Wenn Sie ein Analysesystem für ein Unternehmen implementieren müssen, stellt sich häufig die Frage, wo die Daten gespeichert werden sollen. Es gibt nicht immer eine perfekte Option für alle Anforderungen und es hängt vom Budget, der Datenmenge und den Bedürfnissen des Unternehmens ab.
PostgreSQL ist als fortschrittlichste Open-Source-Datenbank so flexibel, dass sie als einfache relationale Datenbank, als Datenbank für Zeitreihendaten und sogar als effiziente, kostengünstige Data-Warehousing-Lösung dienen kann. Sie können es auch in mehrere Analysetools integrieren.
Wenn Sie nach einem weitgehend kompatiblen, kostengünstigen und leistungsstarken Data Warehouse suchen, könnte PostgreSQL die beste Datenbankoption sein, aber warum? In diesem Blog werden wir sehen, was ein Data Warehouse ist, warum es benötigt wird und warum PostgreSQL hier die beste Option sein könnte.
Was ist ein Data Warehouse
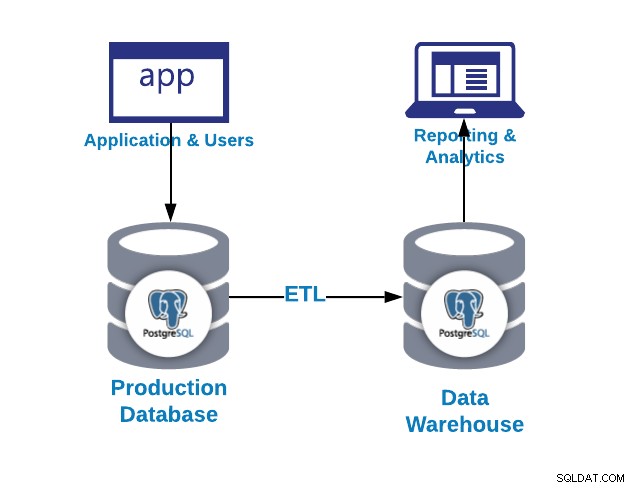
Ein Data Warehouse ist ein standardisiertes, konsistentes und integriertes System, das aktuelle oder historische Daten aus einer oder mehreren Quellen enthält, die für die Berichterstellung und Datenanalyse verwendet werden. Es gilt als eine Kernkomponente von Business Intelligence, d. h. der Strategie und Technologie, die von einem Unternehmen zum besseren Verständnis seines kommerziellen Kontexts verwendet werden.
Die erste Frage, die Sie sich vielleicht stellen, ist, warum brauche ich ein Data Warehouse?
- Integration:Integrieren/Zentralisieren von Daten aus mehreren Systemen/Datenbanken
- Standardisieren:Standardisieren Sie alle Daten im selben Format
- Analytics:Analysieren Sie Daten in einem historischen Kontext
Einige der Vorteile eines Data Warehouse können sein...
- Integrieren Sie Daten aus mehreren Quellen in eine einzige Datenbank
- Vermeiden Sie das Sperren oder Laden der Produktion aufgrund lang andauernder Abfragen
- Speichern Sie historische Informationen
- Restrukturieren Sie die Daten, um sie den Analyseanforderungen anzupassen
Wie wir im vorherigen Bild sehen konnten, können wir PostgreSQL sowohl für OLAP- als auch für OLTP-Vorschläge verwenden. Sehen wir uns den Unterschied an.
- OLTP:Online-Transaktionsverarbeitung. Im Allgemeinen hat es eine große Anzahl von kurzen Online-Transaktionen (INSERT, UPDATE, DELETE), die durch Benutzeraktivität generiert werden. Diese Systeme betonen eine sehr schnelle Abfrageverarbeitung und die Aufrechterhaltung der Datenintegrität in Multi-Access-Umgebungen. Hier wird die Effektivität an der Anzahl der Transaktionen pro Sekunde gemessen. OLTP-Datenbanken enthalten detaillierte und aktuelle Daten.
- OLAP:Online-Analyseverarbeitung. Im Allgemeinen hat es ein geringes Volumen an komplexen Transaktionen, die von großen Berichten generiert werden. Die Reaktionszeit ist ein Effektivitätsmaß. Diese Datenbanken speichern aggregierte historische Daten in mehrdimensionalen Schemata. OLAP-Datenbanken werden verwendet, um mehrdimensionale Daten aus mehreren Quellen und Perspektiven zu analysieren.
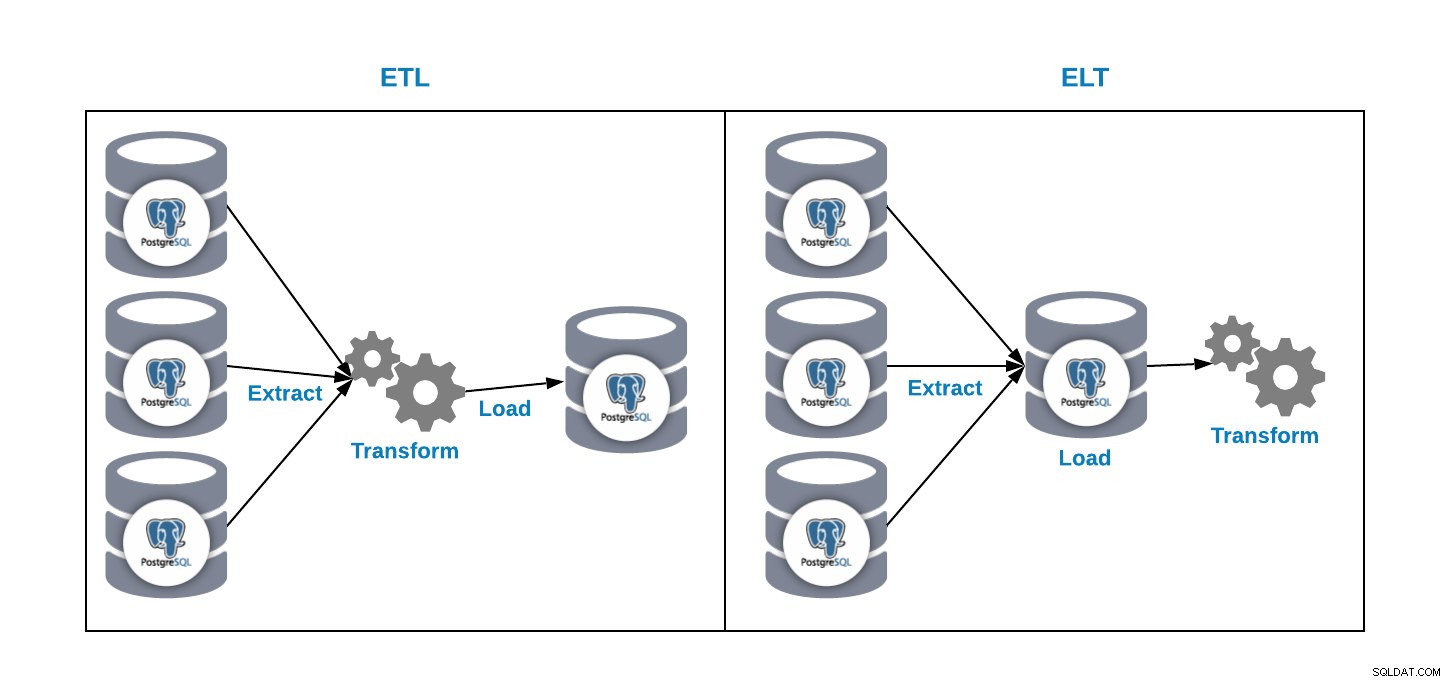
Wir haben zwei Möglichkeiten, Daten in unsere Analysedatenbank zu laden:
- ETL:Extrahieren, transformieren und laden. Auf diese Weise generieren wir unser Data Warehouse. Extrahieren Sie zuerst die Daten aus der Produktionsdatenbank, transformieren Sie die Daten gemäß unseren Anforderungen und laden Sie die Daten dann in unser Data Warehouse.
- ELT:Extrahieren, laden und transformieren. Extrahieren Sie zuerst die Daten aus der Produktionsdatenbank, laden Sie sie in die Datenbank und transformieren Sie dann die Daten. Dieser Weg wird Data Lake genannt und ist ein neues Konzept zur Verwaltung unserer Big Data.
Und nun die zweite Frage:Warum sollte ich PostgreSQL für mein Data Warehouse verwenden?
Vorteile von PostgreSQL als Data Warehouse
Sehen wir uns einige der Vorteile der Verwendung von PostgreSQL als Data Warehouse an...
- Kosten:Wenn Sie eine On-Prem-Umgebung verwenden, betragen die Kosten für das Produkt selbst 0 US-Dollar, selbst wenn Sie ein Produkt in der Cloud verwenden, sind die Kosten für ein PostgreSQL-basiertes Produkt wahrscheinlich geringer als der Rest der Produkte.
- Skalieren:Sie können es auf einfache Weise skalieren, indem Sie so viele Replikationsknoten hinzufügen, wie Sie möchten.
- Leistung:Bei korrekter Konfiguration hat PostgreSQL eine wirklich gute Leistung in verschiedenen Szenarien.
- Kompatibilität:Sie können PostgreSQL mit externen Tools oder Anwendungen für Data Mining, OLAP und Reporting integrieren.
- Erweiterbarkeit:PostgreSQL hat benutzerdefinierte Datentypen und Funktionen.
Es gibt auch einige PostgreSQL-Funktionen, die uns bei der Verwaltung unserer Data-Warehouse-Informationen helfen können...
- Temporäre Tabellen:Es handelt sich um eine kurzlebige Tabelle, die für die Dauer einer Datenbanksitzung existiert. PostgreSQL löscht die temporären Tabellen automatisch am Ende einer Sitzung oder einer Transaktion.
- Gespeicherte Prozeduren:Sie können damit Prozeduren erstellen oder in mehreren Sprachen funktionieren (PL/pgSQL, PL/Perl, PL/Python usw.).
- Partitionierung:Dies ist wirklich nützlich für die Datenbankwartung, Abfragen mit Partitionsschlüssel und INSERT-Leistung.
- Materialisierte Ansicht:Die Abfrageergebnisse werden als Tabelle angezeigt.
- Tablespaces:Sie können den Datenspeicherort auf eine andere Festplatte ändern. Auf diese Weise haben Sie einen parallelisierten Festplattenzugriff.
- PITR-kompatibel:Sie können Sicherungen Point-in-Time-Recovery-kompatibel erstellen, sodass Sie im Falle eines Ausfalls den Datenbankzustand zu einem bestimmten Zeitpunkt wiederherstellen können.
- Riesige Community:Und nicht zuletzt hat PostgreSQL eine riesige Community, in der Sie Unterstützung zu vielen verschiedenen Themen finden können.
Konfigurieren von PostgreSQL für die Verwendung von Data Warehouse
Es gibt keine beste Konfiguration, die in allen Fällen und in allen Datenbanktechnologien verwendet werden kann. Dies hängt von vielen Faktoren wie Hardware, Nutzung und Systemanforderungen ab. Im Folgenden finden Sie einige Tipps, wie Sie Ihre PostgreSQL-Datenbank so konfigurieren, dass sie richtig als Data Warehouse funktioniert.
Speicherbasiert
- max_connections:Als Data-Warehouse-Datenbank benötigen Sie keine große Anzahl von Verbindungen, da diese für Berichterstellungs- und Analysearbeiten verwendet werden, sodass Sie die maximale Verbindungsanzahl mit diesem Parameter begrenzen können.
- shared_buffers:Legt die Speichermenge fest, die der Datenbankserver für gemeinsam genutzte Speicherpuffer verwendet. Ein vernünftiger Wert kann zwischen 15 % und 25 % des RAM-Speichers liegen.
- Effective_cache_size:Dieser Wert wird vom Abfrageplaner verwendet, um Pläne zu berücksichtigen, die möglicherweise in den Speicher passen oder nicht. Dies wird in den Kostenschätzungen der Verwendung eines Index berücksichtigt; Ein hoher Wert macht es wahrscheinlicher, dass Index-Scans verwendet werden, und ein niedriger Wert macht es wahrscheinlicher, dass sequenzielle Scans verwendet werden. Ein sinnvoller Wert wären etwa 75 % des RAM-Speichers.
- Arbeitsspeicher:Gibt die Menge an Arbeitsspeicher an, die von den internen Operationen von ORDER BY, DISTINCT, JOIN und Hash-Tabellen verwendet wird, bevor in die temporären Dateien auf der Festplatte geschrieben wird. Bei der Konfiguration dieses Werts müssen wir berücksichtigen, dass mehrere Sitzungen diese Operationen gleichzeitig ausführen und jede Operation so viel Speicher verwenden darf, wie durch diesen Wert angegeben, bevor sie beginnt, Daten in temporäre Dateien zu schreiben. Ein vernünftiger Wert kann etwa 2 % des RAM-Speichers betragen.
- maintenance_work_mem:Gibt die maximale Speichermenge an, die von Wartungsvorgängen verwendet wird, wie z. B. VACUUM, CREATE INDEX und ALTER TABLE ADD FOREIGN KEY. Ein vernünftiger Wert kann etwa 15 % des RAM-Speichers betragen.
CPU-basiert
- Max_worker_processes:Legt die maximale Anzahl von Hintergrundprozessen fest, die das System unterstützen kann. Ein sinnvoller Wert kann die Anzahl der CPUs sein.
- Max_parallel_workers_per_gather:Legt die maximale Anzahl von Workern fest, die von einem einzelnen Gather- oder Gather-Merge-Knoten gestartet werden können. Ein vernünftiger Wert kann 50 % der CPU-Anzahl sein.
- Max_parallel_workers:Legt die maximale Anzahl von Workern fest, die das System für parallele Abfragen unterstützen kann. Ein sinnvoller Wert kann die Anzahl der CPUs sein.
Da sich die in unser Data Warehouse geladenen Daten nicht ändern sollen, können wir das Autovacuum auch ausschalten, um eine zusätzliche Belastung Ihrer PostgreSQL-Datenbank zu vermeiden. Die Vakuum- und Analyseprozesse können Teil des Stapelladeprozesses sein.
Schlussfolgerung
Wenn Sie nach einem weitgehend kompatiblen, kostengünstigen und leistungsstarken Data Warehouse suchen, sollten Sie PostgreSQL unbedingt als Option für Ihre Data Warehouse-Datenbank in Betracht ziehen. PostgreSQL hat viele Vorteile und Funktionen, die nützlich sind, um unser Data Warehouse zu verwalten, wie Partitionierung oder gespeicherte Prozeduren und noch mehr.