Mit Disaster Recovery zielen wir darauf ab, Systeme einzurichten, die alles handhaben, was mit unserer Datenbank schiefgehen könnte. Was passiert, wenn die Datenbank abstürzt? Was passiert, wenn ein Entwickler versehentlich eine Tabelle abschneidet? Was ist, wenn wir feststellen, dass einige Daten letzte Woche gelöscht wurden, wir es aber bis heute nicht bemerkt haben? Diese Dinge passieren, und mit einem soliden Plan und System wird der DBA wie ein Held aussehen, wenn die Herzen aller anderen bereits stehen geblieben sind, wenn eine Katastrophe ihren hässlichen Kopf erhebt.
Jede Datenbank, die irgendeinen Wert hat, sollte eine Möglichkeit haben, eine oder mehrere Notfallwiederherstellungsoptionen zu implementieren. PostgreSQL verfügt über ein sehr solides integriertes Replikationssystem und ist flexibel genug, um in vielen Konfigurationen eingerichtet zu werden, um die Notfallwiederherstellung zu unterstützen, falls etwas schief gehen sollte. Wir konzentrieren uns auf Szenarien wie die oben befragten, die Einrichtung unserer Disaster Recovery-Optionen und die Vorteile jeder Lösung.
Hohe Verfügbarkeit
Mit der Streaming-Replikation in PostgreSQL ist Hochverfügbarkeit einfach einzurichten und zu warten. Das Ziel besteht darin, eine Failover-Site bereitzustellen, die zum Master heraufgestuft werden kann, wenn die Hauptdatenbank aus irgendeinem Grund ausfällt, z. B. bei Hardwarefehlern, Softwarefehlern oder sogar Netzwerkausfällen. Das Hosten einer Replik auf einem anderen Host ist großartig, aber das Hosten in einem anderen Rechenzentrum ist noch besser.
Für Einzelheiten zum Einrichten der Streaming-Replikation bietet Multiplenines hier einen detaillierten Deep Dive. Die offizielle Dokumentation zur PostgreSQL-Streaming-Replikation enthält detaillierte Informationen zum Streaming-Replikationsprotokoll und wie alles funktioniert.
Ein Standard-Setup sieht so aus, eine Master-Datenbank akzeptiert Lese-/Schreibverbindungen, während eine Replikat-Datenbank alle WAL-Aktivitäten nahezu in Echtzeit empfängt und alle Datenänderungsaktivitäten lokal wiedergibt.
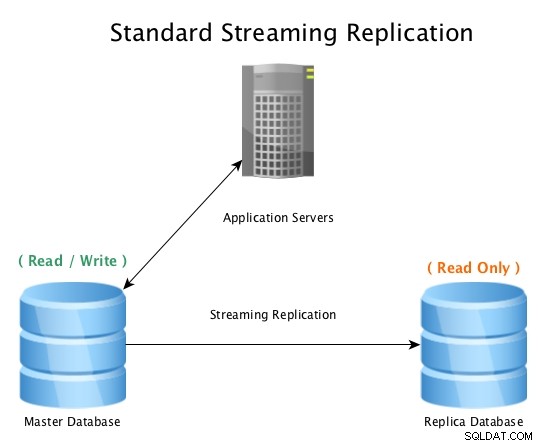 Standard-Streaming-Replikation mit PostgreSQL
Standard-Streaming-Replikation mit PostgreSQL Wenn die Master-Datenbank unbrauchbar wird, wird ein Failover-Verfahren initiiert, um sie offline zu schalten und die Replikatdatenbank zum Master hochzustufen, wobei dann alle Verbindungen auf den neu heraufgestuften Host verweisen. Dies kann entweder durch die Neukonfiguration eines Lastenausgleichs, einer Anwendungskonfiguration, von IP-Aliassen oder durch andere clevere Methoden zur Umleitung des Datenverkehrs erfolgen.
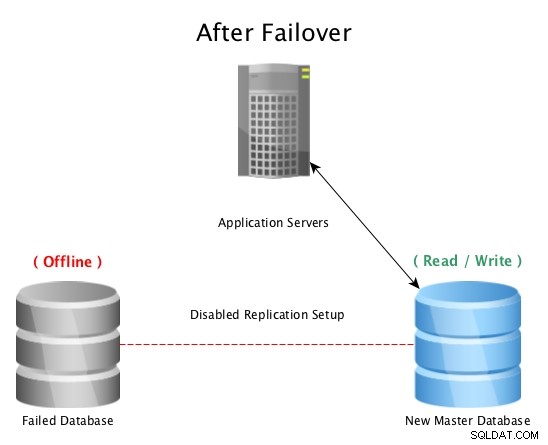 Nach einem Failover mit PostgreSQL Streaming Replication
Nach einem Failover mit PostgreSQL Streaming Replication Wenn eine Master-Datenbank von einer Katastrophe heimgesucht wird (z. B. ein Festplattenausfall, Stromausfall oder irgendetwas, das den Master daran hindert, wie beabsichtigt zu funktionieren), ist das Failover auf einen Hot-Standby der schnellste Weg, um online zu bleiben und Anfragen an Anwendungen oder Kunden ohne ernsthafte Probleme zu beantworten Ausfallzeit. Das Rennen geht dann weiter, um entweder den ausgefallenen Datenbankhost zu reparieren oder eine neue Replik online zu bringen, um das Sicherheitsnetz eines einsatzbereiten Standby-Servers aufrechtzuerhalten. Durch mehrere Standbys wird sichergestellt, dass das Fenster nach einem katastrophalen Ausfall auch für einen zweiten Ausfall bereit ist, wie unwahrscheinlich es auch erscheinen mag.
Hinweis:Beim Failover zu einer Streaming-Replik wird dort weitergemacht, wo der vorherige Master aufgehört hat, sodass dies dazu beiträgt, die Datenbank online zu halten, aber keine versehentlich verlorenen Daten wiederherzustellen.
Punkt-in-Time-Wiederherstellung
Eine weitere Disaster-Recovery-Option ist Point-in-Time-Recovery (PITR). Mit PITR kann eine Kopie der Datenbank zu jedem gewünschten Zeitpunkt zurückgebracht werden, solange wir ein Basis-Backup von vor diesem Zeitpunkt und alle bis zu diesem Zeitpunkt benötigten WAL-Segmente haben.
Eine Point-in-Time-Recovery-Option wird nicht so schnell online geschaltet wie ein Hot Standby, der Hauptvorteil besteht jedoch darin, einen Datenbank-Snapshot vor einem großen Ereignis wie einer gelöschten Tabelle, dem Einfügen fehlerhafter Daten oder sogar einer unerklärlichen Datenbeschädigung wiederherstellen zu können . Alles, was Daten so zerstören würde, dass wir vor dieser Zerstörung eine Kopie haben möchten, PITR rettet den Tag.
Point-in-Time-Recovery funktioniert, indem es regelmäßige Snapshots der Datenbank erstellt, normalerweise unter Verwendung des Programms pg_basebackup, und archivierte Kopien aller vom Master generierten WAL-Dateien aufbewahrt
Point-in-Time-Recovery-Setup
Das Setup erfordert einige auf dem Master festgelegte Konfigurationsoptionen, von denen einige gut zu den Standardwerten der aktuellen neuesten Version, PostgreSQL 11, passen. In diesem Beispiel kopieren wir die 16-MB-Datei mithilfe von rsync direkt auf unseren Remote-PITR-Host , und komprimieren sie auf der anderen Seite mit einem Cron-Job.
WAL-Archivierung
Master postgresql.conf
wal_level = replica
archive_mode = on
archive_command = 'rsync -av -z %p example@sqldat.com:/mnt/db/wal_archive/%f'HINWEIS: Die Einstellung archive_command kann viele Dinge sein, das übergeordnete Ziel ist es, alle archivierten WAL-Dateien aus Sicherheitsgründen an einen anderen Host zu senden. Wenn wir WAL-Dateien verlieren, wird PITR über die verlorene WAL-Datei hinaus unmöglich. Lassen Sie Ihrer Programmierkreativität freien Lauf, aber stellen Sie sicher, dass sie zuverlässig ist.
[Optional] Komprimieren Sie die archivierten WAL-Dateien:
Jedes Setup wird etwas variieren, aber wenn die betreffende Datenbank nicht sehr wenig Datenaktualisierungen durchführt, wird der Aufbau von 16-MB-Dateien den Speicherplatz ziemlich schnell füllen. Ein einfaches Komprimierungsskript, das über Cron eingerichtet wird, könnte wie folgt aussehen.
compress_WAL_archive.sh:
#!/bin/bash
# Compress any WAL files found that are not yet compressed
gzip /mnt/db/wal_archive/*[0-F]HINWEIS: Bei jeder Wiederherstellungsmethode müssen alle komprimierten Dateien später dekomprimiert werden. Einige Administratoren entscheiden sich dafür, Dateien erst zu komprimieren, nachdem sie X Tage alt sind, um den Gesamtspeicherplatz niedrig zu halten, aber auch neuere WAL-Dateien ohne zusätzliche Arbeit für die Wiederherstellung bereitzuhalten. Wählen Sie die beste Option für die betreffenden Datenbanken, um Ihre Wiederherstellungsgeschwindigkeit zu maximieren.
Basissicherungen
Eine der Schlüsselkomponenten einer PITR-Sicherung ist die Basissicherung und die Häufigkeit der Basissicherungen. Diese können stündlich, täglich, wöchentlich, monatlich sein, aber wählen Sie die beste Option basierend auf den Wiederherstellungsanforderungen sowie dem Datenverkehr der Datenbankdatenänderung. Wenn wir jeden Sonntag wöchentliche Backups haben und bis Samstagnachmittag wiederherstellen müssen, bringen wir das Basis-Backup des vorherigen Sonntags mit allen WAL-Dateien zwischen diesem Backup und Samstagnachmittag online. Wenn die Verarbeitung dieses Wiederherstellungsprozesses 10 Stunden dauert, ist dies wahrscheinlich unerwünscht zu lang. Tägliche Basissicherungen verkürzen diese Wiederherstellungszeit, da die Basissicherung von diesem Morgen stammen würde, erhöhen aber auch den Arbeitsaufwand auf dem Host für die Basissicherung selbst.
Wenn eine einwöchige Wiederherstellung von WAL-Dateien nur wenige Minuten dauert, weil die Datenbank eine geringe Änderung aufweist, sind wöchentliche Sicherungen in Ordnung. Am Ende werden dieselben Daten existieren, aber wie schnell Sie darauf zugreifen können, ist der Schlüssel.
In unserem Beispiel richten wir ein wöchentliches Basis-Backup ein, und da wir die Streaming-Replikation für Hochverfügbarkeit verwenden und die Last auf dem Master reduzieren, erstellen wir das Basis-Backup außerhalb der Replikatdatenbank.
base_backup.sh:
#!/bin/bash
backup_dir="$(date +'%Y-%m-%d')_backup"
cd /mnt/db/backups
mkdir $backup_dir
pg_basebackup -h <replica host> -p <replica port> -U replication -D $backup_dir -Ft -zHINWEIS: Der Befehl pg_basebackup geht davon aus, dass dieser Host für den kennwortlosen Zugriff für den Benutzer „replication“ auf dem Master eingerichtet ist, was entweder durch „trust“ in pg_hba für diesen PITR-Sicherungshost, ein Kennwort in der .pgpass-Datei oder andere sicherere Methoden erfolgen kann . Denken Sie beim Einrichten von Backups an die Sicherheit.
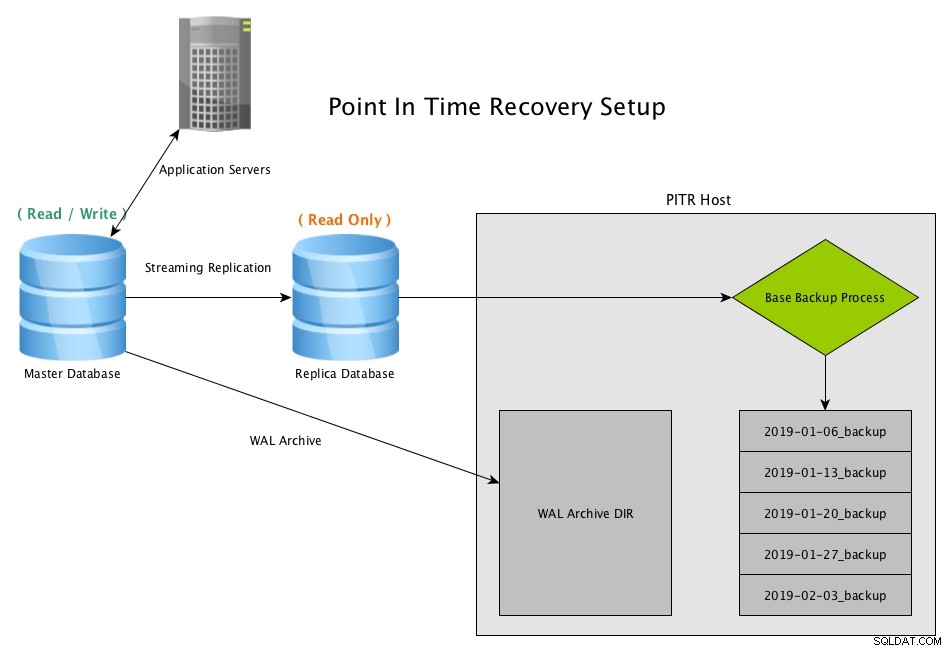 Point-in-Time-Recovery (PITR) von einem Streaming-Replikat mit PostgreSQLLaden Sie noch heute das Whitepaper herunter PostgreSQL-Verwaltung und -Automatisierung mit ClusterControlWeitere Informationen Was Sie wissen müssen, um PostgreSQL bereitzustellen, zu überwachen, zu verwalten und zu skalierenLaden Sie das Whitepaper herunter
Point-in-Time-Recovery (PITR) von einem Streaming-Replikat mit PostgreSQLLaden Sie noch heute das Whitepaper herunter PostgreSQL-Verwaltung und -Automatisierung mit ClusterControlWeitere Informationen Was Sie wissen müssen, um PostgreSQL bereitzustellen, zu überwachen, zu verwalten und zu skalierenLaden Sie das Whitepaper herunter PITR-Wiederherstellungsszenario
Point-in-Time-Recovery einzurichten ist nur ein Teil der Aufgabe, Daten wiederherstellen zu müssen ist der andere Teil. Mit viel Glück muss dies möglicherweise nie passieren, es wird jedoch dringend empfohlen, regelmäßig eine Wiederherstellung einer PITR-Sicherung durchzuführen, um zu überprüfen, ob das System funktioniert, und um sicherzustellen, dass der Prozess bekannt / richtig geschrieben ist.
In unserem Testszenario wählen wir einen Zeitpunkt für die Wiederherstellung aus und leiten den Wiederherstellungsprozess ein. Beispiel:Am Freitagmorgen überträgt ein Entwickler eine neue Codeänderung in die Produktion, ohne eine Codeüberprüfung durchlaufen zu haben, und dabei werden eine Reihe wichtiger Kundendaten zerstört. Da unser Hot Standby immer mit dem Master synchron ist, würde ein Failover nichts beheben, da es sich um dieselben Daten handeln würde. PITR-Backups werden uns retten.
Der Code-Push ging um 11 Uhr ein, also müssen wir die Datenbank kurz vor dieser Zeit wiederherstellen, 10:59 Uhr, entscheiden wir uns, und zum Glück machen wir tägliche Backups, sodass wir heute Morgen ein Backup von Mitternacht haben. Da wir nicht wissen, was alles zerstört wurde, entscheiden wir uns auch, eine vollständige Wiederherstellung dieser Datenbank auf unserem PITR-Host durchzuführen und sie als Master online zu bringen, da sie die gleichen Hardwarespezifikationen wie der Master hat, nur für den Fall, dass dies der Fall ist Szenario passiert.
Schalte den Master aus
Da wir uns entschieden haben, eine vollständige Wiederherstellung aus einem Backup durchzuführen und es zum Master hochzustufen, besteht keine Notwendigkeit, dies online zu halten. Wir schalten es ab, behalten es aber für den Fall, dass wir später etwas daraus holen müssen, nur für den Fall.
Basissicherung für die Wiederherstellung einrichten
Als Nächstes rufen wir auf unserem PITR-Host unser letztes Basis-Backup von vor dem Ereignis ab, nämlich das Backup „2018-12-21_backup“.
mkdir /var/lib/pgsql/11/data
chmod 700 /var/lib/pgsql/11/data
cd /var/lib/pgsql/11/data
tar -xzvf /mnt/db/backups/2018-12-21_backup/base.tar.gz
cd pg_wal
tar -xzvf /mnt/db/backups/2018-12-21_backup/pg_wal.tar.gz
mkdir /mnt/db/wal_archive/pitr_restore/Damit sind das Basis-Backup sowie die von pg_basebackup bereitgestellten WAL-Dateien einsatzbereit. Wenn wir es jetzt online bringen, wird es bis zu dem Punkt wiederhergestellt, an dem das Backup stattfand, aber wir möchten alle WAL-Transaktionen dazwischen wiederherstellen Mitternacht und 11:59 Uhr, also richten wir unsere recovery.conf-Datei ein.
Recovery.conf erstellen
Da diese Sicherung tatsächlich von einer Streaming-Replik stammt, gibt es wahrscheinlich bereits eine recovery.conf-Datei mit Replikateinstellungen. Wir werden es mit neuen Einstellungen überschreiben. Eine detaillierte Informationsliste für alle verschiedenen Optionen finden Sie in der PostgreSQL-Dokumentation hier.
Wenn Sie vorsichtig mit den WAL-Dateien umgehen, kopiert der Wiederherstellungsbefehl die komprimierten Dateien, die er benötigt, in das Wiederherstellungsverzeichnis, dekomprimiert sie und verschiebt sie dann dorthin, wo PostgreSQL sie für die Wiederherstellung benötigt. Die ursprünglichen WAL-Dateien bleiben dort, wo sie für andere Zwecke benötigt werden.
Neue recovery.conf:
recovery_target_time = '2018-12-21 11:59:00-07'
restore_command = 'cp /mnt/db/wal_archive/%f.gz /var/lib/pgsql/test_recovery/pitr_restore/%f.gz && gunzip /var/lib/pgsql/test_recovery/pitr_restore/%f.gz && mv /var/lib/pgsql/test_recovery/pitr_restore/%f "%p"'Starten Sie den Wiederherstellungsprozess
Nachdem alles eingerichtet ist, beginnen wir mit dem Wiederherstellungsprozess. Wenn dies passiert, ist es eine gute Idee, das Datenbankprotokoll zu verfolgen, um sicherzustellen, dass es wie beabsichtigt wiederhergestellt wird.
Datenbank starten:
pg_ctl -D /var/lib/pgsql/11/data startVerfolgen Sie die Protokolle:
Es wird viele Protokolleinträge geben, die zeigen, dass die Datenbank aus Archivdateien wiederhergestellt wird, und an einem bestimmten Punkt wird eine Zeile mit der Aufschrift „Wiederherstellung wird gestoppt, bevor die Transaktion ausgeführt wird …“
angezeigt2018-12-22 04:21:30 UTC [20565]: [705-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000074" from archive
2018-12-22 04:21:30 UTC [20565]: [706-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000075" from archive
2018-12-22 04:21:31 UTC [20565]: [707-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000076" from archive
2018-12-22 04:21:31 UTC [20565]: [708-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000077" from archive
2018-12-22 04:21:31 UTC [20565]: [709-1] user=,db=,app=,client= LOG: recovery stopping before commit of transaction 611765, time 2018-12-21 11:59:01.45545+07Zu diesem Zeitpunkt hat der Wiederherstellungsprozess alle WAL-Dateien aufgenommen, muss aber auch überprüft werden, bevor er als Master online geht. In diesem Beispiel vermerkt das Protokoll, dass die nächste Transaktion nach der Wiederherstellungszielzeit von 11:59:00 Uhr 11:59:01 Uhr war und nicht wiederhergestellt wurde. Um dies zu überprüfen, melden Sie sich bei der Datenbank an und sehen Sie nach, die laufende Datenbank sollte ein Schnappschuss von genau 11:59 sein.
Wenn alles gut aussieht, ist es an der Zeit, die Genesung als Meister voranzutreiben.
postgres=# SELECT pg_wal_replay_resume();
pg_wal_replay_resume
----------------------
(1 row)Jetzt ist die Datenbank online, bis zu dem von uns festgelegten Punkt wiederhergestellt und akzeptiert Lese-/Schreibverbindungen als Masterknoten. Stellen Sie sicher, dass alle Konfigurationsparameter korrekt und produktionsbereit sind.
Die Datenbank ist online, aber der Wiederherstellungsprozess ist noch nicht abgeschlossen! Jetzt, da dieses PITR-Backup als Master online ist, sollte ein neues Standby- und PITR-Setup eingerichtet werden, bis dahin kann dieser neue Master online sein und Anwendungen bedienen, aber er ist nicht vor einem weiteren Notfall sicher, bis das alles wieder eingerichtet ist. P>
Andere Point-in-Time-Wiederherstellungsszenarien
Das Wiederherstellen einer PITR-Sicherung für eine ganze Datenbank ist ein Extremfall, aber es gibt andere Szenarien, in denen nur eine Teilmenge von Daten fehlt, beschädigt oder fehlerhaft ist. In diesen Fällen können wir mit unseren Wiederherstellungsoptionen kreativ werden. Ohne den Master offline zu schalten und durch ein Backup zu ersetzen, können wir ein PITR-Backup genau zum gewünschten Zeitpunkt auf einem anderen Host (oder einem anderen Port, wenn der Platz keine Rolle spielt) online bringen und die wiederhergestellten Daten direkt aus dem Backup exportieren in die Master-Datenbank. Dies könnte verwendet werden, um eine Handvoll Zeilen, eine Handvoll Tabellen oder jede benötigte Konfiguration von Daten wiederherzustellen.
Mit Streaming-Replikation und Point-In-Time-Recovery bietet uns PostgreSQL große Flexibilität, um sicherzustellen, dass wir alle benötigten Daten wiederherstellen können, solange wir Standby-Hosts als Master oder Backups zur Wiederherstellung bereit haben. Eine gute Disaster-Recovery-Option kann mit anderen Backup-Optionen, mehr Replikatknoten, mehreren Backup-Standorten in verschiedenen Rechenzentren und Kontinenten, regelmäßigen pg_dumps auf einem anderen Replikat usw. weiter ausgebaut werden.
Diese Optionen können sich summieren, aber die eigentliche Frage lautet:„Wie wertvoll sind die Daten und wie viel sind Sie bereit auszugeben, um sie zurückzubekommen?“. In vielen Fällen bedeutet der Verlust von Daten das Ende eines Unternehmens, daher sollten gute Notfallwiederherstellungsoptionen vorhanden sein, um das Schlimmste zu verhindern.



