Odoo (früher bekannt als OpenERP) ist eine Suite von Open-Source-Business-Apps. Es ist in zwei Versionen erhältlich – Community und Enterprise. Einige der beliebtesten Apps (und kostenlos!), die in diese Plattform integriert sind, sind Discuss, CRM, Inventory, Website, Employee, Leaves, Recruitment, Expenses, Accounting, Invoicing, Point of Sale und viele mehr.
In diesem Blogbeitrag werden wir uns ansehen, wie Odoo geclustert werden kann, um Hochverfügbarkeit und Skalierbarkeit zu erreichen. Dieser Beitrag ähnelt unseren vorherigen Beiträgen zur Skalierung von Drupal, WordPress, Magento. Die verwendeten Softwares sind Odoo 12, HAProxy 1.8.8, Keepalived 1.3.9, PostgreSQL 11 und OCFS2 (Oracle Cluster File System).
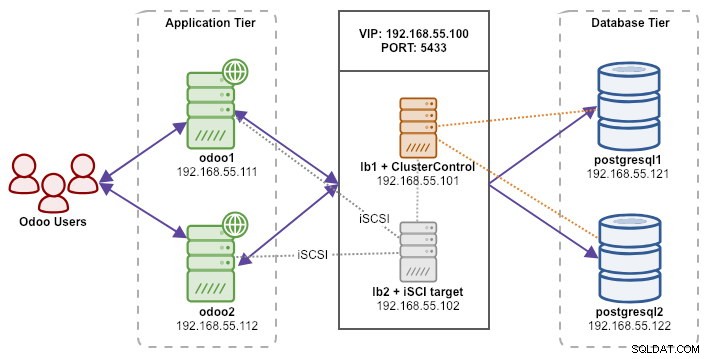
Unser Setup besteht aus 6 Servern:
- lb1 (HAProxy) + Keepalived + ClusterControl - 192.168.55.101
- lb2 (HAProxy) + Keepalive + gemeinsam genutzter Speicher – 192.168.55.102
- odoo1 - 192.168.55.111
- odoo2 - 192.168.55.112
- postgresql1 (Master) – 192.168.55.121
- postgresql2 (Slave) - 192.168.55.122
Alle Knoten laufen auf Ubuntu 18.04.2 LTS (Bionic). Wir werden ClusterControl verwenden, um PostgreSQL, Keepalived und HAProxy bereitzustellen und zu verwalten, da es uns eine Menge Arbeit ersparen wird. ClusterControl wird sich zusammen mit HAProxy auf lb1 befinden, während wir lb2 eine zusätzliche Festplatte hinzufügen werden, die als gemeinsam genutzter Speicheranbieter verwendet wird. Diese Festplatte wird mit einem geclusterten Dateisystem namens OCFS2 als freigegebenes Verzeichnis bereitgestellt. Eine virtuelle IP-Adresse, 192.168.55.100, fungiert als einzelner Endpunkt für unseren Datenbankdienst.
Das folgende Diagramm veranschaulicht unsere Gesamtsystemarchitektur:
Das Folgende ist der Inhalt von /etc/hosts auf allen Knoten:
192.168.55.101 lb1.local lb1 cc.local cc
192.168.55.102 lb2.local lb2 storage.local storage
192.168.55.111 odoo1.local odoo1
192.168.55.112 odoo2.local odoo2
192.168.55.121 postgresql1.local postgresql1
192.168.55.122 postgresql2.local postgresql2Bereitstellen der PostgreSQL-Streaming-Replikation
Wir beginnen mit der Installation von ClusterControl auf lb1:
$ wget severalnines.com/downloads/cmon/install-cc
$ chmod 755 ./install-cc
$ sudo ./install-ccFolgen Sie dem Installationsassistenten, Sie müssen während des Vorgangs einige Fragen beantworten.
Richten Sie passwortloses SSH vom ClusterControl-Knoten (lb1) zu allen Knoten ein, die von ClusterControl verwaltet werden, nämlich lb1 (selbst), lb2, postresql1 und postgresql2. Aber generieren Sie zuerst einen SSH-Schlüssel:
$ whoami
ubuntu
$ ssh-keygen -t rsa # press Enter on all promptsKopieren Sie dann den Schlüssel mit dem Tool ssh-copy-id auf alle Zielknoten:
$ whoami
ubuntu
$ ssh-copy-id example@sqldat.com
$ ssh-copy-id example@sqldat.com
$ ssh-copy-id example@sqldat.com
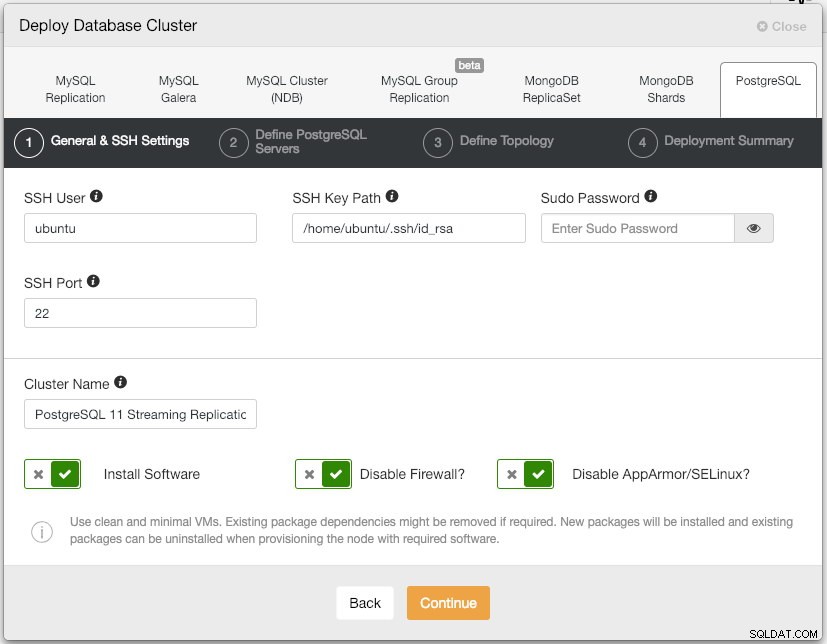
$ ssh-copy-id example@sqldat.comÖffnen Sie die ClusterControl-Benutzeroberfläche unter https://192.168.55.101/clustercontrol und erstellen Sie einen Super-Admin-Benutzer mit Passwort. Sie werden zum Dashboard der ClusterControl-Benutzeroberfläche weitergeleitet. Stellen Sie dann einen neuen PostgreSQL-Cluster bereit, indem Sie im oberen Menü auf die Schaltfläche „Bereitstellen“ klicken. Ihnen wird das folgende Bereitstellungsdialogfeld angezeigt:
Hier ist, was wir in den nächsten Dialog „PostgreSQL-Server definieren“ eingegeben haben:
- Serverport:5432
- Benutzer:postgres
- Passwort:s3cr3t
- Version:11
- Datenverzeichnis:
- Repository:Anbieter-Repositorys verwenden
Geben Sie im Abschnitt „Define Topology“ die IP-Adresse von postgresql1 und postgresql2 entsprechend an:
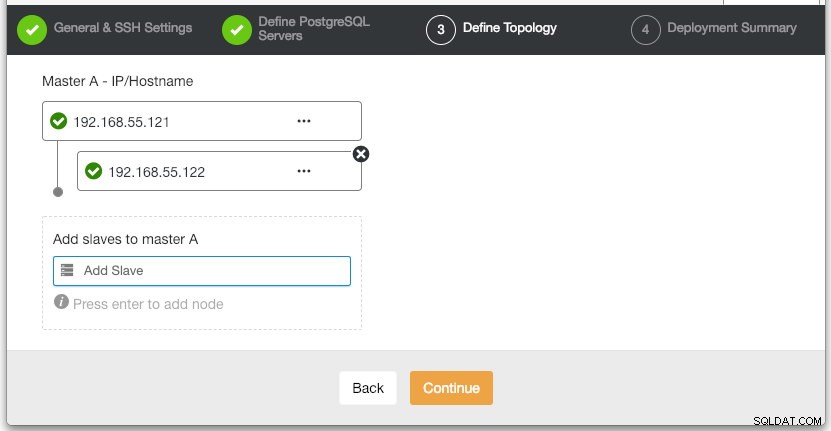
Unter dem letzten Abschnitt „Bereitstellungszusammenfassung“ haben Sie die Möglichkeit, die synchrone Replikation zu aktivieren. Da wir den Slave nur für Failover-Zwecke verwenden werden (der Slave bedient keine Leseoperationen), lassen wir den Standardwert einfach so wie er ist. Klicken Sie dann auf „Bereitstellen“, um die Bereitstellung des Datenbankclusters zu starten. Sie können den Bereitstellungsfortschritt überwachen, indem Sie sich Aktivität> Jobs> Cluster erstellen ansehen :
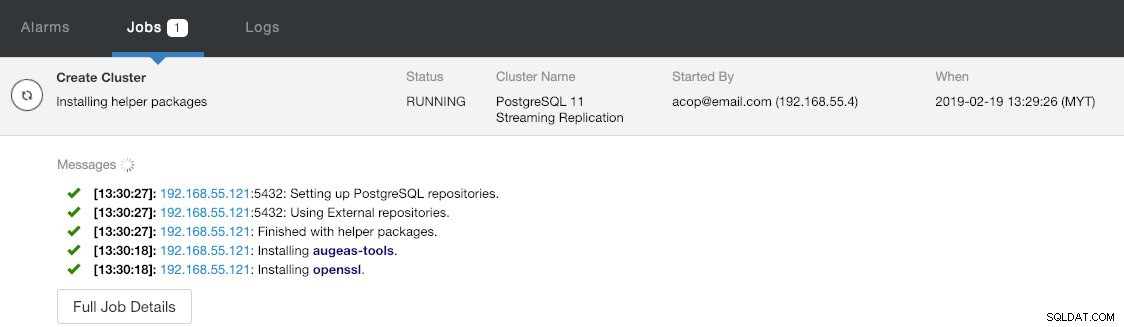
Holen Sie sich in der Zwischenzeit einen Kaffee und die Cluster-Bereitstellung sollte innerhalb von 10 bis 15 Minuten abgeschlossen sein.
Bereitstellen von Load Balancern und virtueller IP für PostgreSQL-Server
Zu diesem Zeitpunkt haben wir bereits einen PostgreSQL-Replikationscluster mit zwei Knoten, der in einer Master-Slave-Konfiguration ausgeführt wird:

Der nächste Schritt besteht darin, die Load-Balancer-Ebene für unsere Datenbank bereitzustellen, wodurch wir die virtuelle IP-Adresse binden und einen einzigen Endpunkt für die Anwendung bereitstellen können. Wir werden die HAProxy-Bereitstellungsoptionen wie folgt konfigurieren:
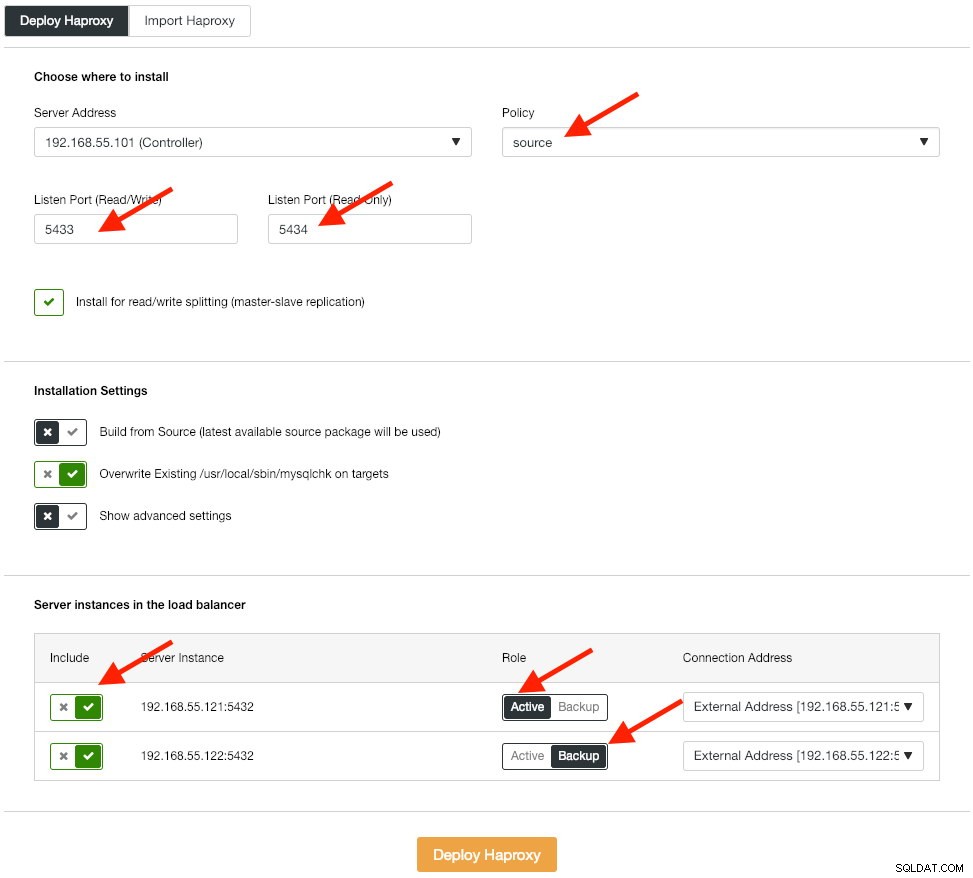
Die Anwendung unterstützt nativ kein Read-Write-Splitting, daher verwenden wir die Aktiv-Passiv-Methode, um eine hohe Verfügbarkeit zu erreichen. Der beste Load-Balancing-Algorithmus ist die „Source“-Richtlinie, da wir jeweils nur einen PostgreSQL-Knoten verwenden.
Wiederholen Sie denselben Schritt für den anderen Load Balancer, lb2. Ändern Sie stattdessen die "Serveradresse" in 192.168.55.102. So sieht es nach Abschluss der Bereitstellung aus, wenn Sie zur Seite „Knoten“ gehen:
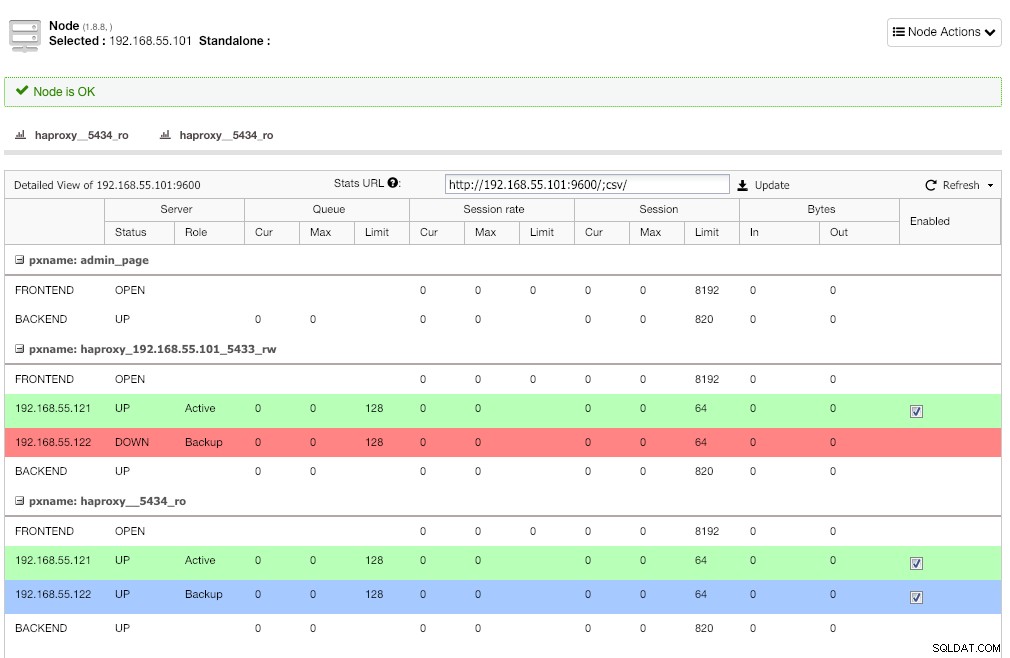
Die rote Linie auf dem ersten Listener wird dort erwartet, wo HAProxy anzeigt, dass postgresql2 (192.168.55.122) ausgefallen ist, weil das Health-Check-Skript zurückgibt, dass der Knoten aktiv, aber kein Master ist. Der zweite Listener mit blauer Linie (haproxy_5434_ro) zeigt, dass der Knoten UP ist, sich aber im „Backup“-Zustand befindet. Dieser Listener kann jedoch ignoriert werden, da die Anwendung kein Read-Write-Splitting unterstützt.
Als Nächstes stellen wir Keepalived-Instanzen auf diesen Load Balancern bereit, um sie mit einer einzigen virtuellen IP-Adresse zu verbinden. Gehen Sie zu Verwalten -> Load Balancer -> Keepalived -> Keepalived bereitstellen und geben Sie die erste und zweite HAProxy-Instanz an, dann die virtuelle IP-Adresse und die Netzwerkschnittstelle, auf die gelauscht werden soll:
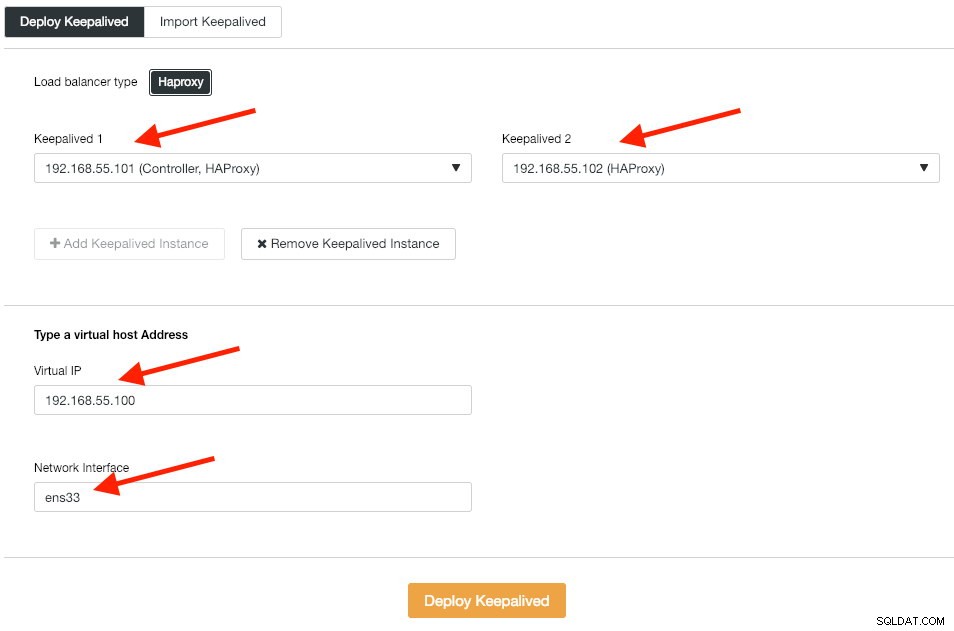
Klicken Sie auf „Keepalive bereitstellen“, um die Bereitstellung zu starten. Der PostgreSQL-Verbindungsdienst ist jetzt auf einen der Datenbankknoten verteilt und über 192.168.55.100 Port 5433 zugänglich.
iSCSI konfigurieren
Der Speicherserver (lb2) muss eine Festplatte über iSCSI exportieren, damit sie auf beiden Odoo-Anwendungsservern (odoo1 und odoo2) gemountet werden kann. iSCSI teilt Ihrem Kernel im Grunde mit, dass Sie eine SCSI-Festplatte haben, und es transportiert diesen Zugriff über IP. Der „Server“ wird als „Ziel“ und der „Client“, der dieses iSCSI-Gerät verwendet, als „Initiator“ bezeichnet.
Installieren Sie zuerst das iSCSI-Ziel in lb2:
$ sudo apt install -y tgttgt beim Booten aktivieren:
$ systemctl enable tgtEs wird bevorzugt, eine separate Festplatte für Dateisystem-Clustering zu haben. Daher werden wir eine andere in lb2 (/dev/sdb) gemountete Festplatte verwenden, die von den Anwendungsservern (odoo1 und odoo2) gemeinsam genutzt wird. Erstellen Sie zunächst ein iSCSI-Ziel mit dem tgtadm-Tool:
$ sudo tgtadm --lld iscsi --op new --mode target --tid 1 -T iqn.2019-02.lb2:odcfs2Weisen Sie dann das Blockgerät /dev/sdb der logischen Einheitennummer (LUN) 1 zusammen mit der Ziel-ID 1 zu:
$ sudo tgtadm --lld iscsi --op new --mode logicalunit --tid 1 --lun 1 -b /dev/sdbErlauben Sie dann den Initiatorknoten im selben Netzwerk den Zugriff auf dieses Ziel:
$ sudo tgtadm --lld iscsi --op bind --mode target --tid 1 --initiator-address 192.168.55.0/24Verwenden Sie das tgt-admin-Tool, um die iSCSI-Konfigurationszeilen auszugeben und als Konfigurationsdatei zu speichern, damit sie über einen Neustart hinweg bestehen bleibt:
$ sudo tgt-admin --dump > /etc/tgt/conf.d/shareddisk.confStarten Sie schließlich den iSCSI-Zieldienst neu:
$ sudo systemctl restart tgt** Die folgenden Schritte sollten auf odoo1 und odoo2 durchgeführt werden.
Installieren Sie den iSCSI-Initiator auf den entsprechenden Hosts:
$ sudo apt-get install -y open-iscsiStellen Sie den iSCSI-Initiator so ein, dass er automatisch startet:
$ sudo systemctl enable open-iscsiEntdecken Sie iSCSI-Ziele, die wir zuvor eingerichtet haben:
$ sudo iscsiadm -m discovery -t sendtargets -p lb2
192.168.55.102:3260,1 iqn.2019-02.lb2:odcfs2Wenn Sie ein ähnliches Ergebnis wie oben sehen, bedeutet dies, dass wir das iSCSI-Ziel sehen und eine Verbindung zu ihm herstellen können. Verwenden Sie den folgenden Befehl, um eine Verbindung zum iSCSI-Ziel auf lb2 herzustellen:
$ sudo iscsiadm -m node --targetname iqn.2019-02.lb2:odcfs2 -p lb2 -l
Logging in to [iface: default, target: iqn.2019-02.lb2:odcfs2, portal: 192.168.55.102,3260] (multiple)
Login to [iface: default, target: iqn.2019-02.lb2:odcfs2, portal: 192.168.55.102,3260] successful.Stellen Sie sicher, dass die neue Festplatte (/dev/sdb) im /dev-Verzeichnis aufgelistet ist:
$ sudo ls -1 /dev/sd*
/dev/sda
/dev/sda1
/dev/sda2
/dev/sda3
/dev/sdbUnsere gemeinsame Festplatte ist jetzt auf beiden Anwendungsservern (odoo1 und odoo2) gemountet.
OCFS2 für Odoo konfigurieren
** Die folgenden Schritte sollten auf odoo1 durchgeführt werden, sofern nicht anders angegeben.
OCFS2 ermöglicht das Einhängen von Dateisystemen an mehr als einer Stelle. Installieren Sie die OCFS2-Tools auf den Servern odoo1 und odoo2:
$ sudo apt install -y ocfs2-toolsErstellen Sie eine Festplattenpartitionstabelle für das Festplattenlaufwerk /dev/sdb:
$ sudo cfdisk /dev/sdbErstellen Sie eine Partition, indem Sie im cfdisk-Assistenten die folgenden Sequenzen verwenden:Neu> Primär> Größe akzeptieren> Schreiben> Ja> Beenden .
Erstellen Sie ein OCFS2-Dateisystem auf /dev/sdb1:
$ sudo mkfs.ocfs2 -b 4K -C 128K -L "Odoo_Cluster" /dev/sdb1
mkfs.ocfs2 1.8.5
Cluster stack: classic o2cb
Label: Odoo_Cluster
Features: sparse extended-slotmap backup-super unwritten inline-data strict-journal-super xattr indexed-dirs refcount discontig-bg append-dio
Block size: 4096 (12 bits)
Cluster size: 131072 (17 bits)
Volume size: 21473656832 (163831 clusters) (5242592 blocks)
Cluster groups: 6 (tail covers 2551 clusters, rest cover 32256 clusters)
Extent allocator size: 4194304 (1 groups)
Journal size: 134217728
Node slots: 8
Creating bitmaps: done
Initializing superblock: done
Writing system files: done
Writing superblock: done
Writing backup superblock: 3 block(s)
Formatting Journals: done
Growing extent allocator: done
Formatting slot map: done
Formatting quota files: done
Writing lost+found: done
mkfs.ocfs2 successfulErstellen Sie eine Cluster-Konfigurationsdatei unter /etc/ocfs2/cluster.conf und definieren Sie die Knoten- und Cluster-Direktiven wie folgt:
# /etc/ocfs2/cluster.conf
cluster:
node_count = 2
name = ocfs2
node:
ip_port = 7777
ip_address = 192.168.55.111
number = 1
name = odoo1
cluster = ocfs2
node:
ip_port = 7777
ip_address = 192.168.55.112
number = 2
name = odoo2
cluster = ocfs2Beachten Sie, dass die Attribute unter der node- oder cluster-Klausel nach einem Tab stehen müssen.
** Die folgenden Schritte sollten auf odoo1 und odoo2 durchgeführt werden, sofern nicht anders angegeben.
Erstellen Sie dieselbe Konfigurationsdatei (/etc/ocfs2/cluster.conf) auf odoo2. Diese Datei sollte auf allen Knoten im Cluster gleich sein, und an dieser Datei vorgenommene Änderungen müssen an die anderen Knoten im Cluster weitergegeben werden.
Starten Sie den o2cb-Dienst neu, um die Änderungen zu übernehmen, die wir in /etc/ocfs2/cluster.conf vorgenommen haben:
$ sudo systemctl restart o2cbErstellen Sie das Odoo-Dateiverzeichnis unter /var/lib/odoo:
$ sudo mkdir -p /var/lib/odooRufen Sie die Block-ID für das /dev/sdb1-Gerät ab. UUID wird in fstab empfohlen, wenn Sie ein iSCSI-Gerät verwenden:
$ sudo blkid /dev/sdb1 | awk {'print $3'}
UUID="93a2b6c4-d800-4532-9a9b-2d2f2f1a726b"Verwenden Sie den UUID-Wert, wenn Sie die folgende Zeile in /etc/fstab hinzufügen:
UUID=93a2b6c4-d800-4532-9a9b-2d2f2f1a726b /var/lib/odoo ocfs2 defaults,_netdev 0 0Registrieren Sie den ocfs2-Cluster und mounten Sie das Dateisystem von fstab:
$ sudo o2cb register-cluster ocfs2
$ sudo mount -a
Bestätigen mit:
$ mount | grep odoo
/dev/sdb1 on /var/lib/odoo type ocfs2 (rw,relatime,_netdev,heartbeat=local,nointr,data=ordered,errors=remount-ro,atime_quantum=60,coherency=full,user_xattr,acl,_netdev)Wenn Sie die obige Zeile auf allen Anwendungsservern sehen können, sind wir bereit, Odoo zu installieren.
Installieren und Konfigurieren von Odoo 12
** Die folgenden Schritte sollten auf odoo1 und odoo2 durchgeführt werden, sofern nicht anders angegeben.
Installieren Sie Odoo 12 über das Paket-Repository:
$ wget -O - https://nightly.odoo.com/odoo.key | sudo apt-key add -
$ echo "deb https://nightly.odoo.com/12.0/nightly/deb/ ./" | sudo tee -a /etc/apt/sources.list.d/odoo.list
$ sudo apt update && sudo apt install odooStandardmäßig installiert der obige Befehl den PostgreSQL-Server automatisch auf demselben Host als Teil der Odoo-Abhängigkeiten. Wir wollen es wahrscheinlich stoppen, weil wir sowieso nicht den lokalen Server verwenden werden:
$ sudo systemctl stop postgresql
$ sudo systemctl disable postgresqlErstellen Sie auf postgresql1 einen Datenbankbenutzer namens „odoo“:
$ sudo -i
$ su - postgres
$ createuser --createrole --createdb --pwprompt odooGeben Sie in der Eingabeaufforderung ein Kennwort an. Fügen Sie dann sowohl auf postgresql1 als auch auf postgresql2 die folgende Zeile in pg_hba.conf hinzu, damit die Anwendungs- und Load Balancer-Knoten eine Verbindung herstellen können. Wie in unserem Fall befindet es sich unter /etc/postgresql/11/main/pg_hba.conf:
host all all 192.168.55.0/24 md5Laden Sie dann den PostgreSQL-Server neu, um die Änderungen zu laden:
$ su - postgres
$ /usr/lib/postgresql/11/bin/pg_ctl reload -D /var/lib/postgresql/11/main/Bearbeiten Sie die Odoo-Konfigurationsdatei unter /etc/odoo/odoo.conf und konfigurieren Sie die Parameter admin_passwd, db_host und db_password entsprechend:
[options]
; This is the password that allows database operations:
admin_passwd = admins3cr3t
db_host = 192.168.55.100
db_port = 5433
db_user = odoo
db_password = odoopassword
;addons_path = /usr/lib/python3/dist-packages/odoo/addonsStarten Sie Odoo auf beiden Servern neu, um die neuen Änderungen zu laden:
$ sudo systemctl restart odooÖffnen Sie Odoo auf einem der Anwendungsserver über einen Webbrowser. In diesem Beispiel haben wir eine Verbindung zu odoo1 hergestellt, daher lautet die URL https://192.168.55.111:8069/ und Sie sollten die folgende Startseite sehen:
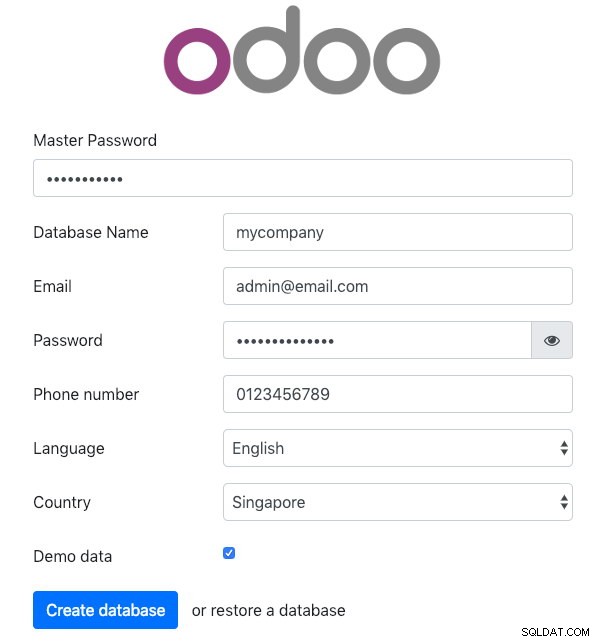
Geben Sie das „Master-Passwort“ an, das mit dem in der Odoo-Konfigurationsdatei definierten admin_passwd-Wert identisch ist. Füllen Sie dann alle erforderlichen Informationen für das neue Unternehmen aus, das diese Plattform nutzen wird.
Warten Sie anschließend einen Moment, bis die Initialisierung abgeschlossen ist. Sie werden zum Odoo-Administrations-Dashboard weitergeleitet:

An diesem Punkt ist die Odoo-Installation abgeschlossen und Sie können mit der Konfiguration der Business-Apps für dieses Unternehmen beginnen. Alle von diesem Anwendungsserver vorgenommenen Dateiänderungen werden im geclusterten Dateisystem unter „/var/lib/odoo/.local“ (das auch auf einem anderen Anwendungsserver, odoo2, gemountet ist) gespeichert, während Änderungen an der Datenbank vorgenommen werden auf dem PostgreSQL-Masterknoten.
Beachten Sie, dass die Odoo-Anwendung selbst, obwohl sie auf zwei verschiedenen Hosts ausgeführt wird, in diesem Schreiben keinen Lastenausgleich aufweist. Sie können die für das Datenbank-Cluster bereitgestellten HAProxy-Instanzen verwenden, um eine bessere Verfügbarkeit zu erreichen, genau wie der Datenbankdienst. Außerdem ist das gemeinsam genutzte Festplattendateisystem (OCFS2), das von beiden Anwendungsservern verwendet wird, immer noch einem Single-Point-of-Failure ausgesetzt, da sie alle dasselbe iSCSI-Gerät auf lb2 verwenden (stellen Sie sich vor, wenn auf lb2 nicht zugegriffen werden kann).
Datenbank-Failover-Vorgang
Sie fragen sich vielleicht, was passieren würde, wenn der PostgreSQL-Master ausfällt. Wenn dies passiert, wird ClusterControl den laufenden Slave automatisch zum Master machen, wie im folgenden Screenshot gezeigt:
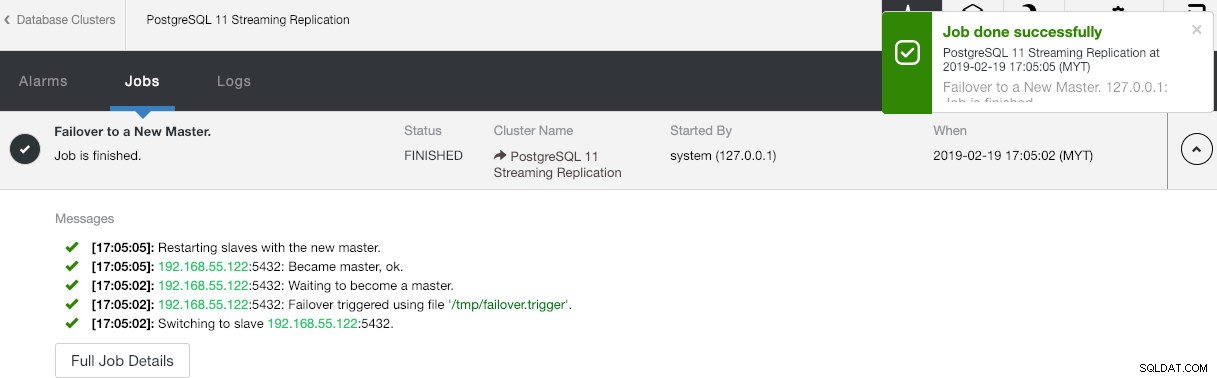
Seitens des Endbenutzers muss nichts unternommen werden, da das Failover automatisch durchgeführt wird (nach einer Karenzzeit von 30 Sekunden). Nachdem das Failover abgeschlossen ist, wird die neue Topologie von ClusterControl wie folgt gemeldet:
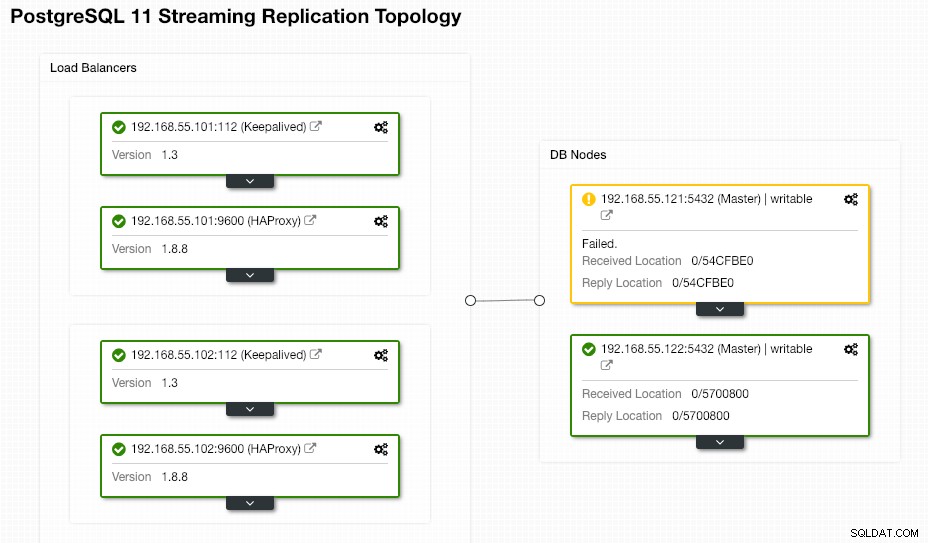
Wenn der alte Master wieder hochfährt, wird der PostgreSQL-Dienst automatisch heruntergefahren, und als Nächstes muss der Benutzer den alten Master wieder vom neuen Master synchronisieren, indem er zu Knotenaktionen> Replikations-Slave neu erstellen :
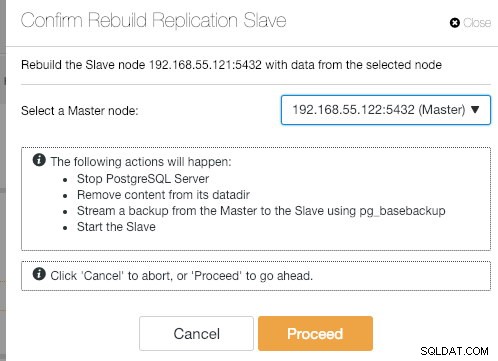
Der alte Master wird dann ein Slave des neuen Masters, nachdem der Synchronisierungsvorgang abgeschlossen ist:
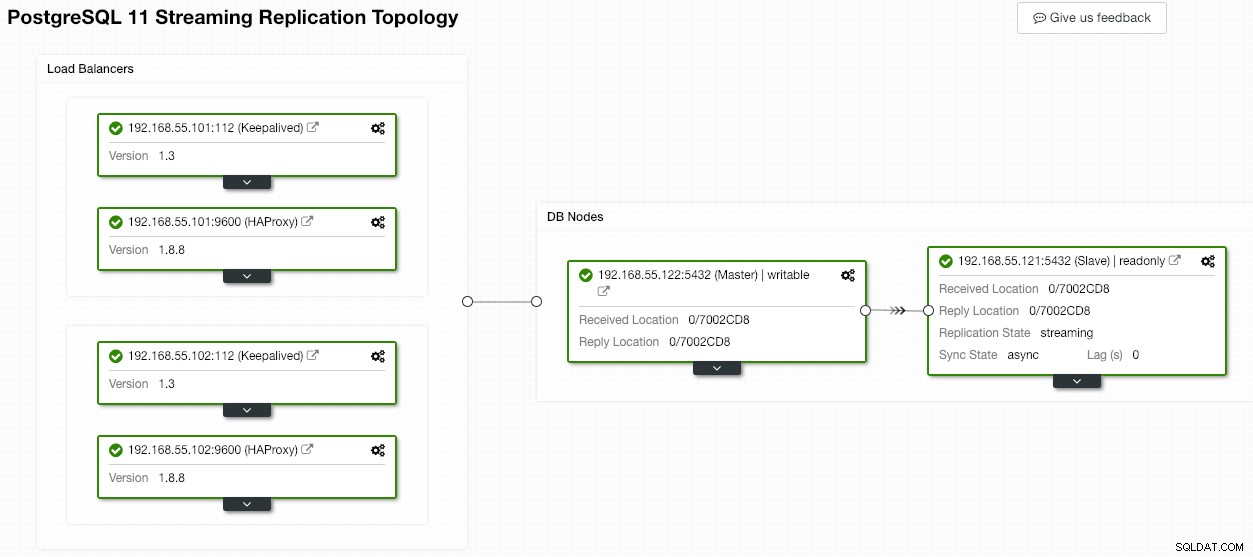
ClusterControl verbessert sicherlich die Datenbankverfügbarkeit mit seiner automatischen Wiederherstellungsfunktion und die erneute Synchronisierung eines fehlerhaften Datenbankknotens ist nur zwei Klicks entfernt. Wie einfach ist das nach einem katastrophalen Fehlerereignis?
Das war's erstmal, Leute. Viel Spaß beim Clustern!



