Amazon Aurora Serverless bietet eine bedarfsgesteuerte, automatisch skalierbare, hochverfügbare, relationale Datenbank, die Ihnen nur dann in Rechnung gestellt wird, wenn sie verwendet wird. Es bietet eine relativ einfache, kostengünstige Option für seltene, intermittierende oder unvorhersehbare Workloads. Möglich wird dies dadurch, dass es automatisch startet, die Rechenkapazität an die Nutzung Ihrer Anwendung anpasst und dann heruntergefahren wird, wenn es nicht mehr benötigt wird.
Das folgende Diagramm zeigt die Architektur von Aurora Serverless auf hoher Ebene.
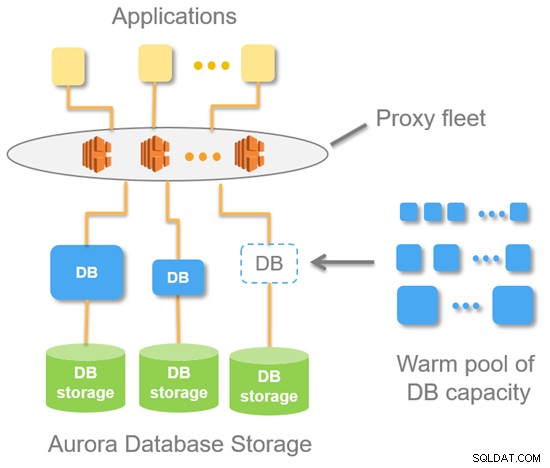
Mit Aurora Serverless erhalten Sie einen Endpunkt (im Gegensatz zu zwei Endpunkten für die von Aurora bereitgestellte Standarddatenbank). Dies ist im Grunde ein DNS-Eintrag, der aus einer Flotte von Proxys besteht, die auf der Datenbankinstanz sitzen. Aus Sicht eines MySQL-Servers bedeutet dies, dass die Verbindungen immer von der Proxy-Flotte kommen.
Aurora Serverless Auto-Scaling
Aurora Serverless ist derzeit nur für MySQL 5.6 verfügbar. Grundsätzlich müssen Sie die minimale und maximale Kapazitätseinheit für das DB-Cluster festlegen. Jede Kapazitätseinheit entspricht einer bestimmten Rechen- und Speicherkonfiguration. Aurora Serverless reduziert die Ressourcen für den DB-Cluster, wenn seine Arbeitslast unter diesen Schwellenwerten liegt. Aurora Serverless kann die Kapazität auf das Minimum reduzieren oder die Kapazität auf die maximale Kapazitätseinheit erhöhen.
Der Cluster wird automatisch hochskaliert, wenn eine der folgenden Bedingungen erfüllt ist:
- Die CPU-Auslastung beträgt über 70 % ODER
- Mehr als 90 % der Verbindungen werden verwendet
Der Cluster wird automatisch herunterskaliert, wenn die beiden folgenden Bedingungen erfüllt sind:
- Die CPU-Auslastung fällt unter 30 % UND
- Weniger als 40 % der Verbindungen werden verwendet.
Einige der bemerkenswerten Dinge, die Sie über den automatischen Skalierungsfluss von Aurora wissen sollten:
- Es wird nur hochskaliert, wenn es Leistungsprobleme erkennt, die durch Hochskalieren behoben werden können.
- Nach dem Hochskalieren beträgt die Abklingzeit für das Herunterskalieren 15 Minuten.
- Nach dem Herunterskalieren beträgt die Abklingzeit für das nächste erneute Herunterskalieren 310 Sekunden.
- Die Kapazität wird auf Null skaliert, wenn für einen Zeitraum von 5 Minuten keine Verbindungen bestehen.
Standardmäßig führt Aurora Serverless die automatische Skalierung nahtlos durch, ohne aktive Datenbankverbindungen zum Server zu unterbrechen. Es ist in der Lage, einen Skalierungspunkt zu bestimmen (einen Zeitpunkt, an dem die Datenbank die Skalierungsoperation sicher einleiten kann). Unter den folgenden Bedingungen kann Aurora Serverless jedoch möglicherweise keinen Skalierungspunkt finden:
- Lang andauernde Abfragen oder Transaktionen sind in Bearbeitung.
- Temporäre Tabellen oder Tabellensperren werden verwendet.
Wenn einer der oben genannten Fälle eintritt, versucht Aurora Serverless weiterhin, einen Skalierungspunkt zu finden, damit es den Skalierungsvorgang einleiten kann (es sei denn, „Force Scaling“ ist aktiviert). Er tut dies so lange, wie er feststellt, dass der DB-Cluster skaliert werden soll.
Beobachtung des Verhaltens von Aurora Auto Scaling
Beachten Sie, dass in Aurora Serverless nur eine kleine Anzahl von Parametern geändert werden kann und max_connections keiner davon ist. Für alle anderen Konfigurationsparameter verwenden Aurora MySQL Serverless-Cluster die Standardwerte. Für max_connections wird es dynamisch von Aurora Serverless mithilfe der folgenden Formel gesteuert:
max_connections =GREATEST({log(DBInstanceClassMemory/805306368)*45},{log(DBInstanceClassMemory/8187281408)*1000})
Wobei log log2 ist (log base-2) und „DBInstanceClassMemory“ ist die Anzahl der Speicherbytes, die der DB-Instance-Klasse zugeordnet sind, die der aktuellen DB-Instance zugeordnet ist, abzüglich des Speichers, der von den Amazon RDS-Prozessen verwendet wird, die die Instance verwalten. Es ist ziemlich schwierig, den Wert, den Aurora verwenden wird, im Voraus zu bestimmen, daher ist es gut, einige Tests durchzuführen, um zu verstehen, wie dieser Wert entsprechend skaliert wird.
Hier ist unsere Aurora Serverless-Bereitstellungszusammenfassung für diesen Test:
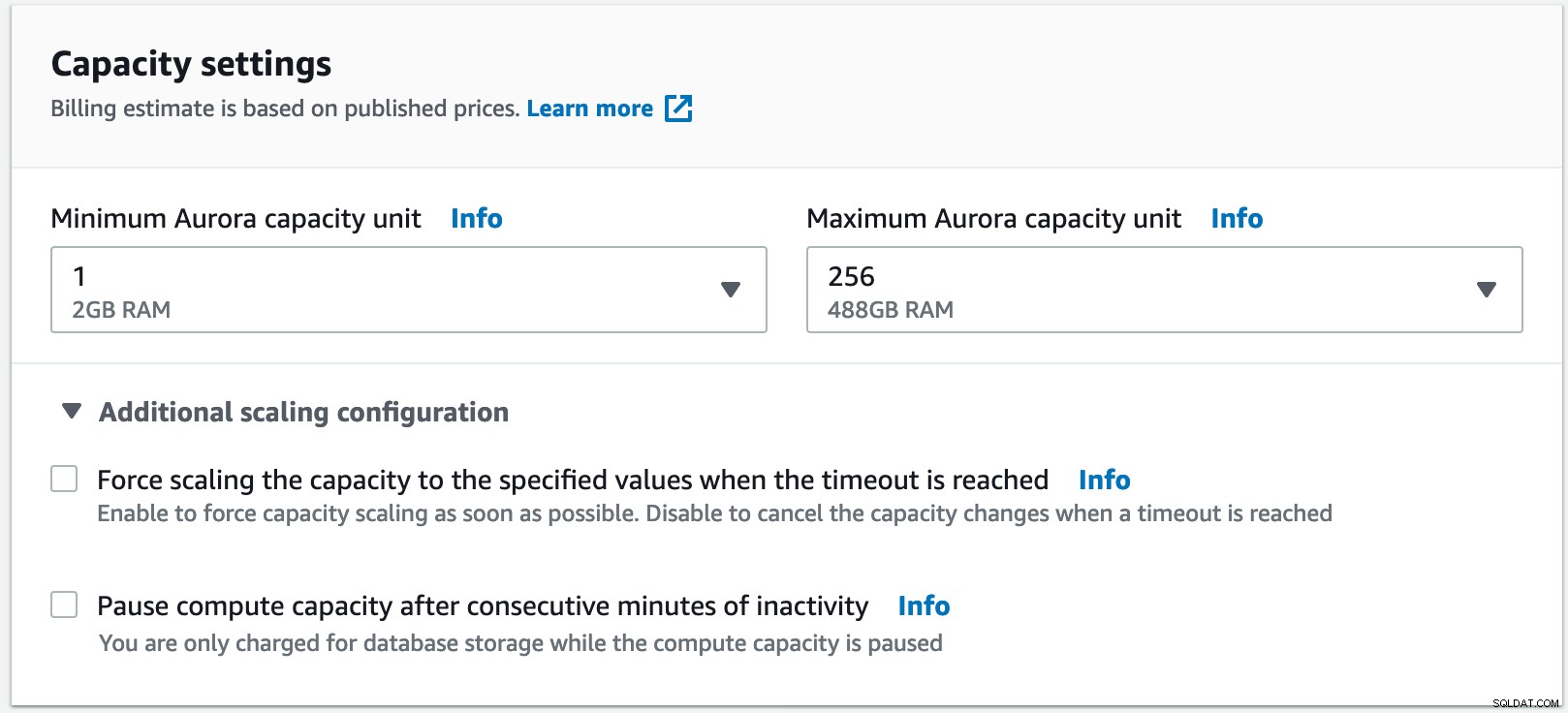
Für dieses Beispiel habe ich mindestens 1 Aurora-Kapazitätseinheit ausgewählt, was 2 GB RAM entspricht, bis maximal 256 Kapazitätseinheit mit 488 GB RAM.
Die Tests wurden mit Sysbench durchgeführt, indem einfach mehrere Threads gesendet wurden, bis das Limit der MySQL-Datenbankverbindungen erreicht wurde. Unser erster Versuch, 128 gleichzeitige Datenbankverbindungen auf einmal zu senden, schlug direkt fehl:
$ sysbench \
/usr/share/sysbench/oltp_read_write.lua \
--report-interval=2 \
--threads=128 \
--delete_inserts=5 \
--time=360 \
--max-requests=0 \
--db-driver=mysql \
--db-ps-mode=disable \
--mysql-host=${_HOST} \
--mysql-user=sbtest \
--mysql-db=sbtest \
--mysql-password=password \
--tables=20 \
--table-size=100000 \
runDer obige Befehl hat sofort den Fehler „Zu viele Verbindungen“ zurückgegeben:
FATAL: unable to connect to MySQL server on host 'aurora-sysbench.cluster-cdw9q2wnb00s.ap-southeast-1.rds.amazonaws.com', port 3306, aborting...
FATAL: error 1040: Too many connectionsWenn wir uns die max_connection-Einstellungen ansehen, erhalten wir Folgendes:
mysql> SELECT @@hostname, @@max_connections;
+----------------+-------------------+
| @@hostname | @@max_connections |
+----------------+-------------------+
| ip-10-2-56-105 | 90 |
+----------------+-------------------+Es stellt sich heraus, dass der Startwert von max_connections für unsere Aurora-Instance mit einer DB-Kapazität (2 GB RAM) 90 beträgt. Dies ist tatsächlich viel niedriger als unser erwarteter Wert, wenn er mit der bereitgestellten Formel zur Schätzung der berechnet wird max_connections-Wert:
mysql> SELECT GREATEST({log2(2147483648/805306368)*45},{log2(2147483648/8187281408)*1000});
+------------------------------------------------------------------------------+
| GREATEST({log2(2147483648/805306368)*45},{log2(2147483648/8187281408)*1000}) |
+------------------------------------------------------------------------------+
| 262.2951 |
+------------------------------------------------------------------------------+Das bedeutet einfach, dass der DBInstanceClassMemory nicht gleich dem tatsächlichen Speicher für die Aurora-Instance ist. Es muss viel niedriger sein. Laut diesem Diskussionsthread wird der Wert der Variablen angepasst, um den Speicher zu berücksichtigen, der bereits für Betriebssystemdienste und den RDS-Management-Daemon verwendet wird.
Dennoch hilft uns auch das Ändern des Standardwerts max_connections auf einen höheren Wert nicht, da dieser Wert dynamisch vom Aurora Serverless-Cluster gesteuert wird. Daher mussten wir den Sysbench-Wert für Startthreads auf 84 reduzieren, da interne Aurora-Threads bereits etwa 4 bis 5 Verbindungen über 'rdsadmin'@'localhost' reserviert haben. Außerdem benötigen wir eine zusätzliche Verbindung für unsere Verwaltungs- und Überwachungszwecke.
Also haben wir stattdessen den folgenden Befehl ausgeführt (mit --threads=84):
$ sysbench \
/usr/share/sysbench/oltp_read_write.lua \
--report-interval=2 \
--threads=84 \
--delete_inserts=5 \
--time=600 \
--max-requests=0 \
--db-driver=mysql \
--db-ps-mode=disable \
--mysql-host=${_HOST} \
--mysql-user=sbtest \
--mysql-db=sbtest \
--mysql-password=password \
--tables=20 \
--table-size=100000 \
runNachdem der obige Test in 10 Minuten abgeschlossen war (--time=600), führten wir denselben Befehl erneut aus und zu diesem Zeitpunkt hatten sich einige der bemerkenswerten Variablen und der Status wie unten gezeigt geändert:
mysql> SELECT @@hostname AS hostname, @@max_connections AS max_connections,
(SELECT VARIABLE_VALUE FROM global_status WHERE VARIABLE_NAME = 'THREADS_CONNECTED') AS threads_connected,
(SELECT VARIABLE_VALUE FROM global_status WHERE VARIABLE_NAME = 'UPTIME') AS uptime;
+--------------+-----------------+-------------------+--------+
| hostname | max_connections | threads_connected | uptime |
+--------------+-----------------+-------------------+--------+
| ip-10-2-34-7 | 180 | 179 | 157 |
+--------------+-----------------+-------------------+--------+Beachten Sie, dass sich die max_connections jetzt auf 180 verdoppelt hat, mit einem anderen Hostnamen und einer geringen Betriebszeit, als ob der Server gerade erst gestartet wurde. Aus Sicht der Anwendung sieht es so aus, als hätte eine andere "größere Datenbankinstanz" den Endpunkt übernommen und mit einer anderen max_connections-Variablen konfiguriert. Beim Aurora-Ereignis ist Folgendes passiert:
Wed, 04 Sep 2019 08:50:56 GMT The DB cluster has scaled from 1 capacity unit to 2 capacity units.Dann haben wir denselben sysbench-Befehl gestartet und weitere 84 Verbindungen zum Datenbank-Endpunkt erstellt. Nach Abschluss des generierten Belastungstests skaliert der Server automatisch auf eine Kapazität von 4 DB, wie unten gezeigt:
mysql> SELECT @@hostname AS hostname, @@max_connections AS max_connections,
(SELECT VARIABLE_VALUE FROM global_status WHERE VARIABLE_NAME = 'THREADS_CONNECTED') AS threads_connected,
(SELECT VARIABLE_VALUE FROM global_status WHERE VARIABLE_NAME = 'UPTIME') AS uptime;
+---------------+-----------------+-------------------+--------+
| hostname | max_connections | threads_connected | uptime |
+---------------+-----------------+-------------------+--------+
| ip-10-2-12-75 | 270 | 6 | 300 |
+---------------+-----------------+-------------------+--------+Sie können dies anhand des unterschiedlichen Werts für Hostname, max_connection und Betriebszeit im Vergleich zum vorherigen erkennen. Eine andere größere Instanz hat die Rolle der vorherigen Instanz „übernommen“, bei der die DB-Kapazität gleich 2 war. Der eigentliche Skalierungspunkt ist, wenn die Serverlast abfällt und fast den Boden erreicht. Hälten wir in unserem Test die Verbindung voll und die Datenbanklast konstant hoch, fand keine automatische Skalierung statt.
Wenn wir uns die beiden Screenshots unten ansehen, können wir feststellen, dass die Skalierung nur erfolgt, wenn unser Sysbench seinen Belastungstest für 600 Sekunden abgeschlossen hat, da dies der sicherste Punkt für die Durchführung der automatischen Skalierung ist.
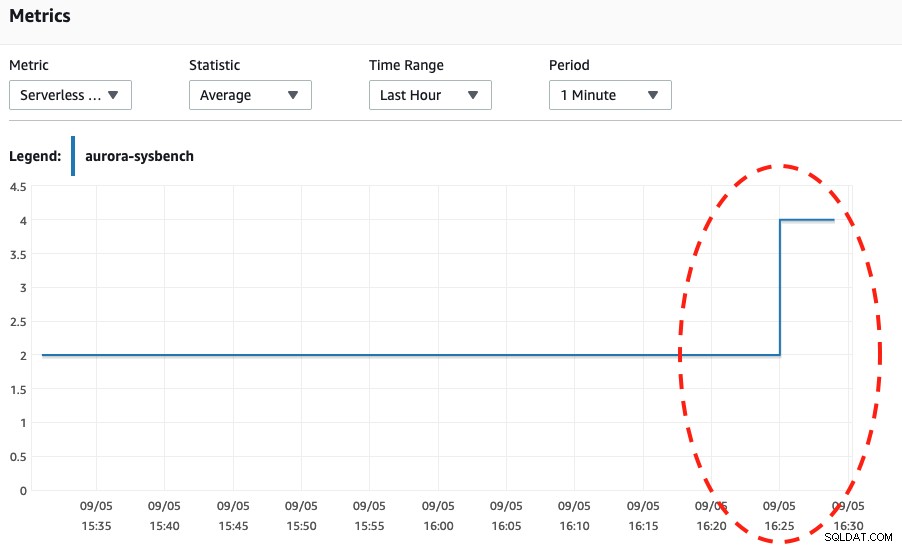 Serverlose DB-Kapazität CPU-Auslastung
Serverlose DB-Kapazität CPU-Auslastung 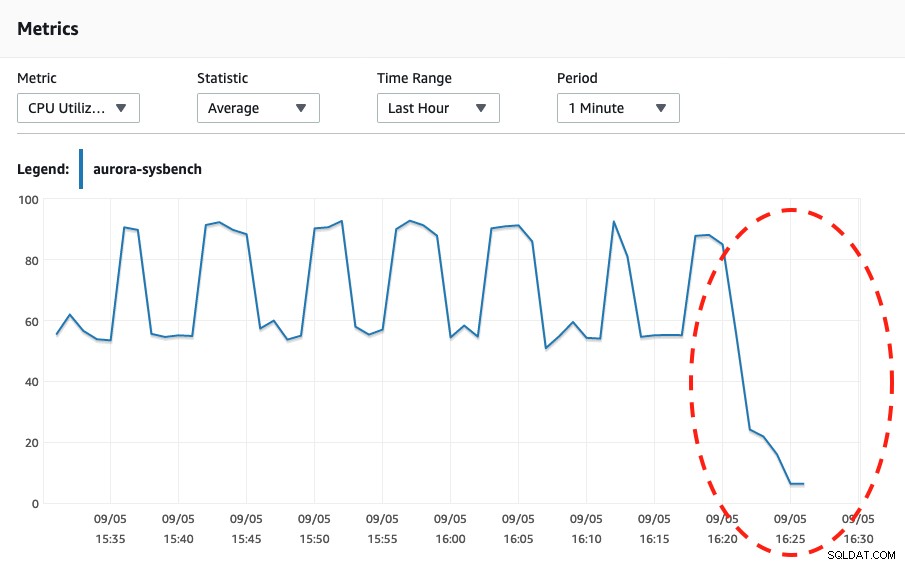 CPU-Auslastung
CPU-Auslastung Bei Betrachtung der Aurora-Ereignisse sind die folgenden Ereignisse aufgetreten:
Wed, 04 Sep 2019 16:25:00 GMT Scaling DB cluster from 4 capacity units to 2 capacity units for this reason: Autoscaling.
Wed, 04 Sep 2019 16:25:05 GMT The DB cluster has scaled from 4 capacity units to 2 capacity units.Schließlich haben wir viel mehr Verbindungen bis fast 270 generiert und warten bis es fertig ist, um in die Kapazität von 8 DB zu kommen:
mysql> SELECT @@hostname as hostname, @@max_connections AS max_connections,
(SELECT VARIABLE_VALUE FROM global_status WHERE VARIABLE_NAME = 'THREADS_CONNECTED') AS threads_connected,
(SELECT VARIABLE_VALUE FROM global_status WHERE VARIABLE_NAME = 'UPTIME') AS uptime;
+---------------+-----------------+-------------------+--------+
| hostname | max_connections | threads_connected | uptime |
+---------------+-----------------+-------------------+--------+
| ip-10-2-72-12 | 1000 | 144 | 230 |
+---------------+-----------------+-------------------+--------+In der Instanz mit 8 Kapazitätseinheiten ist der MySQL-max_connections-Wert jetzt 1000. Wir haben ähnliche Schritte wiederholt, indem wir die Datenbankverbindungen bis zum Limit von 256 Kapazitätseinheiten maximiert haben. Die folgende Tabelle fasst die gesamte DB-Kapazitätseinheit im Vergleich zum max_connections-Wert in unseren Tests bis zur maximalen DB-Kapazität zusammen:
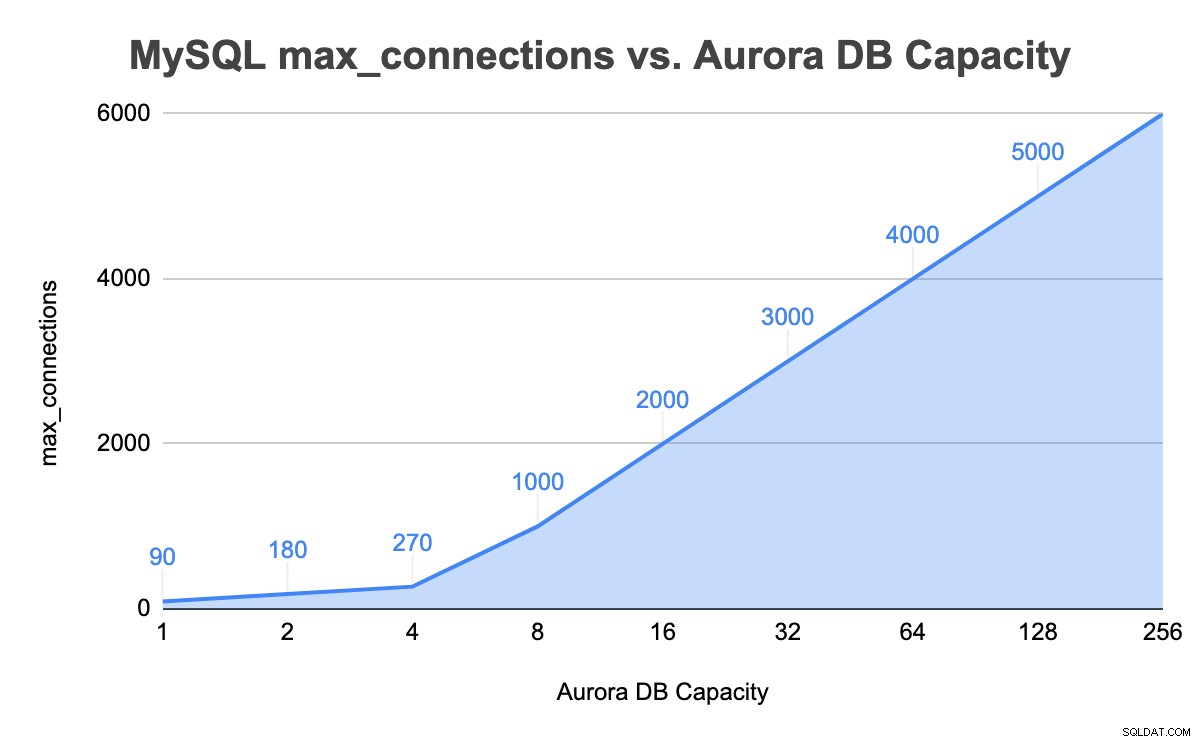
Erzwungene Skalierung
Wie oben erwähnt, führt Aurora Serverless nur dann eine automatische Skalierung durch, wenn dies sicher ist. Der Benutzer hat jedoch die Möglichkeit, die Skalierung der DB-Kapazität sofort zu erzwingen, indem er das Kontrollkästchen Skalierung erzwingen unter der Option „Zusätzliche Skalierungskonfiguration“ aktiviert:
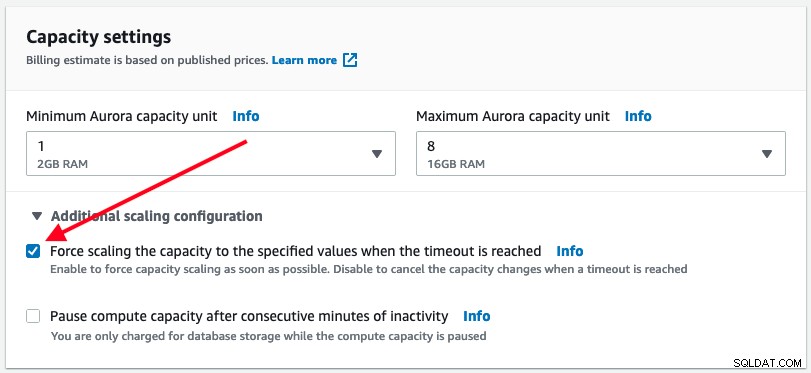
Wenn die erzwungene Skalierung aktiviert ist, erfolgt die Skalierung, sobald das Timeout abgelaufen ist erreicht, das sind 300 Sekunden. Dieses Verhalten kann zu einer Datenbankunterbrechung Ihrer Anwendung führen, bei der aktive Verbindungen zur Datenbank unterbrochen werden können. Wir haben den folgenden Fehler beobachtet, als die automatische Skalierung erzwungen wurde, nachdem das Timeout erreicht wurde:
FATAL: mysql_drv_query() returned error 1105 (The last transaction was aborted due to an unknown error. Please retry.) for query 'SELECT c FROM sbtest19 WHERE id=52824'
FATAL: `thread_run' function failed: /usr/share/sysbench/oltp_common.lua:419: SQL error, errno = 1105, state = 'HY000': The last transaction was aborted due to an unknown error. Please retry.Das Obige bedeutet einfach, dass Aurora Serverless, anstatt den richtigen Zeitpunkt zum Hochskalieren zu finden, die Instanzersetzung erzwingt, unmittelbar nach Erreichen ihrer Zeitüberschreitung zu erfolgen, was dazu führt, dass Transaktionen abgebrochen und rückgängig gemacht werden. Wenn Sie die abgebrochene Abfrage zum zweiten Mal wiederholen, wird das Problem wahrscheinlich behoben. Diese Konfiguration kann verwendet werden, wenn Ihre Anwendung gegenüber Verbindungsunterbrechungen widerstandsfähig ist.
Zusammenfassung
Amazon Aurora Serverless Auto Scaling ist eine vertikale Skalierungslösung, bei der eine leistungsstärkere Instance eine minderwertige Instance übernimmt und die zugrunde liegende Aurora-Shared-Storage-Technologie effizient nutzt. Standardmäßig wird die automatische Skalierung nahtlos durchgeführt, wobei Aurora einen sicheren Skalierungspunkt findet, um den Instanzwechsel durchzuführen. Man hat die Möglichkeit, die automatische Skalierung zu erzwingen, wobei das Risiko besteht, dass aktive Datenbankverbindungen unterbrochen werden.