Es gibt kein perfektes System, keine perfekte Hardware oder Topologie, um alle möglichen Probleme zu vermeiden, die in einer Produktionsumgebung auftreten können. Die Bewältigung dieser Herausforderungen erfordert einen effektiven DRP (Disaster Recovery Plan), der gemäß Ihrer Anwendung, Infrastruktur und Ihren Geschäftsanforderungen konfiguriert ist. Der Schlüssel zum Erfolg in solchen Situationen ist immer, wie schnell wir das Problem beheben oder beheben können.
In diesem Blog werfen wir einen Blick auf die häufigsten PostgreSQL-Fehlerszenarien und zeigen Ihnen, wie Sie die Probleme lösen oder bewältigen können. Wir werden uns auch ansehen, wie ClusterControl uns helfen kann, wieder online zu gehen
Die allgemeine PostgreSQL-Topologie
Um allgemeine Fehlerszenarien zu verstehen, müssen Sie zunächst mit einer allgemeinen PostgreSQL-Topologie beginnen. Dies kann jede Anwendung sein, die mit einem primären PostgreSQL-Knoten verbunden ist, mit dem ein Replikat verbunden ist.
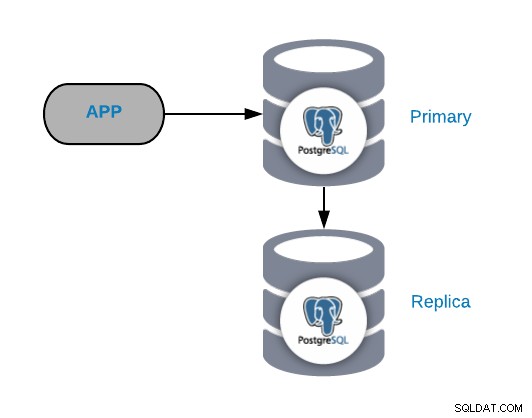
Sie können diese Topologie jederzeit verbessern oder erweitern, indem Sie weitere Knoten oder Load Balancer hinzufügen , aber dies ist die grundlegende Topologie, mit der wir anfangen werden.
Primärer PostgreSQL-Knotenfehler
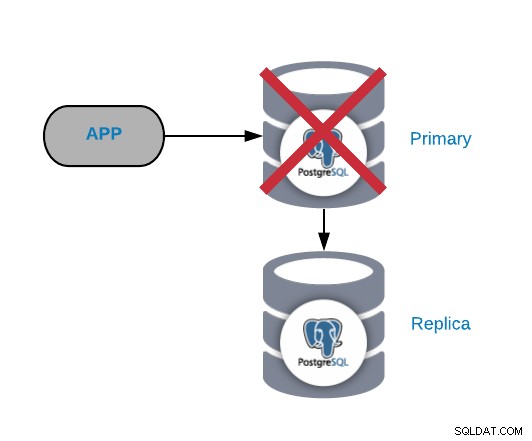
Dies ist einer der kritischsten Fehler, da wir ihn so schnell wie möglich beheben sollten Wir wollen unsere Systeme online halten. Für diese Art von Fehlern ist es wichtig, einen automatischen Failover-Mechanismus zu haben. Nach dem Fehler können Sie den Grund für die Probleme untersuchen. Nach dem Failover-Prozess stellen wir sicher, dass der ausgefallene primäre Knoten nicht immer noch denkt, dass er der primäre Knoten ist. Dies dient dazu, Dateninkonsistenzen beim Schreiben zu vermeiden.
Die häufigsten Ursachen für diese Art von Problemen sind ein Betriebssystemfehler, ein Hardwarefehler oder ein Festplattenfehler. In jedem Fall sollten wir die Datenbank und die Betriebssystemprotokolle überprüfen, um den Grund zu finden.
Die schnellste Lösung für dieses Problem ist die Durchführung einer Failover-Aufgabe, um Ausfallzeiten zu reduzieren. Um ein Replikat hochzustufen, können wir den Befehl pg_ctl promote auf dem Slave-Datenbankknoten verwenden, und dann müssen wir den Datenverkehr von senden Anwendung auf den neuen primären Knoten. Für diese letzte Aufgabe können wir einen Load Balancer zwischen unserer Anwendung und den Datenbankknoten implementieren, um im Fehlerfall Änderungen von der Anwendungsseite zu vermeiden. Wir können den Load Balancer auch so konfigurieren, dass er den Knotenausfall erkennt und den Datenverkehr nicht an ihn, sondern an den neuen primären Knoten sendet.
Nach dem Failover-Prozess und sicherstellen, dass das System wieder funktioniert, können wir das Problem untersuchen, und wir empfehlen, immer mindestens einen Slave-Knoten am Laufen zu halten, damit im Falle eines neuen primären Ausfalls, wir können die Failover-Aufgabe erneut durchführen.
PostgreSQL-Replikatknotenfehler
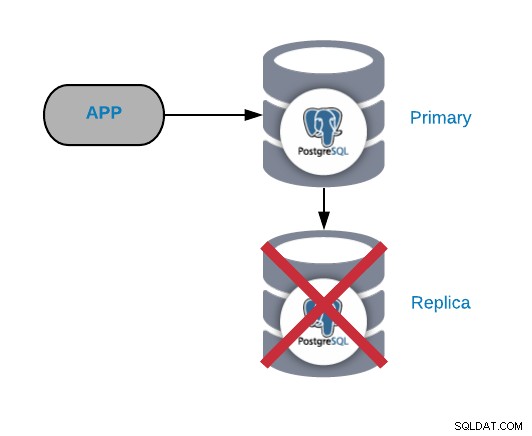
Dies ist normalerweise kein kritisches Problem (solange Sie mehr als ein Replikat und verwenden es nicht zum Senden des Lese-Produktionsdatenverkehrs). Wenn Sie Probleme auf dem primären Knoten haben und Ihr Replikat nicht auf dem neuesten Stand ist, haben Sie ein wirklich kritisches Problem. Wenn Sie unser Replikat für Berichte oder Big-Data-Zwecke verwenden, möchten Sie es wahrscheinlich sowieso schnell reparieren.
Die häufigsten Ursachen für diese Art von Problem sind die gleichen, die wir für den primären Knoten gesehen haben, ein Betriebssystemfehler, ein Hardwarefehler oder ein Festplattenfehler. Sie sollten die Datenbank und die Betriebssystemprotokolle überprüfen um den Grund zu finden.
Es wird nicht empfohlen, das System ohne Replikat am Laufen zu halten, da Sie im Falle eines Ausfalls keine schnelle Möglichkeit haben, wieder online zu gehen. Wenn Sie nur einen Slave haben, sollten Sie das Problem so schnell wie möglich lösen; Der schnellste Weg ist, eine neue Replik von Grund auf neu zu erstellen. Dazu müssen Sie ein konsistentes Backup erstellen und es auf dem Slave-Knoten wiederherstellen und dann die Replikation zwischen diesem Slave-Knoten und dem primären Knoten konfigurieren.
Wenn Sie die Fehlerursache wissen möchten, sollten Sie einen anderen Server verwenden, um die neue Replik zu erstellen, und dann auf der alten nachsehen, um sie zu entdecken. Wenn Sie diese Aufgabe abgeschlossen haben, können Sie auch das alte Replikat neu konfigurieren und beide weiterhin als zukünftige Failover-Option verwenden.
Wenn Sie das Replikat für die Berichterstellung oder für Big-Data-Zwecke verwenden, müssen Sie die IP-Adresse ändern, um eine Verbindung zur neuen herzustellen. Wie im vorherigen Fall besteht eine Möglichkeit, diese Änderung zu vermeiden, darin, einen Load Balancer zu verwenden, der den Status jedes Servers kennt, sodass Sie nach Belieben Replikate hinzufügen/entfernen können.
PostgreSQL-Replikationsfehler
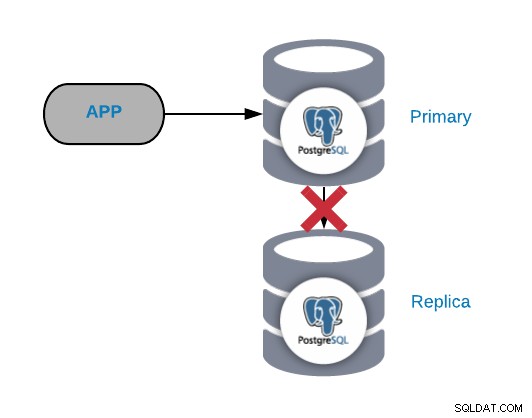
Im Allgemeinen wird diese Art von Problem aufgrund eines Netzwerks oder einer Konfiguration generiert Ausgabe. Es hängt mit einem WAL-Verlust (Write-Ahead Logging) im primären Knoten und der Art und Weise zusammen, wie PostgreSQL die Replikation verwaltet.
Wenn Sie wichtigen Verkehr haben, machen Sie zu häufig Checkpoints oder speichern WALS nur für ein paar Minuten; Wenn Sie ein Netzwerkproblem haben, haben Sie wenig Zeit, es zu lösen. Ihre WALs würden gelöscht, bevor Sie sie senden und auf das Replikat anwenden können.
Wenn die WAL, die das Replikat benötigt, um weiter zu funktionieren, gelöscht wurde, müssen Sie sie neu erstellen, um diese Aufgabe zu vermeiden, sollten wir also unsere Datenbankkonfiguration überprüfen, um die wal_keep_segments (Mengen an WALS, die in der pg_xlog-Verzeichnis) oder die Parameter max_wal_senders (maximale Anzahl gleichzeitig laufender WAL-Sender-Prozesse).
Eine weitere empfohlene Option besteht darin, archive_mode on zu konfigurieren und die WAL-Dateien mit dem Parameter archive_command an einen anderen Pfad zu senden. Wenn PostgreSQL das Limit erreicht und die WAL-Datei löscht, haben wir sie auf diese Weise sowieso in einem anderen Pfad.
PostgreSQL-Datenbeschädigung / Dateninkonsistenz / versehentliches Löschen

Dies ist ein Albtraum für jeden DBA und wahrscheinlich das komplexeste Problem überhaupt behoben, je nachdem, wie weit verbreitet das Problem ist.
Wenn Ihre Daten von einigen dieser Probleme betroffen sind, besteht die häufigste (und wahrscheinlich einzige) Möglichkeit zur Behebung darin, eine Sicherungskopie wiederherzustellen. Aus diesem Grund sind Backups die Grundform jedes Notfallwiederherstellungsplans, und es wird empfohlen, mindestens drei Backups an verschiedenen physischen Orten zu speichern. Best Practice schreibt vor, dass Sicherungsdateien lokal auf dem Datenbankserver gespeichert werden sollten (für eine schnellere Wiederherstellung), eine andere auf einem zentralisierten Sicherungsserver und die letzte in der Cloud.
Wir können auch eine Mischung aus vollständigen/inkrementellen/differenziellen PITR-kompatiblen Sicherungen erstellen, um unser Wiederherstellungspunktziel zu reduzieren.
Verwalten von PostgreSQL-Fehlern mit ClusterControl
Nachdem wir uns nun diese gängigen PostgreSQL-Fehlerszenarien angesehen haben, schauen wir uns an, was passieren würde, wenn wir Ihre PostgreSQL-Datenbanken von einem zentralisierten Datenbankverwaltungssystem aus verwalten würden. Eine, die großartig ist, um das Problem im Falle eines Fehlers schnell und einfach zu beheben, so schnell wie möglich.
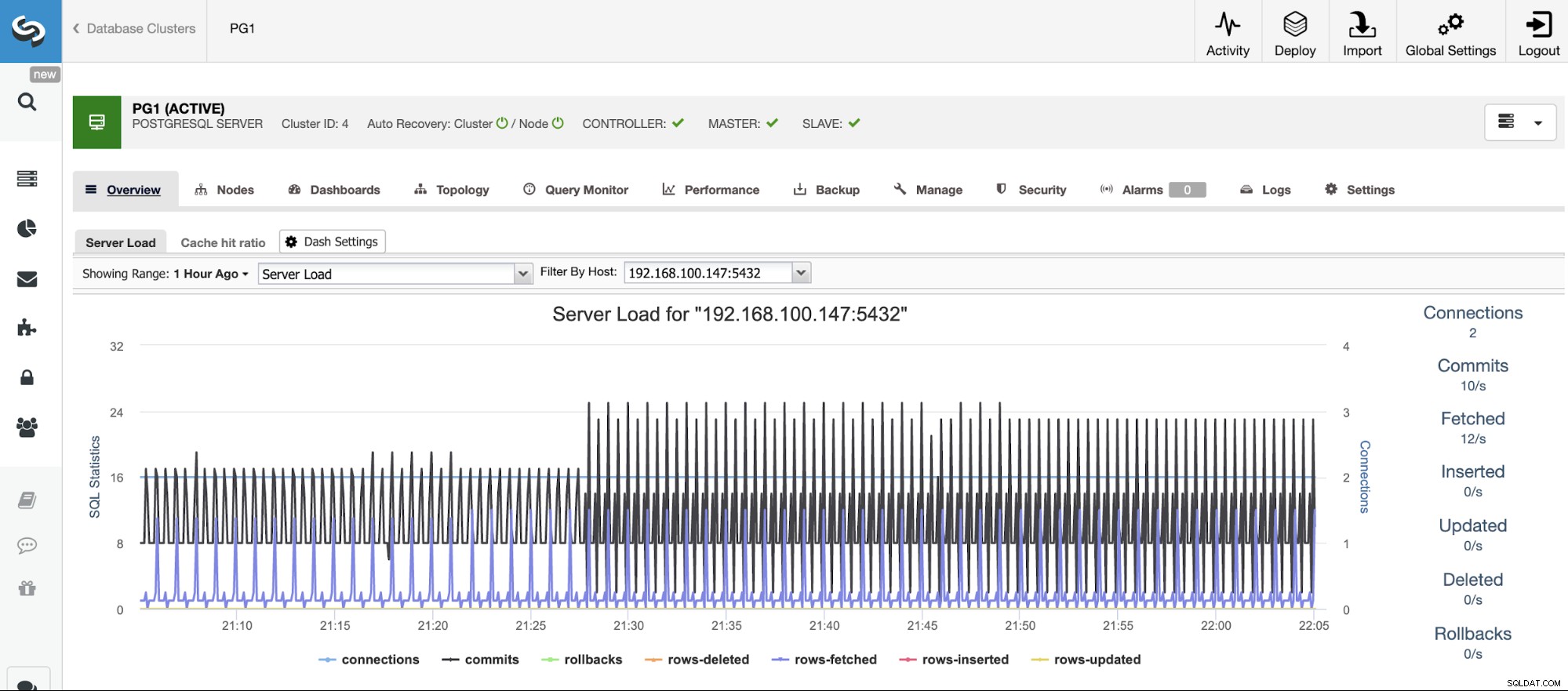
ClusterControl bietet Automatisierung für die meisten der oben beschriebenen PostgreSQL-Aufgaben; alles zentralisiert und benutzerfreundlich. Mit diesem System können Sie ganz einfach Dinge konfigurieren, die manuell Zeit und Mühe kosten würden. Wir werden nun einige der Hauptfunktionen in Bezug auf PostgreSQL-Fehlerszenarien überprüfen.
PostgreSQL-Cluster bereitstellen/importieren
Sobald wir die ClusterControl-Oberfläche aufgerufen haben, müssen Sie als Erstes einen neuen Cluster bereitstellen oder einen vorhandenen importieren. Um eine Bereitstellung durchzuführen, wählen Sie einfach die Option Datenbank-Cluster bereitstellen aus und folgen Sie den angezeigten Anweisungen.
Skalieren Ihres PostgreSQL-Clusters
Wenn Sie zu Cluster-Aktionen gehen und Replikations-Slave hinzufügen auswählen, können Sie entweder eine neue Replik von Grund auf neu erstellen oder eine vorhandene PostgreSQL-Datenbank als Replik hinzufügen. Auf diese Weise können Sie Ihre neue Replik in wenigen Minuten zum Laufen bringen und wir können so viele Repliken hinzufügen, wie wir möchten. Verteilung des Leseverkehrs zwischen ihnen mithilfe eines Load Balancers (den wir auch mit ClusterControl implementieren können).
Automatisches PostgreSQL-Failover
ClusterControl verwaltet das Failover Ihres Replikations-Setups. Es erkennt Master-Ausfälle und macht einen Slave mit den aktuellsten Daten zum neuen Master. Es führt auch automatisch ein Failover für die restlichen Slaves durch, um vom neuen Master zu replizieren. Für Client-Verbindungen werden zwei Tools für diese Aufgabe genutzt:HAProxy und Keepalived.
HAProxy ist ein Load Balancer, der den Datenverkehr von einem Ursprung zu einem oder mehreren Zielen verteilt und spezifische Regeln und/oder Protokolle für die Aufgabe definieren kann. Wenn eines der Ziele nicht mehr reagiert, wird es als offline markiert und der Datenverkehr wird an eines der verfügbaren Ziele gesendet. Dadurch wird verhindert, dass Datenverkehr an ein unzugängliches Ziel gesendet wird und diese Informationen verloren gehen, indem er an ein gültiges Ziel geleitet wird.
Keepalived ermöglicht es Ihnen, eine virtuelle IP innerhalb einer Aktiv/Passiv-Gruppe von Servern zu konfigurieren. Diese virtuelle IP wird einem aktiven „Main“-Server zugewiesen. Wenn dieser Server ausfällt, wird die IP automatisch auf den „sekundären“ Server migriert, der als passiv befunden wurde, sodass dieser auf für unsere Systeme transparente Weise mit derselben IP weiterarbeiten kann.
Hinzufügen eines PostgreSQL-Load-Balancers
Wenn Sie zu Cluster-Aktionen gehen und Load Balancer hinzufügen auswählen (oder in der Clusteransicht - gehen Sie zu Verwalten -> Load Balancer), können Sie Load Balancer zu unserer Datenbanktopologie hinzufügen.
Die zum Erstellen Ihres neuen Load Balancers erforderliche Konfiguration ist recht einfach. Sie müssen nur IP/Hostname, Port, Richtlinie und die Knoten hinzufügen, die wir verwenden werden. Sie können zwei Load Balancer mit Keepalived dazwischen hinzufügen, was uns ein automatisches Failover unseres Load Balancers im Falle eines Ausfalls ermöglicht. Keepalived verwendet eine virtuelle IP-Adresse und migriert sie im Fehlerfall von einem Load Balancer zu einem anderen, sodass unser Setup weiterhin normal funktionieren kann.
PostgreSQL-Sicherungen
Wir haben bereits die Bedeutung von Backups besprochen. ClusterControl bietet die Funktionalität, entweder ein sofortiges Backup zu erstellen oder eines zu planen.
Sie können zwischen drei verschiedenen Sicherungsmethoden wählen:pgdump, pg_basebackup oder pgBackRest. Sie können auch angeben, wo die Sicherungen gespeichert werden sollen (auf dem Datenbankserver, auf dem ClusterControl-Server oder in der Cloud), die Komprimierungsstufe, die erforderliche Verschlüsselung und den Aufbewahrungszeitraum.
PostgreSQL-Überwachung und -Benachrichtigung
Bevor Sie Maßnahmen ergreifen können, müssen Sie wissen, was passiert, also müssen Sie Ihren Datenbankcluster überwachen. ClusterControl ermöglicht es Ihnen, unsere Server in Echtzeit zu überwachen. Es gibt Diagramme mit grundlegenden Daten wie CPU, Netzwerk, Festplatte, RAM, IOPS sowie datenbankspezifischen Metriken, die von den PostgreSQL-Instanzen gesammelt wurden. Datenbankabfragen können auch im Abfragemonitor angezeigt werden.
So wie Sie die Überwachung von ClusterControl aus aktivieren, können Sie auch Warnmeldungen einrichten, die Sie über Ereignisse in Ihrem Cluster informieren. Diese Benachrichtigungen sind konfigurierbar und können nach Bedarf personalisiert werden.
Fazit
Jeder wird irgendwann mit PostgreSQL-Problemen und -Ausfällen fertig werden müssen. Und da Sie das Problem nicht vermeiden können, müssen Sie in der Lage sein, es so schnell wie möglich zu beheben und das System am Laufen zu halten. Wir haben auch gesehen, wie die Verwendung von ClusterControl bei diesen Problemen helfen kann; alles von einer einzigen und benutzerfreundlichen Plattform aus.
Dies sind unserer Meinung nach einige der häufigsten Ausfallszenarien für PostgreSQL. Wir würden uns freuen, von Ihren eigenen Erfahrungen zu hören und wie Sie es behoben haben.