In der Welt der Informationstechnologie ist Automatisierung für die meisten von uns nichts Neues. Tatsächlich verwenden die meisten Organisationen es für verschiedene Zwecke, abhängig von ihrer Arbeitsart und ihren Zielen. Beispielsweise verwenden Datenanalysten die Automatisierung zum Generieren von Berichten, Systemadministratoren verwenden die Automatisierung für ihre sich wiederholenden Aufgaben wie das Bereinigen von Festplattenspeicher und Entwickler verwenden die Automatisierung zur Automatisierung ihres Entwicklungsprozesses.
Heutzutage sind dank der DevOps-Ära viele Automatisierungstools für die IT verfügbar und wählbar. Welches ist das beste Werkzeug? Die Antwort ist ein vorhersehbares „es kommt darauf an“, da es davon abhängt, was wir erreichen wollen, sowie von der Einrichtung unserer Umgebung. Einige der Automatisierungstools sind Terraform, Bolt, Chef, SaltStack und ein sehr trendiges ist Ansible. Ansible ist eine agentenlose Open-Source-IT-Engine, die die Anwendungsbereitstellung, das Konfigurationsmanagement und die IT-Orchestrierung automatisieren kann. Ansible wurde 2012 gegründet und wurde in der beliebtesten Sprache Python geschrieben. Es verwendet ein Playbook, um die gesamte Automatisierung zu implementieren, wobei alle Konfigurationen in einer für Menschen lesbaren Sprache, YAML, geschrieben sind.
Im heutigen Beitrag werden wir lernen, wie man Ansible für die Bereitstellung von Postgresql-Datenbanken verwendet.
Was macht Ansible so besonders?
Der Grund, warum Ansible hauptsächlich wegen seiner Eigenschaften verwendet wird. Diese Funktionen sind:
-
Alles kann automatisiert werden, indem die einfache menschenlesbare Sprache YAML verwendet wird
-
Kein Agent wird auf dem Remote-Rechner installiert (architektur ohne Agent)
-
Die Konfiguration wird von Ihrem lokalen Rechner auf den Server von Ihrem lokalen Rechner übertragen (Push-Modell)
-
Entwickelt unter Verwendung von Python (eine der derzeit verwendeten gängigen Sprachen) und es können viele Bibliotheken ausgewählt werden
-
Sammlung von Ansible-Modulen, die sorgfältig vom Red Had Engineering Team ausgewählt wurden
Die Funktionsweise von Ansible
Bevor Ansible operative Aufgaben auf den Remote-Hosts ausführen kann, müssen wir es auf einem Host installieren, der zum Controller-Knoten wird. In diesem Controller-Knoten orchestrieren wir alle Aufgaben, die wir in den Remote-Hosts ausführen möchten, die auch als verwaltete Knoten bekannt sind.
Der Controller-Knoten muss über das Inventar der verwalteten Knoten und die Ansible-Software verfügen, um ihn zu verwalten. Die erforderlichen Daten, die von Ansible verwendet werden sollen, wie der Hostname oder die IP-Adresse des verwalteten Knotens, werden in dieses Inventar aufgenommen. Ohne eine ordnungsgemäße Bestandsaufnahme könnte Ansible die Automatisierung nicht korrekt durchführen. Weitere Informationen zum Inventar finden Sie hier.
Ansible ist agentenlos und verwendet SSH, um die Änderungen zu pushen, was bedeutet, dass wir Ansible nicht auf allen Knoten installieren müssen, aber auf allen verwalteten Knoten müssen Python und alle erforderlichen Python-Bibliotheken installiert sein. Sowohl der Controller-Knoten als auch die verwalteten Knoten müssen als kennwortlos festgelegt werden. Es ist erwähnenswert, dass die Verbindung zwischen allen Controller-Knoten und verwalteten Knoten gut ist und ordnungsgemäß getestet wurde.
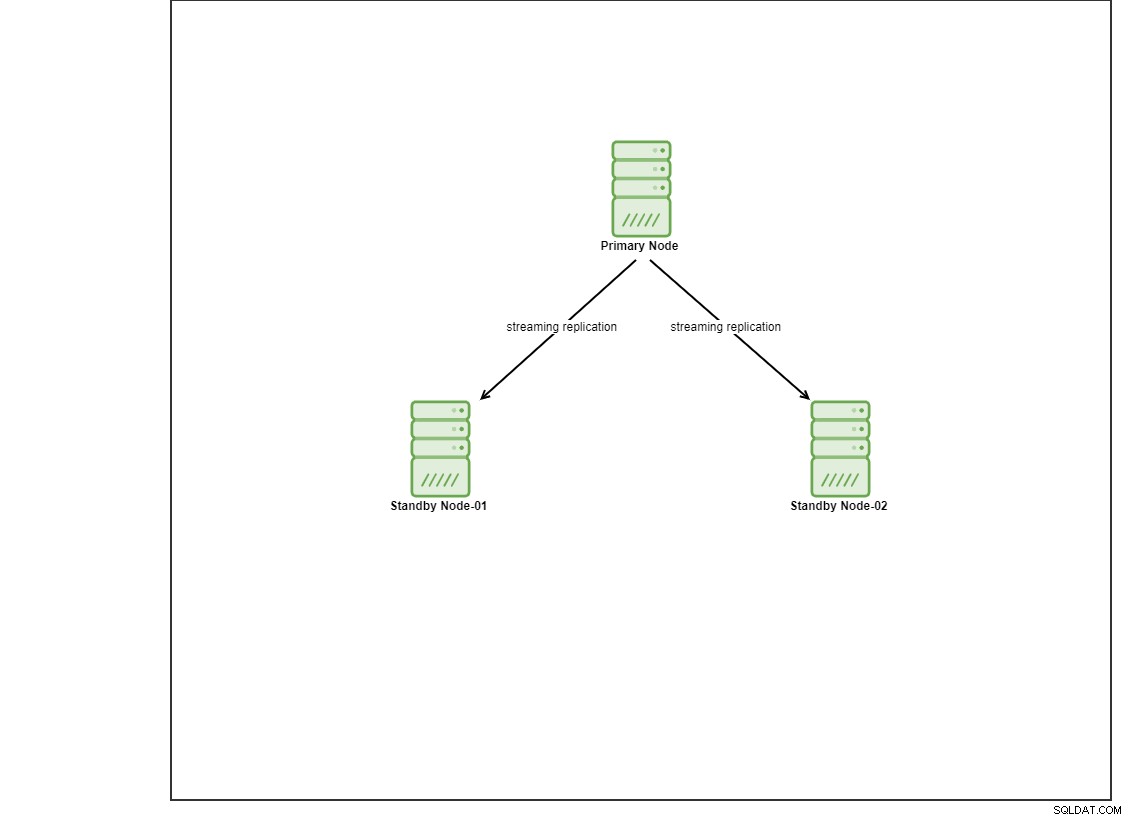
Für diese Demo habe ich 4 Centos 8-VMs mithilfe von Vagrant bereitgestellt. Einer fungiert als Controller-Knoten und die anderen 2 VMs fungieren als bereitzustellende Datenbankknoten. Wir gehen in diesem Blogbeitrag nicht näher auf die Installation von Ansible ein, aber falls Sie die Anleitung sehen möchten, können Sie diesen Link besuchen. Beachten Sie, dass wir 3 Knoten verwenden, um eine Streaming-Replikationstopologie einzurichten, mit einem primären und 2 Standby-Knoten. Heutzutage befinden sich viele Produktionsdatenbanken in einer Konfiguration mit hoher Verfügbarkeit, und eine Konfiguration mit 3 Knoten ist üblich.
PostgreSQL installieren
Es gibt mehrere Möglichkeiten, PostgreSQL mit Ansible zu installieren. Heute werde ich Ansible Roles verwenden, um diesen Zweck zu erreichen. Kurz gesagt, Ansible Roles ist eine Reihe von Aufgaben zum Konfigurieren eines Hosts für einen bestimmten Zweck, z. B. das Konfigurieren eines Dienstes. Ansible-Rollen werden mithilfe von YAML-Dateien mit einer vordefinierten Verzeichnisstruktur definiert, die vom Ansible Galaxy-Portal heruntergeladen werden können.
Ansible Galaxy hingegen ist ein Repository für Ansible-Rollen, die direkt in Ihre Playbooks eingefügt werden können, um Ihre Automatisierungsprojekte zu optimieren.
Für diese Demo habe ich die Rollen ausgewählt, die von dudefellah gepflegt wurden. Damit wir diese Rolle nutzen können, müssen wir sie herunterladen und auf dem Controller-Knoten installieren. Die Aufgabe ist ziemlich einfach und kann durch Ausführen des folgenden Befehls erledigt werden, vorausgesetzt, Ansible wurde auf Ihrem Controller-Knoten installiert:
$ ansible-galaxy install dudefellah.postgresqlSie sollten das folgende Ergebnis sehen, sobald die Rolle erfolgreich in Ihrem Controller-Knoten installiert wurde:
$ ansible-galaxy install dudefellah.postgresql
- downloading role 'postgresql', owned by dudefellah
- downloading role from https://github.com/dudefellah/ansible-role-postgresql/archive/0.1.0.tar.gz
- extracting dudefellah.postgresql to /home/ansible/.ansible/roles/dudefellah.postgresql
- dudefellah.postgresql (0.1.0) was installed successfully
Damit wir PostgreSQL mit dieser Rolle installieren können, müssen einige Schritte ausgeführt werden. Hier kommt das Ansible Playbook. In Ansible Playbook können wir Ansible-Code oder eine Sammlung von Skripts schreiben, die wir auf den verwalteten Knoten ausführen möchten. Ansible Playbook verwendet YAML und besteht aus einem oder mehreren Plays, die in einer bestimmten Reihenfolge ausgeführt werden. Sie können Hosts sowie eine Reihe von Aufgaben definieren, die Sie auf diesen zugewiesenen Hosts oder verwalteten Knoten ausführen möchten.
Alle Aufgaben werden unter dem angemeldeten Ansible-Benutzer ausgeführt. Damit wir die Aufgaben mit einem anderen Benutzer einschließlich „root“ ausführen können, können wir dies verwenden. Werfen wir einen Blick auf pg-play.yml unten:
$ cat pg-play.yml
- hosts: pgcluster
become: yes
vars_files:
- ./custom_var.yml
roles:
- role: dudefellah.postgresql
postgresql_version: 13Wie Sie sehen können, habe ich die Hosts als pgcluster definiert und verwende Bere, damit Ansible die Aufgaben mit dem sudo-Privileg ausführt. User vagrant ist bereits in der sudoer-Gruppe. Ich habe auch die Rolle definiert, die ich dudefellah.postgresql installiert habe. pgcluster wurde in der von mir erstellten hosts-Datei definiert. Falls Sie sich fragen, wie es aussieht, können Sie unten nachsehen:
$ cat pghost
[pgcluster]
10.10.10.11 ansible_user=ansible
10.10.10.12 ansible_user=ansible
10.10.10.13 ansible_user=ansibleZusätzlich dazu habe ich eine weitere benutzerdefinierte Datei (custom_var.yml) erstellt, in der ich alle Konfigurationen und Einstellungen für PostgreSQL enthalten habe, die ich implementieren möchte. Die Details für die benutzerdefinierte Datei lauten wie folgt:
$ cat custom_var.yml
postgresql_conf:
listen_addresses: "*"
wal_level: replica
max_wal_senders: 10
max_replication_slots: 10
hot_standby: on
postgresql_users:
- name: replication
password: example@sqldat.com
privs: "ALL"
role_attr_flags: "SUPERUSER,REPLICATION"
postgresql_pg_hba_conf:
- { type: "local", database: "all", user: "all", method: "trust" }
- { type: "host", database: "all", user: "all", address: "0.0.0.0/0", method: "md5" }
- { type: "host", database: "replication", user: "replication", address: "0.0.0.0/0", method: "md5" }
- { type: "host", database: "replication", user: "replication", address: "127.0.0.1/32", method: "md5" }Um die Installation auszuführen, müssen wir lediglich den folgenden Befehl ausführen. Sie können den ansible-playbook-Befehl nicht ohne die erstellte Playbook-Datei ausführen (in meinem Fall ist es pg-play.yml).
$ ansible-playbook pg-play.yml -i pghostNachdem ich diesen Befehl ausgeführt habe, werden einige von der Rolle definierte Aufgaben ausgeführt und diese Meldung angezeigt, wenn der Befehl erfolgreich ausgeführt wurde:
PLAY [pgcluster] *************************************************************************************
TASK [Gathering Facts] *******************************************************************************
ok: [10.10.10.11]
ok: [10.10.10.12]
TASK [dudefellah.postgresql : Load platform variables] ***********************************************
ok: [10.10.10.11]
ok: [10.10.10.12]
TASK [dudefellah.postgresql : Set up role-specific facts based on some inputs and the OS distribution] ***
included: /home/ansible/.ansible/roles/dudefellah.postgresql/tasks/role_facts.yml for 10.10.10.11, 10.10.10.12Sobald das Ansible die Aufgaben erledigt hat, habe ich mich beim Slave (n2) angemeldet, den PostgreSQL-Dienst gestoppt und den Inhalt des Datenverzeichnisses (/var/lib/pgsql/13/data/) entfernt. und führen Sie den folgenden Befehl aus, um die Sicherungsaufgabe zu starten:
$ sudo -u postgres pg_basebackup -h 10.10.10.11 -D /var/lib/pgsql/13/data/ -U replication -P -v -R -X stream -C -S slaveslot1
10.10.10.11 is the IP address of the master. We can now verify the replication slot by logging into the master:
$ sudo -u postgres psql
postgres=# SELECT * FROM pg_replication_slots;
-[ RECORD 1 ]-------+-----------
slot_name | slaveslot1
plugin |
slot_type | physical
datoid |
database |
temporary | f
active | t
active_pid | 63854
xmin |
catalog_xmin |
restart_lsn | 0/3000148
confirmed_flush_lsn |
wal_status | reserved
safe_wal_size |Wir können den Status der Replikation auch im Standby-Modus mit dem folgenden Befehl überprüfen, nachdem wir den PostgreSQL-Dienst wieder gestartet haben:
$ sudo -u postgres psql
postgres=# SELECT * FROM pg_stat_wal_receiver;
-[ RECORD 1 ]---------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
pid | 229552
status | streaming
receive_start_lsn | 0/3000000
receive_start_tli | 1
written_lsn | 0/3000148
flushed_lsn | 0/3000148
received_tli | 1
last_msg_send_time | 2021-05-09 14:10:00.29382+00
last_msg_receipt_time | 2021-05-09 14:09:59.954983+00
latest_end_lsn | 0/3000148
latest_end_time | 2021-05-09 13:53:28.209279+00
slot_name | slaveslot1
sender_host | 10.10.10.11
sender_port | 5432
conninfo | user=replication password=******** channel_binding=prefer dbname=replication host=10.10.10.11 port=5432 fallback_application_name=walreceiver sslmode=prefer sslcompression=0 ssl_min_protocol_version=TLSv1.2 gssencmode=prefer krbsrvname=postgres target_session_attrs=anyWie Sie sehen können, müssen viele Arbeiten durchgeführt werden, damit wir die Replikation für PostgreSQL einrichten können, obwohl wir einige der Aufgaben automatisiert haben. Sehen wir uns an, wie dies mit ClusterControl erreicht werden kann.
PostgreSQL-Bereitstellung mit ClusterControl-GUI
Da wir nun wissen, wie PostgreSQL mithilfe von Ansible bereitgestellt wird, sehen wir uns an, wie wir mithilfe von ClusterControl bereitstellen können. ClusterControl ist eine Verwaltungs- und Automatisierungssoftware für Datenbankcluster, darunter MySQL, MariaDB, MongoDB sowie TimescaleDB. Es hilft bei der Bereitstellung, Überwachung, Verwaltung und Skalierung Ihres Datenbankclusters. Es gibt zwei Möglichkeiten, die Datenbank bereitzustellen. In diesem Blogbeitrag zeigen wir Ihnen, wie Sie sie mithilfe der grafischen Benutzeroberfläche (GUI) bereitstellen, vorausgesetzt, Sie haben ClusterControl bereits in Ihrer Umgebung installiert.
Der erste Schritt besteht darin, sich bei Ihrem ClusterControl anzumelden und auf Deploy:
zu klicken
Der folgende Screenshot zeigt den nächsten Schritt der Bereitstellung , wählen Sie die Registerkarte PostgreSQL, um fortzufahren:
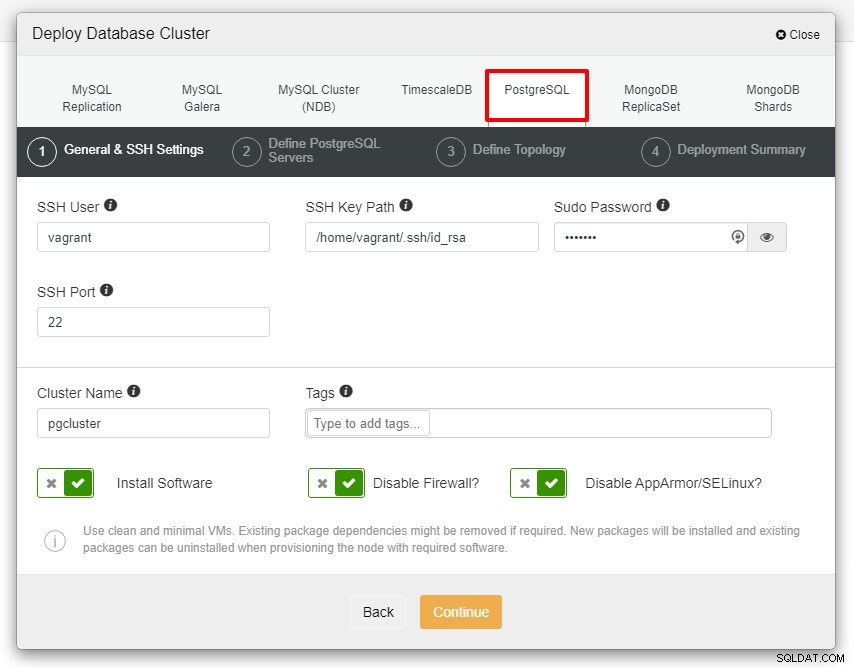
Bevor wir weitermachen, möchte ich Sie daran erinnern, dass die Verbindung zwischen dem ClusterControl-Knoten und den Datenbankknoten passwortlos sein muss. Vor der Bereitstellung müssen wir lediglich das ssh-keygen vom ClusterControl-Knoten generieren und es dann auf alle Knoten kopieren. Füllen Sie die Eingabe für den SSH-Benutzer, das Sudo-Passwort sowie den Clusternamen gemäß Ihren Anforderungen aus und klicken Sie auf Weiter.
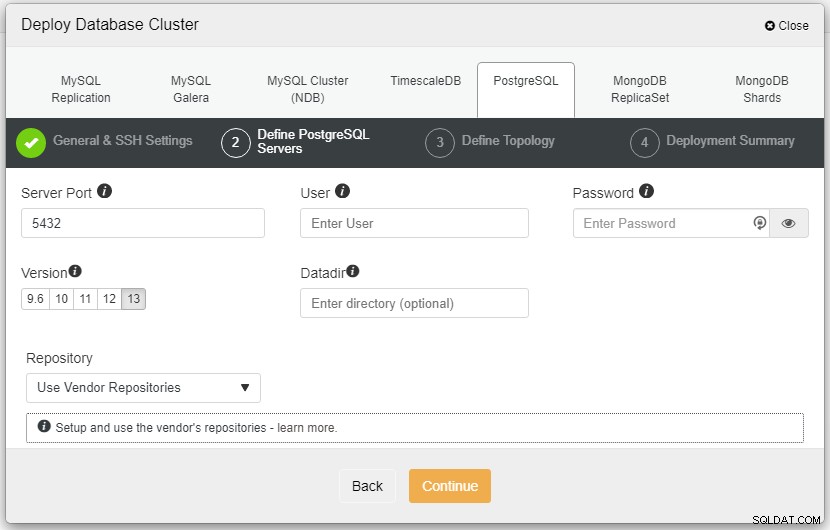
Im obigen Screenshot müssen Sie den Serverport (falls Sie andere verwenden möchten), den Benutzer, den Sie verwenden möchten, sowie das Passwort und die gewünschte Version definieren zu installieren.
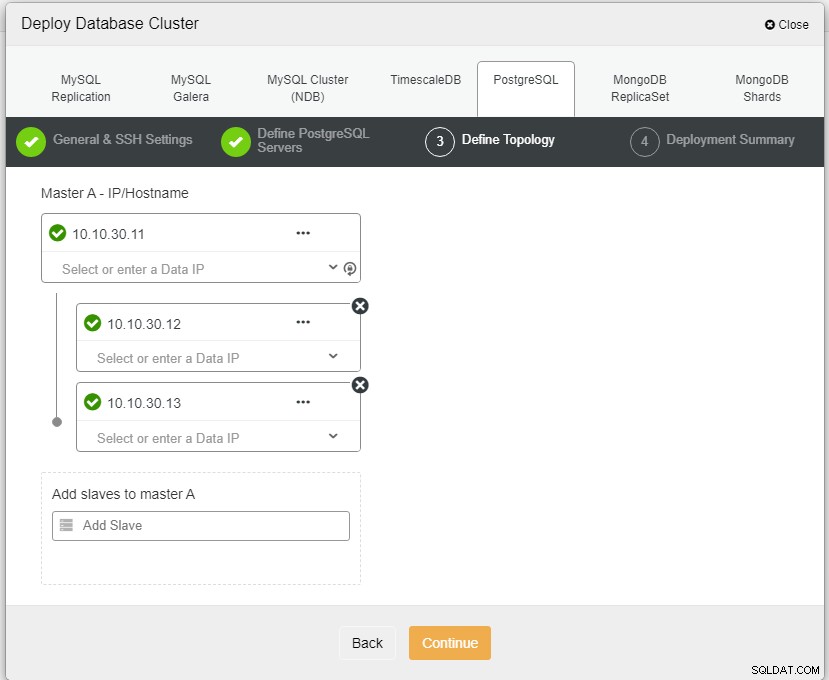
Hier müssen wir die Server entweder über den Hostnamen oder die IP-Adresse definieren, also in diesem Fall 1 Master und 2 Slaves. Der letzte Schritt besteht darin, den Replikationsmodus für unseren Cluster auszuwählen.
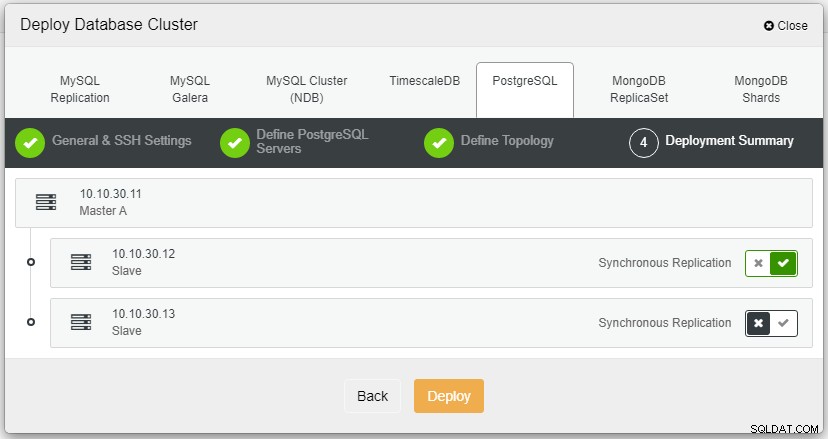
Nachdem Sie auf "Bereitstellen" geklickt haben, beginnt der Bereitstellungsprozess und wir können den Fortschritt auf der Registerkarte "Aktivität" überwachen.
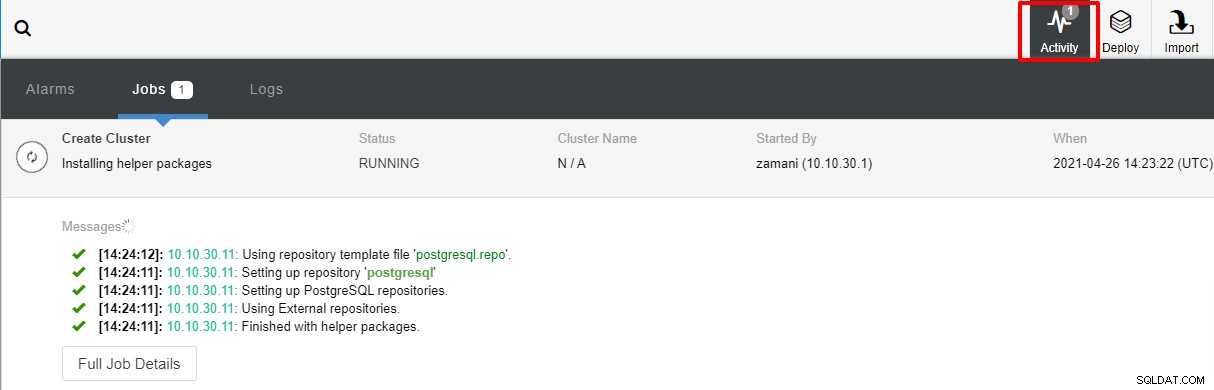
Die Bereitstellung dauert normalerweise ein paar Minuten, die Leistung hängt hauptsächlich vom Netzwerk und den Spezifikationen des Servers ab.

Nun, da wir PostgreSQL mit ClusterControl installiert haben.
PostgreSQL-Bereitstellung mit ClusterControl-CLI
Die andere alternative Methode zur Bereitstellung von PostgreSQL ist die Verwendung der CLI. Vorausgesetzt, wir haben die passwortlose Verbindung bereits konfiguriert, können wir einfach den folgenden Befehl ausführen und beenden.
$ s9s cluster --create --cluster-type=postgresql --nodes="10.10.50.11?master;10.10.50.12?slave;10.10.50.13?slave" --provider-version=13 --db-admin="postgres" --db-admin-passwd="example@sqldat.com$$W0rd" --cluster-name=PGCluster --os-user=root --os-key-file=/root/.ssh/id_rsa --logSie sollten die folgende Meldung sehen, sobald der Vorgang erfolgreich abgeschlossen wurde und Sie sich zur Überprüfung beim ClusterControl-Web anmelden können:
...
Saving cluster configuration.
Directory is '/etc/cmon.d'.
Filename is 'cmon_1.cnf'.
Configuration written to 'cmon_1.cnf'.
Sending SIGHUP to the controller process.
Waiting until the initial cluster starts up.
Cluster 1 is running.
Registering the cluster on the web UI.
Waiting until the initial cluster starts up.
Cluster 1 is running.
Generated & set RPC authentication token.Fazit
Wie Sie sehen, gibt es mehrere Möglichkeiten, PostgreSQL bereitzustellen. In diesem Blogbeitrag haben wir gelernt, wie man es mithilfe von Ansible und unserem ClusterControl bereitstellt. Beide Wege sind einfach zu befolgen und können mit einer minimalen Lernkurve erreicht werden. Mit ClusterControl kann das Streaming-Replikations-Setup mit HAProxy, VIP und PGBouncer ergänzt werden, um Verbindungs-Failover, virtuelle IP und Verbindungs-Pooling zum Setup hinzuzufügen.
Beachten Sie, dass die Bereitstellung nur ein Aspekt einer Produktionsdatenbankumgebung ist. Es ist unerlässlich, es am Laufen zu halten, Failover zu automatisieren, defekte Knoten wiederherzustellen und andere Aspekte wie Überwachung, Warnungen und Backups zu berücksichtigen.
Hoffentlich wird dieser Blogbeitrag einigen von Ihnen zugutekommen und eine Vorstellung davon vermitteln, wie PostgreSQL-Bereitstellungen automatisiert werden können.