Dies ist der zweite Teil der Multiserie Benchmarking Managed PostgreSQL Cloud Solutions . In Teil 1 habe ich einen Überblick über die verfügbaren Tools gegeben, den Grund für die Verwendung des AWS-Benchmark-Verfahrens für Aurora sowie die zu verwendenden PostgreSQL-Versionen erörtert und Amazon Aurora PostgreSQL 10.6 überprüft.
In diesem Teil werden pgbench und sysbench gegen Amazon RDS für PostgreSQL 11.1 ausgeführt. Zum Zeitpunkt der Erstellung dieses Artikels ist die neueste PostgreSQL-Version 11.2, die vor etwa einem Monat veröffentlicht wurde.
Es lohnt sich, einen Moment innezuhalten, um schnell die derzeit in der Cloud verfügbaren PostgreSQL-Versionen zu überprüfen:
- Amazon Aurora PostgreSQL 10.6
- Amazon RDS für PostgreSQL 11.1
- Google Cloud SQL für PostgreSQL 9.6
- Microsoft Azure PostgreSQL 10.5
Amazon ist mit seinem RDS-Angebot erneut ein Gewinner, indem es die neueste Version von PostgreSQL bereitstellt. Wie im RDS-Forum angekündigt, stellte AWS PostgreSQL 11.1 am 13. März zur Verfügung, also vier Monate nach der Veröffentlichung durch die Community.
Umgebung einrichten
Ein paar Anmerkungen zu den Einschränkungen im Zusammenhang mit dem Einrichten der Umgebung und dem Ausführen des Benchmarks, Punkte, die in Teil 1 dieser Serie ausführlicher besprochen wurden:
- Keine Änderungen an den standardmäßigen GUC-Einstellungen des Cloud-Anbieters.
- Die Verbindungen sind auf maximal 1.000 begrenzt, da der AWS-Patch für pgbench nicht sauber angewendet wurde. In einem ähnlichen Zusammenhang musste ich den AWS-Timing-Patch von dieser pgsql-hackers-Einreichung herunterladen, da er nicht mehr unter dem im Handbuch erwähnten Link verfügbar war.
- Das Enhanced Networking muss für die Clientinstanz aktiviert sein.
- Die Datenbank enthält kein Replikat.
- Der Datenbankspeicher ist nicht verschlüsselt.
- Sowohl die Client- als auch die Zielinstanzen befinden sich in derselben Verfügbarkeitszone.
Richten Sie zuerst den Client und die Datenbankinstanzen ein:
- Der Client ist eine on demand r4.8xlarge EC2-Instanz:
- vCPU:32 (16 Kerne x 2 Threads/Kern)
- RAM:244 GiB
- Speicher:EBS-optimiert
- Netzwerk:10 Gigabit
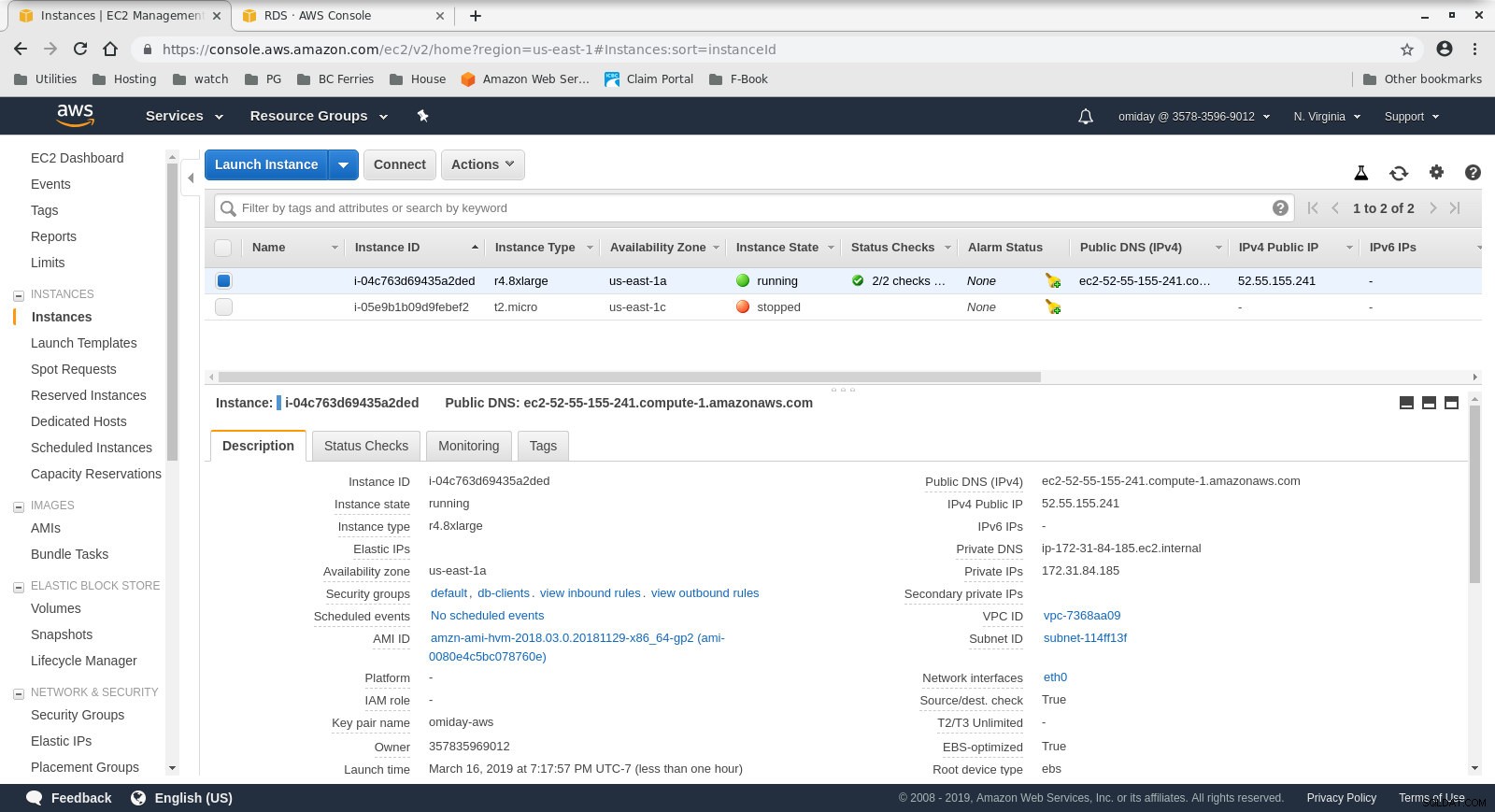 Clientinstanzkonfiguration
Clientinstanzkonfiguration - Der DB-Cluster ist ein On-Demand-db.r4.2xlarge:
- vCPU:8
- RAM:61 GiB
- Speicher:EBS-optimiert
- Netzwerk:1.750 Mbit/s maximale Bandbreite bei einer Verbindung mit bis zu 10 Gbit/s
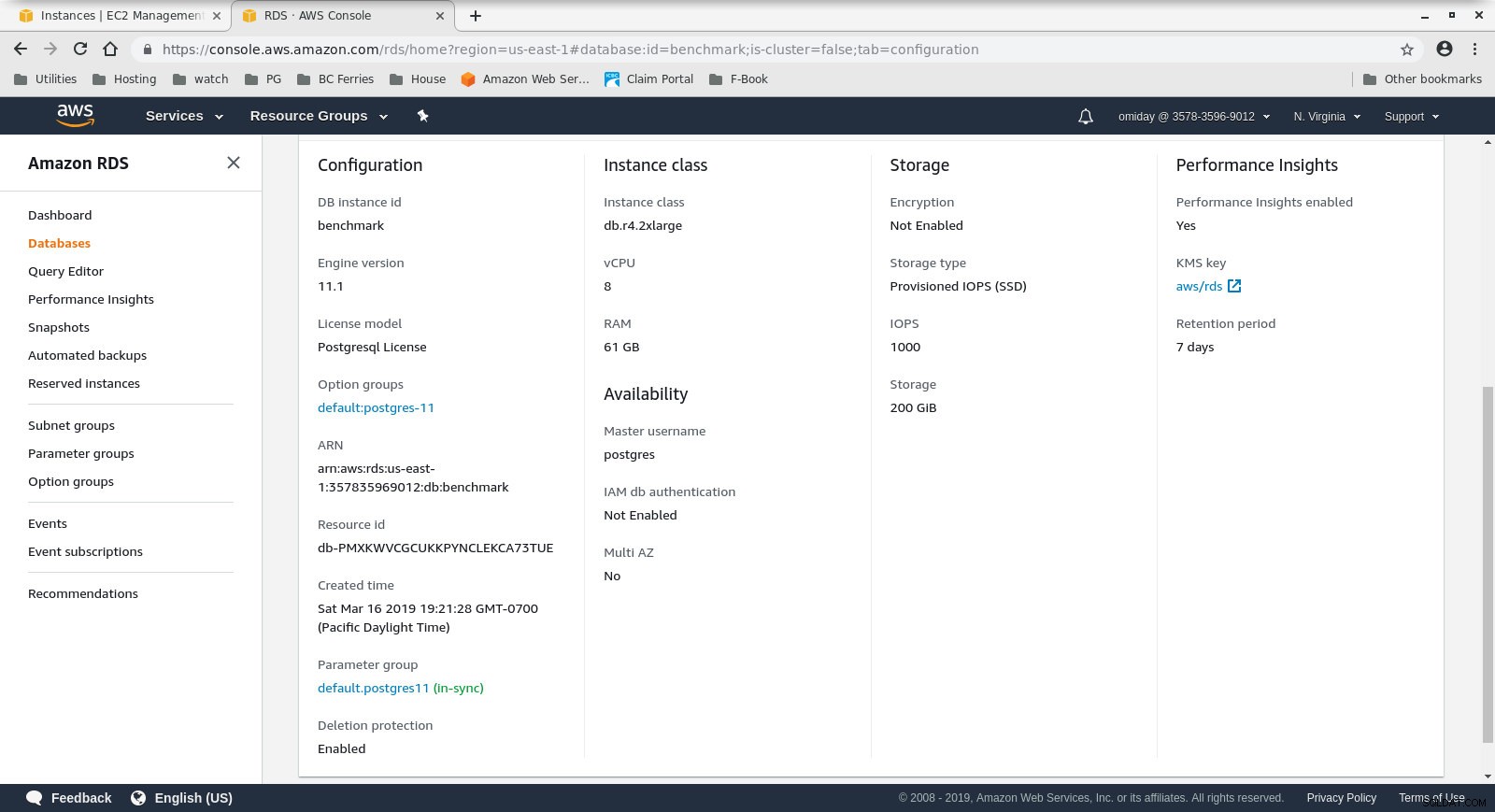 Datenbankinstanzkonfiguration
Datenbankinstanzkonfiguration
Installieren und konfigurieren Sie als Nächstes die Benchmark-Tools pgbench und sysbench, indem Sie den Anweisungen im Amazon-Handbuch folgen.
Der letzte Schritt zur Vorbereitung der Umgebung ist die Konfiguration der PostgreSQL-Verbindungsparameter. Eine Möglichkeit, dies zu tun, besteht darin, die Umgebungsvariablen in .bashrc zu initialisieren. Außerdem müssen wir die Pfade zu PostgreSQL-Binärdateien und -Bibliotheken festlegen:
export PGHOST=benchmark.ctfirtyhadgr.us-east-1.rds.amazonaws.com
export PGHOST=benchmark.ctfirtyhadgr.us-east-1.rds.amazonaws.com
export PGUSER=postgres
export PGPASSWORD=postgres
export PGDATABASE=postgres
export PATH=$PATH:/usr/local/pgsql/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/pgsql/lib
Verify that everything is in place:
[example@sqldat.com ~]# psql --version
psql (PostgreSQL) 11.1
[example@sqldat.com ~]# pgbench --version
pgbench (PostgreSQL) 11.1
[example@sqldat.com ~]# sysbench --version
sysbench 0.5Benchmarks ausführen
pgench
Initialisieren Sie zuerst die pgbench-Datenbank.
[example@sqldat.com ~]# pgbench -i --fillfactor=90 --scale=10000Der Initialisierungsprozess dauert einige Zeit und erzeugt während der Ausführung die folgende Ausgabe:
dropping old tables...
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
creating tables...
generating data...
100000 of 1000000000 tuples (0%) done (elapsed 0.06 s, remaining 599.79 s)
200000 of 1000000000 tuples (0%) done (elapsed 0.15 s, remaining 739.16 s)
300000 of 1000000000 tuples (0%) done (elapsed 0.22 s, remaining 742.21 s)
400000 of 1000000000 tuples (0%) done (elapsed 0.33 s, remaining 814.64 s)
500000 of 1000000000 tuples (0%) done (elapsed 0.41 s, remaining 825.82 s)
600000 of 1000000000 tuples (0%) done (elapsed 0.51 s, remaining 854.13 s)
700000 of 1000000000 tuples (0%) done (elapsed 0.66 s, remaining 937.01 s)
800000 of 1000000000 tuples (0%) done (elapsed 1.52 s, remaining 1897.42 s)
900000 of 1000000000 tuples (0%) done (elapsed 1.66 s, remaining 1840.08 s)
...
500600000 of 1000000000 tuples (50%) done (elapsed 814.78 s, remaining 812.83 s)
500700000 of 1000000000 tuples (50%) done (elapsed 814.81 s, remaining 812.53 s)
500800000 of 1000000000 tuples (50%) done (elapsed 814.83 s, remaining 812.23 s)
500900000 of 1000000000 tuples (50%) done (elapsed 815.11 s, remaining 812.19 s)
501000000 of 1000000000 tuples (50%) done (elapsed 815.20 s, remaining 811.94 s)
...
999200000 of 1000000000 tuples (99%) done (elapsed 1645.02 s, remaining 1.32 s)
999300000 of 1000000000 tuples (99%) done (elapsed 1645.17 s, remaining 1.15 s)
999400000 of 1000000000 tuples (99%) done (elapsed 1645.20 s, remaining 0.99 s)
999500000 of 1000000000 tuples (99%) done (elapsed 1645.23 s, remaining 0.82 s)
999600000 of 1000000000 tuples (99%) done (elapsed 1645.26 s, remaining 0.66 s)
999700000 of 1000000000 tuples (99%) done (elapsed 1645.28 s, remaining 0.49 s)
999800000 of 1000000000 tuples (99%) done (elapsed 1645.51 s, remaining 0.33 s)
999900000 of 1000000000 tuples (99%) done (elapsed 1645.77 s, remaining 0.16 s)
1000000000 of 1000000000 tuples (100%) done (elapsed 1646.03 s, remaining 0.00 s)
vacuuming...
creating primary keys...
total time: 5538.86 s (drop 0.00 s, tables 0.01 s, insert 1647.08 s, commit 0.03 s, primary 1251.60 s, foreign 0.00 s, vacuum 2640.14 s)
done.Überprüfen Sie nach Abschluss dieses Teils, ob die PostgreSQL-Datenbank gefüllt wurde. Die folgende vereinfachte Version der Festplattennutzungsabfrage kann verwendet werden, um die Größe der PostgreSQL-Datenbank zurückzugeben:
SELECT
d.datname AS Name,
pg_catalog.pg_get_userbyid(d.datdba) AS Owner,
pg_catalog.pg_size_pretty(pg_catalog.pg_database_size(d.datname)) AS SIZE
FROM pg_catalog.pg_database d
WHERE d.datname = 'postgres';…und die Ausgabe:
name | owner | size
----------+----------+--------
postgres | postgres | 160 GB
(1 row)Nachdem alle Vorbereitungen abgeschlossen sind, können wir mit dem Read/Write-pgbench-Test beginnen:
[example@sqldat.com ~]# pgbench --protocol=prepared -P 60 --time=600 --client=1000 --jobs=2048Nach 10 Minuten erhalten wir die Ergebnisse:
starting vacuum...end.
progress: 60.0 s, 878.3 tps, lat 1101.258 ms stddev 339.491
progress: 120.0 s, 885.2 tps, lat 1132.301 ms stddev 292.551
progress: 180.0 s, 656.3 tps, lat 1522.102 ms stddev 666.017
progress: 240.0 s, 436.8 tps, lat 2277.140 ms stddev 524.603
progress: 300.0 s, 742.2 tps, lat 1363.558 ms stddev 578.541
progress: 360.0 s, 866.4 tps, lat 1146.972 ms stddev 301.861
progress: 420.0 s, 878.2 tps, lat 1143.939 ms stddev 304.396
progress: 480.0 s, 872.7 tps, lat 1139.892 ms stddev 304.421
progress: 540.0 s, 881.0 tps, lat 1132.373 ms stddev 311.890
progress: 600.0 s, 729.3 tps, lat 1366.517 ms stddev 867.784
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 10000
query mode: prepared
number of clients: 1000
number of threads: 1000
duration: 600 s
number of transactions actually processed: 470582
latency average = 1274.340 ms
latency stddev = 544.179 ms
tps = 782.084354 (including connections establishing)
tps = 783.610726 (excluding connections establishing)sysbench
Der erste Schritt besteht darin, einige Daten hinzuzufügen:
sysbench --test=/usr/local/share/sysbench/oltp.lua \
--pgsql-host=aurora.cluster-ctfirtyhadgr.us-east-1.rds.amazonaws.com \
--pgsql-db=postgres \
--pgsql-user=postgres \
--pgsql-password=postgres \
--pgsql-port=5432 \
--oltp-tables-count=250\
--oltp-table-size=450000 \
prepareDer Befehl erstellt 250 Tabellen, jede Tabelle hat 2 Indizes:
sysbench 0.5: multi-threaded system evaluation benchmark
Creating table 'sbtest1'...
Inserting 450000 records into 'sbtest1'
Creating secondary indexes on 'sbtest1'...
Creating table 'sbtest2'...
...
Creating table 'sbtest250'...
Inserting 450000 records into 'sbtest250'
Creating secondary indexes on 'sbtest250'...Schauen wir uns die Indizes an:
postgres=> \di
List of relations
Schema | Name | Type | Owner | Table
--------+-----------------------+-------+----------+------------------
public | k_1 | index | postgres | sbtest1
public | k_10 | index | postgres | sbtest10
public | k_100 | index | postgres | sbtest100
public | k_101 | index | postgres | sbtest101
public | k_102 | index | postgres | sbtest102
public | k_103 | index | postgres | sbtest103
...
public | k_97 | index | postgres | sbtest97
public | k_98 | index | postgres | sbtest98
public | k_99 | index | postgres | sbtest99
public | pgbench_accounts_pkey | index | postgres | pgbench_accounts
public | pgbench_branches_pkey | index | postgres | pgbench_branches
public | pgbench_tellers_pkey | index | postgres | pgbench_tellers
public | sbtest100_pkey | index | postgres | sbtest100
public | sbtest101_pkey | index | postgres | sbtest101
public | sbtest102_pkey | index | postgres | sbtest102
public | sbtest103_pkey | index | postgres | sbtest103
public | sbtest104_pkey | index | postgres | sbtest104
public | sbtest105_pkey | index | postgres | sbtest105
...
public | sbtest97_pkey | index | postgres | sbtest97
public | sbtest98_pkey | index | postgres | sbtest98
public | sbtest99_pkey | index | postgres | sbtest99
public | sbtest9_pkey | index | postgres | sbtest9
(503 rows)Sieht gut aus ... um den Test zu starten, führen Sie einfach Folgendes aus:
sysbench --test=/usr/local/share/sysbench/oltp.lua \
--pgsql-host=aurora.cluster-ctfirtyhadgr.us-east-1.rds.amazonaws.com \
--pgsql-db=postgres \
--pgsql-user=postgres \
--pgsql-password=postgres \
--pgsql-port=5432 \
--oltp-tables-count=250 \
--oltp-table-size=450000 \
--max-requests=0 \
--forced-shutdown \
--report-interval=60 \
--oltp_simple_ranges=0 \
--oltp-distinct-ranges=0 \
--oltp-sum-ranges=0 \
--oltp-order-ranges=0 \
--oltp-point-selects=0 \
--rand-type=uniform \
--max-time=600 \
--num-threads=1000 \
runEin Hinweis zur Vorsicht:
RDS-Speicher ist nicht „elastisch“, was bedeutet, dass der beim Erstellen der Instanz zugewiesene Speicherplatz groß genug sein muss, um die während des Benchmarks generierte Datenmenge aufzunehmen, oder RDS schlägt fehl mit:
FATAL: PQexec() failed: 7 PANIC: could not write to file "pg_wal/xlogtemp.29144": No space left on device
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
FATAL: failed query: COMMIT
FATAL: failed to execute function `event': 3
WARNING: terminating connection because of crash of another server process
DETAIL: The postmaster has commanded this server process to roll back the current transaction and exit, because another server process exited abnormally and possibly corrupted shared memory.
HINT: In a moment you should be able to reconnect to the database and repeat your command.
WARNING: terminating connection because of crash of another server processDie Speichergröße kann erhöht werden, ohne die Datenbank anzuhalten, ich habe jedoch etwa 30 Minuten gebraucht, um sie von 200 GiB auf 500 GiB zu vergrößern:
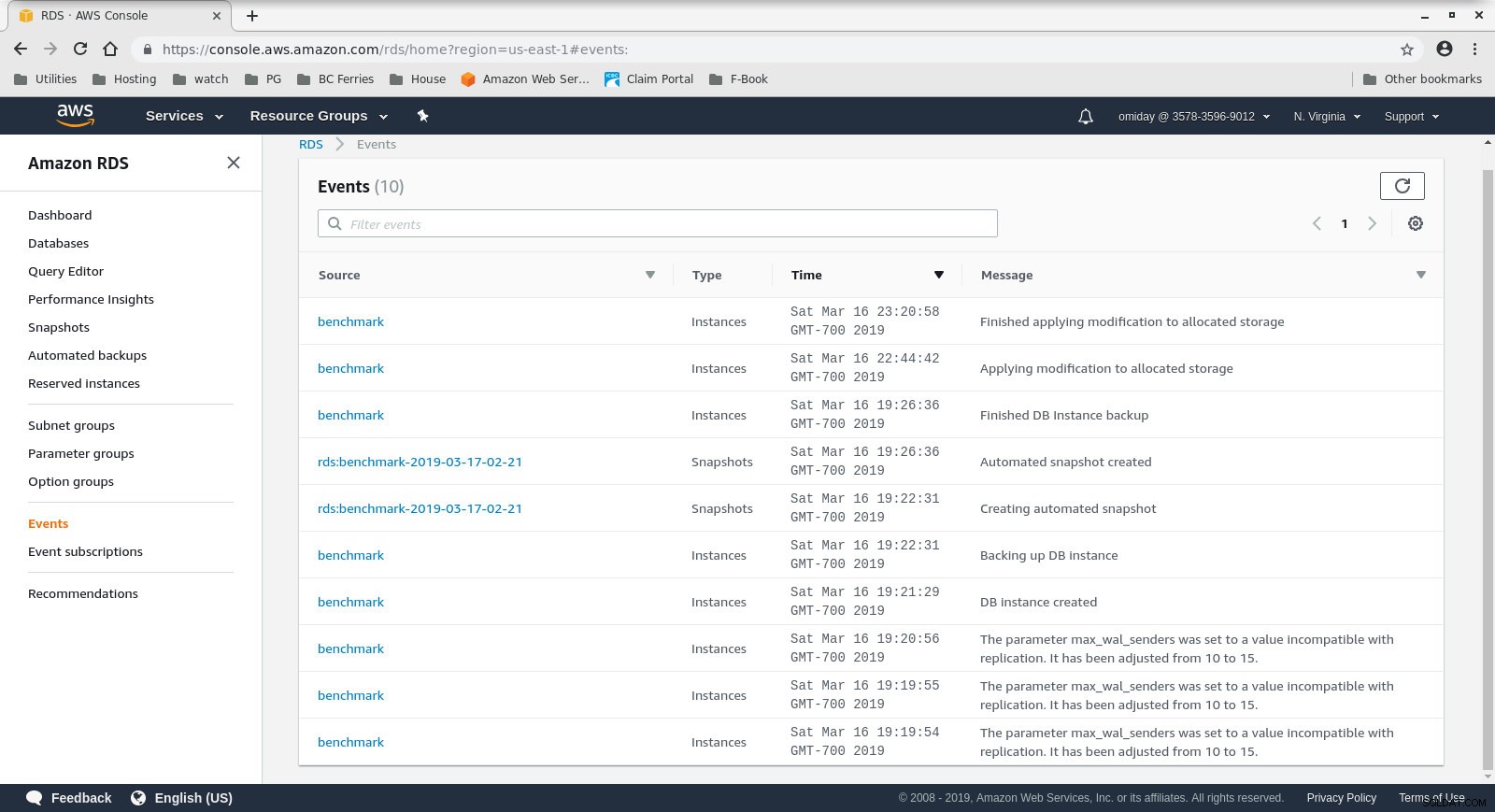 Erhöhen des Speicherplatzes auf RDS
Erhöhen des Speicherplatzes auf RDS Und hier sind die Sysbench-Testergebnisse:
sysbench 0.5: multi-threaded system evaluation benchmark
Running the test with following options:
Number of threads: 1000
Report intermediate results every 60 second(s)
Random number generator seed is 0 and will be ignored
Forcing shutdown in 630 seconds
Initializing worker threads...
Threads started!
[ 60s] threads: 1000, tps: 1070.40, reads: 0.00, writes: 4309.35, response time: 1808.81ms (95%), errors: 0.02, reconnects: 0.00
[ 120s] threads: 1000, tps: 889.68, reads: 0.00, writes: 3575.35, response time: 1951.12ms (95%), errors: 0.02, reconnects: 0.00
[ 180s] threads: 1000, tps: 574.57, reads: 0.00, writes: 2320.62, response time: 3936.73ms (95%), errors: 0.00, reconnects: 0.00
[ 240s] threads: 1000, tps: 232.10, reads: 0.00, writes: 928.43, response time: 10994.37ms (95%), errors: 0.00, reconnects: 0.00
[ 300s] threads: 1000, tps: 242.40, reads: 0.00, writes: 969.60, response time: 9412.39ms (95%), errors: 0.00, reconnects: 0.00
[ 360s] threads: 1000, tps: 257.73, reads: 0.00, writes: 1030.98, response time: 8833.64ms (95%), errors: 0.02, reconnects: 0.00
[ 420s] threads: 1000, tps: 264.65, reads: 0.00, writes: 1036.60, response time: 9192.42ms (95%), errors: 0.00, reconnects: 0.00
[ 480s] threads: 1000, tps: 278.07, reads: 0.00, writes: 1134.27, response time: 7133.76ms (95%), errors: 0.00, reconnects: 0.00
[ 540s] threads: 1000, tps: 250.40, reads: 0.00, writes: 1001.53, response time: 9628.97ms (95%), errors: 0.00, reconnects: 0.00
[ 600s] threads: 1000, tps: 249.97, reads: 0.00, writes: 996.92, response time: 10724.58ms (95%), errors: 0.00, reconnects: 0.00
OLTP test statistics:
queries performed:
read: 0
write: 1038401
other: 519199
total: 1557600
transactions: 259598 (428.59 per sec.)
read/write requests: 1038401 (1714.36 per sec.)
other operations: 519199 (857.18 per sec.)
ignored errors: 3 (0.00 per sec.)
reconnects: 0 (0.00 per sec.)
General statistics:
total time: 605.7086s
total number of events: 259598
total time taken by event execution: 602999.7582s
response time:
min: 55.02ms
avg: 2322.82ms
max: 13133.36ms
approx. 95 percentile: 8400.39ms
Threads fairness:
events (avg/stddev): 259.5980/3.20
execution time (avg/stddev): 602.9998/2.77Benchmark-Metriken
Die Metriken können mit den AWS-Überwachungstools CloudWatch und Performance Insights erfasst werden. Hier ein paar Beispiele für Neugierige:
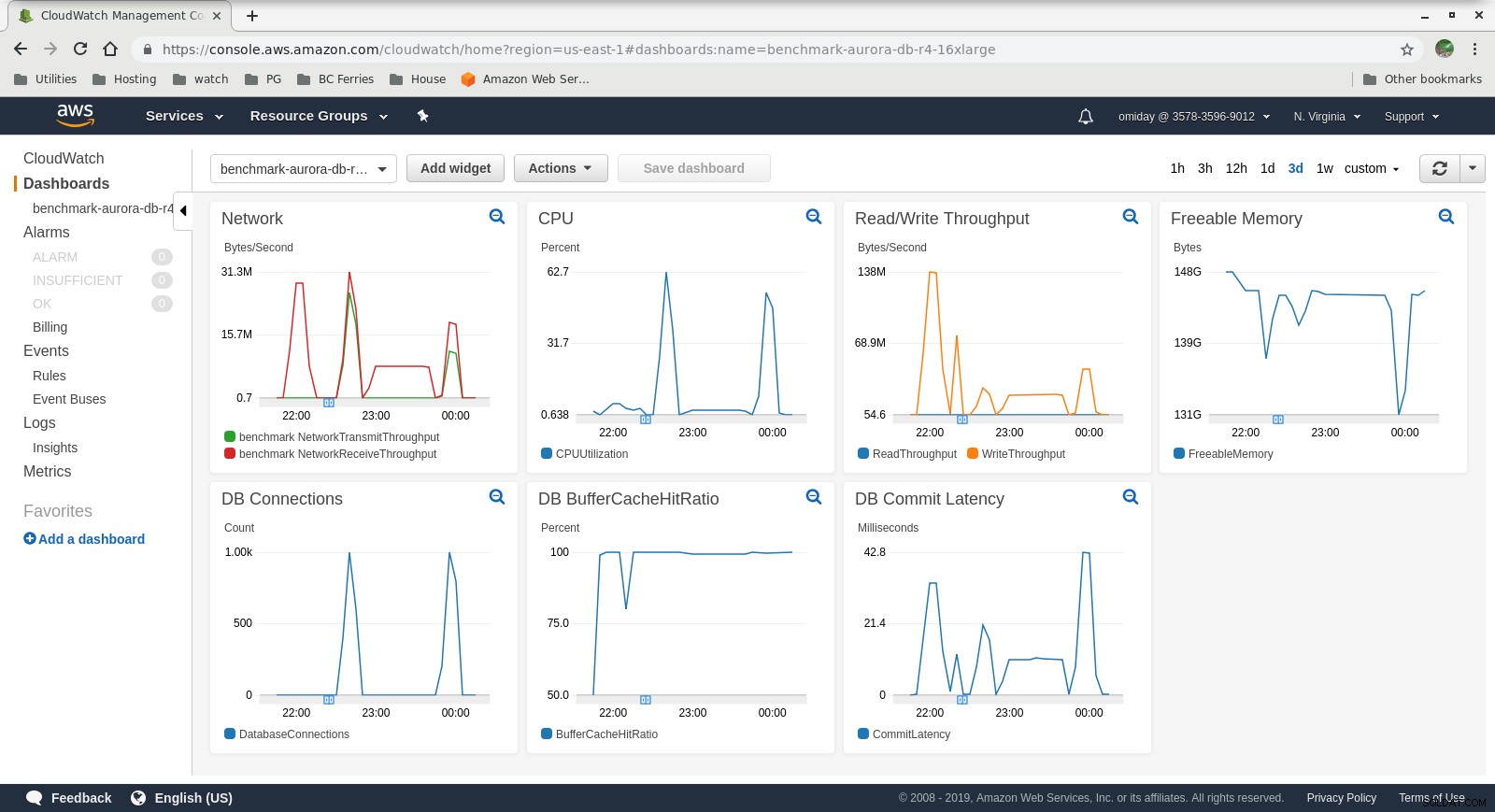 CloudWatch-Metriken der DB-Instance
CloudWatch-Metriken der DB-Instance 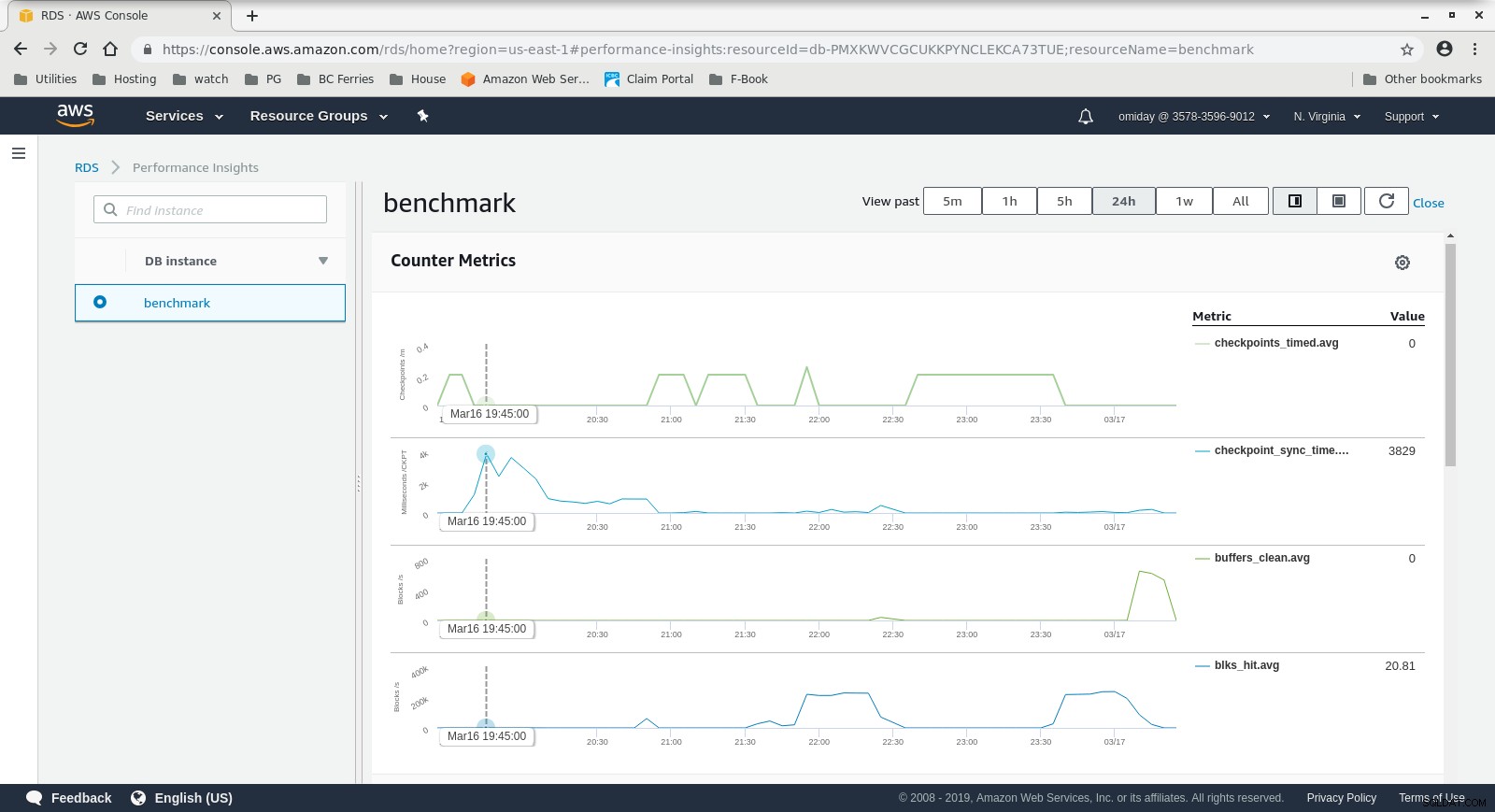 RDS-Leistungseinblicke – Zählermetriken
RDS-Leistungseinblicke – Zählermetriken 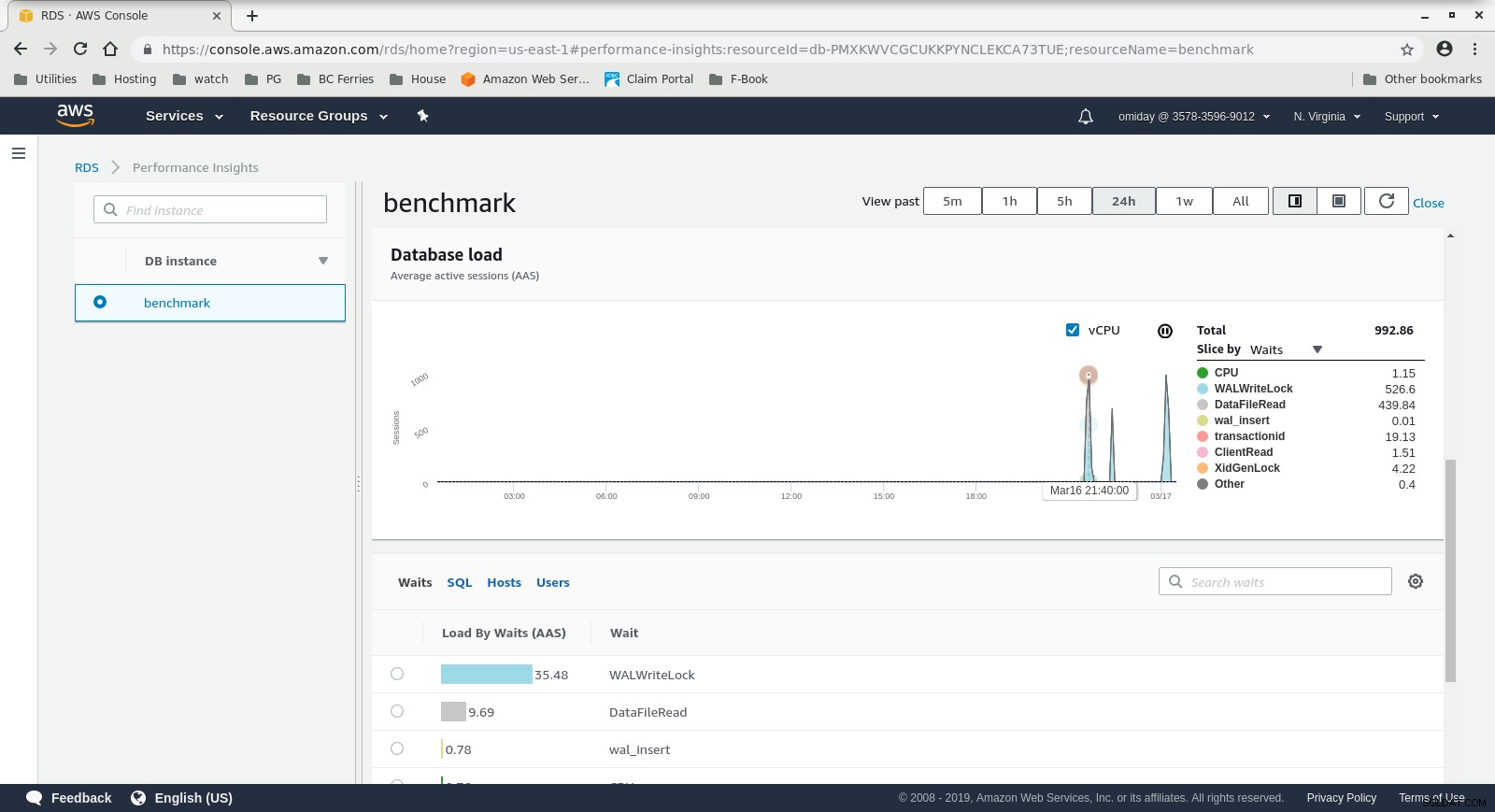 RDS-Leistungseinblicke – Datenbanklast
RDS-Leistungseinblicke – Datenbanklast Ergebnisse
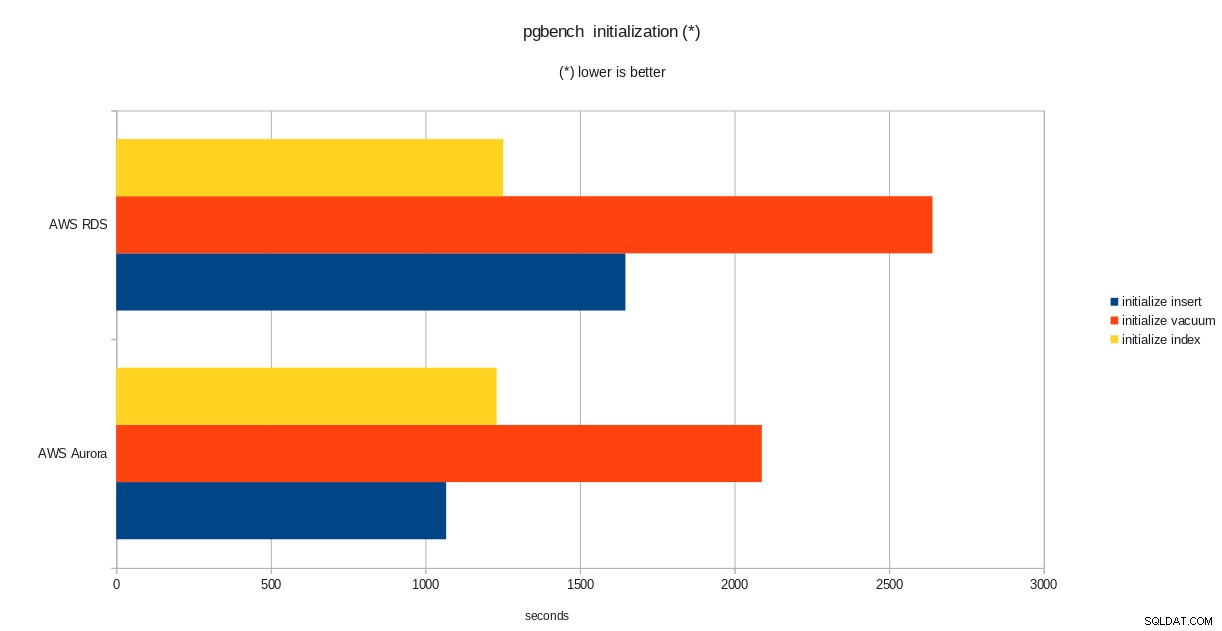 pgbench-Initialisierungsergebnisse
pgbench-Initialisierungsergebnisse 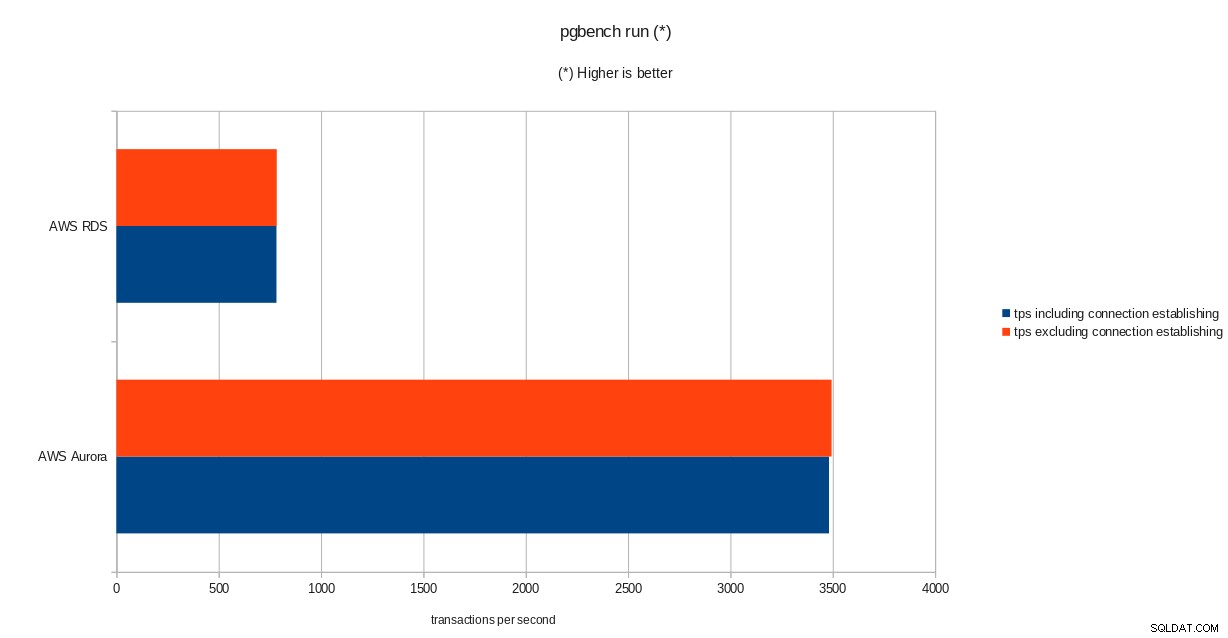 pgbench-Ausführungsergebnisse
pgbench-Ausführungsergebnisse 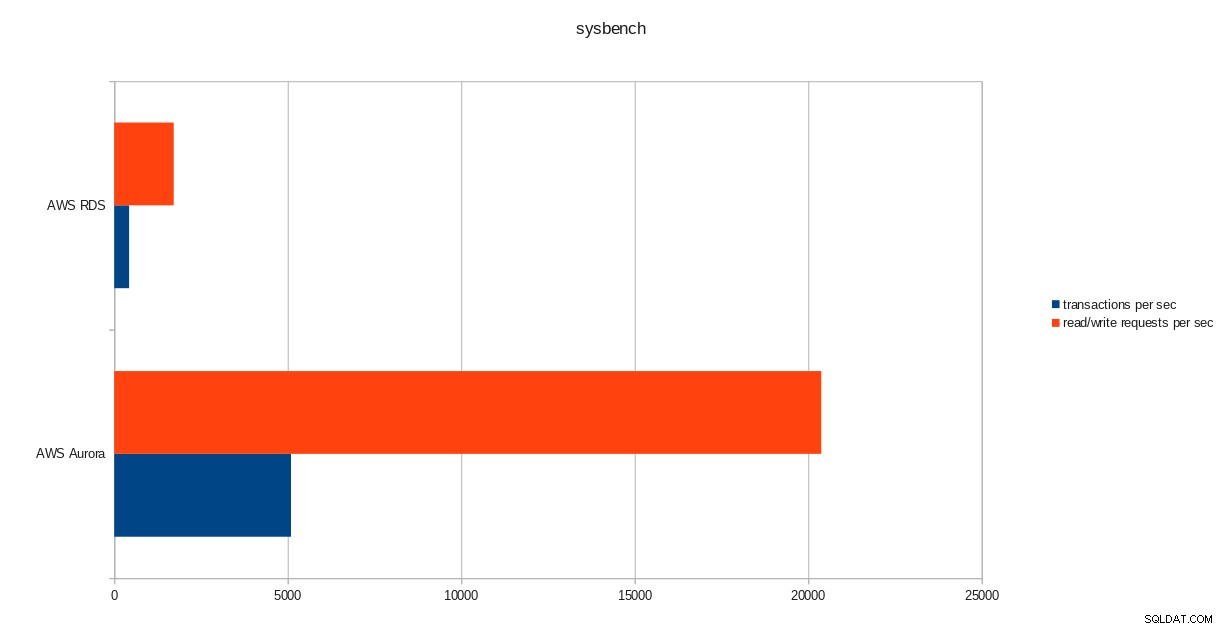 sysbench-Ergebnisse
sysbench-Ergebnisse Schlussfolgerung
Obwohl die PostgreSQL-Version 10.6 ausgeführt wird, übertrifft Amazon Aurora RDS in Version 11.1 deutlich, und das ist keine Überraschung. Laut Aurora-FAQs hat Amazon große Anstrengungen unternommen, um die Gesamtleistung der Datenbank zu verbessern, die auf einer neu gestalteten Speicher-Engine aufbaut.
Nächster in der Reihe
Im nächsten Teil geht es um Google Cloud SQL für PostgreSQL.