Hochverfügbarkeit ist eine Anforderung für nahezu jedes Unternehmen auf der ganzen Welt, das PostgreSQL verwendet. Es ist bekannt, dass PostgreSQL die Streaming-Replikation als Replikationsmethode verwendet. Die PostgreSQL-Streaming-Replikation ist standardmäßig asynchron, sodass es möglich ist, dass einige Transaktionen im primären Knoten festgeschrieben werden, die noch nicht auf den Standby-Server repliziert wurden. Dies bedeutet, dass die Möglichkeit eines potenziellen Datenverlusts besteht.
Diese Verzögerung im Commit-Prozess sollte sehr gering sein ... wenn der Standby-Server leistungsfähig genug ist, um mit der Last Schritt zu halten. Wenn dieses geringe Datenverlustrisiko im Unternehmen nicht akzeptabel ist, können Sie statt der Standardeinstellung auch die synchrone Replikation verwenden.
Bei der synchronen Replikation wartet jeder Commit einer Schreibtransaktion auf die Bestätigung, dass der Commit auf die Write-Ahead-Log-On-Festplatte sowohl des Primär- als auch des Standby-Servers geschrieben wurde.
Diese Methode minimiert die Möglichkeit eines Datenverlusts. Damit ein Datenverlust auftritt, müssen sowohl der Primär- als auch der Standby-Server gleichzeitig ausfallen.
Der Nachteil dieser Methode ist bei allen synchronen Methoden gleich, da sich bei dieser Methode die Antwortzeit für jede Schreibtransaktion erhöht. Dies liegt daran, dass gewartet werden muss, bis alle Bestätigungen vorliegen, dass die Transaktion festgeschrieben wurde. Glücklicherweise sind schreibgeschützte Transaktionen davon nicht betroffen, aber; nur die Schreibtransaktionen.
In diesem Blog zeigen Sie Ihnen, wie Sie einen PostgreSQL-Cluster von Grund auf neu installieren und die asynchrone Replikation (Standard) in eine synchrone umwandeln. Ich zeige Ihnen auch, wie Sie ein Rollback durchführen, wenn die Antwortzeit nicht akzeptabel ist, da Sie ganz einfach zum vorherigen Zustand zurückkehren können. Sie werden sehen, wie Sie eine synchrone PostgreSQL-Replikation mithilfe von ClusterControl einfach bereitstellen, konfigurieren und überwachen können, indem Sie nur ein Tool für den gesamten Prozess verwenden.
Installieren eines PostgreSQL-Clusters
Beginnen wir mit der Installation und Konfiguration einer asynchronen PostgreSQL-Replikation, das ist der übliche Replikationsmodus, der in einem PostgreSQL-Cluster verwendet wird. Wir werden PostgreSQL 11 auf CentOS 7 verwenden.
PostgreSQL-Installation
Nach der offiziellen PostgreSQL-Installationsanleitung ist diese Aufgabe ziemlich einfach.
Installieren Sie zuerst das Repository:
$ yum install https://download.postgresql.org/pub/repos/yum/reporpms/EL-7-x86_64/pgdg-redhat-repo-latest.noarch.rpmInstallieren Sie die PostgreSQL-Client- und -Serverpakete:
$ yum install postgresql11 postgresql11-serverDatenbank initialisieren:
$ /usr/pgsql-11/bin/postgresql-11-setup initdb
$ systemctl enable postgresql-11
$ systemctl start postgresql-11Auf dem Standby-Knoten können Sie den letzten Befehl (Starten des Datenbankdienstes) vermeiden, da Sie eine binäre Sicherung wiederherstellen, um die Streaming-Replikation zu erstellen.
Sehen wir uns nun die Konfiguration an, die für eine asynchrone PostgreSQL-Replikation erforderlich ist.
Asynchrone PostgreSQL-Replikation konfigurieren
Einrichtung des primären Knotens
Im primären PostgreSQL-Knoten müssen Sie die folgende grundlegende Konfiguration verwenden, um eine asynchrone Replikation zu erstellen. Die Dateien, die geändert werden, sind postgresql.conf und pg_hba.conf. Im Allgemeinen befinden sie sich im Datenverzeichnis (/var/lib/pgsql/11/data/), aber Sie können dies auf der Datenbankseite bestätigen:
postgres=# SELECT setting FROM pg_settings WHERE name = 'data_directory';
setting
------------------------
/var/lib/pgsql/11/data
(1 row)Postgresql.conf
Ändern oder fügen Sie die folgenden Parameter in der Konfigurationsdatei postgresql.conf hinzu.
Hier müssen Sie die IP-Adresse(n) hinzufügen, auf der/denen abgehört werden soll. Der Standardwert ist „localhost“, und in diesem Beispiel verwenden wir „*“ für alle IP-Adressen auf dem Server.
listen_addresses = '*' Stellen Sie den Server-Port ein, auf dem gelauscht werden soll. Standardmäßig 5432.
port = 5432 Legen Sie fest, wie viele Informationen in die WALs geschrieben werden. Die möglichen Werte sind minimal, replik oder logisch. Der hot_standby-Wert wird dem Replikat zugeordnet und wird verwendet, um die Kompatibilität mit früheren Versionen aufrechtzuerhalten.
wal_level = hot_standby Setze die maximale Anzahl an Walsender-Prozessen, die die Verbindung mit einem Standby-Server verwalten.
max_wal_senders = 16Legen Sie die Mindestanzahl an WAL-Dateien fest, die im Verzeichnis pg_wal aufbewahrt werden sollen.
wal_keep_segments = 32Das Ändern dieser Parameter erfordert einen Neustart des Datenbankdienstes.
$ systemctl restart postgresql-11Pg_hba.conf
Ändern oder fügen Sie die folgenden Parameter in der Konfigurationsdatei pg_hba.conf hinzu.
# TYPE DATABASE USER ADDRESS METHOD
host replication replication_user IP_STANDBY_NODE/32 md5
host replication replication_user IP_PRIMARY_NODE/32 md5Wie Sie sehen können, müssen Sie hier die Benutzerzugriffsberechtigung hinzufügen. Die erste Spalte ist der Verbindungstyp, der Host oder lokal sein kann. Dann müssen Sie die Datenbank (Replikation), den Benutzer, die Quell-IP-Adresse und die Authentifizierungsmethode angeben. Das Ändern dieser Datei erfordert ein Neuladen des Datenbankdienstes.
$ systemctl reload postgresql-11Sie sollten diese Konfiguration sowohl in primären als auch in Standby-Knoten hinzufügen, da Sie sie benötigen, wenn der Standby-Knoten im Falle eines Fehlers zum Master hochgestuft wird.
Jetzt müssen Sie einen Replikationsbenutzer erstellen.
Replikationsrolle
Die ROLE (Benutzer) muss REPLICATION-Berechtigung haben, um sie in der Streaming-Replikation zu verwenden.
postgres=# CREATE ROLE replication_user WITH LOGIN PASSWORD 'PASSWORD' REPLICATION;
CREATE ROLENach der Konfiguration der entsprechenden Dateien und der Benutzererstellung müssen Sie ein konsistentes Backup vom primären Knoten erstellen und auf dem Standby-Knoten wiederherstellen.
Setup des Standby-Knotens
Gehen Sie auf dem Standby-Knoten in das Verzeichnis /var/lib/pgsql/11/ und verschieben oder entfernen Sie das aktuelle Datenverzeichnis:
$ cd /var/lib/pgsql/11/
$ mv data data.bkFühren Sie dann den Befehl pg_basebackup aus, um das aktuelle primäre Datenverzeichnis abzurufen und den richtigen Eigentümer (postgres) zuzuweisen:
$ pg_basebackup -h 192.168.100.145 -D /var/lib/pgsql/11/data/ -P -U replication_user --wal-method=stream
$ chown -R postgres.postgres dataNun müssen Sie die folgende grundlegende Konfiguration verwenden, um eine asynchrone Replikation zu erstellen. Die Datei, die geändert wird, ist postgresql.conf, und Sie müssen eine neue recovery.conf-Datei erstellen. Beide befinden sich in /var/lib/pgsql/11/.
Recovery.conf
Geben Sie an, dass dieser Server ein Standby-Server sein soll. Wenn es eingeschaltet ist, fährt der Server mit der Wiederherstellung fort, indem neue WAL-Segmente abgerufen werden, wenn das Ende der archivierten WAL erreicht ist.
standby_mode = 'on'Geben Sie eine Verbindungszeichenfolge an, die der Standby-Server verwenden soll, um sich mit dem primären Knoten zu verbinden.
primary_conninfo = 'host=IP_PRIMARY_NODE port=5432 user=replication_user password=PASSWORD'Geben Sie die Wiederherstellung in eine bestimmte Zeitachse an. Standardmäßig erfolgt die Wiederherstellung entlang derselben Zeitachse, die aktuell war, als die Basissicherung erstellt wurde. Wenn Sie dies auf „Neueste“ setzen, wird die letzte im Archiv gefundene Zeitachse wiederhergestellt.
recovery_target_timeline = 'latest'Geben Sie eine Triggerdatei an, deren Vorhandensein die Wiederherstellung im Standby beendet.
trigger_file = '/tmp/failover_5432.trigger'Postgresql.conf
Ändern oder fügen Sie die folgenden Parameter in der Konfigurationsdatei postgresql.conf hinzu.
Bestimmen Sie, wie viele Informationen in die WALs geschrieben werden. Die möglichen Werte sind minimal, replik oder logisch. Der hot_standby-Wert wird dem Replikat zugeordnet und wird verwendet, um die Kompatibilität mit früheren Versionen aufrechtzuerhalten. Das Ändern dieses Werts erfordert einen Dienstneustart.
wal_level = hot_standbyAbfragen während der Wiederherstellung zulassen. Das Ändern dieses Werts erfordert einen Dienstneustart.
hot_standby = onStandby-Knoten wird gestartet
Jetzt haben Sie alle erforderlichen Konfigurationen vorgenommen, Sie müssen nur noch den Datenbankdienst auf dem Standby-Knoten starten.
$ systemctl start postgresql-11Und überprüfen Sie die Datenbankprotokolle in /var/lib/pgsql/11/data/log/. Sie sollten so etwas haben:
2019-11-18 20:23:57.440 UTC [1131] LOG: entering standby mode
2019-11-18 20:23:57.447 UTC [1131] LOG: redo starts at 0/3000028
2019-11-18 20:23:57.449 UTC [1131] LOG: consistent recovery state reached at 0/30000F8
2019-11-18 20:23:57.449 UTC [1129] LOG: database system is ready to accept read only connections
2019-11-18 20:23:57.457 UTC [1135] LOG: started streaming WAL from primary at 0/4000000 on timeline 1Sie können den Replikationsstatus auch im primären Knoten überprüfen, indem Sie die folgende Abfrage ausführen:
postgres=# SELECT pid,usename,application_name,state,sync_state FROM pg_stat_replication;
pid | usename | application_name | state | sync_state
------+------------------+------------------+-----------+------------
1467 | replication_user | walreceiver | streaming | async
(1 row)Wie Sie sehen können, verwenden wir eine asynchrone Replikation.
Konvertieren der asynchronen PostgreSQL-Replikation in die synchrone Replikation
Jetzt ist es an der Zeit, diese asynchrone Replikation in eine synchrone Replikation umzuwandeln, und dafür müssen Sie sowohl den primären als auch den Standby-Knoten konfigurieren.
Primärer Knoten
Im primären PostgreSQL-Knoten müssen Sie diese grundlegende Konfiguration zusätzlich zur vorherigen asynchronen Konfiguration verwenden.
Postgresql.conf
Geben Sie eine Liste von Standby-Servern an, die die synchrone Replikation unterstützen können. Dieser Name des Standby-Servers ist die Einstellung application_name in der recovery.conf-Datei des Standby-Servers.
synchronous_standby_names = 'pgsql_0_node_0'synchronous_standby_names = 'pgsql_0_node_0'Gibt an, ob die Transaktionsfestschreibung darauf wartet, dass WAL-Einträge auf die Festplatte geschrieben werden, bevor der Befehl eine „Erfolgsanzeige“ an den Client zurückgibt. Die gültigen Werte sind on, remote_apply, remote_write, local und off. Der Standardwert ist eingeschaltet.
synchronous_commit = onEinrichtung des Standby-Knotens
Im PostgreSQL-Standby-Knoten müssen Sie die Datei recovery.conf ändern und den Wert 'application_name' im Parameter primary_conninfo hinzufügen.
Recovery.conf
standby_mode = 'on'
primary_conninfo = 'application_name=pgsql_0_node_0 host=IP_PRIMARY_NODE port=5432 user=replication_user password=PASSWORD'
recovery_target_timeline = 'latest'
trigger_file = '/tmp/failover_5432.trigger'Starten Sie den Datenbankdienst sowohl im primären als auch im Standby-Knoten neu:
$ service postgresql-11 restartNun sollte Ihre Sync-Streaming-Replikation betriebsbereit sein:
postgres=# SELECT pid,usename,application_name,state,sync_state FROM pg_stat_replication;
pid | usename | application_name | state | sync_state
------+------------------+------------------+-----------+------------
1561 | replication_user | pgsql_0_node_0 | streaming | sync
(1 row)Rollback von synchroner zu asynchroner PostgreSQL-Replikation
Wenn Sie zur asynchronen PostgreSQL-Replikation zurückkehren müssen, müssen Sie nur die Änderungen rückgängig machen, die in der Datei postgresql.conf auf dem primären Knoten vorgenommen wurden:
Postgresql.conf
#synchronous_standby_names = 'pgsql_0_node_0'
#synchronous_commit = onUnd starten Sie den Datenbankdienst neu.
$ service postgresql-11 restartNun sollten Sie also wieder asynchrone Replikation haben.
postgres=# SELECT pid,usename,application_name,state,sync_state FROM pg_stat_replication;
pid | usename | application_name | state | sync_state
------+------------------+------------------+-----------+------------
1625 | replication_user | pgsql_0_node_0 | streaming | async
(1 row)So stellen Sie eine synchrone PostgreSQL-Replikation mit ClusterControl bereit
Mit ClusterControl können Sie die Bereitstellungs-, Konfigurations- und Überwachungsaufgaben in einem einzigen Job ausführen und über dieselbe Benutzeroberfläche verwalten.
Wir gehen davon aus, dass Sie ClusterControl installiert haben und über SSH auf die Datenbankknoten zugreifen können. Weitere Informationen zur Konfiguration des ClusterControl-Zugriffs finden Sie in unserer offiziellen Dokumentation.
Gehen Sie zu ClusterControl und verwenden Sie die Option „Bereitstellen“, um einen neuen PostgreSQL-Cluster zu erstellen.
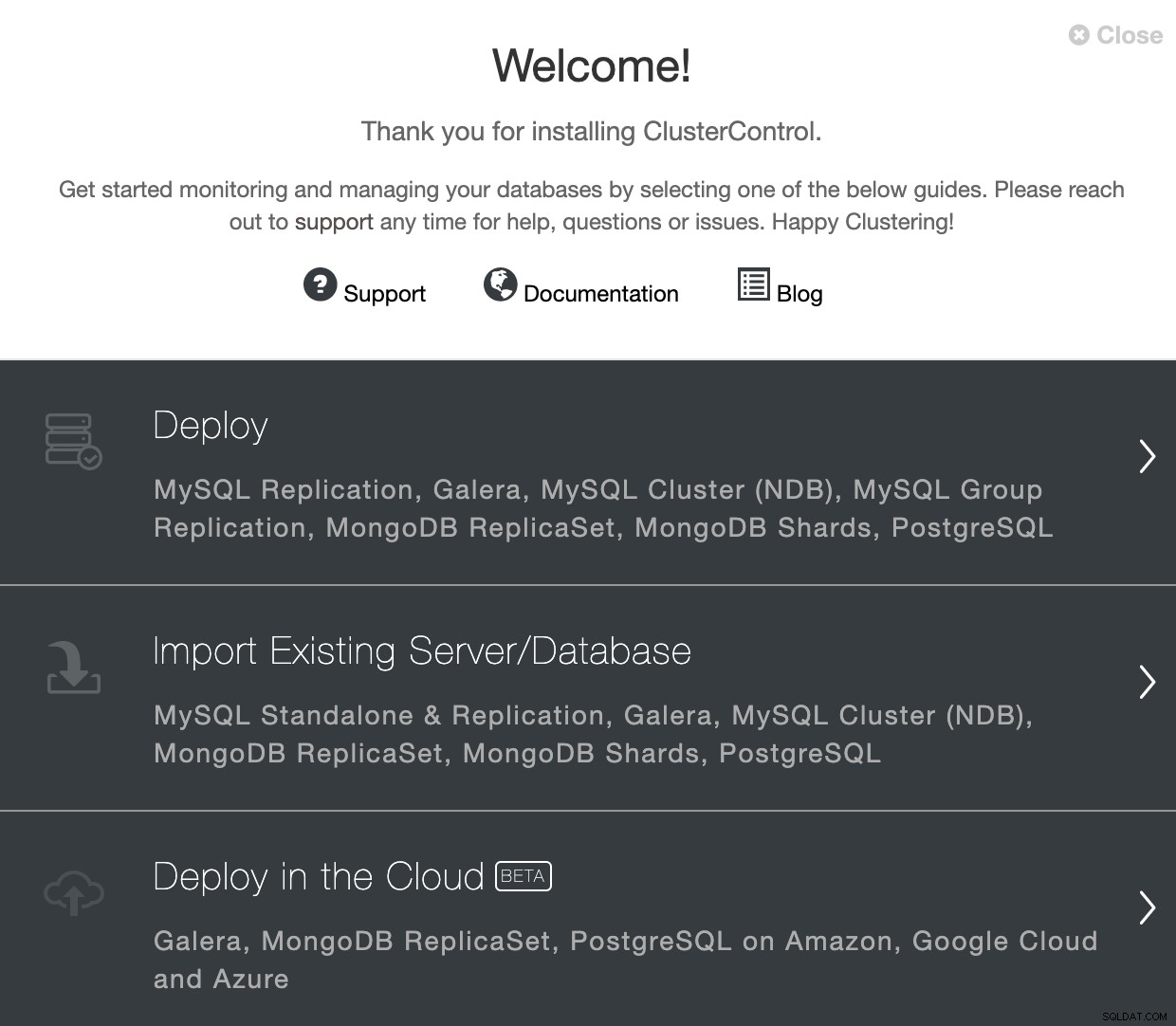
Bei der Auswahl von PostgreSQL müssen Sie Benutzer, Schlüssel oder Passwort und a angeben Port, um sich per SSH mit unseren Servern zu verbinden. Außerdem benötigen Sie einen Namen für Ihren neuen Cluster und wenn Sie möchten, dass ClusterControl die entsprechende Software und Konfigurationen für Sie installiert.
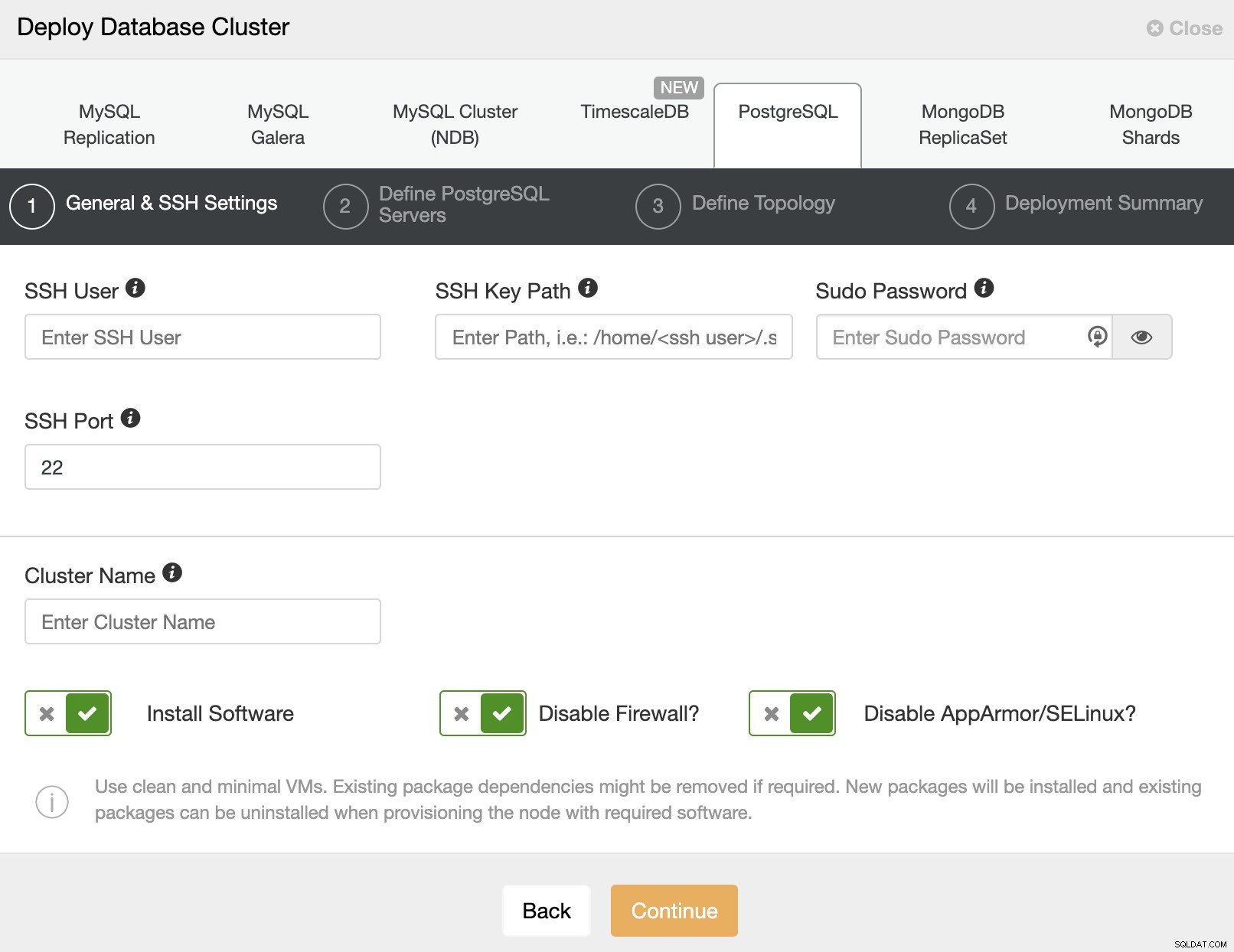
Nachdem Sie die SSH-Zugangsdaten eingerichtet haben, müssen Sie die Zugangsdaten eingeben Ihre Datenbank. Sie können auch angeben, welches Repository verwendet werden soll.
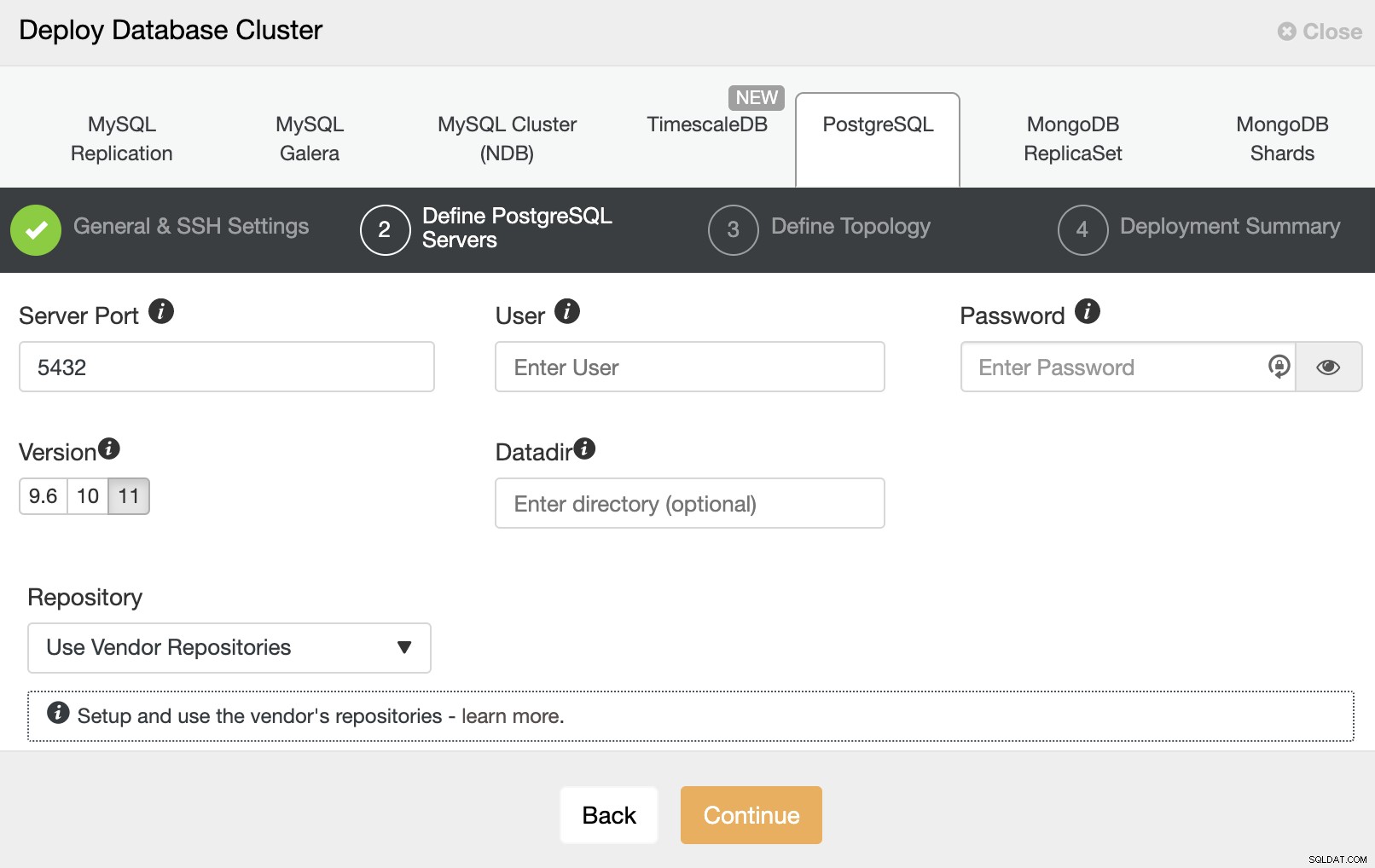
Im nächsten Schritt müssen Sie Ihre Server dem Cluster hinzufügen du wirst erschaffen. Beim Hinzufügen Ihrer Server können Sie die IP oder den Hostnamen eingeben.
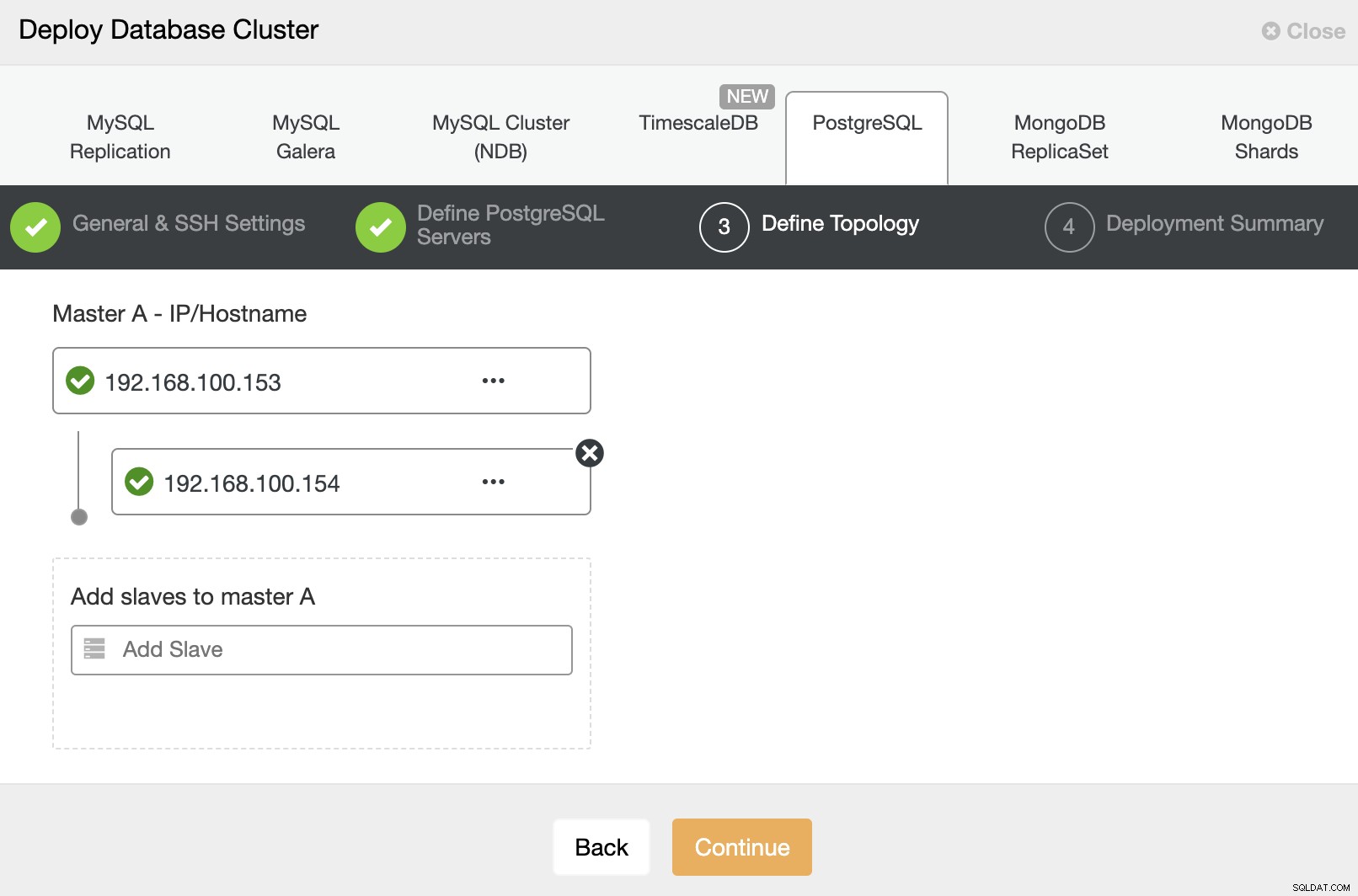
Und schließlich können Sie im letzten Schritt die Replikationsmethode auswählen, die asynchrone oder synchrone Replikation sein kann.
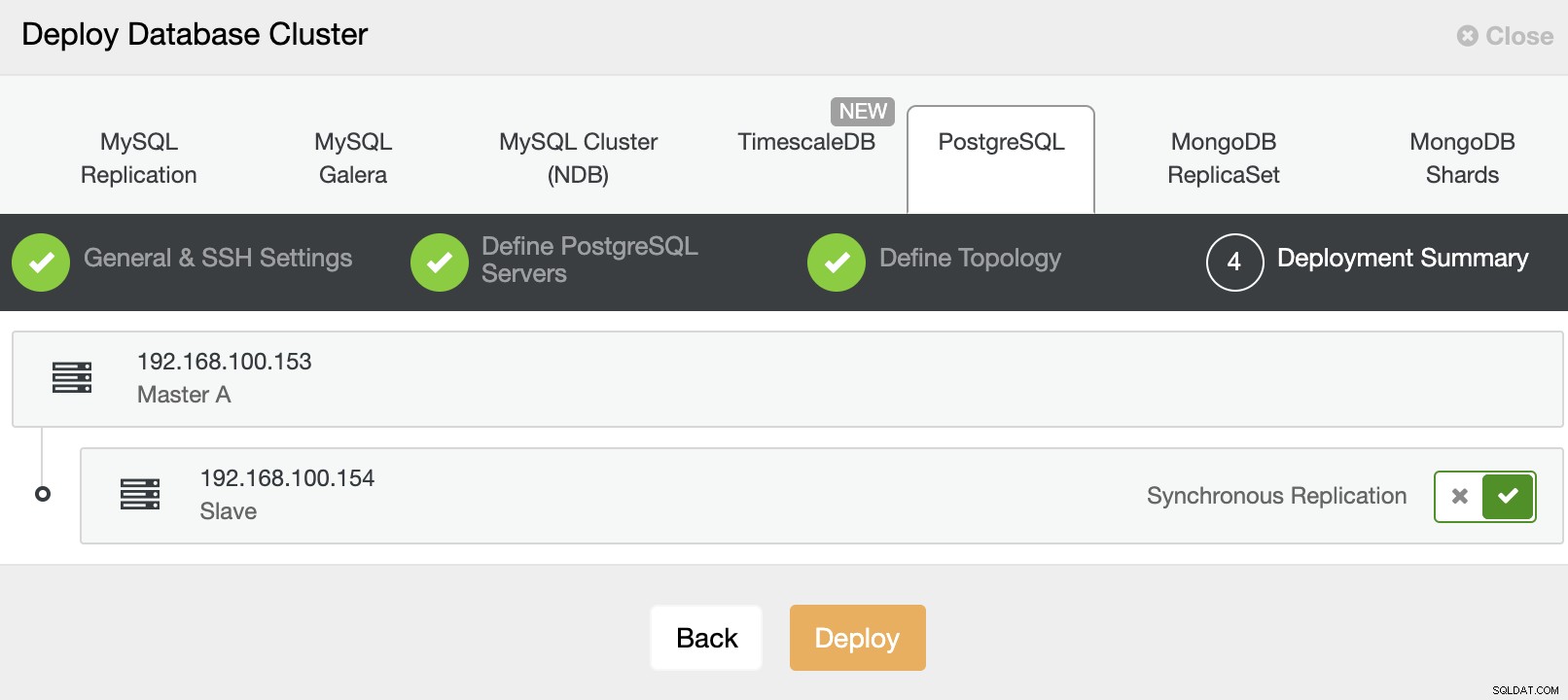
Das war's. Sie können den Auftragsstatus im Aktivitätsbereich von ClusterControl überwachen.
Und wenn dieser Job abgeschlossen ist, haben Sie Ihren synchronen PostgreSQL-Cluster installiert, von ClusterControl konfiguriert und überwacht.
Fazit
Wie wir zu Beginn dieses Blogs erwähnt haben, ist Hochverfügbarkeit eine Anforderung für alle Unternehmen, daher sollten Sie die verfügbaren Optionen kennen, um dies für jede verwendete Technologie zu erreichen. Für PostgreSQL können Sie die synchrone Streaming-Replikation als sicherste Methode zur Implementierung verwenden, aber diese Methode funktioniert nicht für alle Umgebungen und Workloads.
Seien Sie vorsichtig mit der Latenzzeit, die entsteht, wenn Sie auf die Bestätigung jeder Transaktion warten, die ein Problem anstelle einer Hochverfügbarkeitslösung sein könnte.