In meinem vorherigen Blog haben wir verschiedene Möglichkeiten zum Auswählen oder Scannen von Daten aus einer einzelnen Tabelle besprochen. In der Praxis reicht es jedoch nicht aus, Daten aus einer einzelnen Tabelle abzurufen. Es erfordert die Auswahl von Daten aus mehreren Tabellen und die anschließende Korrelation zwischen ihnen. Die Korrelation dieser Daten zwischen Tabellen wird Joining-Tabellen genannt und kann auf verschiedene Weise erfolgen. Da das Verbinden von Tabellen Eingabedaten erfordert (z. B. aus dem Tabellenscan), kann es niemals ein Blattknoten im generierten Plan sein.
zB. Betrachten Sie ein einfaches Abfragebeispiel als SELECT * FROM TBL1, TBL2, wobei TBL1.ID> TBL2.ID; und nehmen wir an, der generierte Plan sieht wie folgt aus:
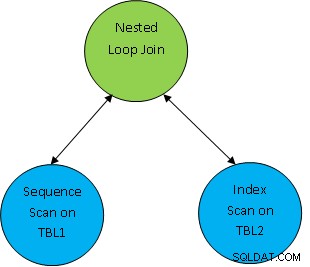
Also hier werden zuerst beide Tabellen gescannt und dann als zusammengefügt gemäß der Korrelationsbedingung als TBL.ID> TBL2.ID
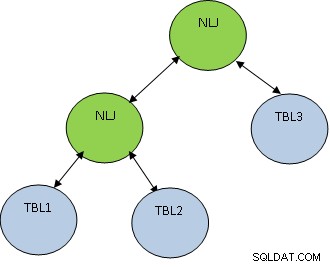
Neben der Join-Methode ist auch die Join-Reihenfolge sehr wichtig. Betrachten Sie das folgende Beispiel:
SELECT * FROM TBL1, TBL2, TBL3 WO TBL1.ID=TBL2.ID UND TBL2.ID=TBL3.ID;
Beachten Sie, dass TBL1, TBL2 UND TBL3 jeweils 10, 100 und 1000 Datensätze haben.
Die Bedingung TBL1.ID=TBL2.ID gibt nur 5 Datensätze zurück, während TBL2.ID=TBL3.ID 100 Datensätze zurückgibt, dann ist es besser, zuerst TBL1 und TBL2 zu verbinden, damit weniger Datensätze entstehen verbunden mit TBL3. Der Plan sieht wie folgt aus:
PostgreSQL unterstützt die folgenden Arten von Joins:
- Nested-Loop-Join
- Hash-Join
- Join zusammenführen
Jede dieser Join-Methoden ist gleichermaßen nützlich, abhängig von der Abfrage und anderen Parametern, z. Abfrage, Tabellendaten, Join-Klausel, Selektivität, Speicher usw. Diese Join-Methoden werden von den meisten relationalen Datenbanken implementiert.
Lassen Sie uns eine voreingestellte Tabelle erstellen und mit einigen Daten füllen, die häufig verwendet werden, um diese Scanmethoden besser zu erklären.
postgres=# create table blogtable1(id1 int, id2 int);
CREATE TABLE
postgres=# create table blogtable2(id1 int, id2 int);
CREATE TABLE
postgres=# insert into blogtable1 values(generate_series(1,10000),3);
INSERT 0 10000
postgres=# insert into blogtable2 values(generate_series(1,1000),3);
INSERT 0 1000
postgres=# analyze;
ANALYZEIn allen unseren nachfolgenden Beispielen berücksichtigen wir die Standardkonfigurationsparameter, sofern nicht ausdrücklich anders angegeben.
Nested-Loop-Join
Nested Loop Join (NLJ) ist der einfachste Join-Algorithmus, bei dem jeder Datensatz einer äußeren Relation mit jedem Datensatz einer inneren Relation abgeglichen wird. Der Join zwischen Relation A und B mit der Bedingung A.ID Nested Loop Join (NLJ) ist die gebräuchlichste Join-Methode und kann für fast jedes Dataset mit jeder Art von Join-Klausel verwendet werden. Da dieser Algorithmus alle Tupel innerer und äußerer Relationen scannt, wird er als die kostspieligste Join-Operation angesehen. Gemäß obiger Tabelle und Daten führt die folgende Abfrage zu einem Nested-Loop-Join, wie unten gezeigt: Da die Join-Klausel „<“ ist, ist die einzig mögliche Join-Methode hier Nested Loop Join. Beachten Sie hier eine neue Art von Knoten als Materialise; Dieser Knoten fungiert als Zwischenergebnis-Cache, d. h. anstatt alle Tupel einer Relation mehrmals abzurufen, wird das zum ersten Mal abgerufene Ergebnis im Speicher gespeichert und bei der nächsten Anfrage zum Abrufen des Tupels aus dem Speicher bedient, anstatt erneut von den Beziehungsseiten abzurufen . Falls nicht alle Tupel in den Speicher passen, werden Spillover-Tupel in eine temporäre Datei verschoben. Es ist am nützlichsten im Fall von Nested Loop Join und in gewissem Maße im Fall von Merge Join, da sie auf einem erneuten Scannen der inneren Beziehung beruhen. Der Materialise-Knoten ist nicht nur auf das Zwischenspeichern von Beziehungsergebnissen beschränkt, sondern kann auch Ergebnisse von jedem Knoten unten in der Planstruktur zwischenspeichern. TIPP:Falls die Join-Klausel „=“ ist und Nested-Loop-Join zwischen einer Relation gewählt wird, dann ist es wirklich wichtig zu untersuchen, ob eine effizientere Join-Methode wie Hash oder Merge-Join gewählt werden kann Tuning-Konfiguration (z. B. work_mem, aber nicht beschränkt auf ) oder durch Hinzufügen eines Index usw. Einige der Abfragen haben möglicherweise keine Join-Klausel, in diesem Fall ist Nested Loop Join auch die einzige Option zum Joinen. Z.B. Betrachten Sie die folgenden Abfragen gemäß den voreingestellten Daten: Der Join im obigen Beispiel ist nur ein kartesisches Produkt beider Tabellen. Dieser Algorithmus arbeitet in zwei Phasen: Der Join zwischen Relation A und B mit Bedingung A.ID =B.ID kann wie folgt dargestellt werden: Gemäß obiger voreingestellter Tabelle und Daten führt die folgende Abfrage zu einem Hash-Join, wie unten gezeigt: Hier wird die Hash-Tabelle auf der Tabelle blogtable2 erstellt, da dies die kleinere Tabelle ist, sodass der für die Hash-Tabelle erforderliche Mindestspeicher und die gesamte Hash-Tabelle in den Speicher passen. Merge Join ist ein Algorithmus, bei dem jeder Datensatz der äußeren Relation mit jedem Datensatz der inneren Relation abgeglichen wird, bis die Möglichkeit besteht, dass die Join-Klausel abgeglichen wird. Dieser Join-Algorithmus wird nur verwendet, wenn beide Relationen sortiert sind und der Join-Klausel-Operator „=“ ist. Der Join zwischen Relation A und B mit der Bedingung A.ID =B.ID kann wie folgt dargestellt werden: Die Beispielabfrage, die wie oben gezeigt zu einem Hash-Join führte, kann zu einem Merge-Join führen, wenn der Index für beide Tabellen erstellt wird. Dies liegt daran, dass die Tabellendaten aufgrund des Index, der eines der Hauptkriterien für die Merge-Join-Methode ist, in sortierter Reihenfolge abgerufen werden können: Also, wie wir sehen, verwenden beide Tabellen einen Index-Scan anstelle eines sequentiellen Scans, weshalb beide Tabellen sortierte Datensätze ausgeben. PostgreSQL unterstützt verschiedene Planer-bezogene Konfigurationen, die verwendet werden können, um den Abfrageoptimierer darauf hinzuweisen, eine bestimmte Art von Join-Methoden nicht auszuwählen. Wenn die vom Optimierer gewählte Join-Methode nicht optimal ist, können diese Konfigurationsparameter abgeschaltet werden, um den Abfrageoptimierer zu zwingen, eine andere Art von Join-Methode zu wählen. Alle diese Konfigurationsparameter sind standardmäßig aktiviert. Nachfolgend finden Sie die für Join-Methoden spezifischen Planer-Konfigurationsparameter. Es gibt viele tarifbezogene Konfigurationsparameter, die für verschiedene Zwecke verwendet werden. Beschränken Sie sich in diesem Blog auf Join-Methoden. Diese Parameter können von einer bestimmten Sitzung aus geändert werden. Falls wir also mit dem Plan aus einer bestimmten Sitzung experimentieren wollen, können diese Konfigurationsparameter manipuliert werden und andere Sitzungen funktionieren weiterhin so wie sie sind. Betrachten Sie nun die obigen Beispiele für Merge-Join und Hash-Join. Ohne einen Index hat der Abfrageoptimierer einen Hash-Join für die folgende Abfrage ausgewählt, wie unten gezeigt, aber nach der Verwendung der Konfiguration wechselt er auch ohne Index zum Merge-Join: Anfangs wird Hash Join gewählt, da Daten aus Tabellen nicht sortiert werden. Um den Merge-Join-Plan auszuwählen, müssen zuerst alle aus beiden Tabellen abgerufenen Datensätze sortiert und dann der Merge-Join angewendet werden. Die Kosten für das Sortieren werden also zusätzlich sein und somit werden die Gesamtkosten steigen. Möglicherweise sind in diesem Fall die Gesamtkosten (einschließlich erhöhter Kosten) höher als die Gesamtkosten von Hash Join, also wird Hash Join gewählt. Sobald der Konfigurationsparameter enable_hashjoin auf „off“ geändert wird, bedeutet dies, dass der Abfrageoptimierer die Kosten für den Hash-Join direkt als Deaktivierungskosten zuweist (=1,0e10, d. h. 10000000000,00). Die Kosten für einen möglichen Beitritt werden geringer sein. Dasselbe Abfrageergebnis in Merge Join, nachdem enable_hashjoin auf „off“ geändert wurde, da die Gesamtkosten für Merge Join selbst unter Berücksichtigung der Sortierkosten geringer sind als die Deaktivierungskosten. Betrachten Sie nun das folgende Beispiel: Wie wir oben sehen können, wird, obwohl der Nested-Loop-Join-bezogene Konfigurationsparameter auf „off“ geändert wurde, immer noch Nested-Loop-Join ausgewählt, da es keine alternative Möglichkeit gibt, eine andere Art von Join-Methode zu erhalten ausgewählt. Einfacher ausgedrückt, da Nested Loop Join der einzig mögliche Join ist, wird es immer der Gewinner sein, egal was es kostet (genauso wie ich früher beim 100-Meter-Rennen der Gewinner war, wenn ich alleine gelaufen bin … :-)). Beachten Sie auch den Kostenunterschied im ersten und zweiten Plan. Der erste Plan zeigt die tatsächlichen Kosten von Nested Loop Join, aber der zweite zeigt die Deaktivierungskosten desselben. Alle Arten von PostgreSQL-Join-Methoden sind nützlich und werden basierend auf der Art der Abfrage, Daten, Join-Klausel usw. ausgewählt. Falls die Abfrage nicht wie erwartet funktioniert, d. h. Join-Methoden nicht wie erwartet ausgewählt, kann der Benutzer mit verschiedenen verfügbaren Plankonfigurationsparametern herumspielen und sehen, ob etwas fehlt.For each tuple r in A
For each tuple s in B
If (r.ID < s.ID)
Emit output tuple (r,s)postgres=# explain select * from blogtable1 bt1, blogtable2 bt2 where bt1.id1 < bt2.id1;
QUERY PLAN
------------------------------------------------------------------------------
Nested Loop (cost=0.00..150162.50 rows=3333333 width=16)
Join Filter: (bt1.id1 < bt2.id1)
-> Seq Scan on blogtable1 bt1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 bt2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)
postgres=# explain select * from blogtable1, blogtable2;
QUERY PLAN
--------------------------------------------------------------------------
Nested Loop (cost=0.00..125162.50 rows=10000000 width=16)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(4 rows)Hash-Join
postgres=# explain select * from blogtable1 bt1, blogtable2 bt2 where bt1.id1 = bt2.id1;
QUERY PLAN
------------------------------------------------------------------------------
Hash Join (cost=27.50..220.00 rows=1000 width=16)
Hash Cond: (bt1.id1 = bt2.id1)
-> Seq Scan on blogtable1 bt1 (cost=0.00..145.00 rows=10000 width=8)
-> Hash (cost=15.00..15.00 rows=1000 width=8)
-> Seq Scan on blogtable2 bt2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows) Join zusammenführen
For each tuple r in A
For each tuple s in B
If (r.ID = s.ID)
Emit output tuple (r,s)
Break;
If (r.ID > s.ID)
Continue;
Else
Break;postgres=# create index idx1 on blogtable1(id1);
CREATE INDEX
postgres=# create index idx2 on blogtable2(id1);
CREATE INDEX
postgres=# explain select * from blogtable1 bt1, blogtable2 bt2 where bt1.id1 = bt2.id1;
QUERY PLAN
---------------------------------------------------------------------------------------
Merge Join (cost=0.56..90.36 rows=1000 width=16)
Merge Cond: (bt1.id1 = bt2.id1)
-> Index Scan using idx1 on blogtable1 bt1 (cost=0.29..318.29 rows=10000 width=8)
-> Index Scan using idx2 on blogtable2 bt2 (cost=0.28..43.27 rows=1000 width=8)
(4 rows)Konfiguration
postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 = blogtable2.id1;
QUERY PLAN
--------------------------------------------------------------------------
Hash Join (cost=27.50..220.00 rows=1000 width=16)
Hash Cond: (blogtable1.id1 = blogtable2.id1)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Hash (cost=15.00..15.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)
postgres=# set enable_hashjoin to off;
SET
postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 = blogtable2.id1;
QUERY PLAN
----------------------------------------------------------------------------
Merge Join (cost=874.21..894.21 rows=1000 width=16)
Merge Cond: (blogtable1.id1 = blogtable2.id1)
-> Sort (cost=809.39..834.39 rows=10000 width=8)
Sort Key: blogtable1.id1
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Sort (cost=64.83..67.33 rows=1000 width=8)
Sort Key: blogtable2.id1
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(8 rows)postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 < blogtable2.id1;
QUERY PLAN
--------------------------------------------------------------------------
Nested Loop (cost=0.00..150162.50 rows=3333333 width=16)
Join Filter: (blogtable1.id1 < blogtable2.id1)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)
postgres=# set enable_nestloop to off;
SET
postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 < blogtable2.id1;
QUERY PLAN
--------------------------------------------------------------------------
Nested Loop (cost=10000000000.00..10000150162.50 rows=3333333 width=16)
Join Filter: (blogtable1.id1 < blogtable2.id1)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)Fazit



