Eine der Hauptanforderungen für jede Datenbank ist die Skalierbarkeit. Dies kann nur erreicht werden, wenn die Konkurrenz (Sperre) so weit wie möglich minimiert, wenn nicht sogar ganz entfernt wird. Da Lesen/Schreiben/Aktualisieren/Löschen einige der häufigsten Vorgänge in der Datenbank sind, ist es sehr wichtig, dass diese Vorgänge gleichzeitig ausgeführt werden, ohne blockiert zu werden. Um dies zu erreichen, verwenden die meisten großen Datenbanken ein Parallelitätsmodell namens Multi-Version Concurrency Control wodurch Konflikte auf ein absolutes Minimum reduziert werden.
Was ist MVCC
Multi Version Concurrency Control (hier nachfolgend MVCC) ist ein Algorithmus zur Bereitstellung einer genauen Parallelitätssteuerung, indem mehrere Versionen desselben Objekts verwaltet werden, sodass READ- und WRITE-Operationen nicht in Konflikt geraten. Hier bedeutet WRITE UPDATE und DELETE, da ein neu eingefügter Datensatz sowieso gemäß Isolationsstufe geschützt wird. Jeder WRITE-Vorgang erzeugt eine neue Version des Objekts und jeder gleichzeitige Lesevorgang liest je nach Isolationsstufe eine andere Version des Objekts. Da sowohl Lesen als auch Schreiben auf verschiedenen Versionen desselben Objekts ausgeführt werden, muss keine dieser Operationen vollständig gesperrt werden, und daher können beide gleichzeitig ausgeführt werden. Der einzige Fall, in dem der Konflikt noch bestehen kann, ist, wenn zwei gleichzeitige Transaktionen versuchen, denselben Datensatz zu SCHREIBEN.
Die meisten der aktuellen großen Datenbanken unterstützen MVCC. Die Absicht dieses Algorithmus besteht darin, mehrere Versionen desselben Objekts zu verwalten, sodass sich die Implementierung von MVCC von Datenbank zu Datenbank nur darin unterscheidet, wie mehrere Versionen erstellt und verwaltet werden. Dementsprechend ändert sich der entsprechende Datenbankbetrieb und die Speicherung der Daten.
Der bekannteste Ansatz zur Implementierung von MVCC ist derjenige, der von PostgreSQL und Firebird/Interbase verwendet wird, und ein anderer wird von InnoDB und Oracle verwendet. In den folgenden Abschnitten werden wir detailliert besprechen, wie es in PostgreSQL und InnoDB implementiert wurde.
MVCC in PostgreSQL
Um mehrere Versionen zu unterstützen, verwaltet PostgreSQL zusätzliche Felder für jedes Objekt (Tupel in der PostgreSQL-Terminologie), wie unten erwähnt:
- xmin – Transaktions-ID der Transaktion, die das Tupel eingefügt oder aktualisiert hat. Bei UPDATE wird dieser Transaktions-ID eine neuere Version des Tupels zugewiesen.
- xmax – Transaktions-ID der Transaktion, die das Tupel gelöscht oder aktualisiert hat. Bei UPDATE wird diese Transaktions-ID einer aktuell existierenden Version des Tupels zugewiesen. Bei einem neu erstellten Tupel ist der Standardwert dieses Felds null.
PostgreSQL speichert alle Daten in einem primären Speicher namens HEAP (Seite mit einer Standardgröße von 8 KB). Alle neuen Tupel erhalten xmin als Transaktion, die sie erstellt hat, und alle Tupel der älteren Version (die aktualisiert oder gelöscht wurden) werden mit xmax zugewiesen. Es gibt immer einen Link vom Tupel der älteren Version zur neuen Version. Das Tupel der älteren Version kann verwendet werden, um das Tupel im Falle eines Rollbacks neu zu erstellen und je nach Isolationsstufe eine ältere Version eines Tupels per READ-Anweisung zu lesen.
Angenommen, es gibt zwei Tupel, T1 (mit Wert 1) und T2 (mit Wert 2) für eine Tabelle, die Erstellung neuer Zeilen kann in den folgenden 3 Schritten demonstriert werden:
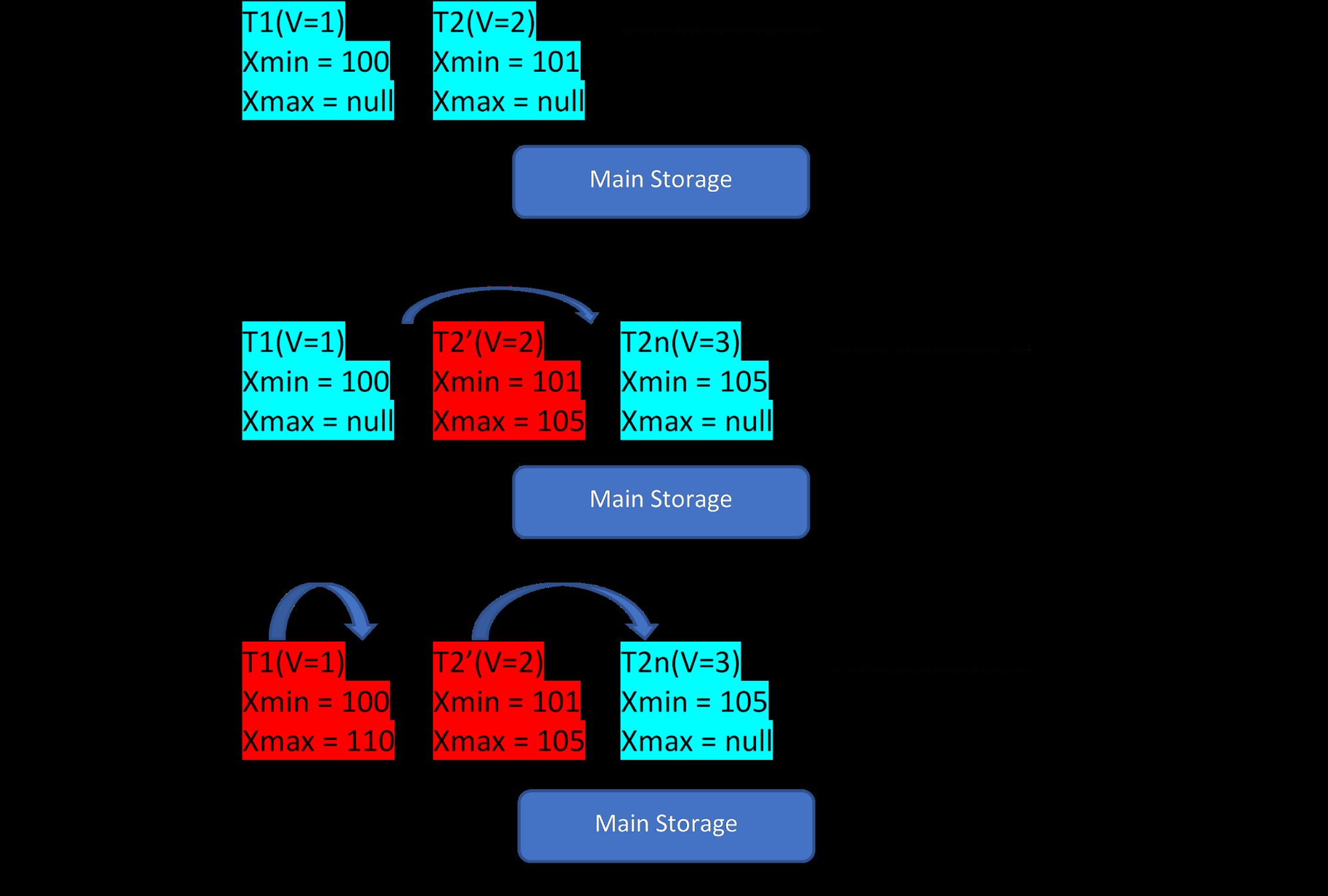 MVCC:Speicherung mehrerer Versionen in PostgreSQL
MVCC:Speicherung mehrerer Versionen in PostgreSQL Wie auf dem Bild zu sehen, gibt es zunächst zwei Tupel in der Datenbank mit den Werten 1 und 2.
Dann wird im zweiten Schritt die Zeile T2 mit dem Wert 2 mit dem Wert 3 aktualisiert. An diesem Punkt wird eine neue Version mit dem neuen Wert erstellt und einfach neben dem vorhandenen Tupel im selben Speicherbereich gespeichert . Davor wird der älteren Version xmax zugewiesen und zeigt auf das neueste Versionstupel.
In ähnlicher Weise wird im dritten Schritt, wenn die Zeile T1 mit dem Wert 1 gelöscht wird, die vorhandene Zeile an derselben Stelle virtuell gelöscht (d. h. sie hat gerade xmax mit der aktuellen Transaktion zugewiesen). Dafür wird keine neue Version erstellt.
Sehen wir uns als Nächstes anhand einiger realer Beispiele an, wie jeder Vorgang mehrere Versionen erstellt und wie die Transaktionsisolationsebene ohne Sperren beibehalten wird. In allen Beispielen unten wird standardmäßig die Isolierung „READ COMMITTED“ verwendet.
EINFÜGEN
Jedes Mal, wenn ein Datensatz eingefügt wird, wird ein neues Tupel erstellt, das einer der Seiten hinzugefügt wird, die zur entsprechenden Tabelle gehören.
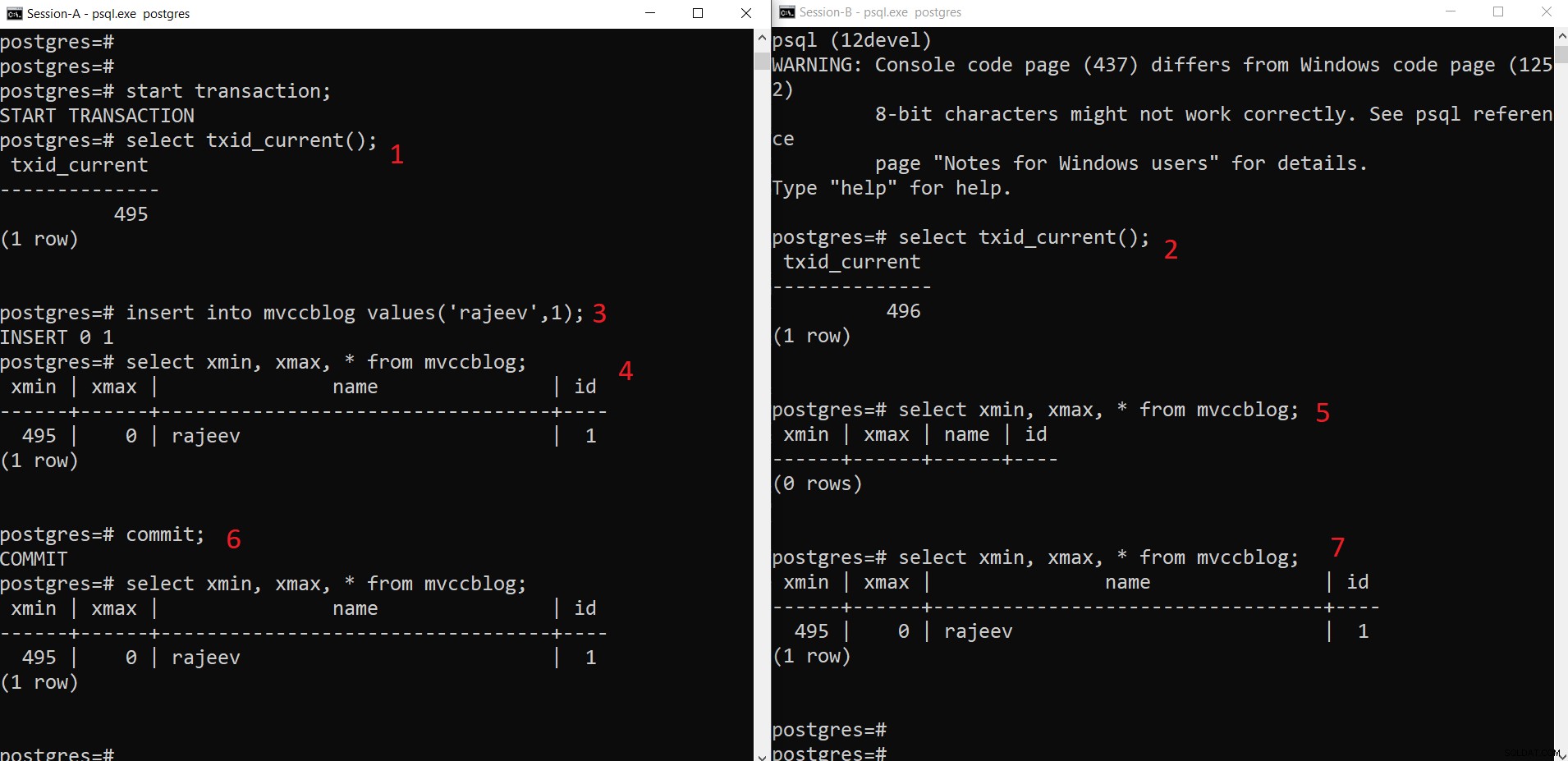 Gleichzeitiger PostgreSQL-INSERT-Vorgang
Gleichzeitiger PostgreSQL-INSERT-Vorgang Wie wir hier schrittweise sehen können:
- Session-A startet eine Transaktion und erhält die Transaktions-ID 495.
- Session-B startet eine Transaktion und erhält die Transaktions-ID 496.
- Sitzung-A fügt ein neues Tupel ein (wird im HEAP gespeichert)
- Nun wird das neue Tupel mit xmin auf die aktuelle Transaktions-ID 495 gesetzt.
- Aber dasselbe ist von Sitzung-B nicht sichtbar, da xmin (d.h. 495) immer noch nicht festgeschrieben ist.
- Einmal zugesagt.
- Daten sind für beide Sitzungen sichtbar.
AKTUALISIEREN
PostgreSQL UPDATE ist kein „IN-PLACE“-Update, d. h. es ändert das vorhandene Objekt nicht mit dem erforderlichen neuen Wert. Stattdessen wird eine neue Version des Objekts erstellt. UPDATE umfasst also im Großen und Ganzen die folgenden Schritte:
- Markiert das aktuelle Objekt als gelöscht.
- Dann fügt es eine neue Version des Objekts hinzu.
- Leiten Sie die ältere Version des Objekts auf eine neue Version um.
Obwohl also eine Anzahl von Datensätzen gleich bleibt, nimmt HEAP Speicherplatz ein, als ob ein weiterer Datensatz eingefügt worden wäre.
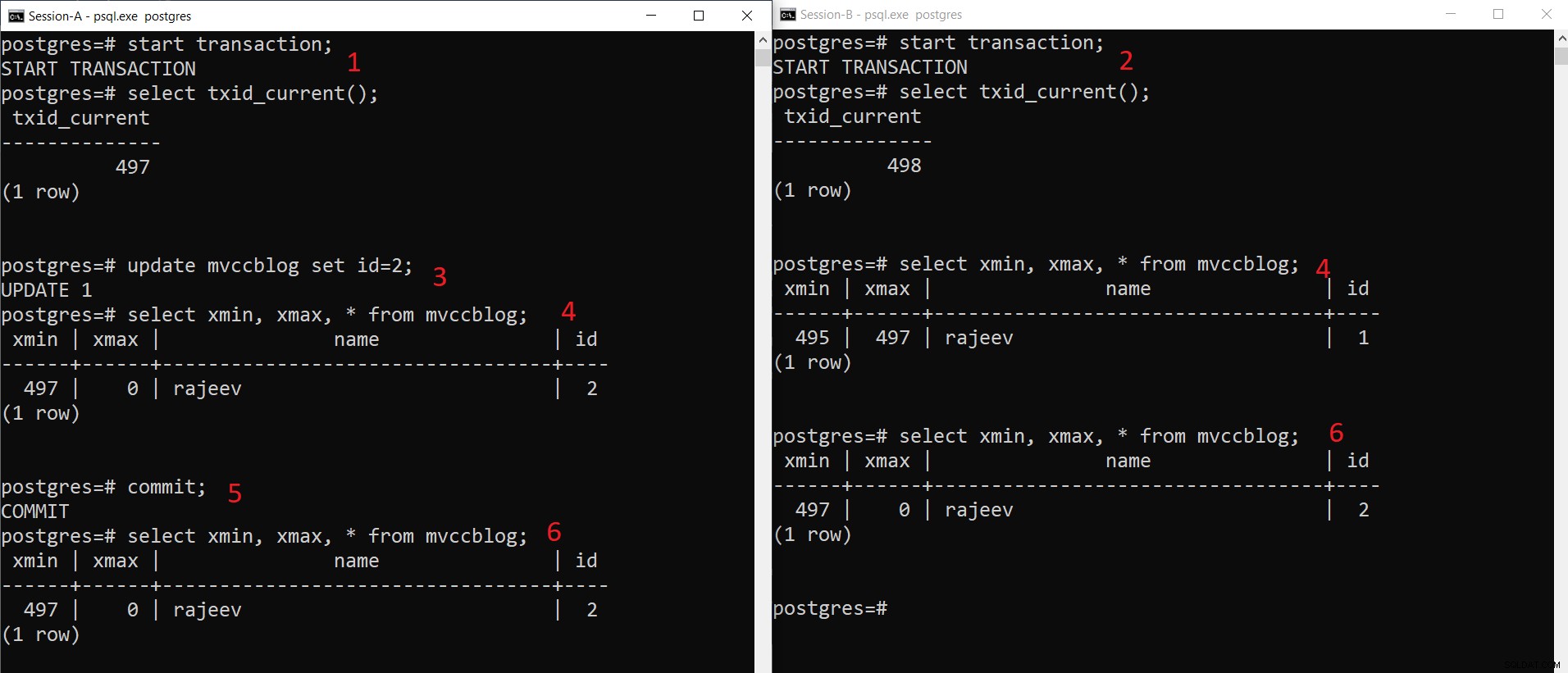 Gleichzeitiger PostgreSQL-INSERT-Vorgang
Gleichzeitiger PostgreSQL-INSERT-Vorgang Wie wir hier schrittweise sehen können:
- Session-A startet eine Transaktion und erhält die Transaktions-ID 497.
- Session-B startet eine Transaktion und erhält die Transaktions-ID 498.
- Sitzung-A aktualisiert den vorhandenen Datensatz.
- Hier sieht Sitzung-A eine Version des Tupels (aktualisiertes Tupel), während Sitzung-B eine andere Version sieht (älteres Tupel, aber xmax auf 497 gesetzt). Beide Tupelversionen werden im HEAP-Speicher gespeichert (je nach verfügbarem Speicherplatz sogar auf derselben Seite)
- Sobald Sitzung-A die Transaktion festschreibt, läuft das ältere Tupel ab, da xmax des älteren Tupels festgeschrieben wird.
- Jetzt sehen beide Sitzungen dieselbe Version des Datensatzes.
LÖSCHEN
Das Löschen ist fast wie die UPDATE-Operation, außer dass keine neue Version hinzugefügt werden muss. Es markiert nur das aktuelle Objekt als GELÖSCHT, wie es im UPDATE-Fall erklärt wird.
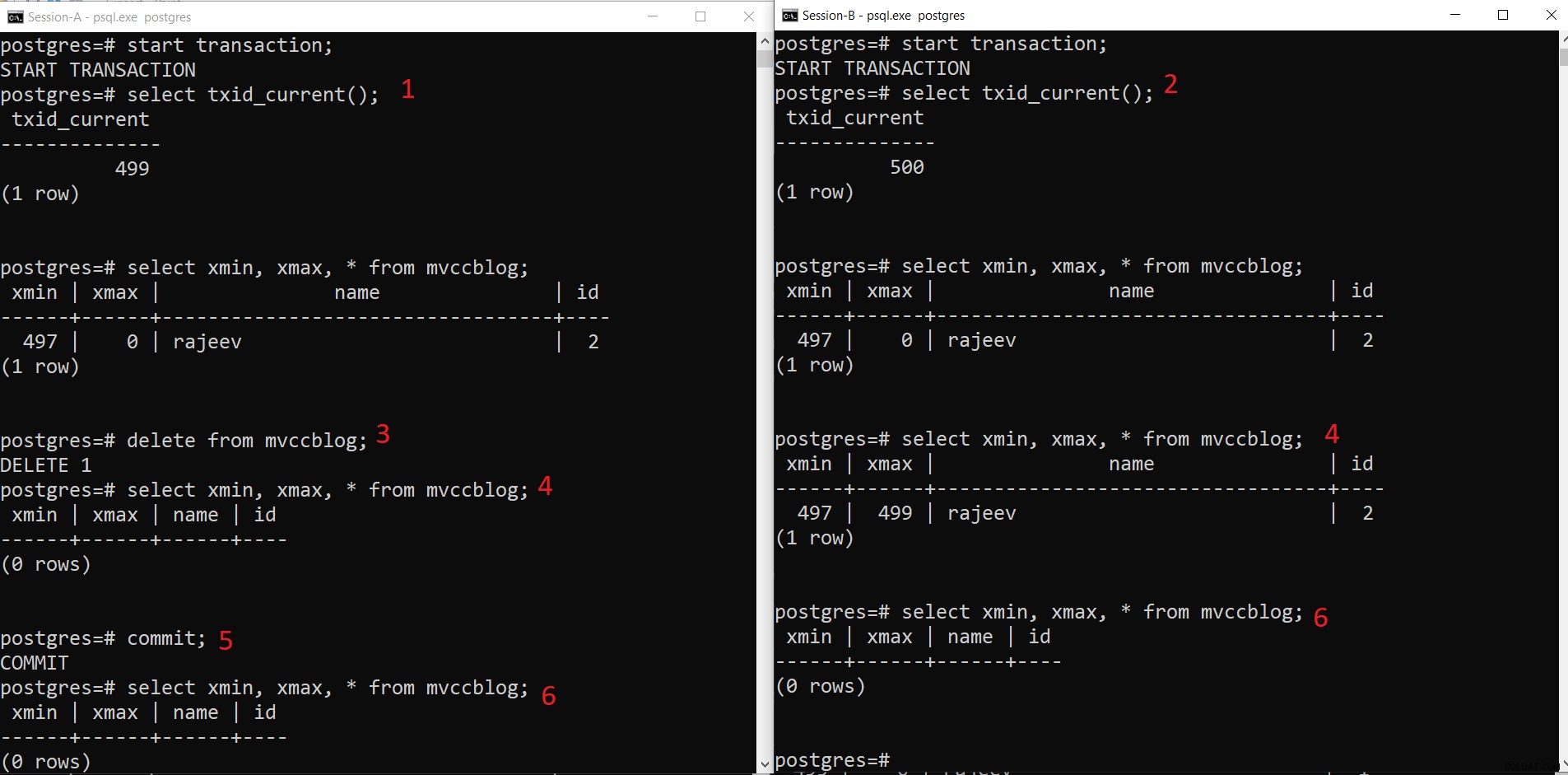 Gleichzeitiger PostgreSQL-DELETE-Vorgang
Gleichzeitiger PostgreSQL-DELETE-Vorgang - Session-A startet eine Transaktion und erhält die Transaktions-ID 499.
- Session-B startet eine Transaktion und erhält die Transaktions-ID 500.
- Sitzung-A löscht den vorhandenen Datensatz.
- Hier sieht Sitzung-A kein Tupel als aus der aktuellen Transaktion gelöscht. Während Sitzung-B eine ältere Version des Tupels sieht (mit xmax als 499; die Transaktion, die diesen Datensatz gelöscht hat).
- Sobald Sitzung-A die Transaktion festschreibt, läuft das ältere Tupel ab, da xmax des älteren Tupels festgeschrieben wird.
- Jetzt sehen beide Sitzungen kein gelöschtes Tupel.
Wie wir sehen können, entfernt keine der Operationen die vorhandene Version des Objekts direkt und fügt bei Bedarf eine zusätzliche Version des Objekts hinzu.
Sehen wir uns nun an, wie die SELECT-Abfrage für ein Tupel mit mehreren Versionen ausgeführt wird:SELECT muss alle Versionen des Tupels lesen, bis es das geeignete Tupel gemäß Isolationsstufe findet. Angenommen, es gab Tupel T1, das aktualisiert wurde und die neue Version T1’ erstellte und das wiederum T1’’ beim Update erstellte:
- Die SELECT-Operation durchläuft den Heap-Speicher für diese Tabelle und prüft zuerst T1. Wenn die T1 xmax-Transaktion festgeschrieben wird, geht sie zur nächsten Version dieses Tupels über.
- Nehmen wir nun an, dass das Tupel xmax von T1 ebenfalls festgeschrieben wird, dann bewegt es sich wieder zur nächsten Version dieses Tupels.
- Schließlich findet es T1’’ und stellt fest, dass xmax nicht festgeschrieben (oder null) ist und T1’’ xmin gemäß Isolationsstufe für die aktuelle Transaktion sichtbar ist. Schließlich wird es T1’’-Tupel lesen.
Wie wir sehen können, muss es alle 3 Versionen des Tupels durchlaufen, um das entsprechende sichtbare Tupel zu finden, bis das abgelaufene Tupel vom Garbage Collector (VACUUM) gelöscht wird.
MVCC in InnoDB
Um mehrere Versionen zu unterstützen, verwaltet InnoDB zusätzliche Felder für jede Zeile, wie unten erwähnt:
- DB_TRX_ID:Transaktions-ID der Transaktion, die die Zeile eingefügt oder aktualisiert hat.
- DB_ROLL_PTR:Er wird auch als Roll-Zeiger bezeichnet und zeigt auf den Undo-Log-Datensatz, der in das Rollback-Segment geschrieben wurde (mehr dazu weiter unten).
Wie PostgreSQL erstellt auch InnoDB mehrere Versionen der Zeile als Teil aller Vorgänge, aber die Speicherung der älteren Version ist anders.
Im Fall von InnoDB wird die alte Version der geänderten Zeile in einem separaten Tablespace/Speicher (genannt Undo-Segment) aufbewahrt. Also behält InnoDB im Gegensatz zu PostgreSQL nur die neueste Version der Zeilen im Hauptspeicherbereich und die ältere Version wird im Undo-Segment aufbewahrt. Zeilenversionen aus dem Undo-Segment werden verwendet, um den Vorgang im Falle eines Rollbacks rückgängig zu machen und je nach Isolationsstufe eine ältere Version von Zeilen per READ-Anweisung zu lesen.
Angenommen, es gibt zwei Zeilen, T1 (mit Wert 1) und T2 (mit Wert 2) für eine Tabelle, die Erstellung neuer Zeilen kann in den folgenden 3 Schritten demonstriert werden:
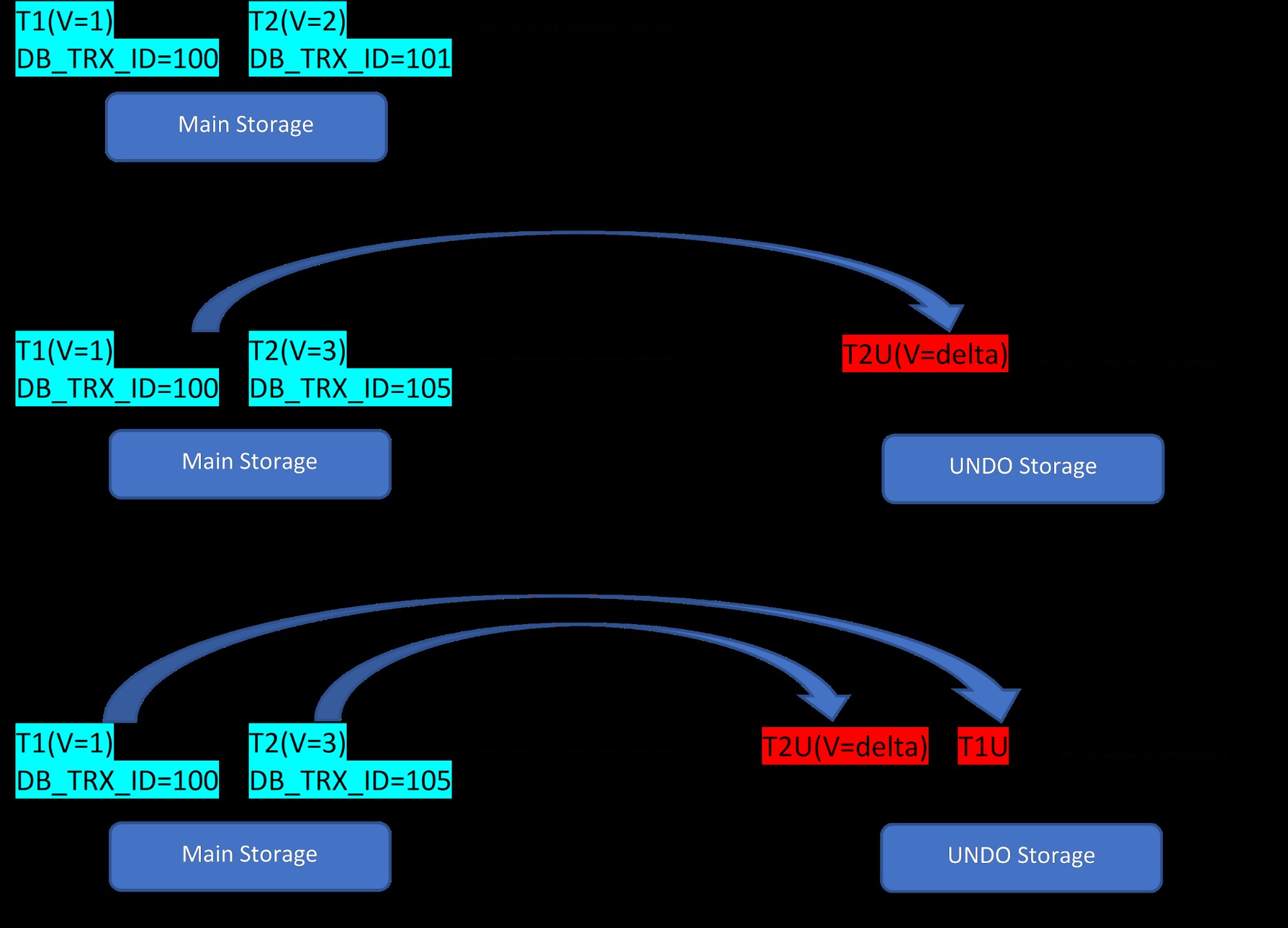 MVCC:Speicherung mehrerer Versionen in InnoDB
MVCC:Speicherung mehrerer Versionen in InnoDB Wie aus der Abbildung ersichtlich, gibt es zunächst zwei Zeilen in der Datenbank mit den Werten 1 und 2.
Dann wird in der zweiten Stufe die Zeile T2 mit dem Wert 2 mit dem Wert 3 aktualisiert. An diesem Punkt wird eine neue Version mit dem neuen Wert erstellt und ersetzt die ältere Version. Davor wird die ältere Version im Undo-Segment gespeichert (beachten Sie, dass die Version des UNDO-Segments nur einen Delta-Wert hat). Beachten Sie auch, dass es im Rollback-Segment einen Zeiger von der neuen Version auf die ältere Version gibt. Im Gegensatz zu PostgreSQL ist das InnoDB-Update also „IN-PLACE“.
In ähnlicher Weise wird im dritten Schritt, wenn die Zeile T1 mit dem Wert 1 gelöscht wird, die vorhandene Zeile im Hauptspeicherbereich virtuell gelöscht (d. h. sie markiert nur ein spezielles Bit in der Zeile) und eine dieser entsprechende neue Version wird hinzugefügt das Rückgängig-Segment. Auch hier gibt es einen Rollzeiger vom Hauptspeicher zum Undo-Segment.
Alle Operationen verhalten sich von außen gesehen genauso wie bei PostgreSQL. Nur der interne Speicher mehrerer Versionen unterscheidet sich.
Laden Sie noch heute das Whitepaper PostgreSQL-Verwaltung und -Automatisierung mit ClusterControl herunterErfahren Sie, was Sie wissen müssen, um PostgreSQL bereitzustellen, zu überwachen, zu verwalten und zu skalierenLaden Sie das Whitepaper herunterMVCC:PostgreSQL vs. InnoDB
Lassen Sie uns nun analysieren, was die Hauptunterschiede zwischen PostgreSQL und InnoDB in Bezug auf ihre MVCC-Implementierung sind:
-
Größe einer älteren Version
PostgreSQL aktualisiert nur xmax auf der älteren Version des Tupels, sodass die Größe der älteren Version die gleiche bleibt wie die des entsprechenden eingefügten Datensatzes. Das bedeutet, wenn Sie 3 Versionen eines älteren Tupels haben, haben alle dieselbe Größe (mit Ausnahme des Unterschieds in der tatsächlichen Datengröße, falls vorhanden, bei jeder Aktualisierung).
Im Fall von InnoDB ist die im Undo-Segment gespeicherte Objektversion normalerweise kleiner als der entsprechende eingefügte Datensatz. Dies liegt daran, dass nur die geänderten Werte (d. h. Differenz) in das UNDO-Protokoll geschrieben werden.
-
INSERT-Vorgang
InnoDB muss auch für INSERT einen zusätzlichen Datensatz in das UNDO-Segment schreiben, während PostgreSQL nur im Falle von UPDATE eine neue Version erstellt.
-
Wiederherstellen einer älteren Version im Falle eines Rollbacks
PostgreSQL muss nichts Besonderes tun, um im Falle eines Rollbacks eine ältere Version wiederherzustellen. Denken Sie daran, dass bei der älteren Version xmax gleich der Transaktion ist, die dieses Tupel aktualisiert hat. Bis diese Transaktions-ID festgeschrieben wird, wird sie also als aktives Tupel für einen gleichzeitigen Snapshot betrachtet. Sobald die Transaktion zurückgesetzt wird, wird die entsprechende Transaktion automatisch für alle Transaktionen als aktiv betrachtet, da es sich um eine abgebrochene Transaktion handelt.
Wohingegen im Fall von InnoDB es ausdrücklich erforderlich ist, die ältere Version des Objekts neu zu erstellen, sobald ein Rollback stattfindet.
-
Freigabe von Speicherplatz, der von einer älteren Version belegt ist
Im Falle von PostgreSQL kann der von einer älteren Version belegte Speicherplatz nur dann als tot betrachtet werden, wenn es keinen parallelen Snapshot zum Lesen dieser Version gibt. Sobald die ältere Version tot ist, kann die VACUUM-Operation den von ihr belegten Speicherplatz zurückfordern. VACUUM kann je nach Konfiguration manuell oder als Hintergrundaufgabe ausgelöst werden.
InnoDB UNDO-Protokolle sind hauptsächlich in INSERT UNDO und UPDATE UNDO unterteilt. Der erste wird verworfen, sobald die entsprechende Transaktion festgeschrieben wird. Der zweite muss beibehalten werden, bis er parallel zu einem anderen Snapshot ist. InnoDB hat keine explizite VACUUM-Operation, aber auf einer ähnlichen Linie hat es asynchrones PURGE, um UNDO-Protokolle zu verwerfen, was als Hintergrundaufgabe läuft.
-
Auswirkung des verzögerten Vakuums
Wie in einem vorherigen Punkt besprochen, hat das verzögerte Vakuum im Falle von PostgreSQL einen enormen Einfluss. Es führt dazu, dass die Tabelle anfängt aufzublähen und der Speicherplatz zunimmt, obwohl Datensätze ständig gelöscht werden. Es kann auch einen Punkt erreichen, an dem VACUUM VOLL durchgeführt werden muss, was sehr kostspielige Vorgänge sind.
-
Sequentielles Scannen bei aufgeblähter Tabelle
Der sequenzielle PostgreSQL-Scan muss alle älteren Versionen eines Objekts durchlaufen, obwohl alle tot sind (bis sie mithilfe von Vakuum entfernt werden). Dies ist das typische und am häufigsten diskutierte Problem in PostgreSQL. Denken Sie daran, dass PostgreSQL alle Versionen eines Tupels im selben Speicher speichert.
Im Fall von InnoDB muss der Undo-Datensatz nicht gelesen werden, es sei denn, dies ist erforderlich. Falls alle Rückgängig-Datensätze tot sind, reicht es nur, die neueste Version der Objekte durchzulesen.
-
Index
PostgreSQL speichert den Index in einem separaten Speicher, der eine Verbindung zu den tatsächlichen Daten im HEAP aufrechterhält. PostgreSQL muss also auch den INDEX-Teil aktualisieren, obwohl es keine Änderung im INDEX gab. Obwohl dieses Problem später durch die Implementierung des HOT-Updates (Heap Only Tuple) behoben wurde, hat es immer noch die Einschränkung, dass es auf das normale UPDATE zurückfällt, wenn ein neues Heap-Tupel nicht auf derselben Seite untergebracht werden kann.
InnoDB hat dieses Problem nicht, da sie geclusterte Indizes verwenden.
Schlussfolgerung
PostgreSQL MVCC hat einige Nachteile, insbesondere in Bezug auf aufgeblähten Speicher, wenn Ihre Workload häufig UPDATE/DELETE hat. Wenn Sie sich also für die Verwendung von PostgreSQL entscheiden, sollten Sie sehr darauf achten, VACUUM mit Bedacht zu konfigurieren.
Die PostgreSQL-Community hat dies ebenfalls als ein wichtiges Problem erkannt und sie haben bereits mit der Arbeit an einem UNDO-basierten MVCC-Ansatz (vorläufiger Name als ZHEAP) begonnen, und wir könnten dasselbe in einer zukünftigen Version sehen.