Daten gehören wahrscheinlich zu den wertvollsten Vermögenswerten in einem Unternehmen. Aus diesem Grund sollten wir immer einen Disaster Recovery Plan (DRP) haben, um Datenverlust im Falle eines Unfalls oder Hardwareausfalls zu verhindern.
Ein Backup ist die einfachste Form von DR, es reicht jedoch möglicherweise nicht immer aus, um ein akzeptables Recovery Point Objective (RPO) zu gewährleisten. Es wird empfohlen, mindestens drei Backups an verschiedenen physischen Orten zu speichern.
Best Practice schreibt vor, dass Sicherungsdateien lokal auf dem Datenbankserver gespeichert werden sollten (für eine schnellere Wiederherstellung), eine andere auf einem zentralisierten Sicherungsserver und die letzte in der Cloud.
Für diesen Blog werfen wir einen Blick darauf, welche Möglichkeiten Amazon AWS für die Speicherung von PostgreSQL-Backups in der Cloud bietet und zeigen einige Beispiele, wie es geht.
Über Amazon AWS
Amazon AWS ist einer der weltweit fortschrittlichsten Cloud-Anbieter in Bezug auf Funktionen und Dienste mit Millionen von Kunden. Wenn wir unsere PostgreSQL-Datenbanken auf Amazon AWS ausführen möchten, haben wir einige Optionen...
-
Amazon RDS:Damit können wir auf einfache und schnelle Weise eine PostgreSQL-Datenbank (oder andere Datenbanktechnologien) in der Cloud erstellen, verwalten und skalieren.
-
Amazon Aurora:Es ist eine PostgreSQL-kompatible Datenbank, die für die Cloud entwickelt wurde. Laut der AWS-Website ist es dreimal schneller als standardmäßige PostgreSQL-Datenbanken.
-
Amazon EC2:Es ist ein Webdienst, der anpassbare Rechenkapazität in der Cloud bereitstellt. Es bietet Ihnen die vollständige Kontrolle über Ihre Rechenressourcen und ermöglicht Ihnen, alles rund um Ihre Instanzen einzurichten und zu konfigurieren, von Ihrem Betriebssystem bis hin zu Ihren Anwendungen.
Aber tatsächlich müssen wir unsere Datenbanken nicht auf Amazon ausführen lassen, um unsere Backups hier zu speichern.
Speichern von Sicherungen auf Amazon AWS
Es gibt verschiedene Möglichkeiten, unser PostgreSQL-Backup auf AWS zu speichern. Wenn wir unsere PostgreSQL-Datenbank auf AWS betreiben, haben wir mehr Optionen und (da wir uns im selben Netzwerk befinden) könnte es auch schneller sein. Sehen wir uns an, wie AWS uns beim Speichern unserer Sicherungen helfen kann.
AWS-CLI
Lassen Sie uns zuerst unsere Umgebung vorbereiten, um die verschiedenen AWS-Optionen zu testen. Für unsere Beispiele verwenden wir einen lokalen PostgreSQL 11-Server, der auf CentOS 7 ausgeführt wird. Hier müssen wir die AWS CLI gemäß den Anweisungen auf dieser Website installieren.
Wenn wir unsere AWS CLI installiert haben, können wir sie über die Befehlszeile testen:
[example@sqldat.com ~]# aws --version
aws-cli/1.16.225 Python/2.7.5 Linux/4.15.18-14-pve botocore/1.12.215Nun ist der nächste Schritt, unseren neuen Client zu konfigurieren, indem er den aws-Befehl mit der Option configure ausführt.
[example@sqldat.com ~]# aws configure
AWS Access Key ID [None]: AKIA7TMEO21BEBR1A7HR
AWS Secret Access Key [None]: SxrCECrW/RGaKh2FTYTyca7SsQGNUW4uQ1JB8hRp
Default region name [None]: us-east-1
Default output format [None]:Um diese Informationen zu erhalten, können Sie zum IAM-AWS-Bereich gehen und den aktuellen Benutzer überprüfen oder, wenn Sie möchten, einen neuen für diese Aufgabe erstellen.
Danach sind wir bereit, die AWS CLI zu verwenden, um auf unsere Amazon AWS-Services zuzugreifen.
Amazon S3
Dies ist wahrscheinlich die am häufigsten verwendete Option zum Speichern von Backups in der Cloud. Amazon S3 kann beliebige Datenmengen überall im Internet speichern und abrufen. Es handelt sich um einen einfachen Speicherdienst, der eine äußerst langlebige, hochverfügbare und unbegrenzt skalierbare Datenspeicherinfrastruktur zu geringen Kosten bietet.
Amazon S3 bietet eine einfache Webservice-Schnittstelle, die Sie zum Speichern und Abrufen beliebiger Datenmengen jederzeit und überall im Internet und (mit der AWS CLI oder AWS SDK) von Ihnen verwenden können kann es mit verschiedenen Systemen und Programmiersprachen integrieren.
Wie man es benutzt
Amazon S3 verwendet Buckets. Sie sind einzigartige Container für alles, was Sie in Amazon S3 speichern. Der erste Schritt besteht also darin, auf die Amazon S3-Verwaltungskonsole zuzugreifen und einen neuen Bucket zu erstellen.
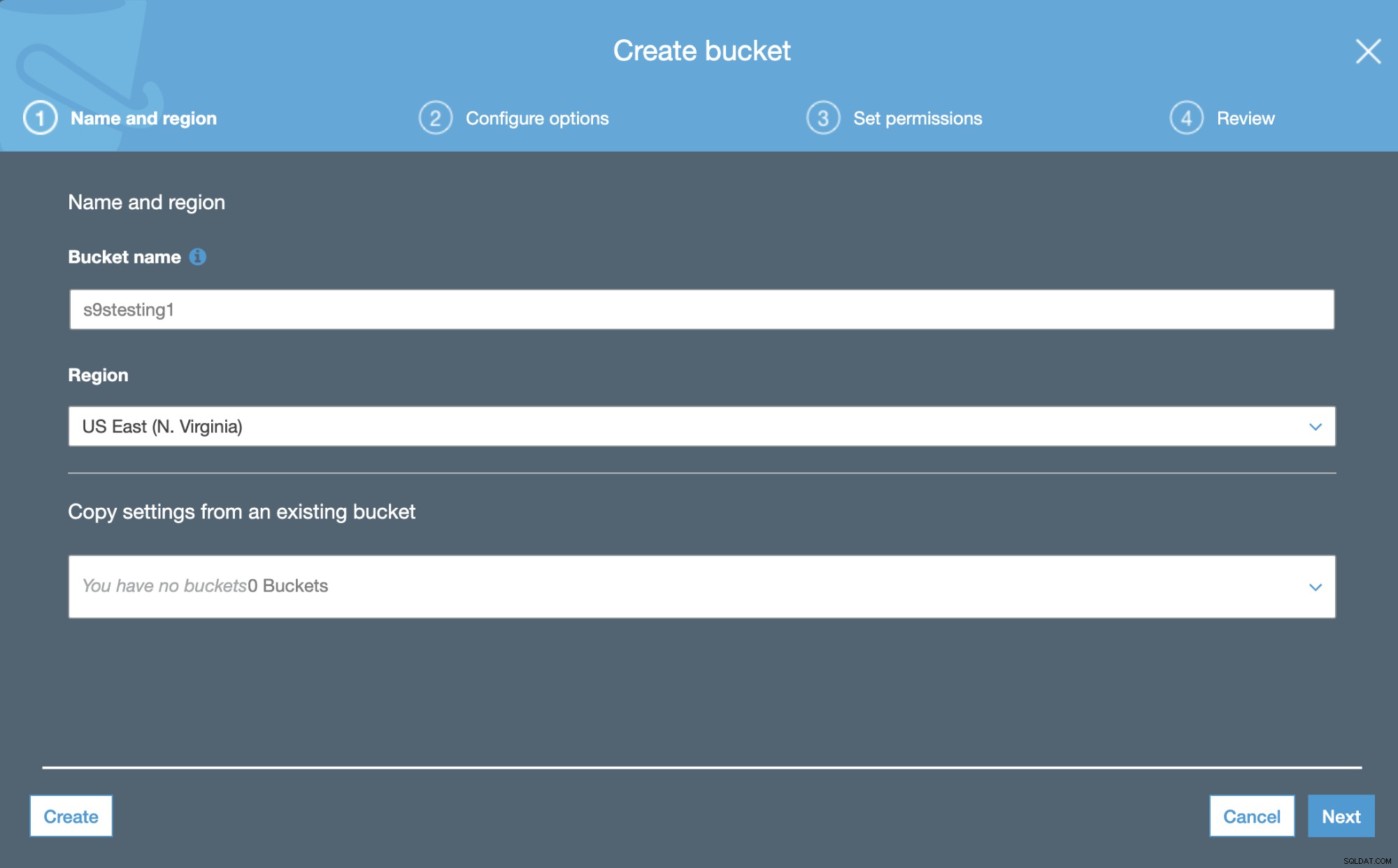
Im ersten Schritt müssen wir nur den Bucket-Namen und die AWS-Region.
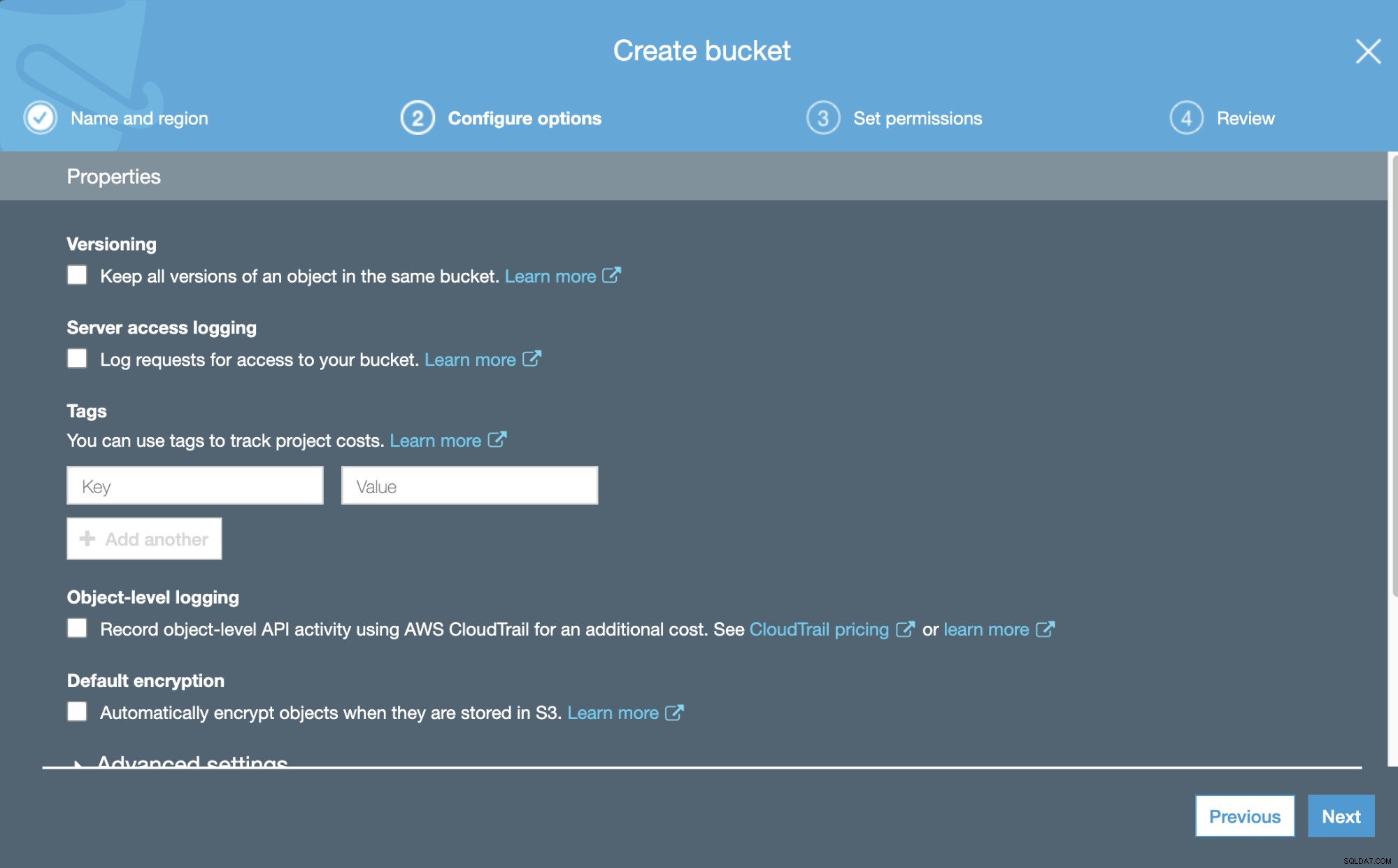
Jetzt können wir einige Details zu unserem neuen Bucket konfigurieren, wie Versionierung und Protokollierung.

Und dann können wir die Berechtigungen für diesen neuen Bucket festlegen.
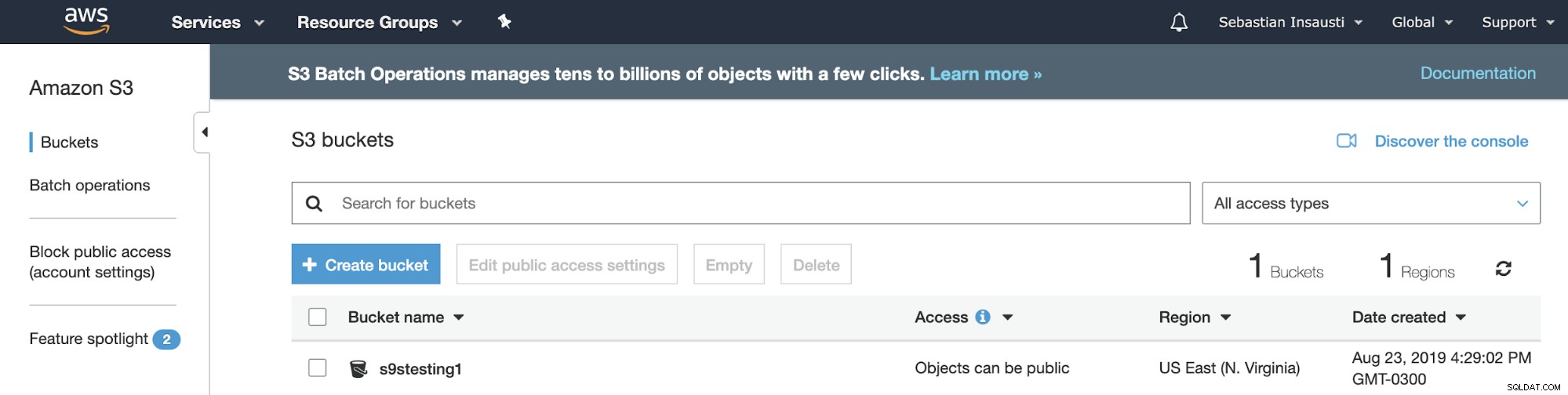
Jetzt haben wir unseren Bucket erstellt, mal sehen, wie wir ihn verwenden können unsere PostgreSQL-Backups speichern.
Lassen Sie uns zuerst unseren Client testen, der ihn mit S3 verbindet.
[example@sqldat.com ~]# aws s3 ls
2019-08-23 19:29:02 s9stesting1Es funktioniert! Mit dem vorherigen Befehl listen wir die aktuell erstellten Buckets auf.
So, jetzt können wir das Backup einfach auf den S3-Dienst hochladen. Dazu können wir den Befehl aws sync oder aws cp verwenden.
[example@sqldat.com ~]# aws s3 sync /root/backups/BACKUP-5/ s3://s9stesting1/backups/
upload: backups/BACKUP-5/cmon_backup.metadata to s3://s9stesting1/backups/cmon_backup.metadata
upload: backups/BACKUP-5/cmon_backup.log to s3://s9stesting1/backups/cmon_backup.log
upload: backups/BACKUP-5/base.tar.gz to s3://s9stesting1/backups/base.tar.gz
[example@sqldat.com ~]#
[example@sqldat.com ~]# aws s3 cp /root/backups/BACKUP-6/pg_dump_2019-08-23_205919.sql.gz s3://s9stesting1/backups/
upload: backups/BACKUP-6/pg_dump_2019-08-23_205919.sql.gz to s3://s9stesting1/backups/pg_dump_2019-08-23_205919.sql.gz
[example@sqldat.com ~]# Wir können den Bucket-Inhalt von der AWS-Website überprüfen.
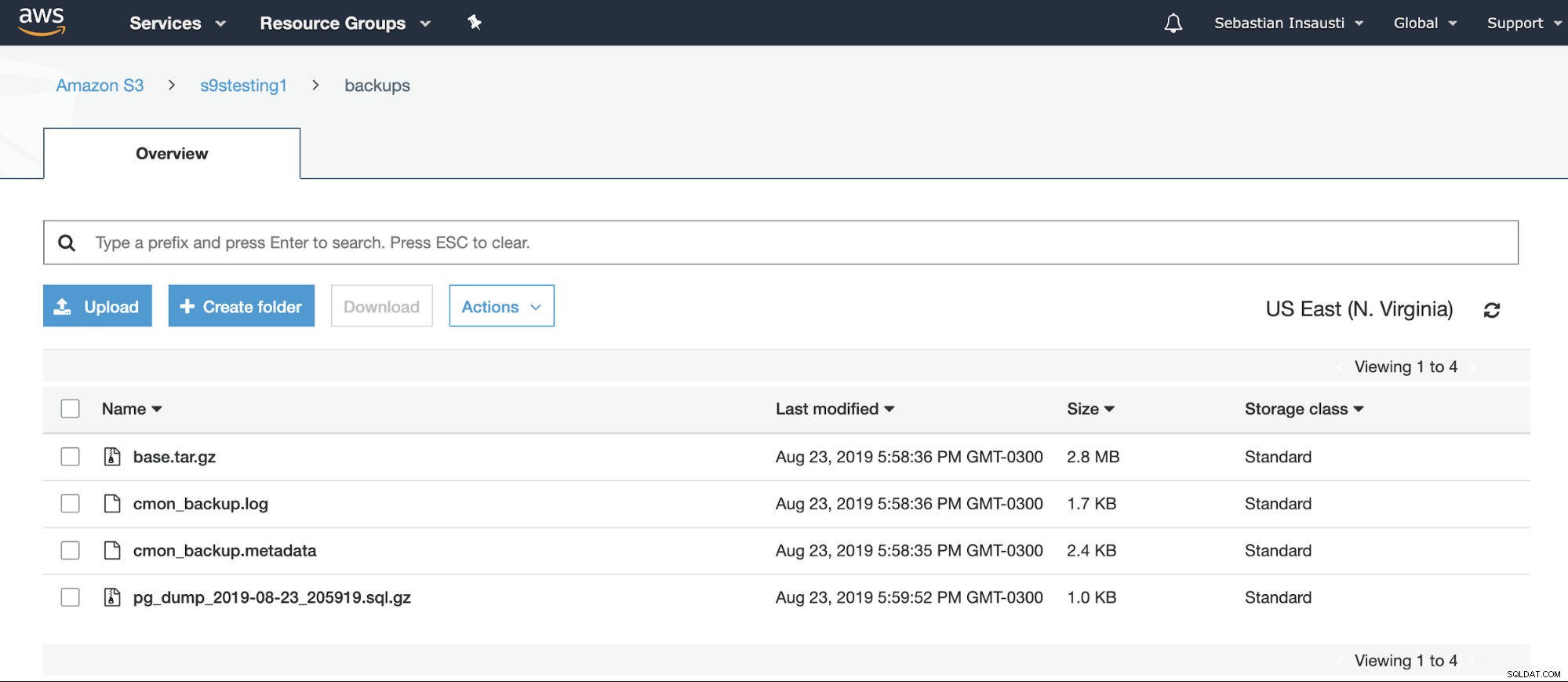
Oder sogar über die AWS CLI.
[example@sqldat.com ~]# aws s3 ls s3://s9stesting1/backups/
2019-08-23 19:29:31 0
2019-08-23 20:58:36 2974633 base.tar.gz
2019-08-23 20:58:36 1742 cmon_backup.log
2019-08-23 20:58:35 2419 cmon_backup.metadata
2019-08-23 20:59:52 1028 pg_dump_2019-08-23_205919.sql.gzWeitere Informationen zur AWS S3 CLI finden Sie in der offiziellen AWS-Dokumentation.
Amazonas-S3-Gletscher
Dies ist die kostengünstigere Version von Amazon S3. Der Hauptunterschied zwischen ihnen ist Geschwindigkeit und Zugänglichkeit. Sie können Amazon S3 Glacier verwenden, wenn die Speicherkosten niedrig bleiben müssen und Sie keinen Millisekundenzugriff auf Ihre Daten benötigen. Die Verwendung ist ein weiterer wichtiger Unterschied zwischen ihnen.
Wie man es benutzt
Anstelle von Buckets verwendet Amazon S3 Glacier Vaults. Es ist ein Container zum Speichern von Objekten. Der erste Schritt besteht also darin, auf die Amazon S3 Glacier Management Console zuzugreifen und einen neuen Tresor zu erstellen.
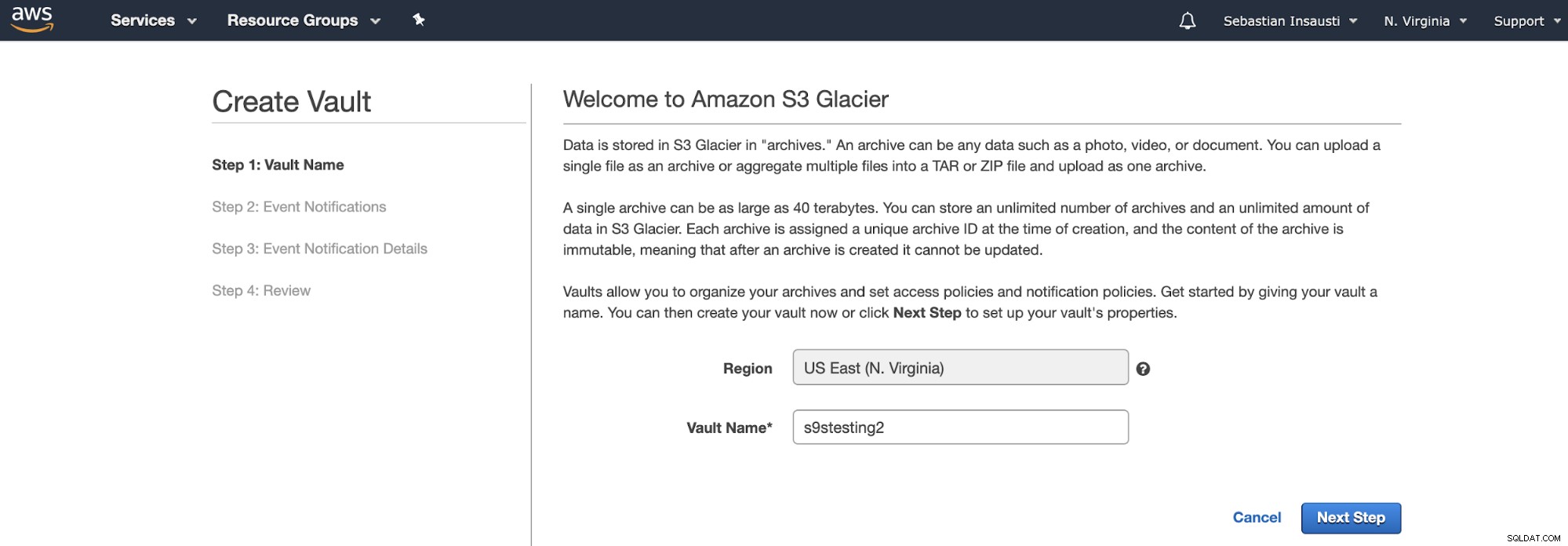
Hier müssen wir den Tresornamen und die Region hinzufügen und in Im nächsten Schritt können wir die Ereignisbenachrichtigungen aktivieren, die den Amazon Simple Notification Service (Amazon SNS) verwenden.
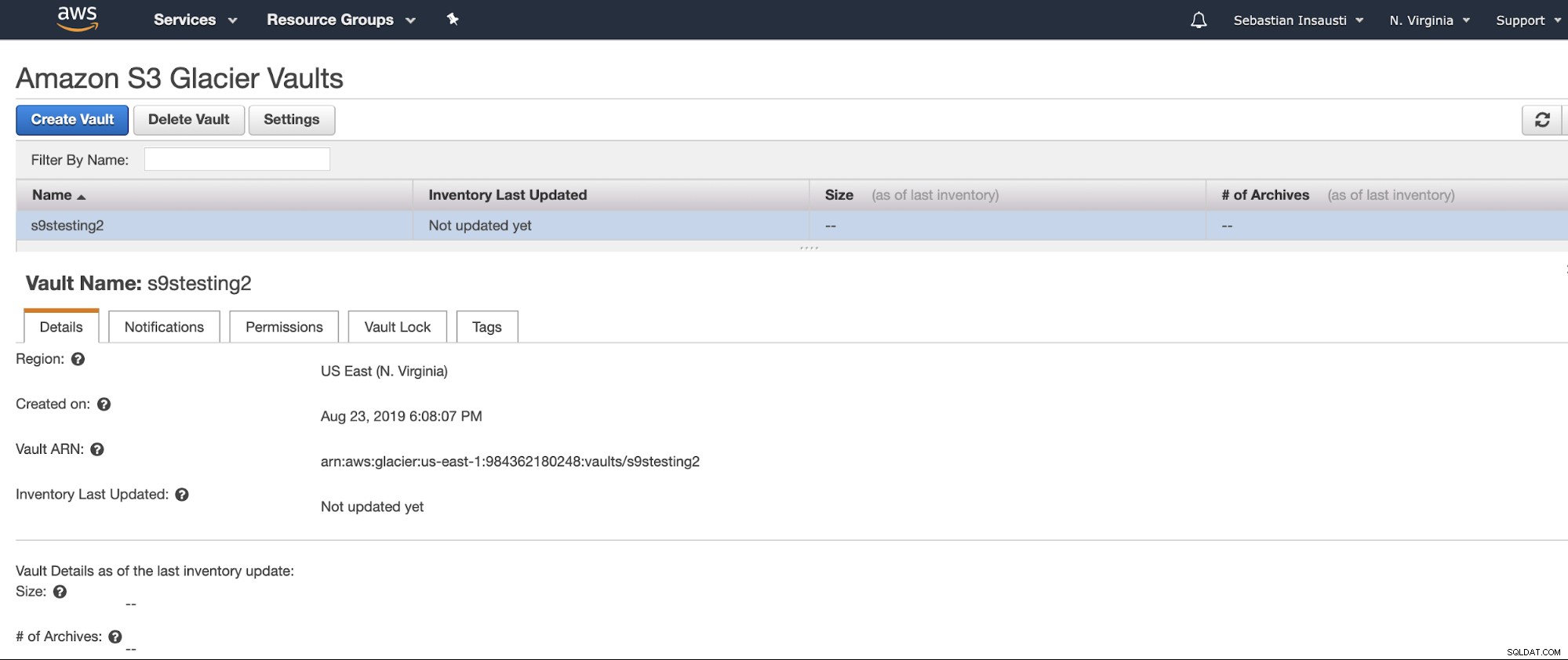
Jetzt haben wir unseren Tresor erstellt und können über die AWS CLI darauf zugreifen .
[example@sqldat.com ~]# aws glacier describe-vault --account-id - --vault-name s9stesting2
{
"SizeInBytes": 0,
"VaultARN": "arn:aws:glacier:us-east-1:984227183428:vaults/s9stesting2",
"NumberOfArchives": 0,
"CreationDate": "2019-08-23T21:08:07.943Z",
"VaultName": "s9stesting2"
}Es funktioniert. Jetzt können wir also unser Backup hier hochladen.
[example@sqldat.com ~]# aws glacier upload-archive --body /root/backups/BACKUP-6/pg_dump_2019-08-23_205919.sql.gz --account-id - --archive-description "Backup upload test" --vault-name s9stesting2
{
"archiveId": "ddgCJi_qCJaIVinEW-xRl4I_0u2a8Ge5d2LHfoFBlO6SLMzG_0Cw6fm-OLJy4ZH_vkSh4NzFG1hRRZYDA-QBCEU4d8UleZNqsspF6MI1XtZFOo_bVcvIorLrXHgd3pQQmPbxI8okyg",
"checksum": "258faaa90b5139cfdd2fb06cb904fe8b0c0f0f80cba9bb6f39f0d7dd2566a9aa",
"location": "/984227183428/vaults/s9stesting2/archives/ddgCJi_qCJaIVinEW-xRl4I_0u2a8Ge5d2LHfoFBlO6SLMzG_0Cw6fm-OLJy4ZH_vkSh4NzFG1hRRZYDA-QBCEU4d8UleZNqsspF6MI1XtZFOo_bVcvIorLrXHgd3pQQmPbxI8okyg"
}Eine wichtige Sache ist, dass der Vault-Status etwa einmal pro Tag aktualisiert wird, also sollten wir warten, bis die Datei hochgeladen wird.
[example@sqldat.com ~]# aws glacier describe-vault --account-id - --vault-name s9stesting2
{
"SizeInBytes": 33796,
"VaultARN": "arn:aws:glacier:us-east-1:984227183428:vaults/s9stesting2",
"LastInventoryDate": "2019-08-24T06:37:02.598Z",
"NumberOfArchives": 1,
"CreationDate": "2019-08-23T21:08:07.943Z",
"VaultName": "s9stesting2"
}Hier haben wir unsere Datei auf unseren S3 Glacier Vault hochgeladen.
Weitere Informationen zur AWS Glacier CLI finden Sie in der offiziellen AWS-Dokumentation.
EC2
Diese Backup-Speicheroption ist teurer und zeitaufwändiger, aber sie ist nützlich, wenn Sie die vollständige Kontrolle über die Backup-Speicherumgebung haben und benutzerdefinierte Aufgaben für die Backups ausführen möchten (z. B. Backup-Verifizierung .)
Amazon EC2 (Elastic Compute Cloud) ist ein Webdienst, der anpassbare Rechenkapazität in der Cloud bereitstellt. Es bietet Ihnen die vollständige Kontrolle über Ihre Rechenressourcen und ermöglicht Ihnen, alles rund um Ihre Instanzen einzurichten und zu konfigurieren, von Ihrem Betriebssystem bis hin zu Ihren Anwendungen. Außerdem können Sie die Kapazität schnell sowohl nach oben als auch nach unten skalieren, wenn sich Ihre Rechenanforderungen ändern.
Amazon EC2 unterstützt verschiedene Betriebssysteme wie Amazon Linux, Ubuntu, Windows Server, Red Hat Enterprise Linux, SUSE Linux Enterprise Server, Fedora, Debian, CentOS, Gentoo Linux, Oracle Linux und FreeBSD.
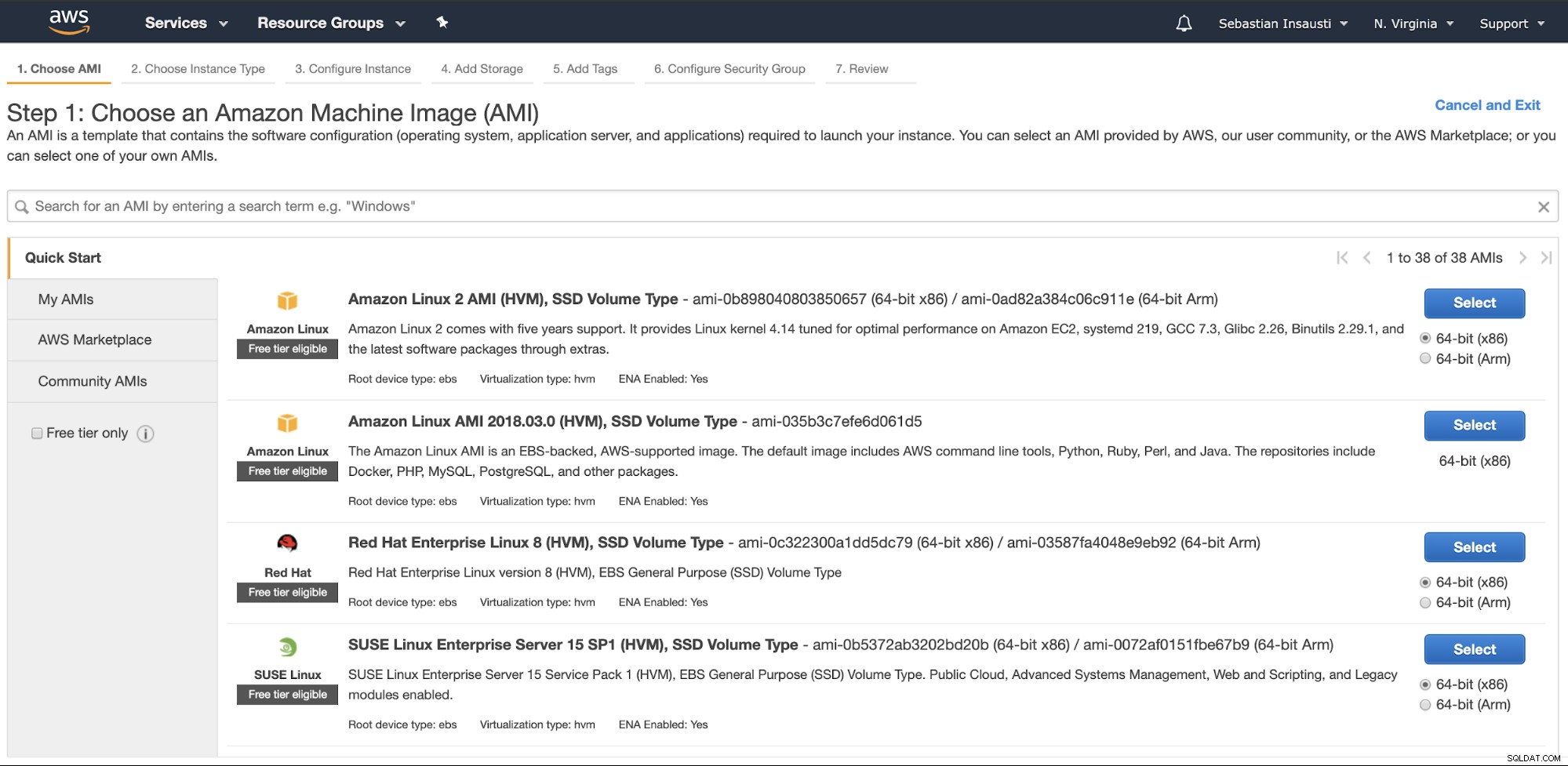
P>Wie man es benutzt
Gehen Sie zum Abschnitt Amazon EC2 und klicken Sie auf Instanz starten. Im ersten Schritt müssen Sie das EC2-Instance-Betriebssystem auswählen.
Im nächsten Schritt müssen Sie die Ressourcen für die neue Instanz auswählen.
Dann können Sie eine detailliertere Konfiguration wie Netzwerk, Subnetz und mehr angeben .
Jetzt können wir dieser neuen Instanz mehr Speicherkapazität hinzufügen und so ein Backup-Server, wir sollten es tun.
Wenn wir die Erstellungsaufgabe abgeschlossen haben, können wir zum Abschnitt Instanzen gehen siehe unsere neue EC2-Instanz.
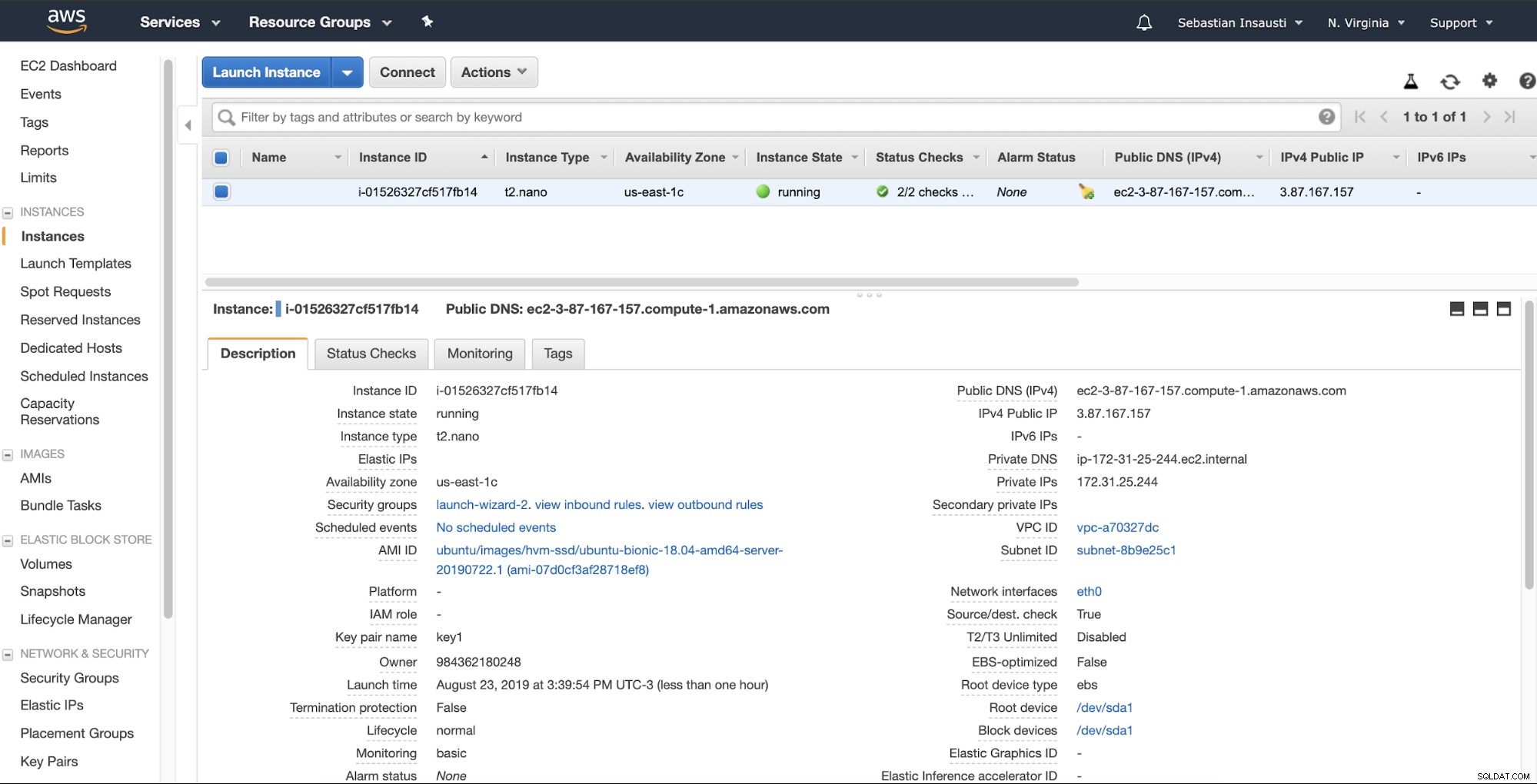
Wenn die Instanz bereit ist (Instanzstatus läuft), können Sie die Datei speichern Backups hier beispielsweise per SSH oder FTP über das von AWS erstellte Public DNS versenden. Sehen wir uns ein Beispiel mit Rsync und ein weiteres mit dem SCP-Linux-Befehl an.
[example@sqldat.com ~]# rsync -avzP -e "ssh -i /home/user/key1.pem" /root/backups/BACKUP-11/base.tar.gz example@sqldat.com:/backups/20190823/
sending incremental file list
base.tar.gz
4,091,563 100% 2.18MB/s 0:00:01 (xfr#1, to-chk=0/1)
sent 3,735,675 bytes received 35 bytes 574,724.62 bytes/sec
total size is 4,091,563 speedup is 1.10
[example@sqldat.com ~]#
[example@sqldat.com ~]# scp -i /tmp/key1.pem /root/backups/BACKUP-12/pg_dump_2019-08-25_211903.sql.gz example@sqldat.com:/backups/20190823/
pg_dump_2019-08-25_211903.sql.gz 100% 24KB 76.4KB/s 00:00AWS-Sicherung
AWS Backup ist ein zentralisierter Backup-Service, der Ihnen Backup-Verwaltungsfunktionen wie Backup-Planung, Aufbewahrungsverwaltung und Backup-Überwachung sowie zusätzliche Funktionen wie Lifecycle-Backups zu geringen Kosten bietet Speicherebene, Backup-Speicher und Verschlüsselung, die unabhängig von den Quelldaten ist, und Backup-Zugriffsrichtlinien.
Sie können AWS Backup verwenden, um Sicherungen von EBS-Volumes, RDS-Datenbanken, DynamoDB-Tabellen, EFS-Dateisystemen und Storage Gateway-Volumes zu verwalten.
Wie man es benutzt
Gehen Sie zum Abschnitt AWS Backup in der AWS Management Console.
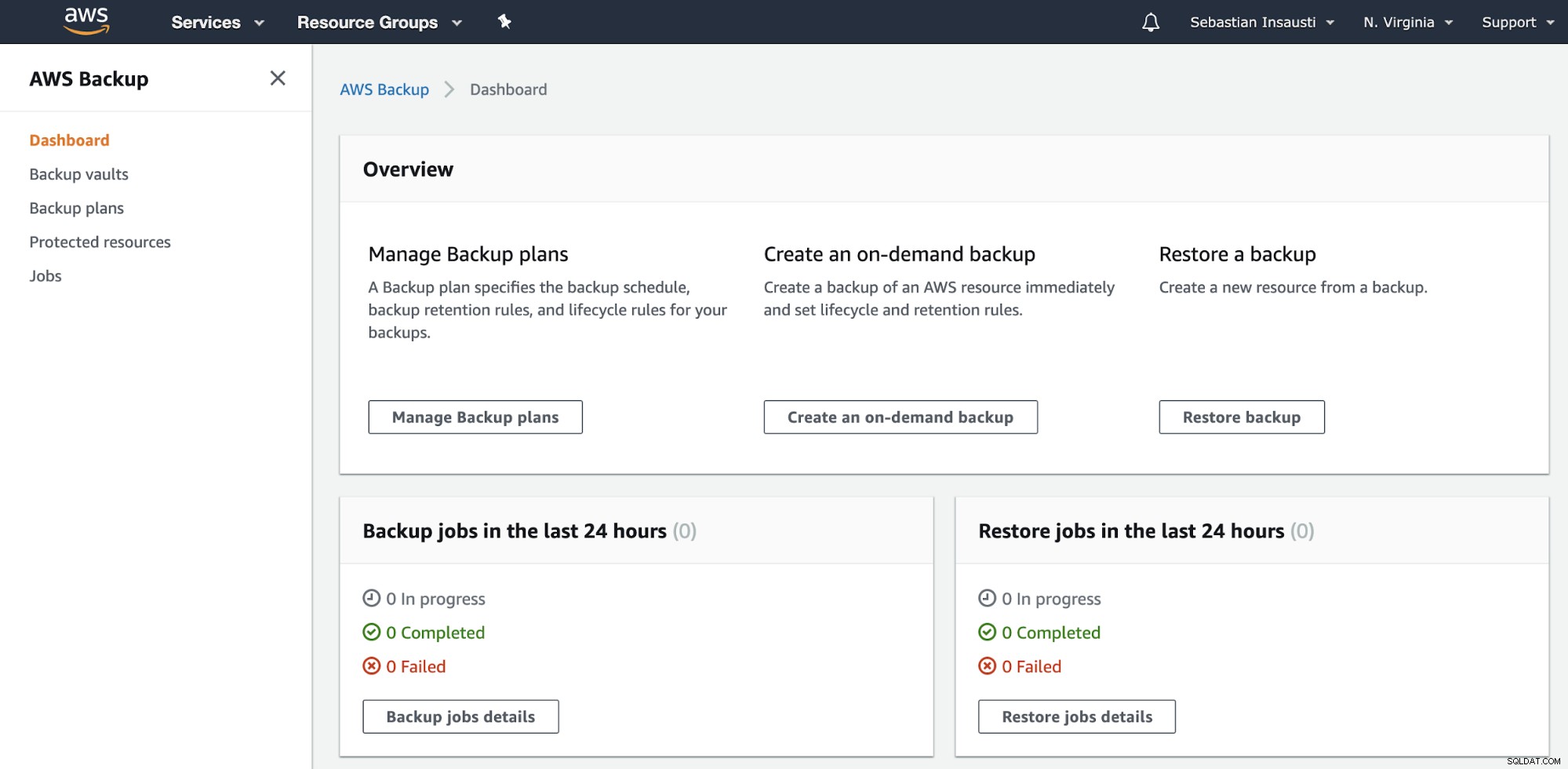
Hier haben Sie verschiedene Optionen, wie z. B. Planen, Erstellen oder Wiederherstellen einer Sicherung . Mal sehen, wie man ein neues Backup erstellt.
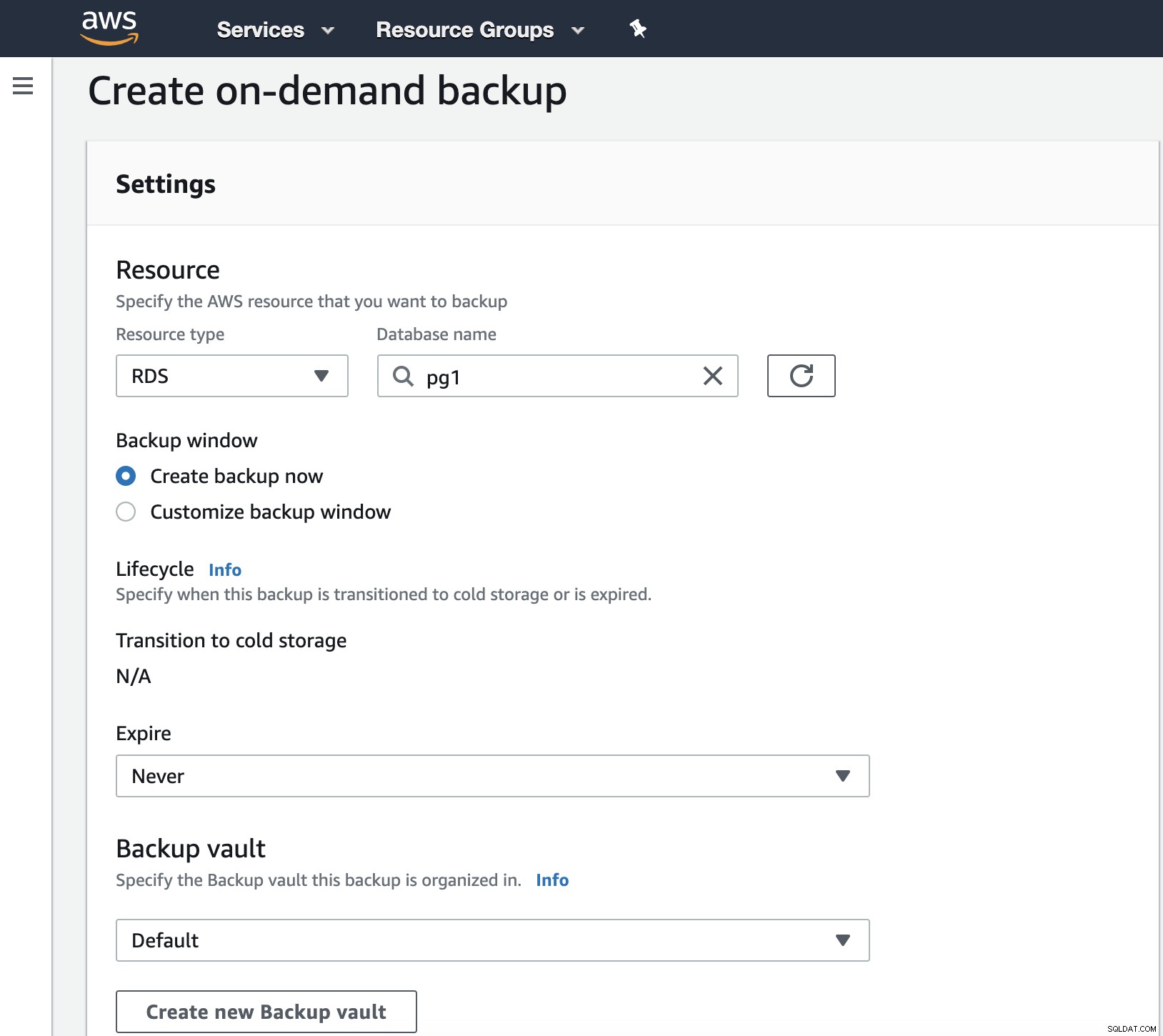
In diesem Schritt müssen wir den Ressourcentyp auswählen, der DynamoDB sein kann, RDS, EBS, EFS oder Storage Gateway und weitere Details wie Ablaufdatum, Backup-Tresor und die IAM-Rolle.
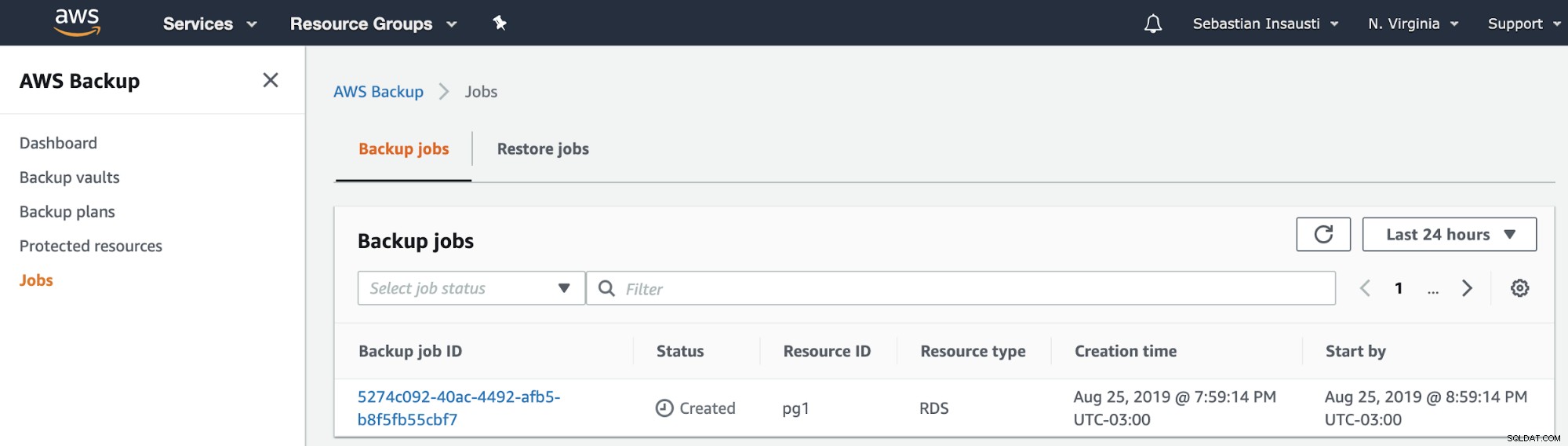
Dann sehen wir den neu erstellten Job im Abschnitt AWS Backup Jobs .
Schnappschuss
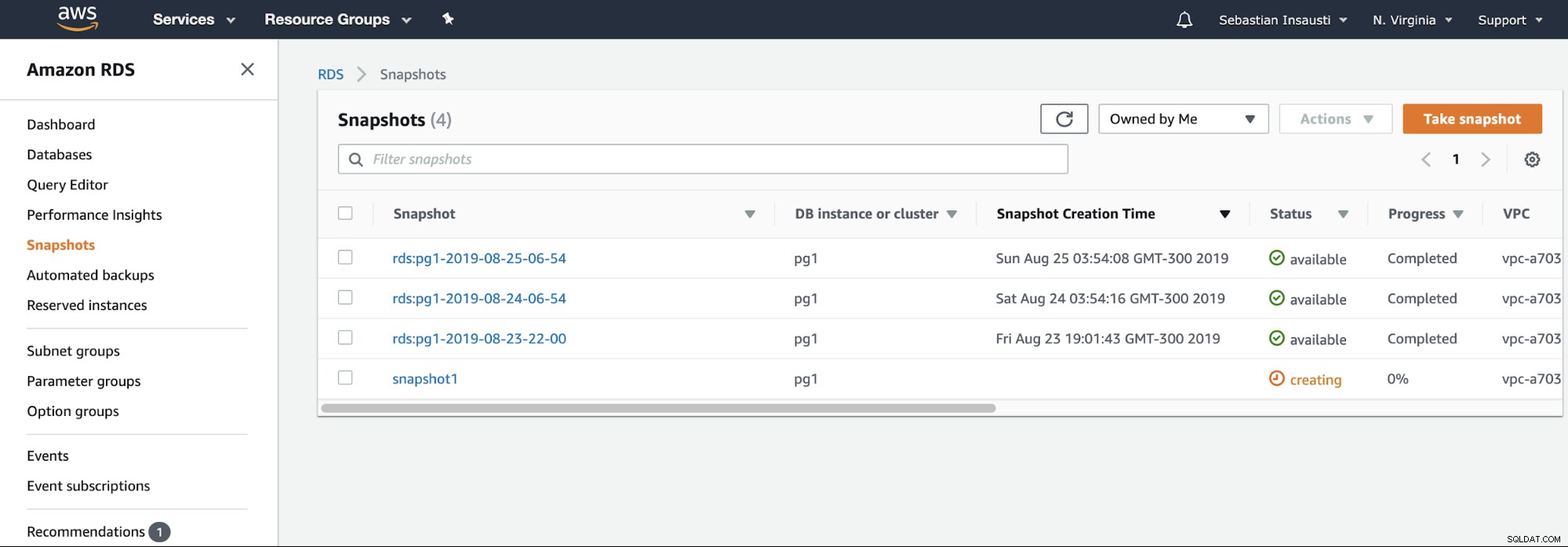
Jetzt können wir diese bekannte Option in allen Virtualisierungsumgebungen erwähnen. Der Snapshot ist eine Sicherung, die zu einem bestimmten Zeitpunkt erstellt wurde, und AWS erlaubt uns, ihn für die AWS-Produkte zu verwenden. Sehen wir uns ein Beispiel für einen RDS-Snapshot an.
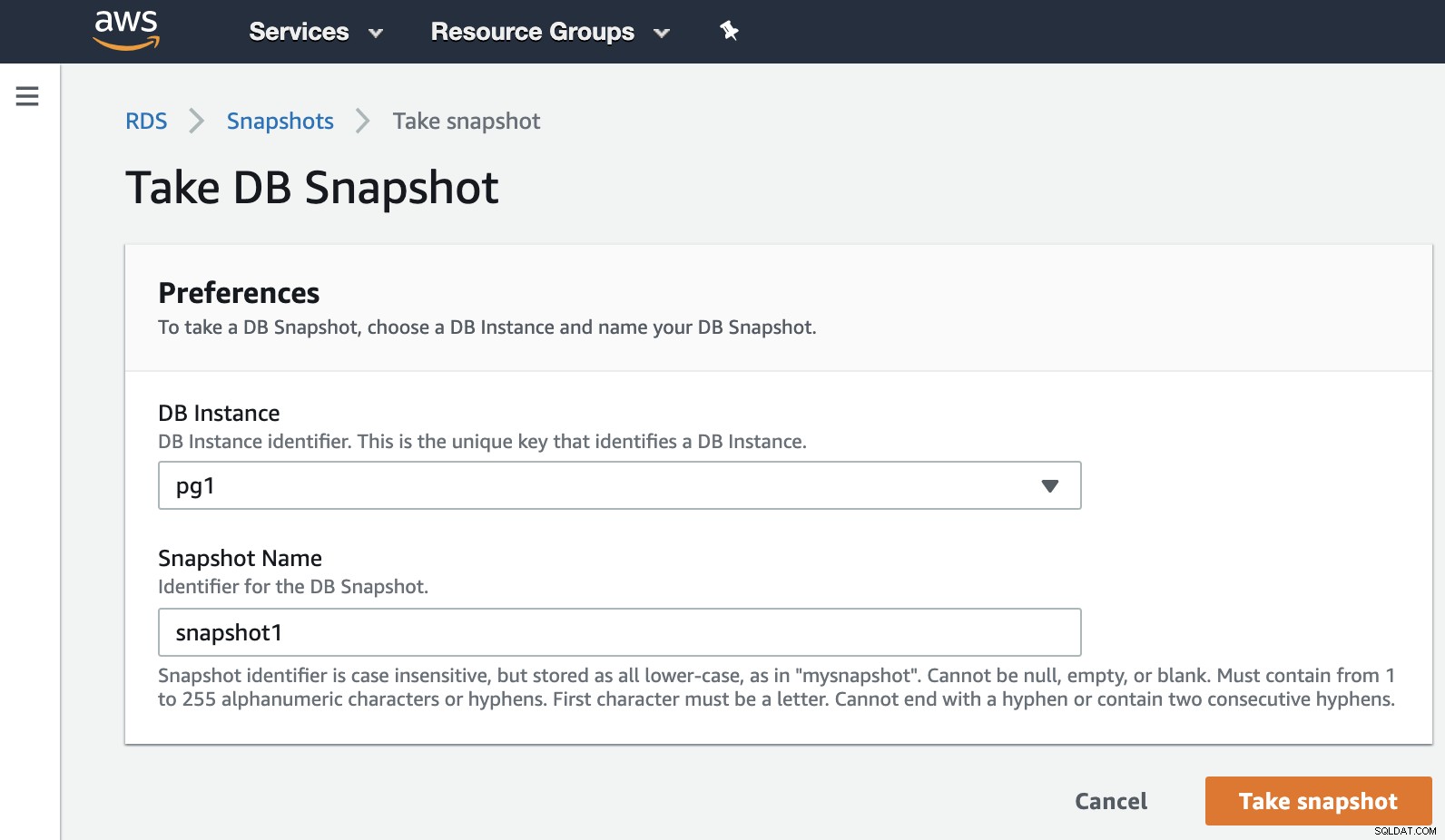
Wir müssen nur die Instanz auswählen und den Snapshot-Namen hinzufügen, und fertig es. Wir können diesen und den vorherigen Schnappschuss im Abschnitt RDS-Schnappschuss sehen.
Verwalten Ihrer Backups mit ClusterControl
ClusterControl ist ein umfassendes Verwaltungssystem für Open-Source-Datenbanken, das Bereitstellungs- und Verwaltungsfunktionen sowie Zustands- und Leistungsüberwachung automatisiert. ClusterControl unterstützt die Bereitstellung, Verwaltung, Überwachung und Skalierung für verschiedene Datenbanktechnologien und -umgebungen, einschließlich EC2. So können wir beispielsweise unsere EC2-Instanz auf AWS erstellen und unseren Datenbankdienst mit ClusterControl bereitstellen/importieren.

Erstellen einer Sicherung
Gehen Sie für diese Aufgabe zu ClusterControl -> Cluster auswählen -> Backup -> Backup erstellen.
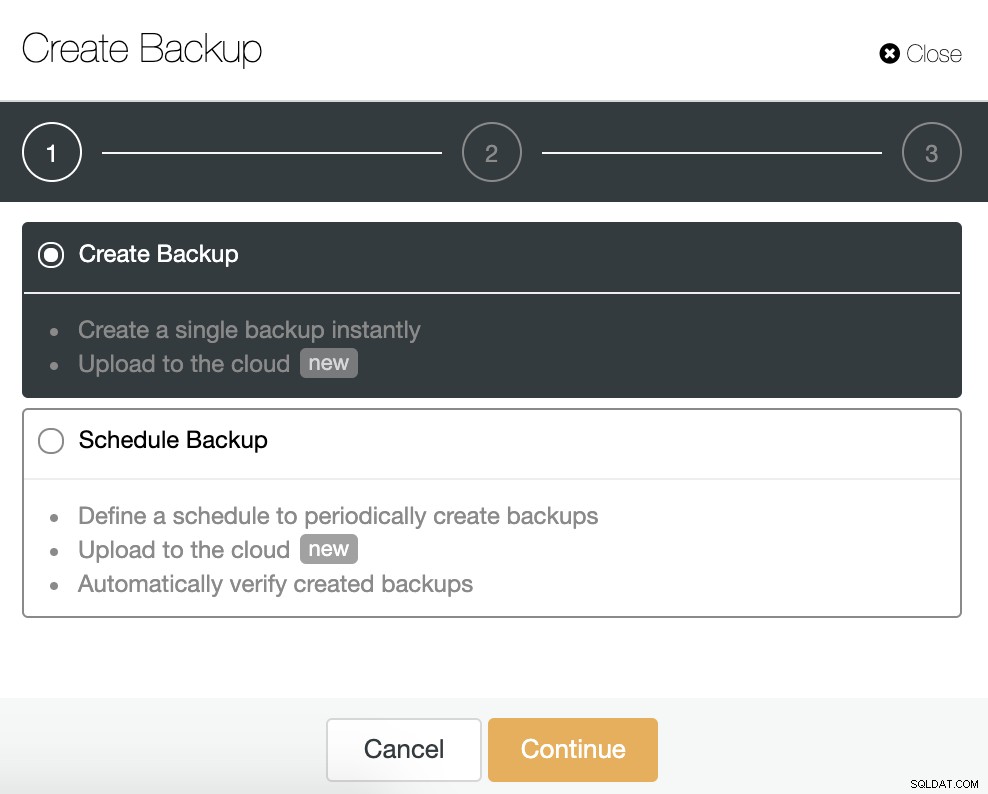
Wir können ein neues Backup erstellen oder ein geplantes konfigurieren. Für unser Beispiel erstellen wir sofort ein einzelnes Backup.
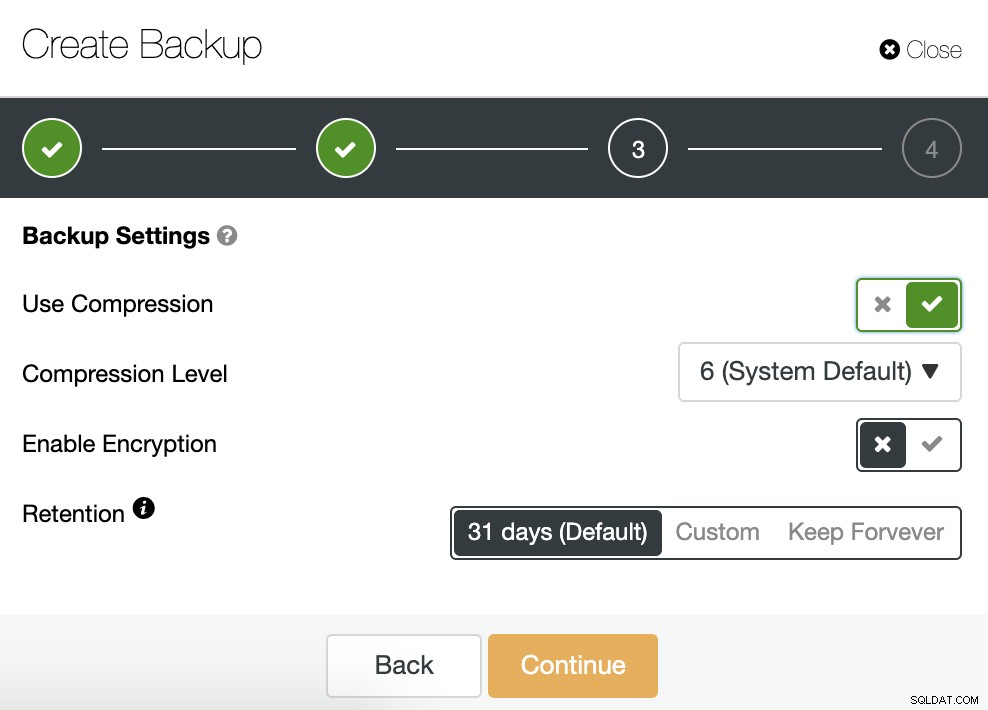
Wir müssen eine Methode auswählen, den Server, von dem die Sicherung genommen wird , und wo wir die Sicherung speichern möchten. Wir können unser Backup auch in die Cloud (AWS, Google oder Azure) hochladen, indem wir die entsprechende Schaltfläche aktivieren.
Dann legen wir die Verwendung der Komprimierung, die Komprimierungsstufe, die Verschlüsselung und die Aufbewahrung fest Zeitraum für unser Backup.
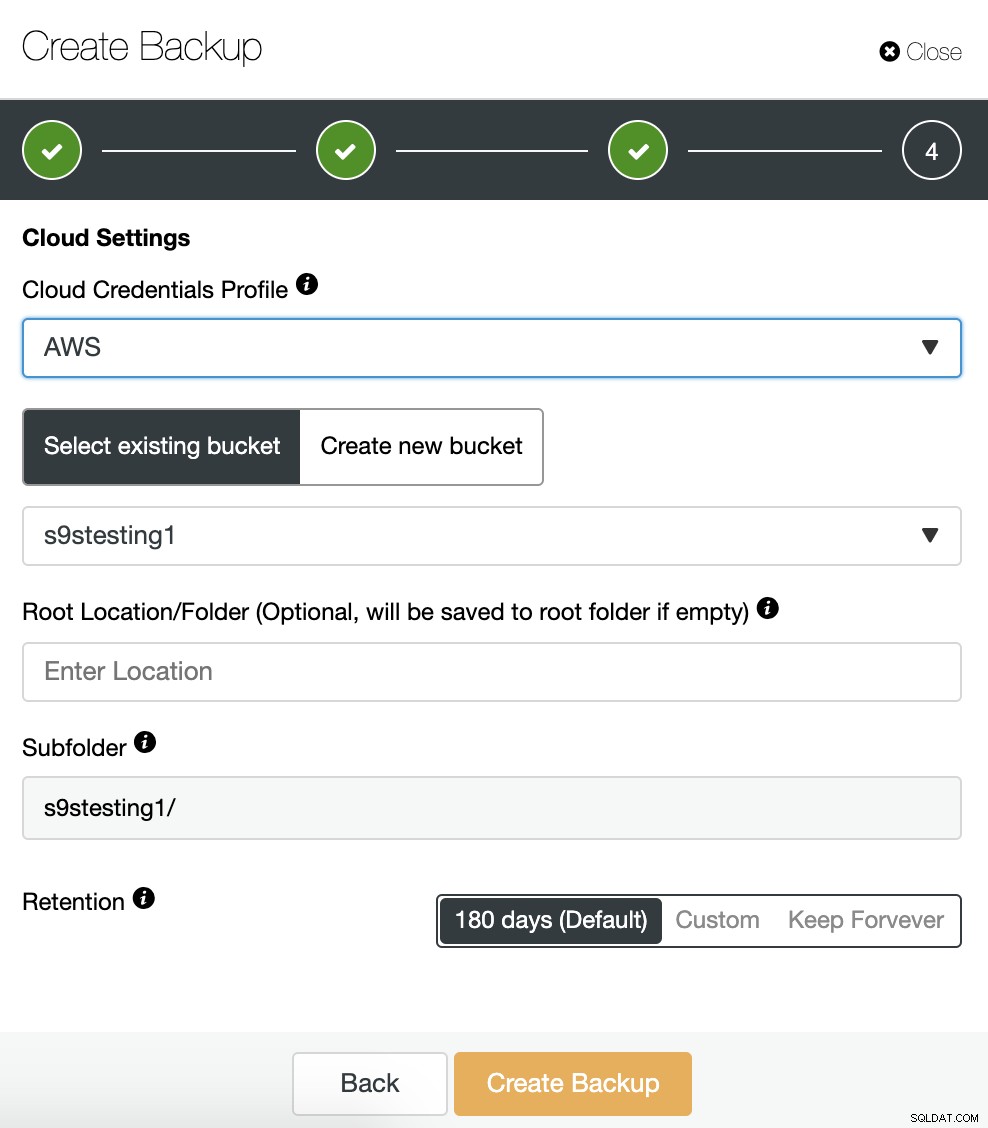
Wenn wir die Option zum Hochladen der Sicherung in die Cloud aktiviert haben, werden wir sehen einen Abschnitt zur Angabe des Cloud-Anbieters (in diesem Fall AWS) und der Anmeldeinformationen (ClusterControl -> Integrations -> Cloud Providers). Für AWS verwendet es den S3-Service, daher müssen wir einen Bucket auswählen oder sogar einen neuen erstellen, um unsere Backups zu speichern.
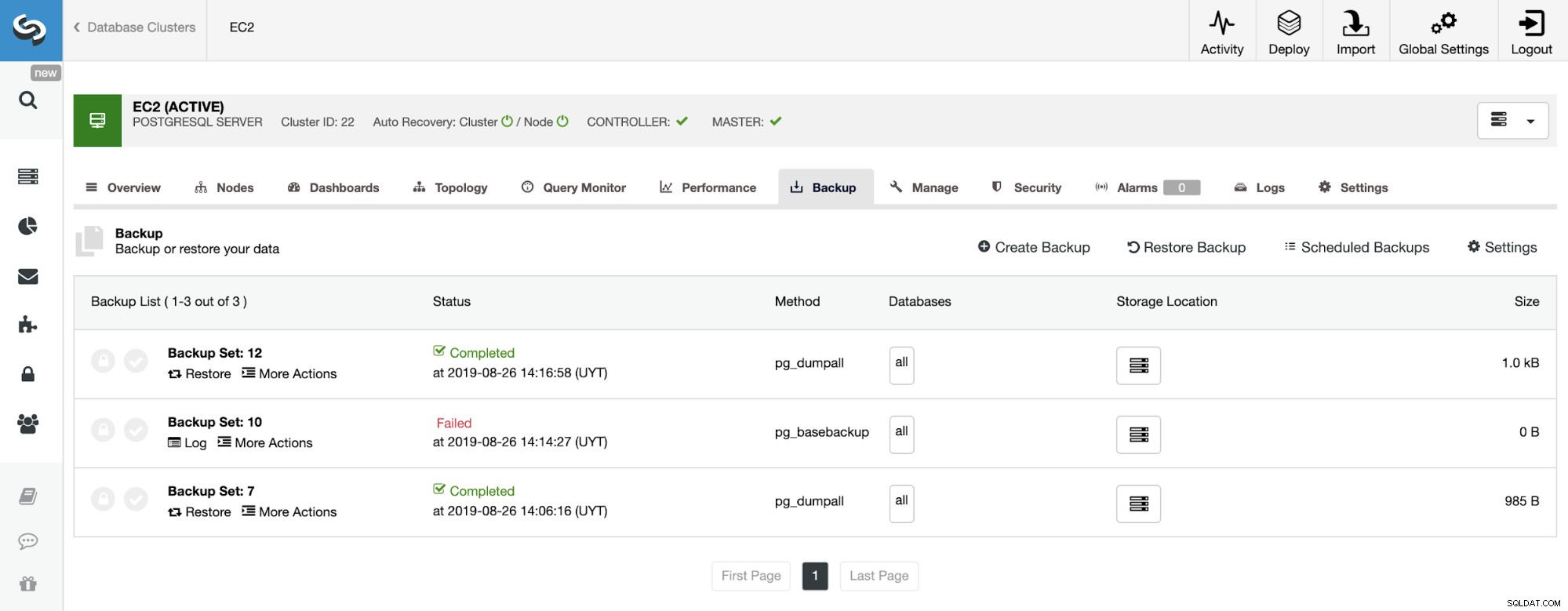
Im Sicherungsabschnitt können wir den Fortschritt der Sicherung sehen und Informationen wie Methode, Größe, Ort und mehr.
Fazit
Amazon AWS ermöglicht es uns, unsere PostgreSQL-Backups zu speichern, unabhängig davon, ob wir es als Datenbank-Cloud-Anbieter verwenden oder nicht. Um einen effektiven Sicherungsplan zu haben, sollten Sie erwägen, mindestens eine Sicherungskopie der Datenbank in der Cloud zu speichern, um Datenverluste im Falle eines Hardwareausfalls in einem anderen Sicherungsspeicher zu vermeiden. In der Cloud können Sie so viele Backups speichern, wie Sie speichern oder bezahlen möchten.