Dieser Blog ist der zweite Teil von Implementing a Multi-Datacenter Setup for PostgreSQL. In diesem Schlag zeigen wir, wie PostgreSQL in dieser Art von Umgebung bereitgestellt wird und wie im Falle eines Master-Ausfalls ein Failover mithilfe der automatischen Wiederherstellungsfunktion von ClusterControl durchgeführt wird.
An dieser Stelle gehen wir davon aus, dass Sie über eine Verbindung zwischen den Rechenzentren verfügen (wie wir im ersten Teil dieses Blogs gesehen haben) und dass Sie über die erforderlichen Server für diese Aufgabe verfügen (wie wir auch in der vorheriger Teil).
Stellen Sie einen PostgreSQL-Cluster bereit
Wir verwenden ClusterControl für diese Aufgabe, daher gehen wir davon aus, dass Sie es installiert haben (es könnte auf demselben Load Balancer-Server installiert sein, aber wenn Sie einen anderen verwenden können, ist es noch besser).
Gehen Sie zu Ihrem ClusterControl-Server und wählen Sie die Option „Bereitstellen“. Wenn Sie bereits eine PostgreSQL-Instanz ausführen, müssen Sie stattdessen „Vorhandenen Server/Datenbank importieren“ auswählen.
Bei der Auswahl von PostgreSQL müssen Sie Benutzer, Schlüssel oder Passwort und Port angeben verbinden Sie sich per SSH mit unseren PostgreSQL-Hosts. Außerdem benötigen Sie den Namen für Ihren neuen Cluster und wenn Sie möchten, dass ClusterControl die entsprechende Software und Konfigurationen für Sie installiert.
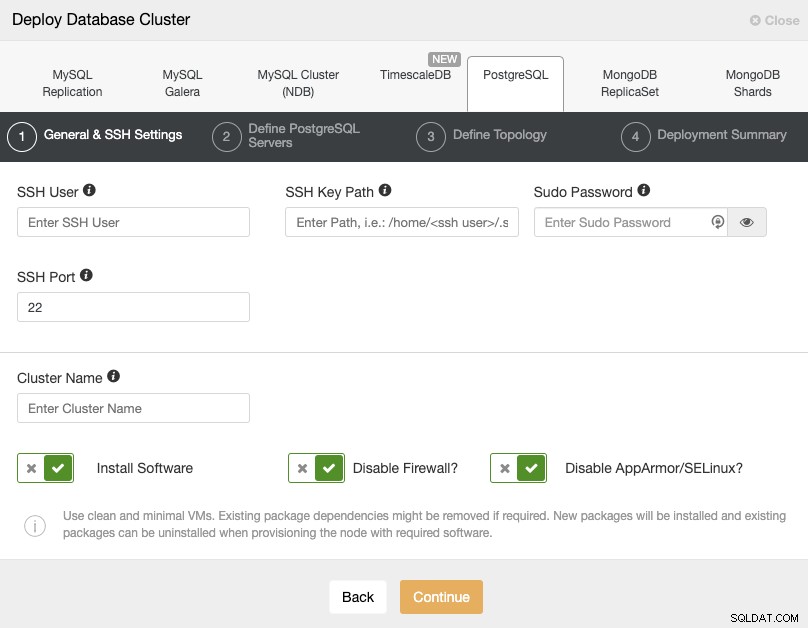
Bitte überprüfen Sie die ClusterControl-Benutzeranforderungen für diese Aufgabe hier, aber wenn Sie sie befolgen Im vorherigen Blog sollten Sie hier den Benutzer „remote“ und den richtigen SSH-Port verwenden (wie bereits erwähnt, wird empfohlen, einen anderen zu verwenden, wenn Sie die öffentliche IP-Adresse verwenden, um darauf zuzugreifen, anstatt ein VPN).
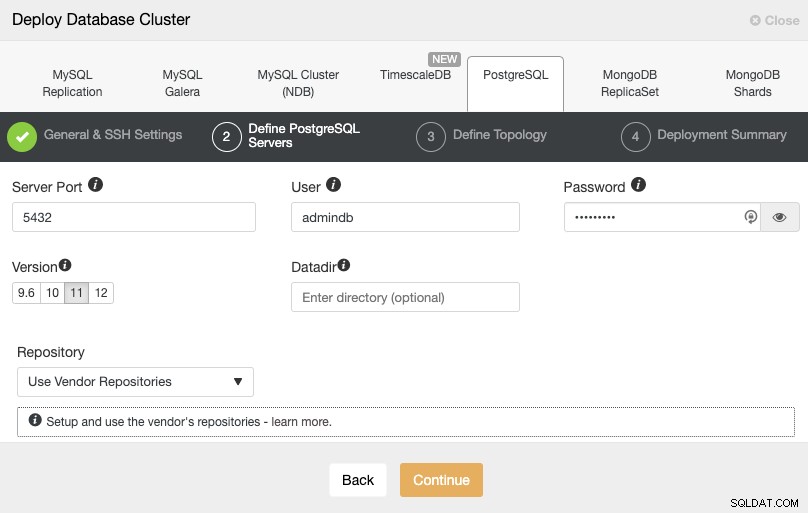
Nachdem Sie die SSH-Zugangsdaten eingerichtet haben, müssen Sie den Datenbankbenutzer definieren, version und datadir (optional). Sie können auch angeben, welches Repository verwendet werden soll. Im nächsten Schritt müssen Sie Ihre Server zu dem Cluster hinzufügen, den Sie erstellen werden.
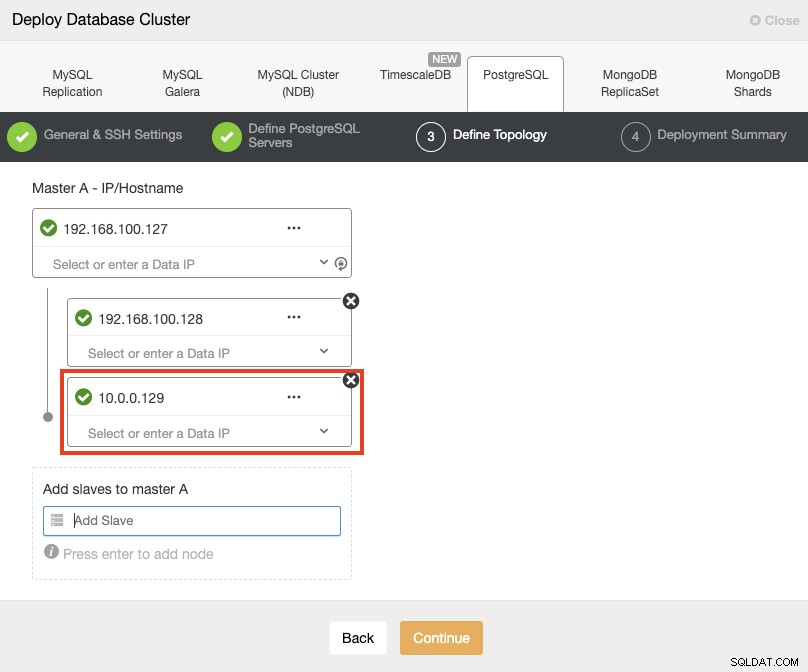
Wenn Sie Ihre Server hinzufügen, können Sie die IP oder den Hostnamen eingeben. In diesem Teil verwenden Sie die öffentlichen IP-Adressen Ihrer Server, und wie Sie im roten Kasten sehen können, verwende ich ein anderes Netzwerk für den zweiten Standby-Knoten. ClusterControl hat keine Einschränkungen hinsichtlich des zu verwendenden Netzwerks. Die einzige Voraussetzung dafür ist, SSH-Zugriff auf den Knoten zu haben.
Nach unserem vorherigen Beispiel sollten diese IP-Adressen also lauten:
Primary Node: 35.166.37.12
Standby 1 Node: 35.166.37.13
Standby 2 Node: 18.197.23.14 (red box)Im letzten Schritt können Sie wählen, ob Ihre Replikation synchron oder asynchron sein soll.
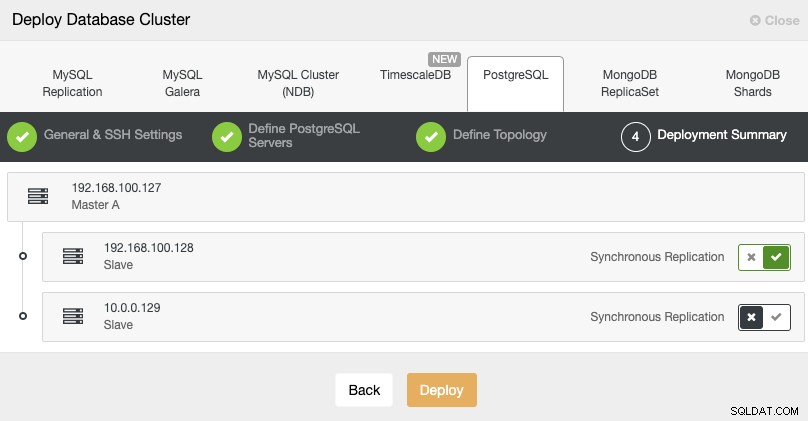
In diesem Fall ist es wichtig, die asynchrone Replikation für Ihren Remote-Knoten zu verwenden , andernfalls könnte Ihr Cluster von Latenz- oder Netzwerkproblemen betroffen sein.
Sie können den Status der Erstellung Ihres neuen Clusters im Aktivitätsmonitor von ClusterControl überwachen.
Sobald die Aufgabe abgeschlossen ist, können Sie Ihren neuen PostgreSQL-Cluster im sehen Hauptbildschirm von ClusterControl.

Hinzufügen eines PostgreSQL-Load-Balancers (HAProxy)
Sobald Sie Ihren Cluster erstellt haben, können Sie mehrere Aufgaben darauf ausführen, wie z. B. das Hinzufügen eines Load Balancers (HAProxy) oder einer neuen Replikation.
Um unserem vorherigen Beispiel zu folgen, fügen wir einen Load Balancer hinzu, der Ihnen, wie bereits erwähnt, bei der Verwaltung Ihrer HA-Umgebung hilft. Gehen Sie dazu zu ClusterControl -> PostgreSQL-Cluster auswählen -> Clusteraktionen -> Load Balancer hinzufügen.
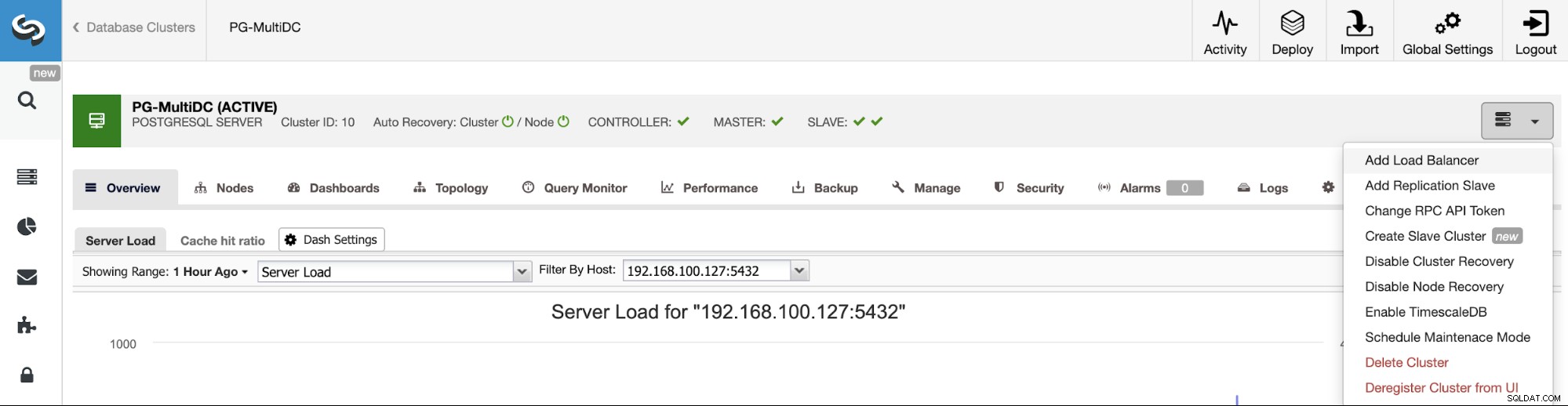
Hier müssen Sie die Informationen hinzufügen, die ClusterControl zur Installation und Konfiguration Ihrer HAProxy-Load-Balancer. Dieser Load Balancer kann auf demselben ClusterControl-Server installiert werden, aber wenn Sie einen anderen verwenden können, noch besser.
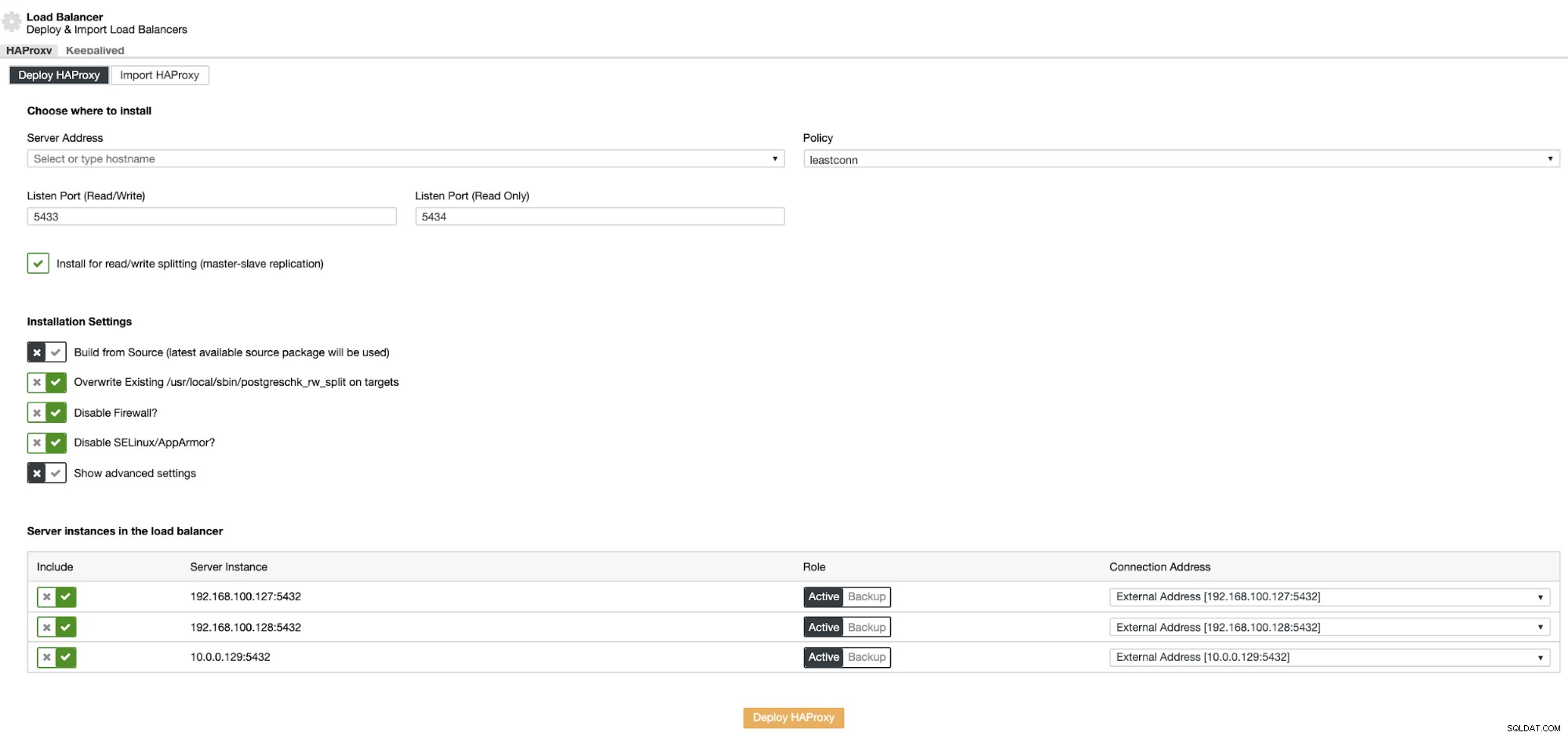
Die Informationen, die Sie eingeben müssen, sind:
Aktion:Bereitstellen oder Importieren.
Serveradresse:IP-Adresse für Ihren HAProxy-Server (es kann dieselbe ClusterControl-IP-Adresse sein).
Listen Port (Read/Write):Port für Lese-/Schreibmodus.
Listen Port (Read Only):Port für Nur-Lese-Modus.
Richtlinie:Es kann sein:
- leastconn:Der Server mit der geringsten Anzahl an Verbindungen erhält die Verbindung.
- Roundrobin:Jeder Server wird abwechselnd entsprechend seiner Gewichtung verwendet.
- source:Die Quell-IP-Adresse wird gehasht und durch die Gesamtgewichtung der laufenden Server dividiert, um festzulegen, welcher Server die Anfrage erhält.
Installieren für Read/Write-Splitting:Für Master-Slave-Replikation.
Vom Quellcode erstellen:Sie können von einem Paketmanager installieren oder vom Quellcode erstellen auswählen.
Und Sie müssen auswählen, welche Server Sie zur HAProxy-Konfiguration hinzufügen möchten.
Außerdem können Sie erweiterte Einstellungen wie Admin-Benutzer, Backend-Name, Zeitüberschreitungen und mehr konfigurieren.
Wenn Sie die Konfiguration abgeschlossen und die Bereitstellung bestätigt haben, können Sie den Fortschritt im Aktivitätsbereich auf der ClusterControl-Benutzeroberfläche verfolgen.
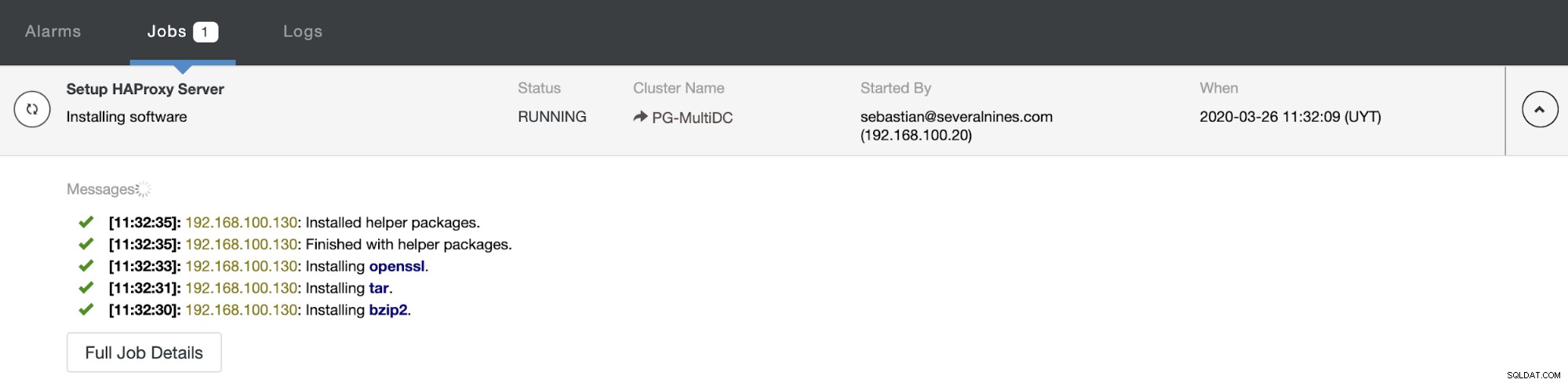
Und wenn dies abgeschlossen ist, können Sie zu ClusterControl -> Nodes -> gehen HAProxy-Knoten und überprüfen Sie den aktuellen Status.
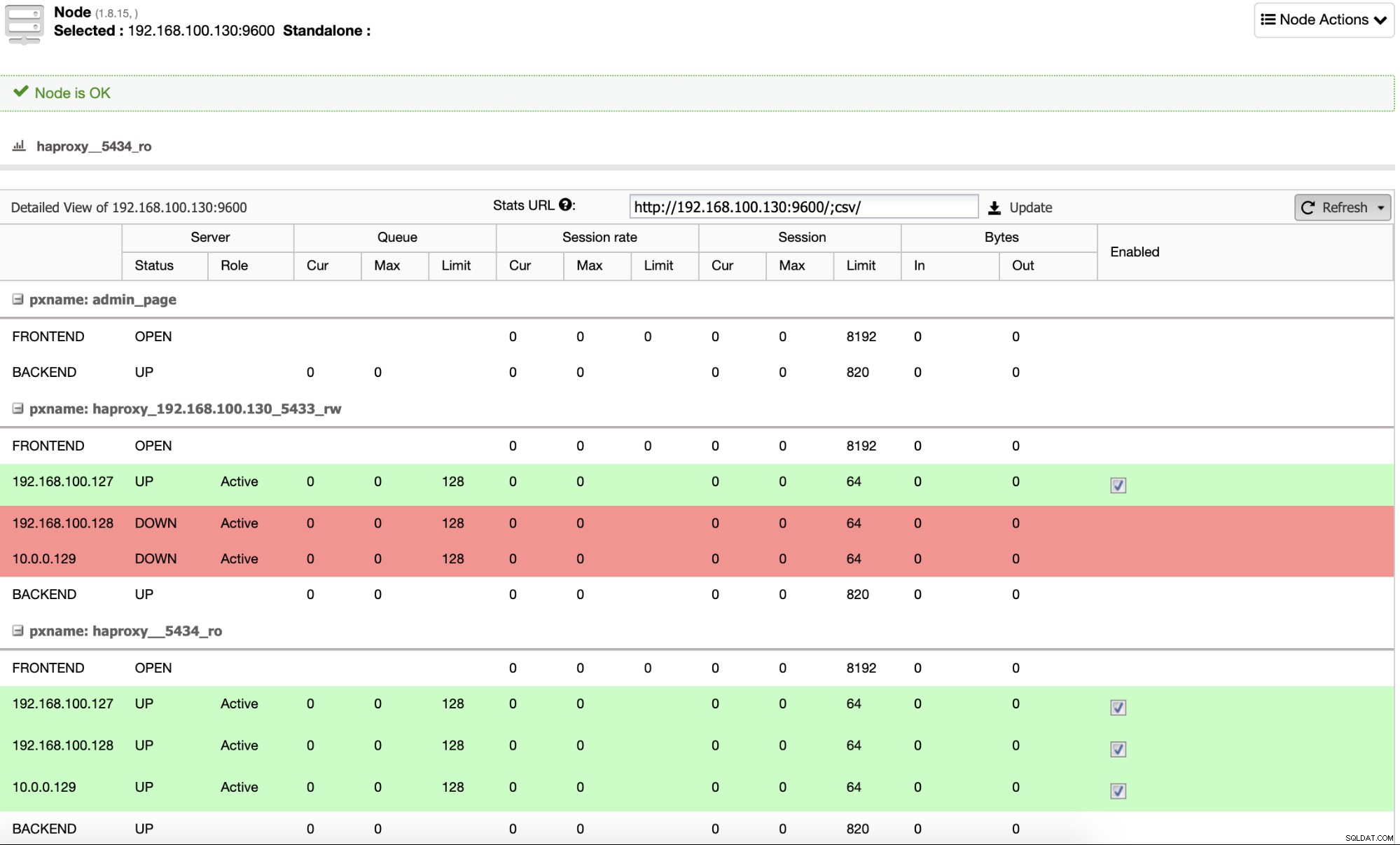
Standardmäßig konfiguriert ClusterControl HAProxy mit zwei verschiedenen Ports, einen für Read- Write, das für die Anwendung oder den Benutzer zum Schreiben (und Lesen) von Daten verwendet wird, und ein weiteres für Read-Only, das zum Ausgleichen des Leseverkehrs zwischen allen Knoten verwendet wird. Im Read-Write-Port ist nur der Master-Knoten aktiviert, und im Falle eines Master-Ausfalls befördert ClusterControl den fortschrittlichsten Slave zum Master und konfiguriert diesen Port neu, um den alten Master zu deaktivieren und den neuen zu aktivieren. Auf diese Weise kann Ihre Anwendung im Falle eines Ausfalls der Master-Datenbank weiterhin funktionieren, da der Datenverkehr vom Load Balancer an den richtigen Knoten umgeleitet wird.
Sie können auch Ihre HAProxy-Server überwachen, indem Sie den Dashboard-Bereich überprüfen.
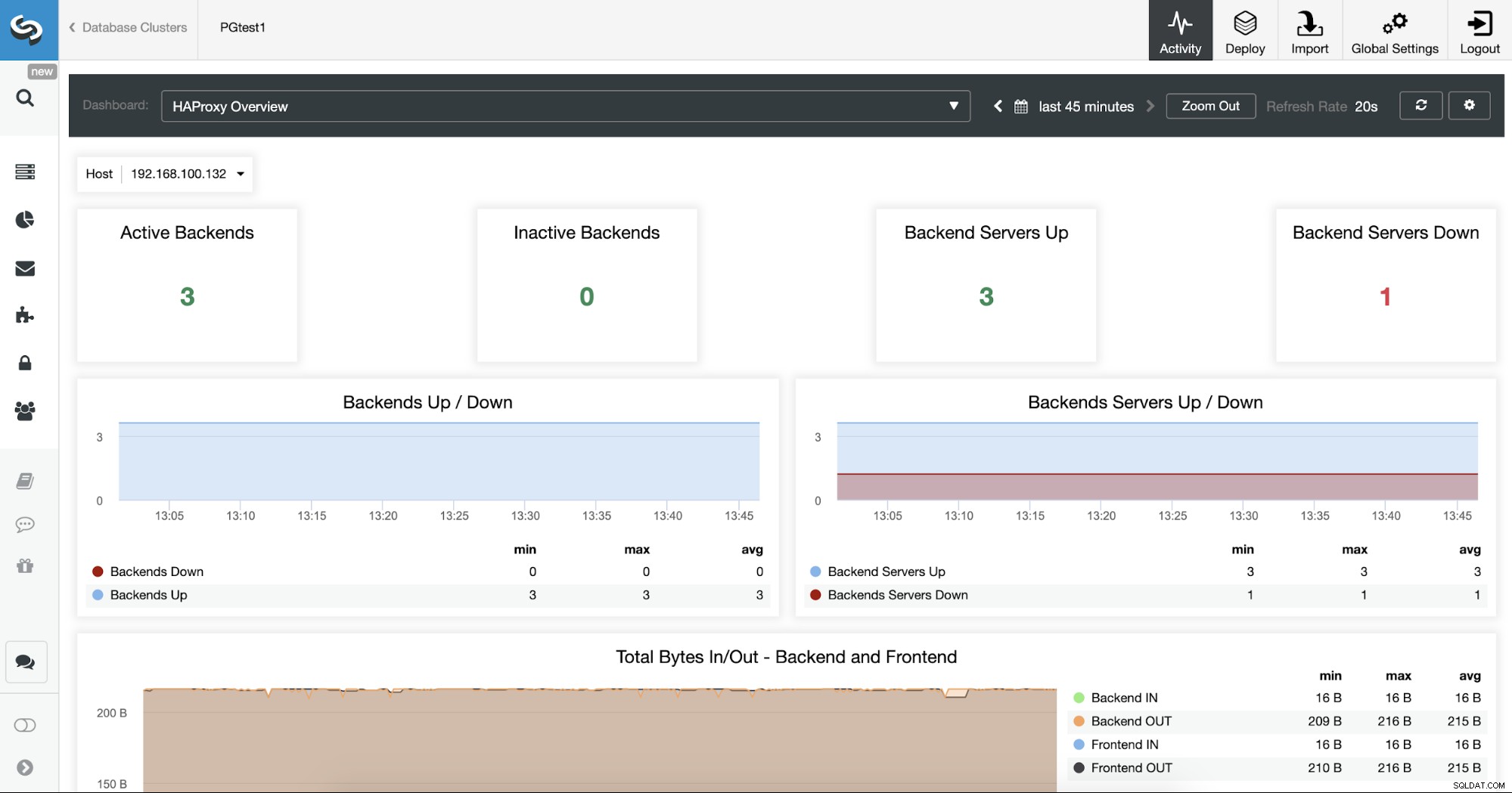
Jetzt können Sie Ihr HA-Design verbessern, indem Sie einen neuen HAProxy-Knoten in hinzufügen Remote-Rechenzentrum und Konfigurieren des Keepalived-Dienstes zwischen ihnen. Mit Keepalived können Sie eine virtuelle IP-Adresse verwenden, die dem aktiven Load Balancer-Knoten zugewiesen ist. Wenn dieser Knoten ausfällt, wird diese virtuelle IP auf den sekundären HAProxy-Knoten migriert, sodass Sie durch die Konfiguration dieser IP in Ihrer Anwendung im Falle eines Load Balancer-Problems alles am Laufen halten können.
All diese Konfiguration kann mit ClusterControl durchgeführt werden.
Fazit
Indem Sie diesem zweiteiligen Blog folgen, können Sie ein Setup für mehrere Rechenzentren für PostgreSQL mit hoher Verfügbarkeit und SSH-Konnektivität zwischen den Rechenzentren implementieren, um die Komplexität einer VPN-Konfiguration zu vermeiden.
Durch die asynchrone Replikation für den Remote-Knoten vermeiden Sie Probleme im Zusammenhang mit Latenz und Netzwerkleistung, und mit ClusterControl haben Sie im Falle eines Ausfalls (neben anderen Funktionen) ein automatisches (oder manuelles) Failover. Dies könnte der einfachste Weg sein, um diese Topologie zu erreichen, und wir hoffen, dass dies für Sie nützlich ist.