AWS PostgreSQL-Dienste fallen unter das Dach von RDS, das Amazons DaaS-Angebot für alle bekannten Datenbank-Engines ist.
Verwaltete Datenbankdienste bieten bestimmte Vorteile, die für Kunden attraktiv sind, die Unabhängigkeit von der Wartung der Infrastruktur und hochverfügbare Konfigurationen suchen. Wie immer gibt es keine Einheitslösung. Die derzeit verfügbaren Optionen sind unten hervorgehoben:
Aurora PostgreSQL
Die FAQ-Seite von Amazon Aurora enthält wichtige Details, die berücksichtigt werden müssen, bevor Sie sich mit dem Produkt befassen. Beispielsweise erfahren wir, dass die Speicherebene virtualisiert ist und sich auf einem proprietären virtualisierten Speichersystem befindet, das von SSD gesichert wird.
Preise
In Bezug auf die Preise muss beachtet werden, dass Aurora PostgreSQL nicht im kostenlosen Kontingent von AWS verfügbar ist.
Kompatibilität
Dieselbe FAQ-Seite macht deutlich, dass Amazon keine 100-prozentige PostgreSQL-Kompatibilität beansprucht. Die meisten (meine Betonung) der Anwendungen wird in Ordnung sein, z.B. die AWS PostgreSQL-Variante ist Wire-kompatibel mit PostgreSQL 9.6. Als Ergebnis wird der Wireshark PostgreSQL Dissector problemlos funktionieren.
Leistung
Die Leistung ist auch mit dem Instanztyp verknüpft, beispielsweise wird die maximale Anzahl von Verbindungen standardmäßig basierend auf der Instanzgröße konfiguriert.
Ebenfalls wichtig in Bezug auf die Kompatibilität ist die Seitengröße, die bei 8 KiB gehalten wurde, was die Standardseitengröße von PostgreSQL ist. Apropos Seiten, es lohnt sich, die FAQ zu zitieren:„Im Gegensatz zu herkömmlichen Datenbank-Engines schiebt Amazon Aurora niemals modifizierte Datenbankseiten auf die Speicherebene, was zu weiteren Einsparungen beim IO-Verbrauch führt. ” Dies wird möglich, weil Amazon die Art und Weise geändert hat, wie der Seiten-Cache verwaltet wird, sodass er im Falle eines Datenbankausfalls im Speicher bleiben kann. Diese Funktion kommt auch dem Neustart der Datenbank nach einem Absturz zugute, wodurch die Wiederherstellung viel schneller erfolgen kann als bei der herkömmlichen Methode der Wiedergabe der Protokolle.
Gemäß den oben genannten häufig gestellten Fragen liefert Aurora PostgreSQL die dreifache Leistung von PostgreSQL bei SELECT- und UPDATE-Operationen. Laut Amazons PostgreSQL Benchmark White Paper waren die Tools, die zur Messung der Leistung verwendet wurden, pgbench und sysbench. Bemerkenswert ist die Leistungsabhängigkeit vom Instance-Typ, der Regionsauswahl und der Netzwerkleistung. Sie fragen sich, warum INSERT nicht erwähnt wird? Dies liegt daran, dass die PostgreSQL-ACID-Konformität (das „C“) erfordert, dass ein aktualisierter Datensatz mit einer Löschung gefolgt von einer Einfügung erstellt wird.
Um die Leistungsverbesserungen voll auszuschöpfen, empfiehlt Amazon, Anwendungen so zu gestalten, dass sie mit der Datenbank über eine große Anzahl gleichzeitiger Abfragen und Transaktionen interagieren . Dieser wichtige Faktor wird oft übersehen, was zu einer schlechten Leistung führt, die der Implementierung zugeschrieben wird.
Grenzen
Bei der Planung der Migration sind einige Einschränkungen zu beachten:
-
huge_pages kann nicht geändert werden, ist jedoch standardmäßig aktiviert:
template1=> select aurora_version(); aurora_version ---------------- 1.0.11 (1 row) template1=> show huge_pages ; huge_pages ------------ on (1 row) - pg_hba kann nicht verwendet werden, da es einen Serverneustart erfordert. Nebenbei bemerkt, das muss ein Tippfehler in der Dokumentation von Amazon sein, da PostgreSQL nur neu geladen werden muss. Anstatt sich auf pg_hba zu verlassen, müssen Administratoren die AWS-Sicherheitsgruppen und PostgreSQL GRANT verwenden.
- PITR-Granularität beträgt 5 Minuten.
- Regionsübergreifende Replikation ist derzeit nicht für PostgreSQL verfügbar.
- Die maximale Größe von Tabellen beträgt 64 TiB
- Bis zu 15 Read Replicas
Skalierbarkeit
Das Herauf- und Herunterskalieren der Datenbankinstanz ist derzeit ein manueller Prozess, der über die AWS-Konsole oder CLI durchgeführt werden kann, obwohl die automatische Skalierung in Arbeit ist, jedoch laut Amazon Aurora-FAQ nur für MySQL verfügbar sein wird.
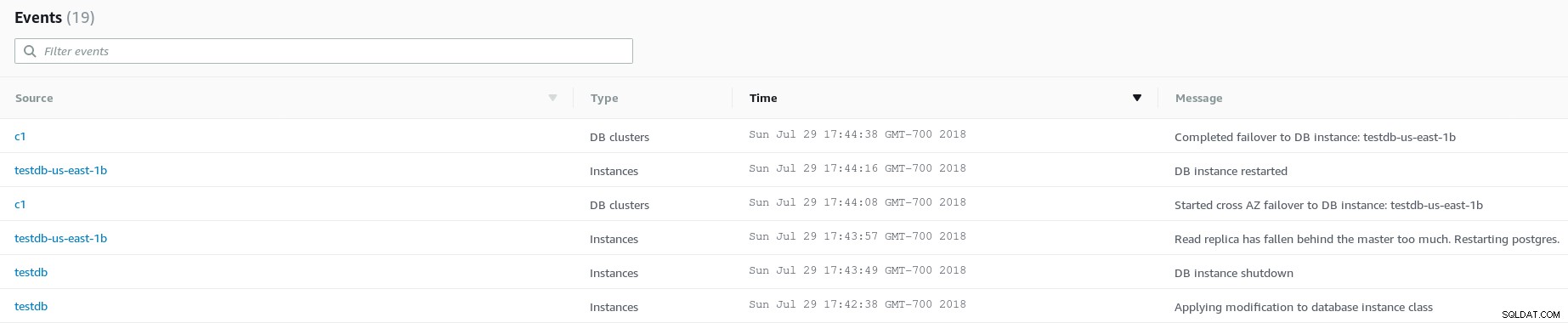 Skalierende Rechenressourcen für Ereignisprotokolle
Skalierende Rechenressourcen für Ereignisprotokolle Um horizontal zu skalieren, müssen Anwendungen AWS SDK-APIs nutzen, um beispielsweise ein schnelles Failover zu erreichen.
Hohe Verfügbarkeit
Weiter zur Hochverfügbarkeit:Im Falle eines Ausfalls des primären Knotens stellt Aurora PostgreSQL einen Cluster-Endpunkt als DNS-A-Eintrag bereit, der automatisch intern aktualisiert wird, um auf das Replikat zu verweisen, das als Master ausgewählt wurde.
Sicherungen
Erwähnenswert ist, dass beim Löschen der Datenbank alle manuellen Backup-Snapshots beibehalten werden, während automatische Snapshots entfernt werden.
Replikation
Da Replikate denselben zugrunde liegenden Speicher wie die primäre Instanz nutzen, liegt die Replikationsverzögerung theoretisch im Bereich von Millisekunden.
Amazon empfiehlt Read Replicas, um die Failover-Dauer zu verkürzen. Mit einer Read Replica im Standby-Modus dauert der Failover-Vorgang etwa 30 Sekunden, während ohne eine Replica bis zu 15 Minuten zu erwarten sind.
Eine weitere gute Nachricht ist, dass auch die logische Replikation unterstützt wird, wie auf Seite 22 gezeigt.
Obwohl die häufig gestellten Fragen zu Amazon Aurora keine Details zur Replikation wie für MySQL enthalten, bieten die Aurora PostgreSQL Best Practices eine nützliche Abfrage zur Überprüfung des Replikationsstatus:
select server_id, session_id, highest_lsn_rcvd,
cur_replay_latency_in_usec, now(), last_update_timestamp from
aurora_replica_status();Die obige Abfrage ergibt:
-[ RECORD 1 ]--------------+-------------------------------------
server_id | testdb
session_id | 9e268c62-9392-11e8-87fc-a926fa8340fe
highest_lsn_rcvd | 46640889
cur_replay_latency_in_usec | 8830
now | 2018-07-29 20:14:55.434701-07
last_update_timestamp | 2018-07-29 20:14:54-07
-[ RECORD 2 ]--------------+-------------------------------------
server_id | testdb-us-east-1b
session_id | MASTER_SESSION_ID
highest_lsn_rcvd |
cur_replay_latency_in_usec |
now | 2018-07-29 20:14:55.434701-07
last_update_timestamp | 2018-07-29 20:14:55-07Da die Replikation ein so wichtiges Thema ist, hat es sich gelohnt, den pgbench-Test einzurichten, wie im oben genannten Benchmark-Whitepaper beschrieben:
[example@sqldat.com ~]$ whoami
ec2-user
[example@sqldat.com ~]$ tail -n 2 .bashrc
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/pgsql/lib
export PATH=$PATH:/usr/local/pgsql/bin/
[example@sqldat.com ~]$ which pgbench
/usr/local/pgsql/bin/pgbench
[example@sqldat.com ~]$ pgbench --version
pgbench (PostgreSQL) 9.6.8Hinweis: Vermeiden Sie unnötiges Tippen, indem Sie eine pgpass-Datei erstellen und die Host-, Datenbank- und Benutzerumgebungsvariablen exportieren, z. B.:
[example@sqldat.com ~]# tail -n 3 ~/.bashrc export
PGUSER=dbadmin
export PGHOST=c1.cluster-ctfirtyhadgr.us-east-1.rds.amazonaws.com
export PGDATABASE=template1
[example@sqldat.com ~]# cat ~/.pgpass
*:*:*:dbadmin:passwordFühren Sie den Dateninitialisierungsbefehl aus:
[example@sqldat.com ~]$ pgbench -i --fillfactor=90 --scale=10000 postgresErfassen Sie während der Dateninitialisierung die Replikationsverzögerung mithilfe der obigen SQL, die aus dem folgenden Skript aufgerufen wird:
while : ; do
psql -t -q \
-c 'select server_id, session_id, highest_lsn_rcvd,
cur_replay_latency_in_usec, now(), last_update_timestamp
from aurora_replica_status();' postgres
sleep 1
doneFiltern der Bildschirmprotokollausgabe durch den folgenden Befehl:
[example@sqldat.com ~]# awk -F '|' '{print $4,$5,$6}' screenlog.2 | sort -k1,1 -n | tail
513116 2018-07-30 04:30:44.394729+00 2018-07-30 04:30:43+00
529294 2018-07-30 04:20:54.261741+00 2018-07-30 04:20:53+00
544139 2018-07-30 04:41:57.538566+00 2018-07-30 04:41:57+00
1001902 2018-07-30 04:42:54.80136+00 2018-07-30 04:42:53+00
2376951 2018-07-30 04:38:06.621681+00 2018-07-30 04:38:06+00
2376951 2018-07-30 04:38:07.672919+00 2018-07-30 04:38:07+00
5365719 2018-07-30 04:36:51.608983+00 2018-07-30 04:36:50+00
5365719 2018-07-30 04:36:52.912731+00 2018-07-30 04:36:51+00
6308586 2018-07-30 04:45:22.951966+00 2018-07-30 04:45:21+00
8210986 2018-07-30 04:46:14.575385+00 2018-07-30 04:46:13+00Es stellte sich heraus, dass die Replikation bis zu 8 Sekunden verzögert wurde!
In diesem Zusammenhang stimmt die AWS CloudWatch-Metrik AuroraReplicaLagMaximum nicht mit den Ergebnissen des obigen SQL-Befehls überein. Ich würde gerne wissen, warum, daher ist Feedback sehr willkommen.
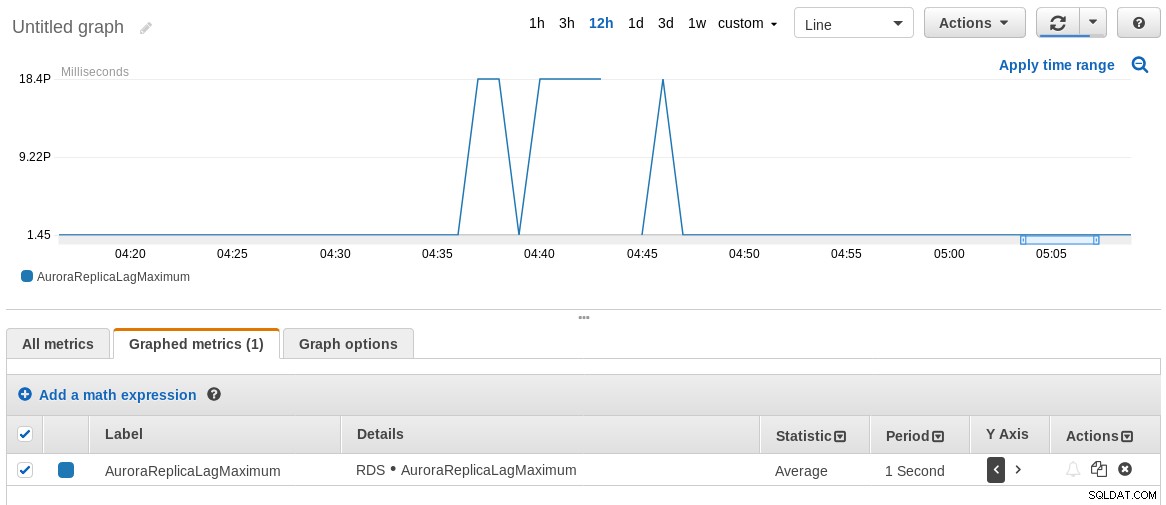 Diagramm zur maximalen Replikationsverzögerung von RDS CloudWatch
Diagramm zur maximalen Replikationsverzögerung von RDS CloudWatch Sicherheit
-
Die Verschlüsselung ist verfügbar und muss aktiviert werden, wenn die Datenbank erstellt wird, da sie nachträglich nicht mehr geändert werden kann.
Fehlerbehebung
Dieser kurze Abschnitt ist ein wichtiger Teil. Stellen Sie sicher, dass PostgreSQL work_mem richtig eingestellt ist, damit Sortiervorgänge keine Daten auf die Festplatte schreiben.
Einrichtung
Folgen Sie einfach dem Einrichtungsassistenten in der AWS-Konsole:
-
Öffnen Sie das Amazon RDS Verwaltungskonsole.
 RDS-Verwaltungskonsole
RDS-Verwaltungskonsole -
Wählen Sie Amazon Aurora aus und PostgreSQL Ausgabe.
 Aurora PostgreSQL-Assistent
Aurora PostgreSQL-Assistent -
Geben Sie die DB-Details an und beachten Sie die Aurora PostgreSQL-Passwortbeschränkungen:
Master Password must be at least eight characters long, as in "mypassword". Can be any printable ASCII character except "/", """, or "@". Details zur Aurora PostgreSQL-Assistentendatenbank
Details zur Aurora PostgreSQL-Assistentendatenbank -
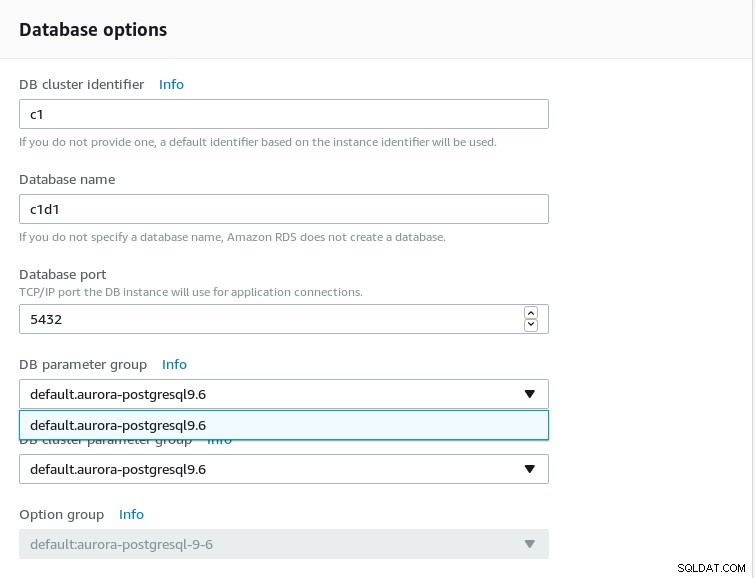
Konfigurieren Sie die Datenbankoptionen:
- Zum jetzigen Zeitpunkt ist nur PostgreSQL 9.6 verfügbar. Verwenden Sie PostgreSQL auf Amazon RDS, wenn Sie Unterstützung für neuere Versionen benötigen, einschließlich Beta-Vorschauen.
-
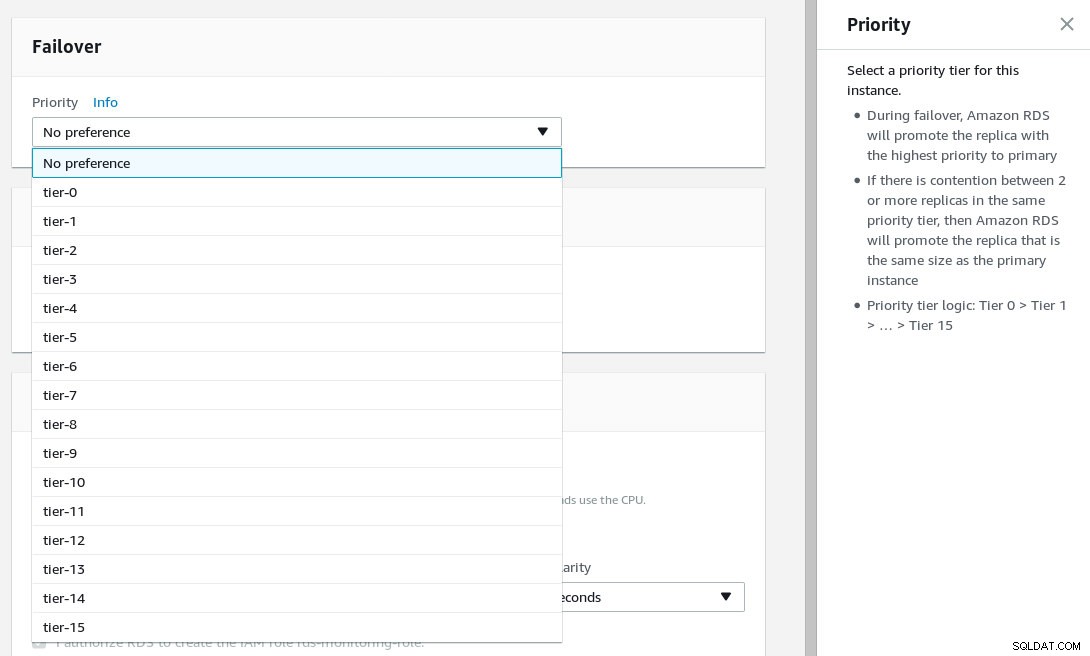
Konfigurieren Sie die Failover-Priorität und wählen Sie die Anzahl der Reproduktionen aus.
 Fotobeschreibung
Fotobeschreibung -
Legen Sie die Backup-Aufbewahrung fest (maximal 35 Tage).
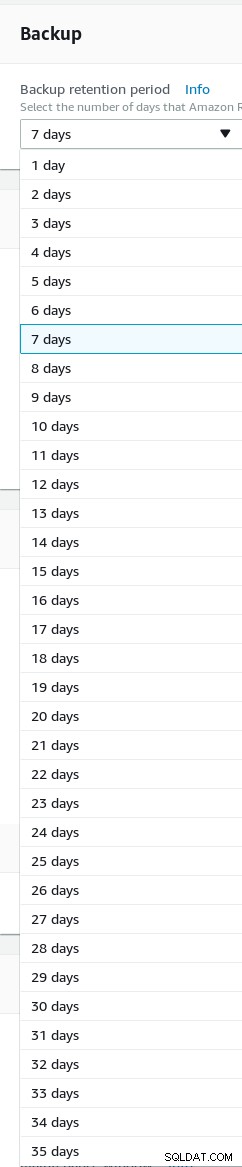 Aufbewahrung von Sicherungen des Aurora PostgreSQL-Assistenten
Aufbewahrung von Sicherungen des Aurora PostgreSQL-Assistenten -
Wählen Sie den Wartungsplan aus. Automatische Nebenversions-Upgrades sind verfügbar, es ist jedoch wichtig, mit dem AWS-Support zu überprüfen, ob der Patch-Zeitplan beschleunigt werden kann, falls das PostgreSQL-Projekt dringende Updates veröffentlicht. Beispielsweise dauerte es mehr als zwei Monate, bis AWS die Updates vom 10. Mai 2018 veröffentlichte.
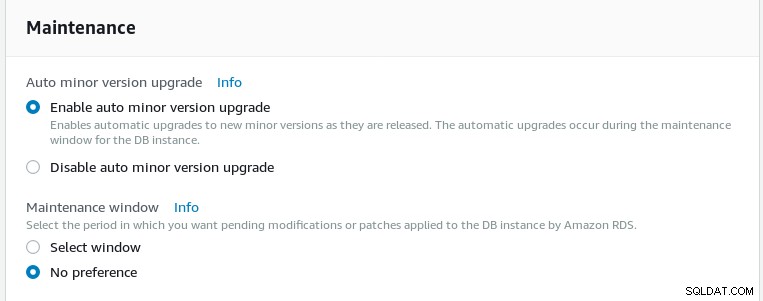 Wartungszeitplan für den Aurora PostgreSQL-Assistenten
Wartungszeitplan für den Aurora PostgreSQL-Assistenten -
Wenn die Datenbank erfolgreich erstellt wurde, wird ein Link zu Anweisungen zum Herstellen einer Verbindung angezeigt:
 Einrichtung des Aurora PostgreSQL-Assistenten abgeschlossen
Einrichtung des Aurora PostgreSQL-Assistenten abgeschlossen
Verbindung zur Datenbank herstellen
Lesen Sie detaillierte Anweisungen für verfügbare Verbindungsoptionen, basierend auf dem Infrastruktur-Setup. Im einfachsten Fall erfolgt die Anbindung über eine öffentliche EC2-Instanz.
Hinweis:Der Client muss mit PostgreSQL 9.6.3 oder höher kompatibel sein.
[example@sqldat.com ~]# psql -U dbadmin -h c1.cluster-ctfirtyhadgr.us-east-1.rds.amazonaws.com template1
Password for user dbadmin:
psql (9.6.8, server 9.6.3)
SSL connection (protocol: TLSv1.2, cipher: DHE-RSA-AES256-GCM-SHA384, bits: 256, compression: off)
Type "help" for help.Überwachung
Amazon stellt verschiedene Metriken zur Überwachung der Datenbank bereit, ein Beispiel unten zeigt Instanzmetriken:
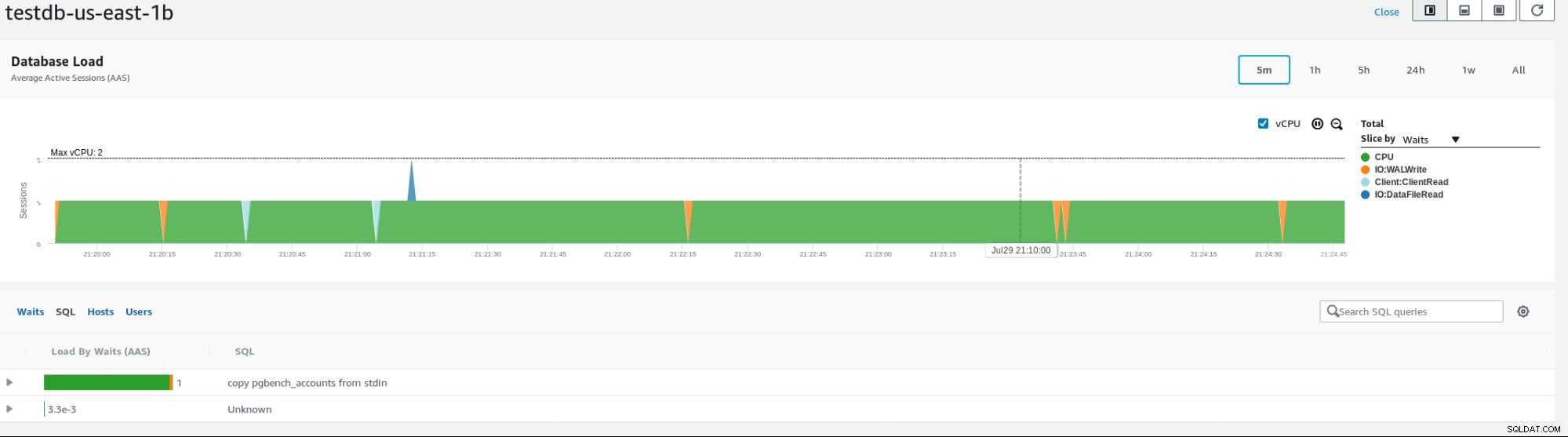 RDS-InstanzmetrikenLaden Sie noch heute das Whitepaper herunter PostgreSQL Management &Automation with ClusterControlErfahren Sie, was Sie wissen müssen, um bereitzustellen, zu überwachen, PostgreSQL verwalten und skalierenLaden Sie das Whitepaper herunter
RDS-InstanzmetrikenLaden Sie noch heute das Whitepaper herunter PostgreSQL Management &Automation with ClusterControlErfahren Sie, was Sie wissen müssen, um bereitzustellen, zu überwachen, PostgreSQL verwalten und skalierenLaden Sie das Whitepaper herunter RDS für PostgreSQL
Dies ist ein Angebot, das mehr Granularität in Bezug auf Konfigurationsoptionen ermöglicht. Im Gegensatz zu Aurora, das ein proprietäres Speichersystem verwendet, bietet RDS beispielsweise konfigurierbaren Speicher mit EBS-Volumes, die entweder Allzweck-SSD (GP2) oder bereitgestellte IOPS oder magnetisch (nicht empfohlen) sein können.
Um große Installationen zu unterstützen, die eine Anpassung erfordern, die im Aurora-Angebot nicht verfügbar ist, hat Amazon kürzlich die Best Practices-Empfehlungen veröffentlicht, die nur für RDS verfügbar sind.
Hochverfügbarkeit muss manuell konfiguriert werden (oder mit einem der bekannten AWS-Tools automatisiert werden) und es wird empfohlen, eine Multi-AZ-Bereitstellung einzurichten.
Die Replikation wird mithilfe der nativen PostgreSQL-Replikation implementiert.
Es gibt einige Einschränkungen für PostgreSQL-DB-Instances, die berücksichtigt werden müssen.
Unter Berücksichtigung der obigen Hinweise finden Sie hier eine exemplarische Vorgehensweise zum Einrichten einer RDS-PostgreSQL-Multi-AZ-Umgebung:
-
Über die RDS-Verwaltungskonsole Starten Sie den Assistenten
 RDS-PostgreSQL-Assistent
RDS-PostgreSQL-Assistent -
Wählen Sie zwischen einem Produktions- und einem Entwicklungs-Setup.
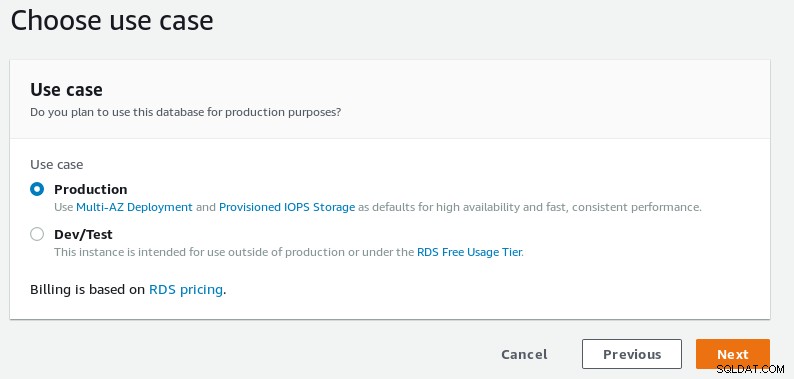 Anwendungsfallauswahl für die Datenbank des RDS-PostgreSQL-Assistenten
Anwendungsfallauswahl für die Datenbank des RDS-PostgreSQL-Assistenten -
Geben Sie die Details zu Ihrem neuen Datenbank-Cluster ein.
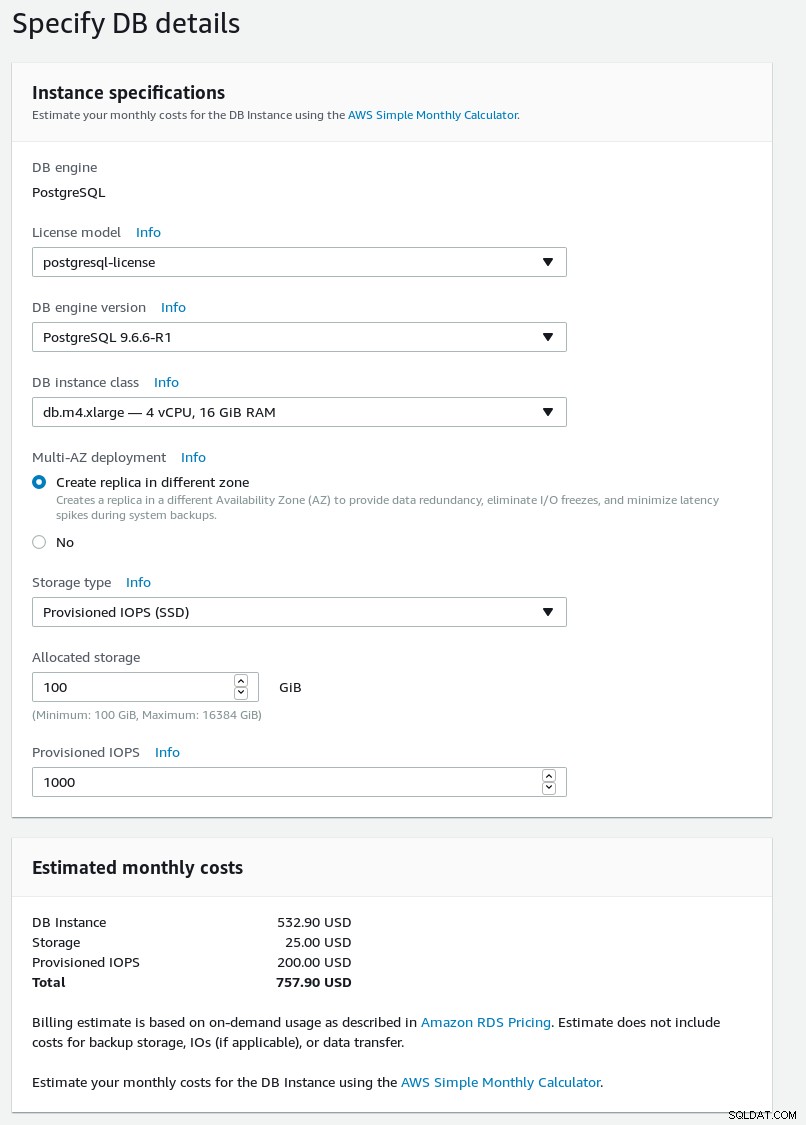 DB-Details des RDS-PostgreSQL-Assistenten
DB-Details des RDS-PostgreSQL-Assistenten 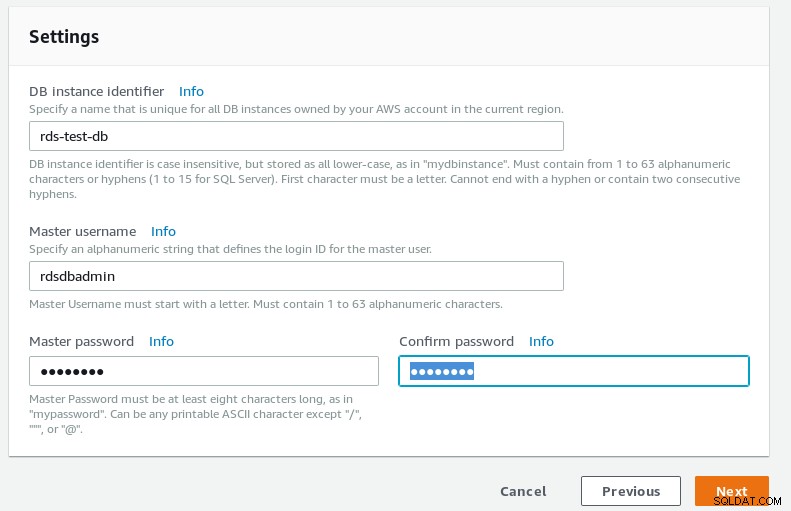 Datenbankeinstellungen des RDS PostgreSQL-Assistenten
Datenbankeinstellungen des RDS PostgreSQL-Assistenten -
Richten Sie auf der nächsten Seite den Netzwerk-, Sicherheits- und Wartungsplan ein:
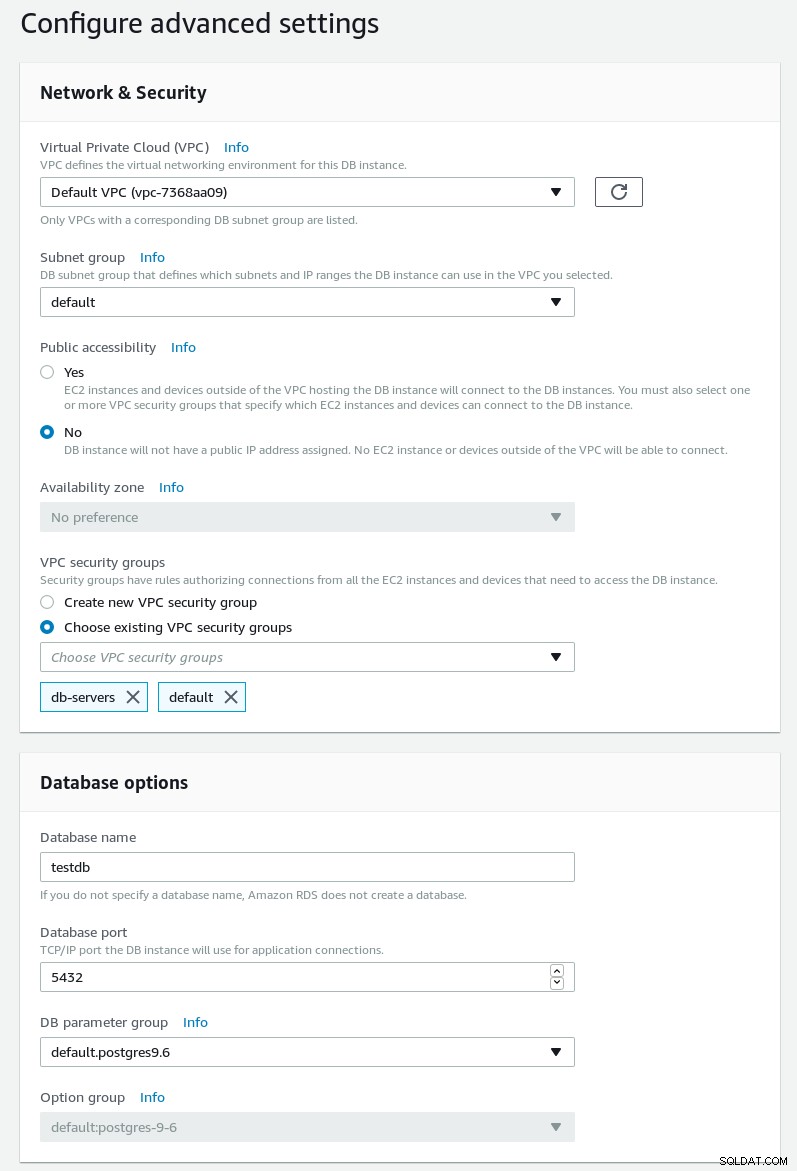 Erweiterte Einstellungen des RDS-PostgreSQL-Assistenten
Erweiterte Einstellungen des RDS-PostgreSQL-Assistenten 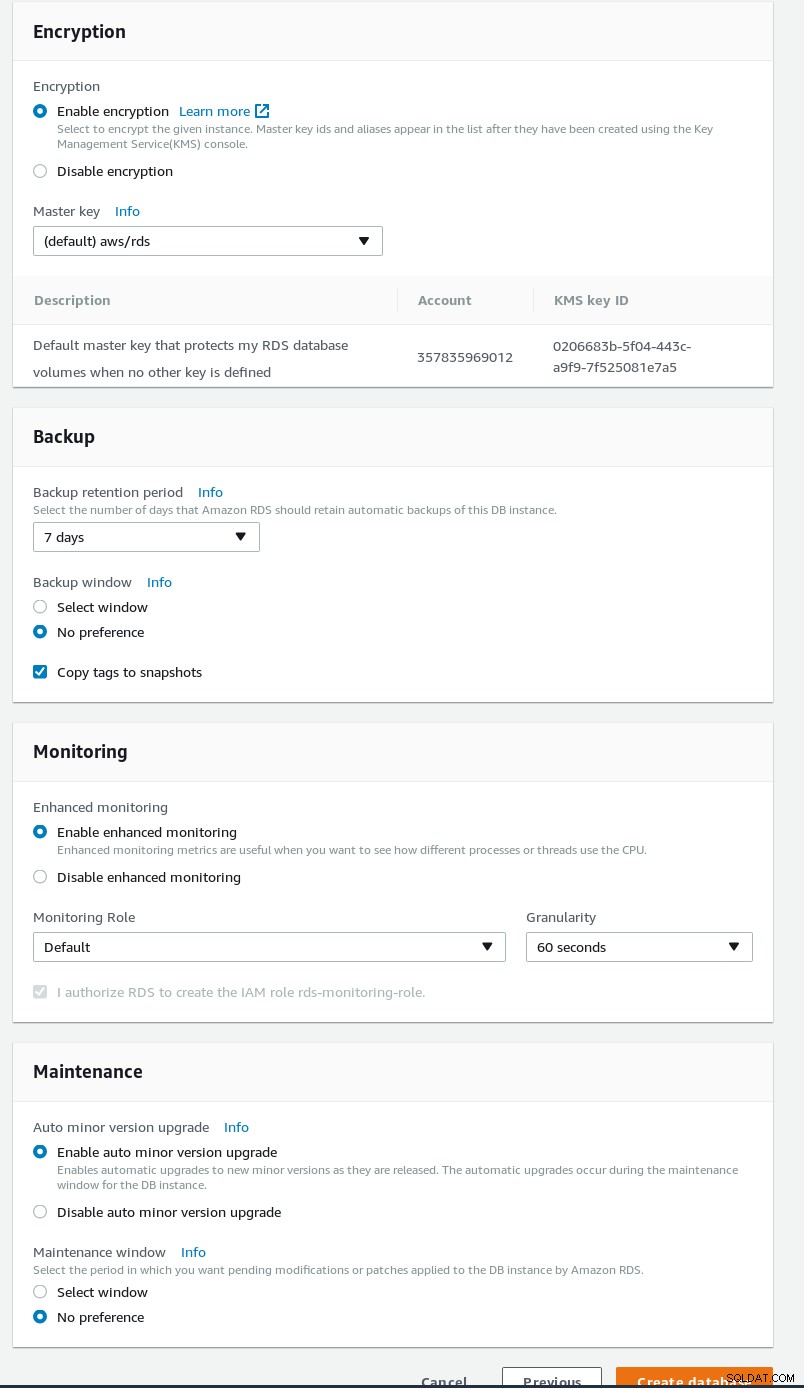 Sicherheit und Wartung des RDS-PostgreSQL-Assistenten
Sicherheit und Wartung des RDS-PostgreSQL-Assistenten
Schlussfolgerung
Amazon RDS Services for PostgreSQL umfassen RDS PostgreSQL und Aurora PostgreSQL, beides verwaltete DaaS-Angebote. Vollgepackt mit zahlreichen Funktionen und solidem Backend-Speicher haben sie einige Einschränkungen gegenüber dem traditionellen Setup, aber bei sorgfältiger Planung können diese Angebote ein ausgewogenes Kosten-Funktions-Verhältnis bieten. Amazon RDS for PostgreSQL richtet sich an Benutzer, die mehr Optionen zum Konfigurieren ihrer Umgebungen benötigen, und ist im Allgemeinen teurer. Die Mehrheit der Benutzer wird davon profitieren, mit Aurora PostgreSQL zu starten und sich in komplexere Konfigurationen einzuarbeiten.