Puppet ist eine Open-Source-Software für die Konfigurationsverwaltung und -bereitstellung. Es wurde 2005 gegründet, ist plattformübergreifend und hat sogar eine eigene deklarative Sprache für die Konfiguration.

Die Aufgaben im Zusammenhang mit der Verwaltung und Wartung von PostgreSQL (oder eigentlich anderer Software) besteht aus täglichen, sich wiederholenden Prozessen, die überwacht werden müssen. Dies gilt sogar für solche Aufgaben, die von Skripten oder Befehlen über ein Planungstool ausgeführt werden. Die Komplexität dieser Aufgaben nimmt exponentiell zu, wenn sie auf einer riesigen Infrastruktur ausgeführt werden. Die Verwendung von Puppet für diese Art von Aufgaben kann jedoch häufig diese Art von großen Problemen lösen, da Puppet die Ausführung dieser Vorgänge auf sehr agile Weise zentralisiert und automatisiert. P>
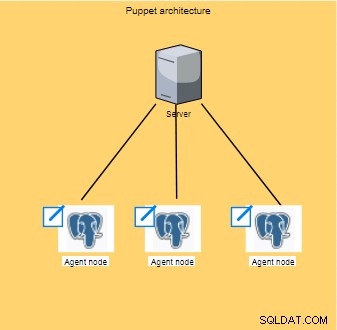
Puppet arbeitet innerhalb der Architektur auf der Client/Server-Ebene, wo die Konfiguration durchgeführt wird; diese Operationen werden dann verbreitet und auf allen Clients (auch bekannt als Knoten) ausgeführt.
Der Knoten des Agenten, der normalerweise alle 30 Minuten ausgeführt wird, sammelt eine Reihe von Informationen (Prozessortyp, Architektur, IP-Adresse usw.), die auch als Fakten bezeichnet werden, und sendet die Informationen dann an die master, der auf eine Antwort wartet, um zu sehen, ob neue Konfigurationen anzuwenden sind.
Diese Fakten ermöglichen es dem Master, die gleiche Konfiguration für jeden Knoten anzupassen.
Puppet ist, vereinfacht gesagt, eines der wichtigsten DevOps-Tools heute verfügbar. In diesem Blog werden wir uns Folgendes ansehen...
- Der Anwendungsfall für Puppet &PostgreSQL
- Puppet installieren
- Puppet konfigurieren und programmieren
- Puppet für PostgreSQL konfigurieren
Die unten beschriebene Installation und Einrichtung von Puppet (Version 5.3.10) wurde auf einer Reihe von Hosts durchgeführt, die CentOS 7.0 als Betriebssystem verwenden.
Der Anwendungsfall für Puppet &PostgreSQL
Angenommen, es gibt ein Problem in Ihrer Firewall auf den Computern, die alle Ihre PostgreSQL-Server hosten, dann müssten Sie alle ausgehenden Verbindungen zu PostgreSQL ablehnen, und zwar so schnell wie möglich.
P>
Puppet ist das perfekte Werkzeug für diese Situation, besonders weil es auf Geschwindigkeit und Effizienz ankommt essentiell. Wir sprechen über dieses Beispiel, das im Abschnitt „Konfigurieren von Puppet für PostgreSQL“ vorgestellt wird, indem wir den Parameter listen_addresses verwalten.
Puppet installieren
Es gibt eine Reihe allgemeiner Schritte, die entweder auf Master- oder Agent-Hosts ausgeführt werden müssen:
Schritt Eins
Aktualisierung der Datei /etc/hosts mit Hostnamen und deren IP-Adresse
192.168.1.85 agent agent.severalnines.com
192.168.1.87 master master.severalnines.com puppetSchritt Zwei
Hinzufügen der Puppet-Repositories zum System
$ sudo rpm –Uvh https://yum.puppetlabs.com/puppet5/el/7/x86_64/puppet5-release-5.0.0-1-el7.noarch.rpmFür andere Betriebssysteme oder CentOS-Versionen finden Sie das am besten geeignete Repository in Puppet, Inc. Yum Repositories.
Schritt Drei
Konfiguration des NTP (Network Time Protocol)-Servers
$ sudo yum -y install chronySchritt Vier
Der Chrony wird verwendet, um die Systemuhr von verschiedenen NTP-Servern zu synchronisieren und hält so die Zeit zwischen Master- und Agent-Server synchronisiert.
Sobald Chrony installiert ist, muss es aktiviert und neu gestartet werden:
$ sudo systemctl enable chronyd.service
$ sudo systemctl restart chronyd.serviceSchritt Fünf
Deaktivieren Sie den SELinux-Parameter
Auf der Datei /etc/sysconfig/selinux muss der Parameter SELINUX (Security-Enhanced Linux) deaktiviert werden, um den Zugriff nicht auf beiden Hosts einzuschränken.
SELINUX=disabledSchritt Sechs
Vor der Puppet-Installation (entweder Master oder Agent) muss die Firewall in diesen Hosts entsprechend definiert werden:
$ sudo firewall-cmd -–add-service=ntp -–permanent
$ sudo firewall-cmd –-reload Den Puppet Master installieren
Sobald das Paket-Repository puppet5-release-5.0.0-1-el7.noarch.rpm dem System hinzugefügt wurde, kann die Installation von Puppetserver durchgeführt werden:
$ sudo yum install -y puppetserverDer Parameter für die maximale Speicherzuweisung ist eine wichtige Einstellung, um die Datei /etc/sysconfig/puppetserver auf 2 GB (oder auf 1 GB, wenn der Dienst nicht startet) zu aktualisieren:
JAVA_ARGS="-Xms2g –Xmx2g "In der Konfigurationsdatei /etc/puppetlabs/puppet/puppet.conf muss die folgende Parametrisierung hinzugefügt werden:
[master]
dns_alt_names=master.severalnines.com,puppet
[main]
certname = master.severalnines.com
server = master.severalnines.com
environment = production
runinterval = 1hDer Puppetserver-Dienst verwendet den Port 8140, um auf die Knotenanfragen zu hören, daher muss sichergestellt werden, dass dieser Port aktiviert wird:
$ sudo firewall-cmd --add-port=8140/tcp --permanent
$ sudo firewall-cmd --reloadSobald alle Einstellungen in Puppet Master vorgenommen wurden, ist es an der Zeit, diesen Dienst zu starten:
$ sudo systemctl start puppetserver
$ sudo systemctl enable puppetserver
Installieren des Puppet-Agenten
Der Puppet-Agent im Paket-Repository puppet5-release-5.0.0-1-el7.noarch.rpm wird ebenfalls dem System hinzugefügt, die Installation des Puppet-Agent kann sofort durchgeführt werden:
$ sudo yum install -y puppet-agentDie Puppet-Agent-Konfigurationsdatei /etc/puppetlabs/puppet/puppet.conf muss ebenfalls aktualisiert werden, indem der folgende Parameter hinzugefügt wird:
[main]
certname = agent.severalnines.com
server = master.severalnines.com
environment = production
runinterval = 1hDer nächste Schritt besteht darin, den Agent-Knoten auf dem Master-Host zu registrieren, indem Sie den folgenden Befehl ausführen:
$ sudo /opt/puppetlabs/bin/puppet resource service puppet ensure=running enable=true
service { ‘puppet’:
ensure => ‘running’,
enable => ‘true’
}Zu diesem Zeitpunkt gibt es auf dem Master-Host eine ausstehende Anfrage vom Puppet-Agenten zum Signieren eines Zertifikats:

Das muss durch Ausführen eines der folgenden Befehle signiert werden:
$ sudo /opt/puppetlabs/bin/puppet cert sign agent.severalnines.comoder
$ sudo /opt/puppetlabs/bin/puppet cert sign --allSchließlich (und nachdem der Puppet Master das Zertifikat signiert hat) ist es an der Zeit, die Konfigurationen auf den Agenten anzuwenden, indem der Katalog vom Puppet Master abgerufen wird:
$ sudo /opt/puppetlabs/bin/puppet agent --testIn diesem Befehl bedeutet der Parameter --test keinen Test, die vom Master abgerufenen Einstellungen werden auf den lokalen Agenten angewendet. Um die Konfigurationen vom Master zu testen/überprüfen, muss der folgende Befehl ausgeführt werden:
$ sudo /opt/puppetlabs/bin/puppet agent --noopPuppe konfigurieren und programmieren
Puppet verwendet einen deklarativen Programmieransatz, bei dem der Zweck darin besteht, festzulegen, was zu tun ist, und der Weg, dies zu erreichen, egal ist!
Das elementarste Stück Code auf Puppet ist die Ressource, die eine Systemeigenschaft wie Befehl, Dienst, Datei, Verzeichnis, Benutzer oder Paket angibt.
Unten ist die Syntax einer Ressource zum Erstellen eines Benutzers dargestellt:
user { 'admin_postgresql':
ensure => present,
uid => '1000',
gid => '1000',
home => '/home/admin/postresql'
}Verschiedene Ressourcen könnten mit der früheren Klasse (auch bekannt als Manifest) von Dateien mit der Erweiterung „pp“ (es steht für Puppet Program) verbunden werden, dennoch mehrere Manifeste und Daten (wie Fakten, Dateien und Vorlagen) bilden ein Modul. Alle dort logischen Hierarchien und Regeln sind im Diagramm unten dargestellt:
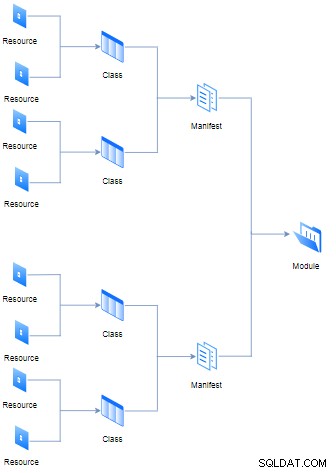
Der Zweck jedes Moduls besteht darin, alle erforderlichen Manifeste zur Ausführung einzeln zu enthalten Aufgaben modular. Auf der anderen Seite ist das Klassenkonzept nicht dasselbe wie in objektorientierten Programmiersprachen, in Puppet funktioniert es als Aggregator von Ressourcen.
Die Organisation dieser Dateien muss einer bestimmten Verzeichnisstruktur folgen:
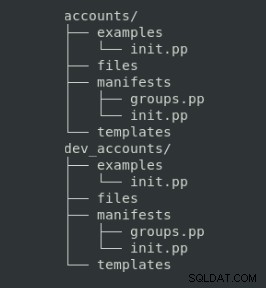
wobei der Zweck jedes Ordners folgender ist:
| Ordner | Beschreibung |
| Manifeste | Puppet-Code |
| Dateien | Statische Dateien, die auf Knoten kopiert werden sollen |
| Vorlagen | Vorlagendateien, die auf verwaltete Knoten kopiert werden sollen (kann mit Variablen angepasst werden) |
| Beispiele | Manifest, um zu zeigen, wie das Modul verwendet wird |
class dev_accounts {
$rootgroup = $osfamily ? {
'Debian' => 'sudo',
'RedHat' => 'wheel',
default => warning('This distribution is not supported by the Accounts module'),
}
include accounts::groups
user { 'username':
ensure => present,
home => '/home/admin/postresql',
shell => '/bin/bash',
managehome => true,
gid => 'admin_db',
groups => "$rootgroup",
password => '$1$7URTNNqb$65ca6wPFDvixURc/MMg7O1'
}
}Im nächsten Abschnitt zeigen wir Ihnen, wie Sie den Inhalt des Beispielordners generieren, sowie die Befehle zum Testen und Veröffentlichen jedes Moduls.
Puppet für PostgreSQL konfigurieren
Bevor die verschiedenen Konfigurationsbeispiele zum Bereitstellen und Verwalten einer PostgreSQL-Datenbank vorgestellt werden, ist es notwendig, das PostgreSQL-Puppet-Modul (auf dem Serverhost) zu installieren, um alle seine Funktionen nutzen zu können:
$ sudo /opt/puppetlabs/bin/puppet module install puppetlabs-postgresqlDerzeit sind Tausende von Modulen, die bereit sind, auf Puppet verwendet zu werden, im öffentlichen Modul-Repository Puppet Forge verfügbar.
Schritt Eins
Konfigurieren und implementieren Sie eine neue PostgreSQL-Instanz. Hier ist die gesamte notwendige Programmierung und Konfiguration, um eine neue PostgreSQL-Instanz in allen Knoten zu installieren.
Der erste Schritt besteht darin, ein neues Modulstrukturverzeichnis zu erstellen, wie es zuvor freigegeben wurde:
$ cd /etc/puppetlabs/code/environments/production/modules
$ mkdir db_postgresql_admin
$ cd db_postgresql_admin; mkdir{examples,files,manifests,templates}Dann müssen Sie in der Manifestdatei manifests/init.pp die vom installierten Modul bereitgestellte Klasse postgresql::server einbinden :
class db_postgresql_admin{
include postgresql::server
}Um die Syntax des Manifests zu überprüfen, empfiehlt es sich, den folgenden Befehl auszuführen:
$ sudo /opt/puppetlabs/bin/puppet parser validate init.ppWenn nichts zurückgegeben wird, bedeutet dies, dass die Syntax korrekt ist
Um Ihnen zu zeigen, wie Sie dieses Modul im Beispielordner verwenden, müssen Sie eine neue Manifestdatei init.pp mit folgendem Inhalt erstellen:
include db_postgresql_adminDer Beispielspeicherort im Modul muss getestet und auf den Hauptkatalog angewendet werden:
$ sudo /opt/puppetlabs/bin/puppet apply --modulepath=/etc/puppetlabs/code/environments/production/modules --noop init.ppSchließlich muss in der Datei „/etc/puppetlabs/code/environments/production/manifests/site.pp“ definiert werden, auf welches Modul jeder Knoten Zugriff hat:
node ’agent.severalnines.com’,’agent2.severalnines.com’{
include db_postgresql_admin
}Oder eine Standardkonfiguration für alle Knoten:
node default {
include db_postgresql_admin
}Normalerweise prüfen die Knoten alle 30min den Hauptkatalog, dennoch kann diese Abfrage auf Knotenseite durch folgenden Befehl erzwungen werden:
$ /opt/puppetlabs/bin/puppet agent -tOder wenn der Zweck darin besteht, die Unterschiede zwischen der Master-Konfiguration und den aktuellen Knoteneinstellungen zu simulieren, könnte der nopp-Parameter verwendet werden (keine Operation):
$ /opt/puppetlabs/bin/puppet agent -t --noopSchritt Zwei
Aktualisieren Sie die PostgreSQL-Instanz, um alle Schnittstellen abzuhören. Die vorherige Installation definiert eine Instanzeinstellung in einem sehr restriktiven Modus:erlaubt nur Verbindungen auf localhost, wie durch die Hosts bestätigt werden kann, die für den Port 5432 (definiert für PostgreSQL) zugeordnet sind:
$ sudo netstat -ntlp|grep 5432
tcp 0 0 127.0.0.1:5432 0.0.0.0:* LISTEN 3237/postgres
tcp6 0 0 ::1:5432 :::* LISTEN 3237/postgres Um das Abhören aller Schnittstellen zu ermöglichen, muss der folgende Inhalt in der Datei /etc/puppetlabs/code/environments/production/modules/db_postgresql_admin/manifests/init.pp vorhanden sein
class db_postgresql_admin{
class{‘postgresql:server’:
listen_addresses=>’*’ #listening all interfaces
}
}Im obigen Beispiel wird die Klasse postgresql::server deklariert und der Parameter listen_addresses auf „*“ gesetzt, das bedeutet alle Schnittstellen.
Nun ist der Port 5432 allen Schnittstellen zugeordnet, er kann mit folgender IP-Adresse/Port bestätigt werden:„0.0.0.0:5432“
$ sudo netstat -ntlp|grep 5432
tcp 0 0 0.0.0.0:5432 0.0.0.0:* LISTEN 1232/postgres
tcp6 0 0 :::5432 :::* LISTEN 1232/postgres Um die Anfangseinstellung zurückzusetzen:nur Datenbankverbindungen von localhost zulassen muss der Parameter listen_addresses auf „localhost“ gesetzt werden oder eine Liste von Hosts angeben, falls gewünscht:
listen_addresses = 'agent2.severalnines.com,agent3.severalnines.com,localhost'Um die neue Konfiguration vom Master-Host abzurufen, muss sie nur auf dem Knoten angefordert werden:
$ /opt/puppetlabs/bin/puppet agent -tSchritt Drei
Erstellen Sie eine PostgreSQL-Datenbank. Die PostgreSQL-Instanz kann mit einer neuen Datenbank sowie einem neuen Benutzer (mit Passwort) zur Verwendung dieser Datenbank und einer Regel für die Datei pg_hab.conf erstellt werden, um die Datenbankverbindung für diesen neuen Benutzer zuzulassen:
class db_postgresql_admin{
class{‘postgresql:server’:
listen_addresses=>’*’ #listening all interfaces
}
postgresql::server::db{‘nines_blog_db’:
user => ‘severalnines’, password=> postgresql_password(‘severalnines’,’passwd12’)
}
postgresql::server::pg_hba_rule{‘Authentication for severalnines’:
Description =>’Open access to severalnines’,
type => ‘local’,
database => ‘nines_blog_db’,
user => ‘severalnines’,
address => ‘127.0.0.1/32’
auth_method => ‘md5’
}
}Diese letzte Ressource hat den Namen „Authentifizierung für mehrere Neunen“ und die Datei pg_hba.conf enthält eine weitere zusätzliche Regel:
# Rule Name: Authentication for severalnines
# Description: Open access for severalnines
# Order: 150
local nines_blog_db severalnines 127.0.0.1/32 md5Um die neue Konfiguration vom Master-Host abzurufen, muss sie nur auf dem Knoten angefordert werden:
$ /opt/puppetlabs/bin/puppet agent -tSchritt Vier
Erstellen Sie einen schreibgeschützten Benutzer. Um einen neuen Benutzer mit Nur-Lese-Berechtigungen zu erstellen, müssen die folgenden Ressourcen zum vorherigen Manifest hinzugefügt werden:
postgresql::server::role{‘Creation of a new role nines_reader’:
createdb => false,
createrole => false,
superuser => false, password_hash=> postgresql_password(‘nines_reader’,’passwd13’)
}
postgresql::server::pg_hba_rule{‘Authentication for nines_reader’:
description =>’Open access to nines_reader’,
type => ‘host’,
database => ‘nines_blog_db’,
user => ‘nines_reader’,
address => ‘192.168.1.10/32’,
auth_method => ‘md5’
}Um die neue Konfiguration vom Master-Host abzurufen, muss sie nur auf dem Knoten angefordert werden:
$ /opt/puppetlabs/bin/puppet agent -tSchlussfolgerung
In diesem Blogpost haben wir Ihnen die grundlegenden Schritte zum Bereitstellen und Starten der Konfiguration Ihrer PostgreSQL-Datenbank durch einen automatischen und angepassten Weg auf mehreren Knoten (die sogar virtuelle Maschinen sein können) gezeigt.
Diese Arten der Automatisierung können Ihnen helfen, effektiver zu werden, als es manuell zu tun, und die PostgreSQL-Konfiguration kann einfach durchgeführt werden, indem Sie mehrere der im Puppetforge-Repository verfügbaren Klassen verwenden