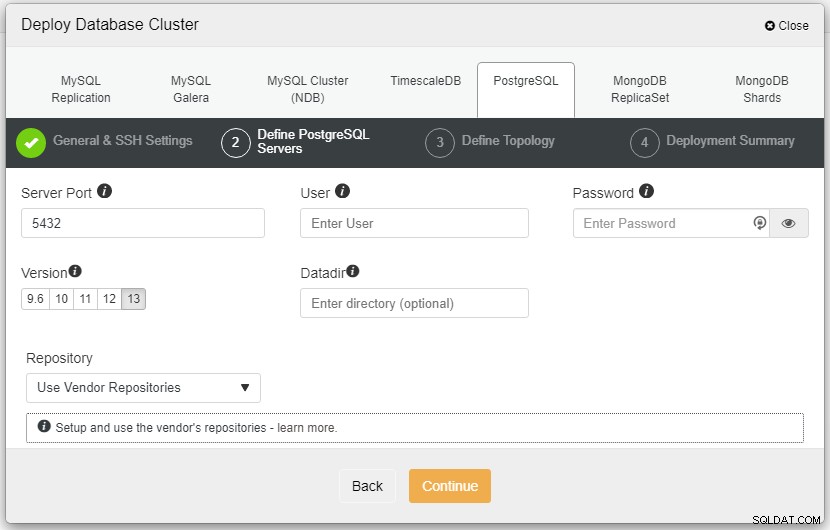
Im obigen Screenshot müssen Sie den Server-Port (in falls Sie andere verwenden möchten), den gewünschten Benutzer sowie das Passwort und stellen Sie sicher, dass Sie Version 13 auswählen, die Sie installieren möchten.
 FotoautorFotobeschreibung
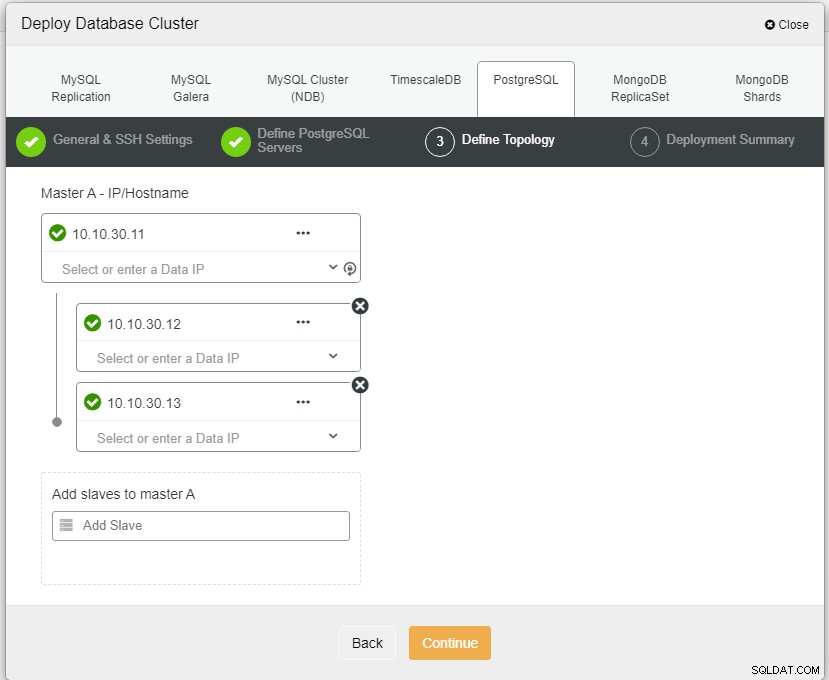
FotoautorFotobeschreibungHier müssen wir die Server entweder über den Hostnamen definieren oder die IP-Adresse, wie in diesem Fall 1 Master und 2 Slaves. Der letzte Schritt besteht darin, den Replikationsmodus für unseren Cluster auszuwählen.
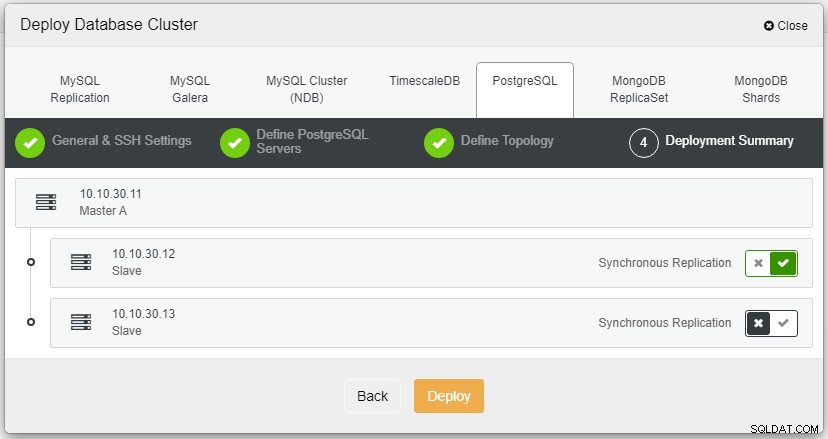
Nachdem Sie auf „Bereitstellen“ geklickt haben, wird der Bereitstellungsprozess gestartet und wir können ihn überwachen Fortschritt auf der Registerkarte "Aktivität".
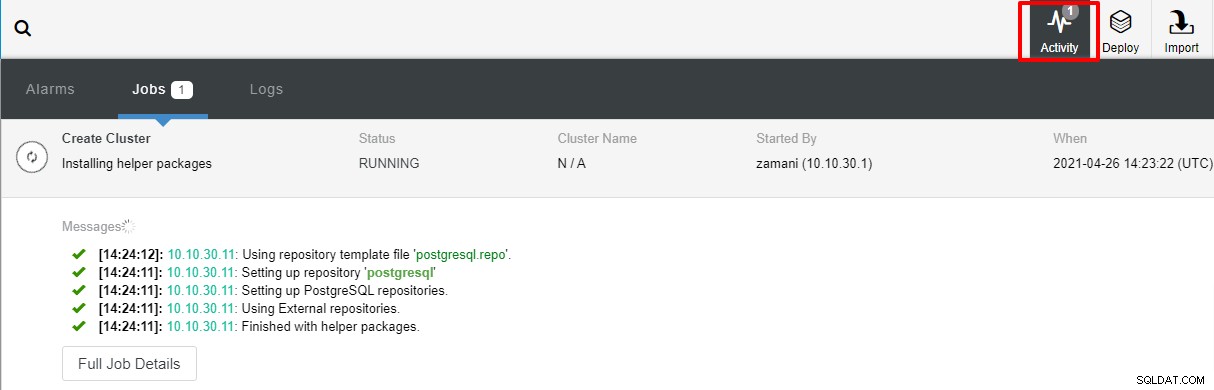
Die Bereitstellung dauert normalerweise einige Minuten, die Leistung hängt hauptsächlich von der Netzwerk und die Spezifikation des Servers.

Nun, da wir PostgreSQL v13 mit ClusterControl GUI installiert haben, was ziemlich einfach ist .
Befehlszeilenschnittstelle (CLI) PostgreSQL-Bereitstellung
Aus dem Obigen können wir ersehen, dass die Bereitstellung über die Web-Benutzeroberfläche ziemlich einfach ist. Der wichtige Hinweis ist, dass alle Knoten vor der Bereitstellung passwortlose SSH-Verbindungen haben müssen. In diesem Abschnitt werden wir sehen, wie die Bereitstellung mithilfe der Befehlszeile der ClusterControl-CLI oder der „s9s“-Tools erfolgt.
Wir sind davon ausgegangen, dass ClusterControl zuvor installiert wurde, beginnen wir mit der Generierung des ssh-keygen. Führen Sie im ClusterControl-Knoten die folgenden Befehle aus:
$ whoami
root
$ ssh-keygen -t rsa # generate the SSH key for the user
$ ssh-copy-id 10.10.40.11 # pg node1
$ ssh-copy-id 10.10.40.12 # pg node2
$ ssh-copy-id 10.10.40.13 # pg node3Sobald alle obigen Befehle erfolgreich ausgeführt wurden, können wir die passwortlose Verbindung mit dem folgenden Befehl überprüfen:
$ ssh 10.10.40.11 "whoami" # make sure can ssh without passwordWenn der obige Befehl erfolgreich ausgeführt wird, kann das Cluster-Deployment vom ClusterControl-Server aus mit der folgenden Befehlszeile gestartet werden:
$ s9s cluster --create --cluster-type=postgresql --nodes="10.10.40.11?master;10.10.40.12?slave;10.10.40.13?slave" --provider-version='13' --db-admin="postgres" --db-admin-passwd="example@sqldat.com$$W0rd" --cluster-name=PGCluster --os-user=root --os-key-file=/root/.ssh/id_rsa --logGleich nachdem Sie den obigen Befehl ausgeführt haben, sehen Sie so etwas wie das Folgende, was bedeutet, dass die Aufgabe begonnen hat zu laufen:
Cluster wird auf 3 Datenknoten erstellt.
Job-Parameter überprüfen.
10.10.40.11: Checking ssh/sudo with credentials ssh_cred_job_6656.
10.10.40.12: Checking ssh/sudo with credentials ssh_cred_job_6656.
10.10.40.13: Checking ssh/sudo with credentials ssh_cred_job_6656.
…
…
This will take a few moments and the following message will be displayed once the cluster is deployed:
…
…
Directory is '/etc/cmon.d'.
Filename is 'cmon_1.cnf'.
Configuration written to 'cmon_1.cnf'.
Sending SIGHUP to the controller process.
Waiting until the initial cluster starts up.
Cluster 1 is running.
Registering the cluster on the web UI.
Waiting until the initial cluster starts up.
Cluster 1 is running.
Generated & set RPC authentication token.
Sie können dies auch überprüfen, indem Sie sich mit dem von Ihnen erstellten Benutzernamen bei der Webkonsole anmelden. Jetzt haben wir einen PostgreSQL-Cluster mit 3 Knoten bereitgestellt. Wenn Sie mehr über den obigen Bereitstellungsbefehl erfahren möchten, ist hier die beste Referenz für Sie.
Hochskalieren von PostgreSQL mit der ClusterControl-Benutzeroberfläche
PostgreSQL ist eine relationale Datenbank und wir wissen, dass die Skalierung dieser Art von Datenbank im Vergleich zu einer nicht relationalen Datenbank nicht einfach ist. Heutzutage benötigen die meisten Anwendungen Skalierbarkeit, um eine bessere Leistung und Geschwindigkeit bereitzustellen. Abhängig von Ihrer Infrastruktur und Umgebung gibt es viele Möglichkeiten, wie Sie dies implementieren können.
Skalierbarkeit ist eine der Funktionen, die durch ClusterControl unterstützt werden können und sowohl über die UI als auch über die CLI erreicht werden kann. In diesem Abschnitt werden wir sehen, wie wir PostgreSQL mithilfe der ClusterControl-Benutzeroberfläche skalieren können. Der erste Schritt besteht darin, sich bei Ihrer Benutzeroberfläche anzumelden und den Cluster auszuwählen. Sobald der Cluster ausgewählt ist, können Sie auf die Option wie im folgenden Screenshot klicken:
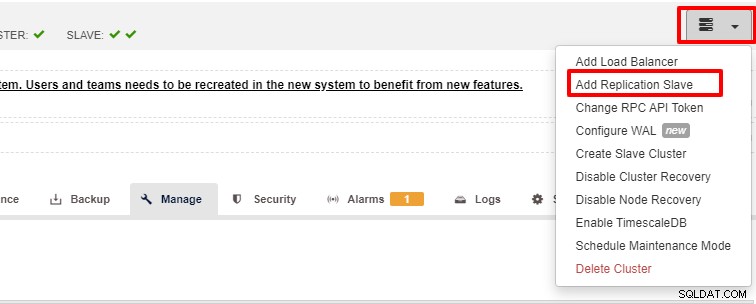
Nachdem Sie auf „Add Replication Slave“ geklickt haben, sehen Sie die folgende Seite . Sie können je nach Situation entweder „Neu hinzufügen…“ oder „Importieren…“ auswählen. In diesem Beispiel wählen wir die erste Option:
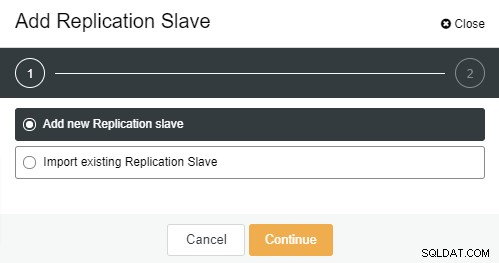
Der folgende Bildschirm wird angezeigt, sobald Sie darauf geklickt haben:
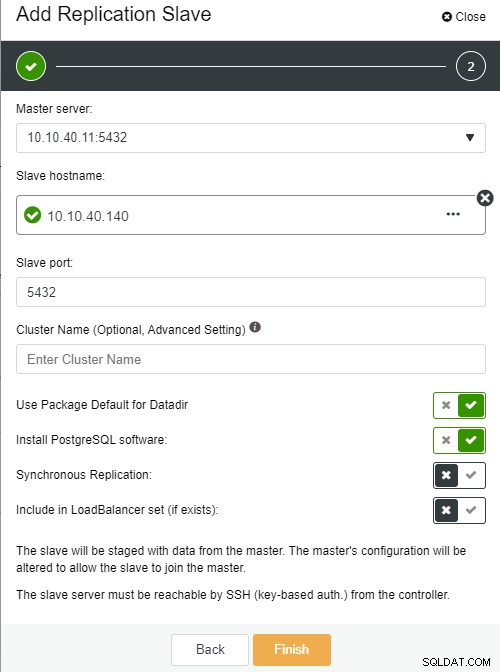 FotoautorFotobeschreibung
FotoautorFotobeschreibung-
Slave-Hostname:der Hostname/die IP-Adresse des neuen Slaves oder Knotens
-
Slave-Port:der PostgreSQL-Port des Slaves, Standard ist 5432
-
Clustername:Der Name des Clusters, Sie können ihn entweder hinzufügen oder leer lassen
-
Paketstandard für Datadir verwenden:Sie können diese Option aktivieren oder deaktivieren, wenn Sie einen anderen Speicherort haben möchten für Datadir
-
PostgreSQL-Software installieren:Sie können diese Option aktiviert lassen
-
Synchrone Replikation:Sie können wählen, welche Art von Replikation Sie hier wünschen
-
In LoadBalancer-Set aufnehmen (falls vorhanden):Diese Option muss aktiviert werden, wenn Sie LoadBalancer für den Cluster konfiguriert haben
Der wichtigste wichtige Hinweis hier ist, dass Sie den neuen Slave-Host so konfigurieren müssen, dass er passwortlos ist, bevor Sie dieses Setup ausführen können. Sobald alles bestätigt ist, können wir auf die Schaltfläche „Fertig stellen“ klicken, um die Einrichtung abzuschließen. In diesem Beispiel habe ich die IP „10.10.40.140“ hinzugefügt.
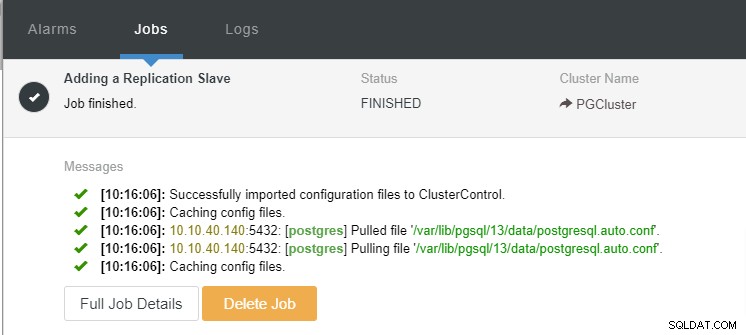
Wir können jetzt die Auftragsaktivität überwachen und die Einrichtung abschließen. Um die Einrichtung zu bestätigen, können wir auf die Registerkarte „Topologie“ gehen, um den neuen Slave zu sehen:
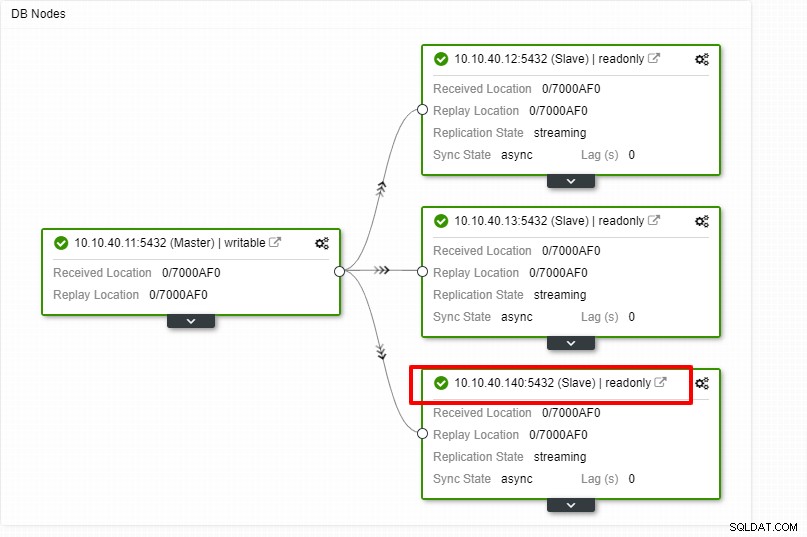
Skalieren von PostgreSQL mit ClusterControl CLI
Das Hinzufügen der neuen Knoten zum bestehenden Cluster ist mit der CLI sehr einfach. Führen Sie vom Controller-Knoten aus den folgenden Befehl aus. Der erste Befehl besteht darin, den Cluster zu identifizieren, zu dem wir den neuen Knoten hinzufügen möchten:
$ s9s cluster --list --long
ID STATE TYPE OWNER GROUP NAME COMMENT
1 STARTED postgresql_single admin admins PGCluster All nodes are operational.In diesem Beispiel können wir sehen, dass die Knoten-ID „1“ für den Clusternamen „PGCluster“ ist. Sehen Sie sich die erste Befehlsoption zum Hinzufügen eines neuen Knotens zum vorhandenen PostgreSQL-Cluster an:
$ s9s cluster --add-node --cluster-id=1 --nodes="postgresql://10.10.40.141?slave" --logDie Abkürzung „--log“ am Ende der Zeile lässt uns sehen, was die aktuelle Aufgabe ist, die nach dem unten ausgeführten Befehl ausgeführt wird:
Using SSH credentials from cluster.
Cluster ID is 1.
The username is 'root'.
Verifying job parameters.
Found a master candidate: 10.10.40.11:5432, adding 10.10.40.141:5432 as a slave.
Verifying job parameters.
10.10.40.11: Checking ssh/sudo with credentials ssh_cred_cluster_1_6245.
10.10.40.11:5432: Loading configuration file '/var/lib/pgsql/13/data/postgresql.conf'.
10.10.40.11:5432: wal_keep_segments is set to 0, increase this for safer replication.
…
…Der nächste verfügbare Befehl, den Sie verwenden können, sieht folgendermaßen aus:
$ s9s cluster --add-node --cluster-id=1 --nodes="postgresql://10.10.40.142?slave" --waitKnoten zum Cluster hinzufügen
\ Job 9 RUNNING [▋ ] 5% Installing packagesBeachten Sie, dass in der Zeile die Abkürzung „--wait“ steht und die Ausgabe, die Sie sehen werden, wie oben angezeigt wird. Sobald der Vorgang abgeschlossen ist, können wir die neuen Knoten auf der Registerkarte „Übersicht“ des Clusters auf der Benutzeroberfläche bestätigen:
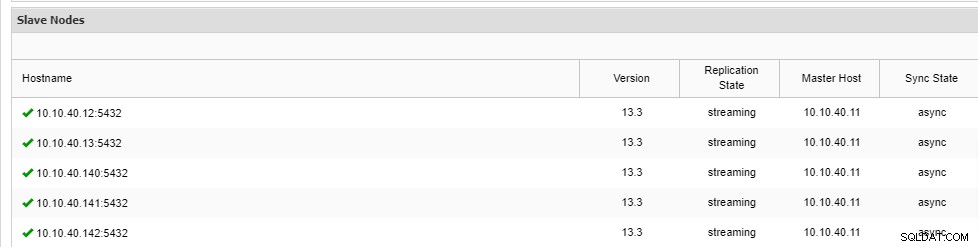
Fazit
In diesem Blogbeitrag haben wir zwei Optionen zum horizontalen Hochskalieren von PostgreSQL in ClusterControl besprochen. Wie Sie vielleicht bemerkt haben, ist das Hochskalieren von PostgreSQL mit ClusterControl einfach. ClusterControl kann nicht nur die Skalierbarkeit übernehmen, sondern Sie können auch ein Hochverfügbarkeits-Setup für Ihren Datenbank-Cluster erreichen. Funktionen wie HAProxy, PgBouncer sowie Keepalived sind verfügbar und bereit, für Ihren Cluster implementiert zu werden, wann immer Sie diese Optionen benötigen. Mit ClusterControl ist Ihr Datenbank-Cluster einfach zu verwalten und gleichzeitig zu überwachen.
Wir hoffen, dass dieser Blog-Beitrag Sie bei der horizontalen Skalierung Ihres PostgreSQL-Setups unterstützt.