In der Vergangenheit war die schwierigste Aufgabe bei der Arbeit mit PostgreSQL der Umgang mit den Upgrades. Die intuitivste Upgrade-Methode, die Sie sich vorstellen können, besteht darin, ein Replikat in einer neuen Version zu erstellen und ein Failover der Anwendung darauf durchzuführen. Mit PostgreSQL war dies nativ einfach nicht möglich. Um Upgrades durchzuführen, mussten Sie sich andere Upgrade-Möglichkeiten überlegen, wie z. B. die Verwendung von pg_upgrade, Dumping und Wiederherstellung oder die Verwendung einiger Tools von Drittanbietern wie Slony oder Bucardo, die alle ihre eigenen Einschränkungen haben.
Warum war das so? Aufgrund der Art und Weise, wie PostgreSQL die Replikation implementiert.
Die in PostgreSQL integrierte Streaming-Replikation wird als physisch bezeichnet:Sie repliziert die Änderungen Byte für Byte und erstellt eine identische Kopie der Datenbank auf einem anderen Server. Diese Methode hat viele Einschränkungen, wenn Sie an ein Upgrade denken, da Sie einfach kein Replikat in einer anderen Serverversion oder sogar in einer anderen Architektur erstellen können.
Hier wird PostgreSQL 10 also zu einem Game Changer. Mit diesen neuen Versionen 10 und 11 implementiert PostgreSQL eine integrierte logische Replikation, die Sie im Gegensatz zur physischen Replikation zwischen verschiedenen Hauptversionen von PostgreSQL replizieren können. Dies öffnet natürlich eine neue Tür zum Upgraden von Strategien.
Sehen wir uns in diesem Blog an, wie wir unser PostgreSQL 10 ohne Ausfallzeiten mithilfe der logischen Replikation auf PostgreSQL 11 aktualisieren können. Sehen wir uns zunächst eine Einführung in die logische Replikation an.
Was ist logische Replikation?
Die logische Replikation ist eine Methode zum Replizieren von Datenobjekten und deren Änderungen auf der Grundlage ihrer Replikationsidentität (normalerweise ein Primärschlüssel). Es basiert auf einem Publish-and-Subscribe-Modus, bei dem ein oder mehrere Abonnenten eine oder mehrere Publikationen auf einem Publisher-Knoten abonnieren.
Eine Veröffentlichung ist ein Satz von Änderungen, der aus einer Tabelle oder einer Gruppe von Tabellen generiert wird (auch als Replikationssatz bezeichnet). Der Knoten, in dem eine Veröffentlichung definiert ist, wird als Herausgeber bezeichnet. Ein Abonnement ist die Downstream-Seite der logischen Replikation. Der Knoten, an dem ein Abonnement definiert ist, wird als Abonnent bezeichnet und definiert die Verbindung zu einer anderen Datenbank und einem Satz von Veröffentlichungen (einer oder mehreren), die er abonnieren möchte. Abonnenten beziehen Daten aus den von ihnen abonnierten Publikationen.
Die logische Replikation basiert auf einer ähnlichen Architektur wie die physische Streaming-Replikation. Es wird durch die Prozesse "walsender" und "apply" implementiert. Der Walsender-Prozess startet die logische Dekodierung der WAL und lädt das standardmäßige Plug-in für die logische Dekodierung. Das Plugin wandelt die von WAL gelesenen Änderungen in das logische Replikationsprotokoll um und filtert die Daten gemäß der Veröffentlichungsspezifikation. Die Daten werden dann kontinuierlich unter Verwendung des Streaming-Replikationsprotokolls an den Apply-Worker übertragen, der die Daten lokalen Tabellen zuordnet und die einzelnen Änderungen, sobald sie empfangen werden, in einer korrekten Transaktionsreihenfolge anwendet.
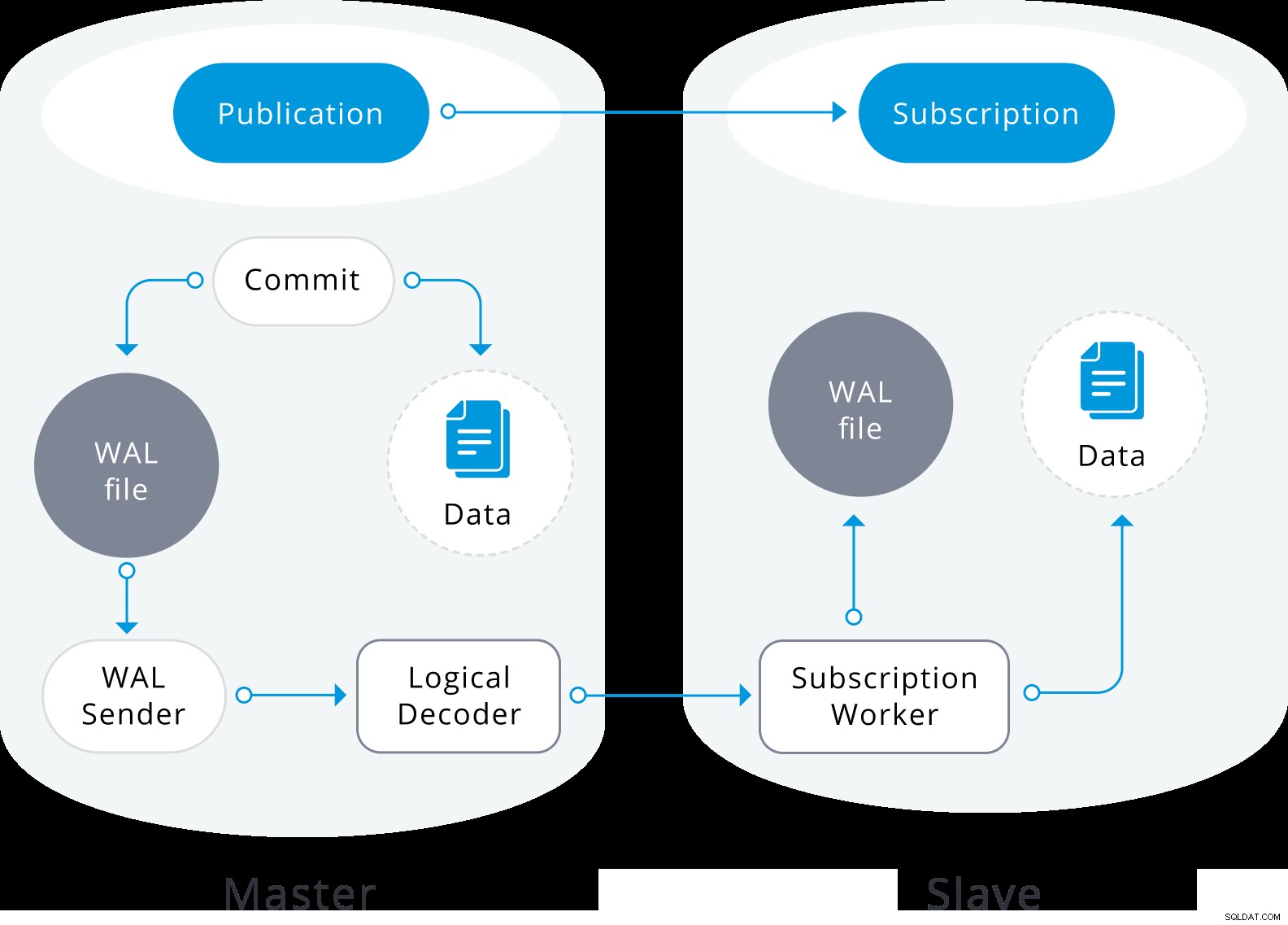 Logisches Replikationsdiagramm
Logisches Replikationsdiagramm Die logische Replikation beginnt damit, dass ein Snapshot der Daten in der Herausgeberdatenbank erstellt und auf den Abonnenten kopiert wird. Die Anfangsdaten in den vorhandenen abonnierten Tabellen werden in einer parallelen Instanz eines speziellen Typs von Anwendungsprozessen abgespeichert und kopiert. Dieser Prozess erstellt einen eigenen temporären Replikationsslot und kopiert die vorhandenen Daten. Sobald die vorhandenen Daten kopiert sind, wechselt der Worker in den Synchronisationsmodus, der sicherstellt, dass die Tabelle in einen synchronisierten Zustand mit dem Hauptanwendungsprozess gebracht wird, indem alle Änderungen, die während der anfänglichen Datenkopie unter Verwendung der standardmäßigen logischen Replikation vorgenommen wurden, gestreamt werden. Sobald die Synchronisierung abgeschlossen ist, wird die Steuerung der Replikation der Tabelle an den Hauptanwendungsprozess zurückgegeben, wo die Replikation normal fortgesetzt wird. Die Änderungen am Herausgeber werden in Echtzeit an den Abonnenten gesendet.
Weitere Informationen zur logischen Replikation finden Sie in den folgenden Blogs:
- Ein Überblick über die logische Replikation in PostgreSQL
- PostgreSQL-Streaming-Replikation vs. logische Replikation
So aktualisieren Sie PostgreSQL 10 auf PostgreSQL 11 mithilfe der logischen Replikation
Nun, da wir wissen, worum es bei dieser neuen Funktion geht, können wir darüber nachdenken, wie wir damit das Upgrade-Problem lösen können.
Wir werden die logische Replikation zwischen zwei verschiedenen Hauptversionen von PostgreSQL (10 und 11) konfigurieren, und nachdem Sie damit gearbeitet haben, ist es natürlich nur noch eine Frage der Ausführung eines Anwendungs-Failovers in die Datenbank mit der neueren Version.
Wir werden die folgenden Schritte ausführen, um die logische Replikation zum Laufen zu bringen:
- Konfigurieren Sie den Publisher-Knoten
- Konfigurieren Sie den Abonnentenknoten
- Erstellen Sie den Abonnenten-Benutzer
- Erstellen Sie eine Veröffentlichung
- Erstellen Sie die Tabellenstruktur im Abonnenten
- Erstellen Sie das Abonnement
- Überprüfen Sie den Replikationsstatus
Fangen wir also an.
Auf der Seite des Herausgebers konfigurieren wir die folgenden Parameter in der Datei postgresql.conf:
- listen_addresses:Welche IP-Adresse(n) zum Abhören. Wir verwenden '*' für alle.
- wal_level:Legt fest, wie viele Informationen in die WAL geschrieben werden. Wir werden es auf logisch setzen.
- max_replication_slots:Gibt die maximale Anzahl von Replikationsslots an, die der Server unterstützen kann. Es muss mindestens auf die Anzahl der Abonnements gesetzt werden, die voraussichtlich eine Verbindung herstellen, plus etwas Reserve für die Tabellensynchronisierung.
- max_wal_senders:Gibt die maximale Anzahl gleichzeitiger Verbindungen von Standby-Servern oder Streaming-Basis-Backup-Clients an. Es sollte mindestens auf den gleichen Wert wie max_replication_slots plus die Anzahl der physischen Replikate gesetzt werden, die gleichzeitig verbunden sind.
Beachten Sie, dass für einige dieser Parameter ein Neustart des PostgreSQL-Dienstes erforderlich war, um angewendet zu werden.
Die Datei pg_hba.conf muss ebenfalls angepasst werden, um die Replikation zu ermöglichen. Wir müssen dem Replikationsbenutzer erlauben, sich mit der Datenbank zu verbinden.
Lassen Sie uns auf dieser Grundlage unseren Herausgeber (in diesem Fall unseren PostgreSQL 10-Server) wie folgt konfigurieren:
- postgresql.conf:
listen_addresses = '*' wal_level = logical max_wal_senders = 8 max_replication_slots = 4 - pg_hba.conf:
# TYPE DATABASE USER ADDRESS METHOD host all rep 192.168.100.144/32 md5
Wir müssen den Benutzer (in unserem Beispiel rep), der für die Replikation verwendet wird, und die IP-Adresse 192.168.100.144/32 für die IP ändern, die unserem PostgreSQL 11 entspricht.
Auf der Abonnentenseite müssen außerdem die max_replication_slots festgelegt werden. In diesem Fall sollte es mindestens auf die Anzahl der Abonnements eingestellt werden, die dem Abonnenten hinzugefügt werden.
Die anderen Parameter, die hier ebenfalls eingestellt werden müssen, sind:
- max_logical_replication_workers:Gibt die maximale Anzahl logischer Replikationsworker an. Dies umfasst sowohl Anwendungsworker als auch Tabellensynchronisierungsworker. Logische Replikations-Worker werden aus dem durch max_worker_processes definierten Pool entnommen. Sie muss mindestens auf die Anzahl der Abonnements gesetzt werden, wieder plus etwas Reserve für die Tabellensynchronisierung.
- max_worker_processes:Legt die maximale Anzahl von Hintergrundprozessen fest, die das System unterstützen kann. Er muss möglicherweise angepasst werden, um Replikationsworker aufzunehmen, mindestens max_logical_replication_workers + 1. Dieser Parameter erfordert einen PostgreSQL-Neustart.
Also müssen wir unseren Abonnenten (in diesem Fall unseren PostgreSQL 11-Server) wie folgt konfigurieren:
- postgresql.conf:
listen_addresses = '*' max_replication_slots = 4 max_logical_replication_workers = 4 max_worker_processes = 8
Da dieses PostgreSQL 11 bald unser neuer Master sein wird, sollten wir in diesem Schritt die Parameter wal_level und archive_mode hinzufügen, um einen späteren Neustart des Dienstes zu vermeiden.
wal_level = logical
archive_mode = onDiese Parameter sind nützlich, wenn wir einen neuen Replikations-Slave hinzufügen oder PITR-Sicherungen verwenden möchten.
Im Herausgeber müssen wir den Benutzer erstellen, mit dem sich unser Abonnent verbinden wird:
world=# CREATE ROLE rep WITH LOGIN PASSWORD '*****' REPLICATION;
CREATE ROLEDie für die Replikationsverbindung verwendete Rolle muss das REPLICATION-Attribut haben. Der Zugriff für die Rolle muss in pg_hba.conf konfiguriert sein und das LOGIN-Attribut haben.
Um die Ausgangsdaten kopieren zu können, muss die für die Replikationsverbindung verwendete Rolle das SELECT-Privileg auf eine veröffentlichte Tabelle haben.
world=# GRANT SELECT ON ALL TABLES IN SCHEMA public to rep;
GRANTWir erstellen die pub1-Publikation im Publisher-Knoten für alle Tabellen:
world=# CREATE PUBLICATION pub1 FOR ALL TABLES;
CREATE PUBLICATIONDer Benutzer, der eine Veröffentlichung erstellt, muss das CREATE-Privileg in der Datenbank haben, aber um eine Veröffentlichung zu erstellen, die alle Tabellen automatisch veröffentlicht, muss der Benutzer ein Superuser sein.
Um die erstellte Veröffentlichung zu bestätigen, verwenden wir den pg_publication-Katalog. Dieser Katalog enthält Informationen zu allen in der Datenbank angelegten Publikationen.
world=# SELECT * FROM pg_publication;
-[ RECORD 1 ]+------
pubname | pub1
pubowner | 16384
puballtables | t
pubinsert | t
pubupdate | t
pubdelete | tSpaltenbeschreibungen:
- pubname:Name der Publikation.
- pubowner:Eigentümer der Veröffentlichung.
- puballtables:Wenn wahr, enthält diese Veröffentlichung automatisch alle Tabellen in der Datenbank, einschließlich aller, die in Zukunft erstellt werden.
- pubinsert:Wenn wahr, werden INSERT-Vorgänge für Tabellen in der Veröffentlichung repliziert.
- pubupdate:Wenn wahr, werden UPDATE-Vorgänge für Tabellen in der Veröffentlichung repliziert.
- pubdelete:Wenn wahr, werden DELETE-Vorgänge für Tabellen in der Veröffentlichung repliziert.
Da das Schema nicht repliziert wird, müssen wir ein Backup in PostgreSQL 10 erstellen und es in unserem PostgreSQL 11 wiederherstellen. Das Backup wird nur für das Schema erstellt, da die Informationen bei der ersten Übertragung repliziert werden.
In PostgreSQL 10:
$ pg_dumpall -s > schema.sqlIn PostgreSQL 11:
$ psql -d postgres -f schema.sqlSobald wir unser Schema in PostgreSQL 11 haben, erstellen wir das Abonnement und ersetzen die Werte von host, dbname, user und password durch diejenigen, die unserer Umgebung entsprechen.
PostgreSQL 11:
world=# CREATE SUBSCRIPTION sub1 CONNECTION 'host=192.168.100.143 dbname=world user=rep password=*****' PUBLICATION pub1;
NOTICE: created replication slot "sub1" on publisher
CREATE SUBSCRIPTIONDas Obige startet den Replikationsprozess, der die anfänglichen Tabelleninhalte der Tabellen in der Veröffentlichung synchronisiert und dann mit der Replikation inkrementeller Änderungen an diesen Tabellen beginnt.
Der Benutzer, der ein Abonnement erstellt, muss ein Superuser sein. Der Abonnementantragsprozess wird in der lokalen Datenbank mit den Rechten eines Superusers ausgeführt.
Um das erstellte Abonnement zu überprüfen, können wir den pg_stat_subscription-Katalog verwenden. Diese Ansicht enthält eine Zeile pro Abonnement für den Haupt-Worker (mit Null-PID, wenn der Worker nicht ausgeführt wird) und zusätzliche Zeilen für Worker, die die anfängliche Datenkopie der abonnierten Tabellen handhaben.
world=# SELECT * FROM pg_stat_subscription;
-[ RECORD 1 ]---------+------------------------------
subid | 16428
subname | sub1
pid | 1111
relid |
received_lsn | 0/172AF90
last_msg_send_time | 2018-12-05 22:11:45.195963+00
last_msg_receipt_time | 2018-12-05 22:11:45.196065+00
latest_end_lsn | 0/172AF90
latest_end_time | 2018-12-05 22:11:45.195963+00Spaltenbeschreibungen:
- subid:OID des Abonnements.
- subname:Name des Abonnements.
- pid:Prozess-ID des Abonnement-Worker-Prozesses.
- relid:OID der Relation, die der Worker synchronisiert; null für den Hauptanwendungsworker.
- received_lsn:Letzter Write-Ahead-Log-Speicherort, der empfangen wurde, wobei der Anfangswert dieses Felds 0 ist.
- last_msg_send_time:Sendezeit der letzten vom ursprünglichen WAL-Absender empfangenen Nachricht.
- last_msg_receipt_time:Empfangszeit der letzten vom ursprünglichen WAL-Absender empfangenen Nachricht.
- latest_end_lsn:Letzter Write-Ahead-Protokollspeicherort, der an den ursprünglichen WAL-Absender gemeldet wurde.
- latest_end_time:Zeitpunkt des letzten Write-Ahead-Protokollspeicherorts, der an den ursprünglichen WAL-Absender gemeldet wurde.
Um den Status der Replikation im Master zu überprüfen, können wir pg_stat_replication:
verwendenworld=# SELECT * FROM pg_stat_replication;
-[ RECORD 1 ]----+------------------------------
pid | 1178
usesysid | 16427
usename | rep
application_name | sub1
client_addr | 192.168.100.144
client_hostname |
client_port | 58270
backend_start | 2018-12-05 22:11:45.097539+00
backend_xmin |
state | streaming
sent_lsn | 0/172AF90
write_lsn | 0/172AF90
flush_lsn | 0/172AF90
replay_lsn | 0/172AF90
write_lag |
flush_lag |
replay_lag |
sync_priority | 0
sync_state | asyncSpaltenbeschreibungen:
- pid:Prozess-ID eines WAL-Senderprozesses.
- usesysid:OID des Benutzers, der bei diesem WAL-Senderprozess angemeldet ist.
- usename:Name des Benutzers, der bei diesem WAL-Senderprozess angemeldet ist.
- application_name:Name der Anwendung, die mit diesem WAL-Sender verbunden ist.
- client_addr:IP-Adresse des Clients, der mit diesem WAL-Sender verbunden ist. Wenn dieses Feld null ist, zeigt es an, dass der Client über einen Unix-Socket auf dem Server-Rechner verbunden ist.
- client_hostname:Hostname des verbundenen Clients, wie von einem Reverse-DNS-Lookup von client_addr gemeldet. Dieses Feld ist nur für IP-Verbindungen ungleich Null und nur dann, wenn log_hostname aktiviert ist.
- client_port:TCP-Portnummer, die der Client für die Kommunikation mit diesem WAL-Sender verwendet, oder -1, wenn ein Unix-Socket verwendet wird.
- backend_start:Uhrzeit, wann dieser Prozess gestartet wurde.
- backend_xmin:Der xmin-Horizont dieses Standbys, gemeldet von hot_standby_feedback.
- state:Aktueller Status des WAL-Senders. Die möglichen Werte sind:Startup, Catchup, Streaming, Backup und Stoppen.
- sent_lsn:Letzte Write-Ahead-Protokollposition, die auf dieser Verbindung gesendet wurde.
- write_lsn:Letzte Write-Ahead-Protokollposition, die von diesem Standby-Server auf die Platte geschrieben wurde.
- flush_lsn:Letzte Write-Ahead-Protokollposition, die von diesem Standby-Server auf die Festplatte geschrieben wurde.
- replay_lsn:Letzte Write-Ahead-Log-Location, die in die Datenbank auf diesem Standby-Server eingespielt wurde.
- write_lag:Verstrichene Zeit zwischen dem lokalen Leeren der letzten WAL und dem Erhalt der Benachrichtigung, dass dieser Standby-Server sie geschrieben hat (aber noch nicht geleert oder angewendet hat).
- flush_lag:Zeit, die zwischen dem lokalen Leeren der letzten WAL und dem Erhalt der Benachrichtigung vergangen ist, dass dieser Standby-Server sie geschrieben und geleert (aber noch nicht angewendet) hat.
- replay_lag:Zeit, die zwischen dem lokalen Leeren der letzten WAL und dem Erhalt der Benachrichtigung vergangen ist, dass dieser Standby-Server sie geschrieben, geleert und angewendet hat.
- sync_priority:Priorität dieses Standby-Servers, um in einer prioritätsbasierten synchronen Replikation als synchroner Standby-Server ausgewählt zu werden.
- sync_state:Synchronzustand dieses Standby-Servers. Die möglichen Werte sind async, potential, sync, quorum.
Um zu überprüfen, wann die anfängliche Übertragung abgeschlossen ist, können wir das PostgreSQL-Protokoll auf dem Abonnenten sehen:
2018-12-05 22:11:45.096 UTC [1111] LOG: logical replication apply worker for subscription "sub1" has started
2018-12-05 22:11:45.103 UTC [1112] LOG: logical replication table synchronization worker for subscription "sub1", table "city" has started
2018-12-05 22:11:45.114 UTC [1113] LOG: logical replication table synchronization worker for subscription "sub1", table "country" has started
2018-12-05 22:11:45.156 UTC [1112] LOG: logical replication table synchronization worker for subscription "sub1", table "city" has finished
2018-12-05 22:11:45.162 UTC [1114] LOG: logical replication table synchronization worker for subscription "sub1", table "countrylanguage" has started
2018-12-05 22:11:45.168 UTC [1113] LOG: logical replication table synchronization worker for subscription "sub1", table "country" has finished
2018-12-05 22:11:45.206 UTC [1114] LOG: logical replication table synchronization worker for subscription "sub1", table "countrylanguage" has finishedOder überprüfen Sie die Variable srsubstate im Katalog pg_subscription_rel. Dieser Katalog enthält den Status für jede replizierte Beziehung in jedem Abonnement.
world=# SELECT * FROM pg_subscription_rel;
-[ RECORD 1 ]---------
srsubid | 16428
srrelid | 16387
srsubstate | r
srsublsn | 0/172AF20
-[ RECORD 2 ]---------
srsubid | 16428
srrelid | 16393
srsubstate | r
srsublsn | 0/172AF58
-[ RECORD 3 ]---------
srsubid | 16428
srrelid | 16400
srsubstate | r
srsublsn | 0/172AF90Spaltenbeschreibungen:
- srsubid:Referenz auf Abonnement.
- srrelid:Verweis auf Beziehung.
- srsubstate:Zustandscode:i =initialisieren, d =Daten werden kopiert, s =synchronisiert, r =bereit (normale Replikation).
- srsublsn:End-LSN für s- und r-Zustände.
Wir können einige Testdatensätze in unser PostgreSQL 10 einfügen und validieren, dass wir sie in unserem PostgreSQL 11 haben:
PostgreSQL 10:
world=# INSERT INTO city (id,name,countrycode,district,population) VALUES (5001,'city1','USA','District1',10000);
INSERT 0 1
world=# INSERT INTO city (id,name,countrycode,district,population) VALUES (5002,'city2','ITA','District2',20000);
INSERT 0 1
world=# INSERT INTO city (id,name,countrycode,district,population) VALUES (5003,'city3','CHN','District3',30000);
INSERT 0 1PostgreSQL 11:
world=# SELECT * FROM city WHERE id>5000;
id | name | countrycode | district | population
------+-------+-------------+-----------+------------
5001 | city1 | USA | District1 | 10000
5002 | city2 | ITA | District2 | 20000
5003 | city3 | CHN | District3 | 30000
(3 rows)An diesem Punkt haben wir alles bereit, um unsere Anwendung auf unser PostgreSQL 11 zu verweisen.
Dazu müssen wir zunächst bestätigen, dass wir keine Replikationsverzögerung haben.
Auf dem Master:
world=# SELECT application_name, pg_wal_lsn_diff(pg_current_wal_lsn(), replay_lsn) lag FROM pg_stat_replication;
-[ RECORD 1 ]----+-----
application_name | sub1
lag | 0Und jetzt müssen wir nur noch unseren Endpunkt von unserer Anwendung oder unserem Load Balancer (falls vorhanden) auf den neuen PostgreSQL 11-Server ändern.
Wenn wir einen Load Balancer wie HAProxy haben, können wir ihn so konfigurieren, dass PostgreSQL 10 als aktiv und PostgreSQL 11 als Backup verwendet wird:
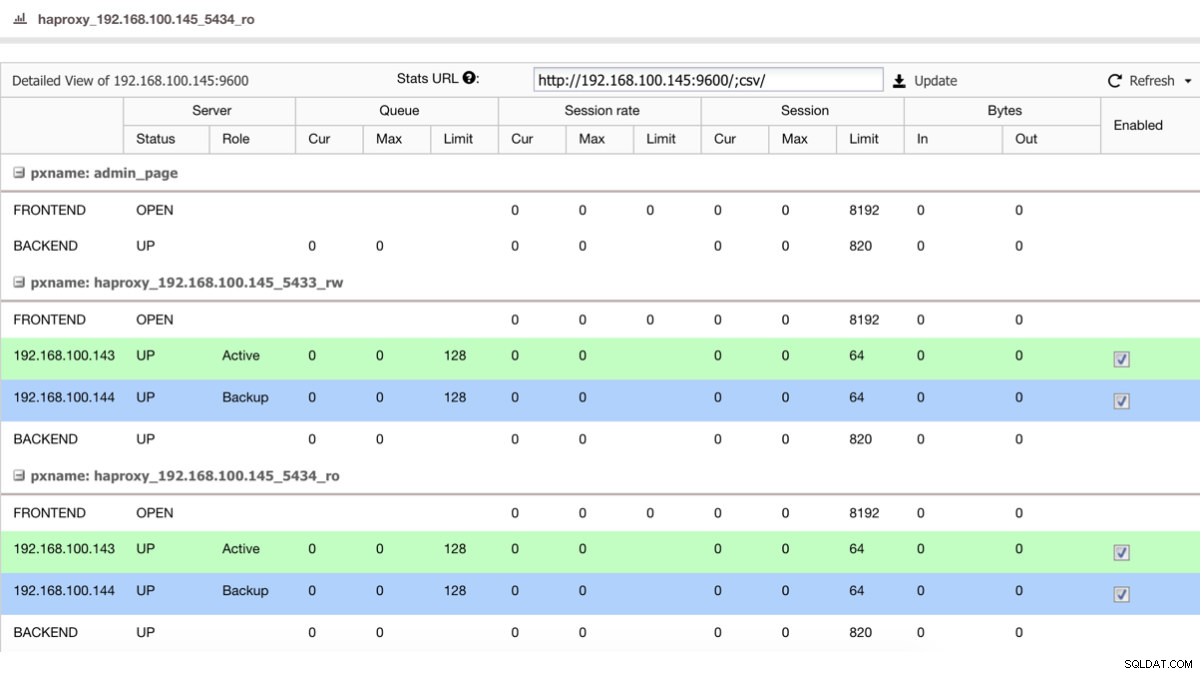 HAProxy-Statusansicht
HAProxy-Statusansicht Wenn Sie also einfach den Master in PostgreSQL 10 herunterfahren, beginnt der Backup-Server, in diesem Fall in PostgreSQL 11, den Datenverkehr auf transparente Weise für den Benutzer/die Anwendung zu empfangen.
Am Ende der Migration können wir das Abonnement in unserem neuen Master in PostgreSQL 11 löschen:
world=# DROP SUBSCRIPTION sub1;
NOTICE: dropped replication slot "sub1" on publisher
DROP SUBSCRIPTIONUnd vergewissern Sie sich, dass es korrekt entfernt wurde:
world=# SELECT * FROM pg_subscription_rel;
(0 rows)
world=# SELECT * FROM pg_stat_subscription;
(0 rows)Einschränkungen
Bevor Sie die logische Replikation verwenden, beachten Sie bitte die folgenden Einschränkungen:
- Das Datenbankschema und die DDL-Befehle werden nicht repliziert. Das anfängliche Schema kann mit pg_dump --schema-only. kopiert werden
- Sequenzdaten werden nicht repliziert. Die Daten in seriellen oder Identitätsspalten, die von Sequenzen unterstützt werden, werden als Teil der Tabelle repliziert, aber die Sequenz selbst würde immer noch den Startwert für den Abonnenten anzeigen.
- Die Replikation von TRUNCATE-Befehlen wird unterstützt, aber beim Abschneiden von Tabellengruppen, die durch Fremdschlüssel verbunden sind, ist Vorsicht geboten. Beim Replizieren einer Kürzungsaktion kürzt der Abonnent dieselbe Gruppe von Tabellen, die auf dem Herausgeber gekürzt wurde, entweder explizit angegeben oder implizit über CASCADE erfasst, abzüglich Tabellen, die nicht Teil des Abonnements sind. Dies funktioniert ordnungsgemäß, wenn alle betroffenen Tabellen Teil desselben Abonnements sind. Wenn jedoch einige Tabellen, die auf dem Abonnenten gekürzt werden sollen, Fremdschlüsselverknüpfungen zu Tabellen haben, die nicht Teil desselben (oder eines beliebigen) Abonnements sind, schlägt die Anwendung der Kürzungsaktion auf dem Abonnenten fehl.
- Große Objekte werden nicht repliziert. Dafür gibt es keine Problemumgehung, außer Daten in normalen Tabellen zu speichern.
- Die Replikation ist nur von Basistabellen zu Basistabellen möglich. Das heißt, die Tabellen auf der Veröffentlichungs- und auf der Abonnementseite müssen normale Tabellen sein, keine Ansichten, materialisierten Ansichten, Partitionsstammtabellen oder Fremdtabellen. Im Fall von Partitionen können Sie eine Partitionshierarchie eins zu eins replizieren, aber Sie können derzeit nicht auf eine anders partitionierte Einrichtung replizieren.
Schlussfolgerung
Ihren PostgreSQL-Server durch regelmäßige Upgrades auf dem neuesten Stand zu halten, war bis zur Version PostgreSQL 10 eine notwendige, aber schwierige Aufgabe.
In diesem Blog haben wir eine kurze Einführung in die logische Replikation gegeben, eine PostgreSQL-Funktion, die nativ in Version 10 eingeführt wurde, und wir haben Ihnen gezeigt, wie sie Ihnen helfen kann, diese Herausforderung mit einer Null-Ausfallzeit-Strategie zu meistern.