Replikationsverzögerungsprobleme in PostgreSQL sind bei den meisten Setups kein weit verbreitetes Problem. Es kann jedoch vorkommen, und wenn dies der Fall ist, kann es sich auf Ihre Produktionseinrichtungen auswirken. PostgreSQL wurde entwickelt, um mehrere Threads zu verarbeiten, wie z. B. Abfrageparallelität oder das Bereitstellen von Worker-Threads, um bestimmte Aufgaben basierend auf den zugewiesenen Werten in der Konfiguration zu erledigen. PostgreSQL ist darauf ausgelegt, schwere und stressige Lasten zu bewältigen, aber manchmal (aufgrund einer schlechten Konfiguration) könnte Ihr Server trotzdem den Bach runtergehen.
Das Identifizieren der Replikationsverzögerung in PostgreSQL ist keine komplizierte Aufgabe, aber es gibt ein paar verschiedene Ansätze, um das Problem zu untersuchen. In diesem Blog werfen wir einen Blick darauf, worauf Sie achten sollten, wenn Ihre PostgreSQL-Replikation verzögert wird.
Replikationstypen in PostgreSQL
Bevor wir in das Thema eintauchen, sehen wir uns zunächst an, wie sich die Replikation in PostgreSQL entwickelt, da es verschiedene Ansätze und Lösungen im Umgang mit der Replikation gibt.
Warm-Standby für PostgreSQL wurde in Version 8.2 (damals 2006) implementiert und basierte auf der Protokollversandmethode. Das bedeutet, dass die WAL-Einträge direkt von einem Datenbankserver auf einen anderen verschoben werden, um angewendet zu werden, oder einfach ein analoger Ansatz zu PITR, oder sehr ähnlich wie Sie es mit rsync tun.
Dieser Ansatz, auch wenn er alt ist, wird heute noch verwendet, und einige Institutionen bevorzugen tatsächlich diesen älteren Ansatz. Dieser Ansatz implementiert einen dateibasierten Protokollversand, indem WAL-Datensätze einzeln (WAL-Segment) übertragen werden. Obwohl es einen Nachteil hat; Bei einem größeren Ausfall auf den primären Servern gehen noch nicht versendete Transaktionen verloren. Es gibt ein Fenster für Datenverlust (Sie können dies mit dem Parameter archive_timeout einstellen, der auf wenige Sekunden eingestellt werden kann, aber eine so niedrige Einstellung erhöht die für den Dateiversand erforderliche Bandbreite erheblich).
In PostgreSQL-Version 9.0 wurde die Streaming-Replikation eingeführt. Mit dieser Funktion konnten wir im Vergleich zum dateibasierten Protokollversand aktueller bleiben. Sein Ansatz besteht darin, WAL-Datensätze (eine WAL-Datei besteht aus WAL-Datensätzen) im laufenden Betrieb (lediglich ein datensatzbasierter Protokollversand) zwischen einem Master-Server und einem oder mehreren Standby-Servern zu übertragen. Anders als beim dateibasierten Protokollversand muss dieses Protokoll nicht auf das Füllen der WAL-Datei warten. In der Praxis stellt ein Prozess namens WAL-Empfänger, der auf dem Standby-Server ausgeführt wird, über eine TCP/IP-Verbindung eine Verbindung zum primären Server her. Auf dem primären Server existiert ein weiterer Prozess namens WAL-Sender. Seine Rolle ist für das Senden der WAL-Registrierungen an den/die Standby-Server zuständig, sobald sie auftreten.
Setups für asynchrone Replikation in der Streaming-Replikation können Probleme wie Datenverlust oder Slave-Verzögerung verursachen, daher führt Version 9.1 die synchrone Replikation ein. Bei der synchronen Replikation wartet jeder Commit einer Schreibtransaktion, bis eine Bestätigung empfangen wird, dass der Commit auf die Write-Ahead-Protokollplatte sowohl des Primär- als auch des Standby-Servers geschrieben wurde. Diese Methode minimiert die Möglichkeit eines Datenverlusts, da dazu der Master und der Standby gleichzeitig ausfallen müssen.
Der offensichtliche Nachteil dieser Konfiguration ist, dass die Antwortzeit für jede Schreibtransaktion zunimmt, da wir warten müssen, bis alle Parteien geantwortet haben. Im Gegensatz zu MySQL gibt es keine Unterstützung, z. B. in einer halbsynchronen Umgebung von MySQL, es wird ein Failback auf asynchron durchgeführt, wenn eine Zeitüberschreitung aufgetreten ist. Bei PostgreSQL ist die Zeit für einen Commit also (mindestens) die Hin- und Rückfahrt zwischen dem primären und dem Standby. Nur-Lese-Transaktionen sind davon nicht betroffen.
Während es sich weiterentwickelt, wird PostgreSQL kontinuierlich verbessert und dennoch ist seine Replikation vielfältig. Beispielsweise können Sie die physische asynchrone Streaming-Replikation oder die logische Streaming-Replikation verwenden. Beide werden unterschiedlich überwacht, verwenden jedoch denselben Ansatz, wenn Daten über die Replikation gesendet werden, die immer noch eine Streaming-Replikation ist. Weitere Einzelheiten finden Sie im Handbuch für verschiedene Arten von Lösungen in PostgreSQL, wenn es um die Replikation geht.
Ursachen der PostgreSQL-Replikationsverzögerung
Wie in unserem vorherigen Blog definiert, sind Replikationsverzögerungen die Kosten der Verzögerung für Transaktionen oder Operationen, die anhand der Zeitdifferenz der Ausführung zwischen Primär/Master und Standby/Slave berechnet werden Knoten.
Da PostgreSQL die Streaming-Replikation verwendet, ist es auf Schnelligkeit ausgelegt, da Änderungen als eine Reihe von Protokolldatensätzen (Byte für Byte) aufgezeichnet werden, die vom WAL-Empfänger abgefangen und dann diese Protokolldatensätze geschrieben werden in die WAL-Datei. Dann gibt der Startvorgang von PostgreSQL die Daten aus diesem WAL-Segment wieder und die Streaming-Replikation beginnt. In PostgreSQL kann eine Replikationsverzögerung durch folgende Faktoren auftreten:
- Netzwerkprobleme
- Kann das WAL-Segment von der Primärseite nicht finden. Normalerweise liegt dies an dem Checkpointing-Verhalten, bei dem WAL-Segmente gedreht oder recycelt werden
- Beschäftigte Knoten (primäre und Standby(s)). Kann durch externe Prozesse oder einige fehlerhafte Abfragen verursacht werden, die ressourcenintensiv sind
- Schlechte Hardware oder Hardwareprobleme, die zu Verzögerungen führen
- Schlechte Konfiguration in PostgreSQL, wie z. B. eine kleine Anzahl von max_wal_senders, die gesetzt werden, während Tonnen von Transaktionsanfragen (oder große Mengen an Änderungen) verarbeitet werden.
Worauf Sie bei der PostgreSQL-Replikationsverzögerung achten sollten
Die PostgreSQL-Replikation ist zwar vielfältig, aber die Überwachung des Replikationszustands ist subtil, aber nicht kompliziert. Bei diesem Ansatz, den wir präsentieren, basieren sie auf einer Primär-Standby-Konfiguration mit asynchroner Streaming-Replikation. Die logische Replikation kann in den meisten Fällen, die wir hier besprechen, keinen Nutzen bringen, aber die Ansicht pg_stat_subscription kann Ihnen beim Sammeln von Informationen helfen. Darauf konzentrieren wir uns in diesem Blog jedoch nicht.
Pg_stat_replication-Ansicht verwenden
Der gebräuchlichste Ansatz besteht darin, eine Abfrage auszuführen, die auf diese Ansicht im primären Knoten verweist. Denken Sie daran, dass Sie mit dieser Ansicht nur Informationen vom primären Knoten sammeln können. Diese Ansicht enthält die folgende Tabellendefinition basierend auf PostgreSQL 11, wie unten gezeigt:
postgres=# \d pg_stat_replication
View "pg_catalog.pg_stat_replication"
Column | Type | Collation | Nullable | Default
------------------+--------------------------+-----------+----------+---------
pid | integer | | |
usesysid | oid | | |
usename | name | | |
application_name | text | | |
client_addr | inet | | |
client_hostname | text | | |
client_port | integer | | |
backend_start | timestamp with time zone | | |
backend_xmin | xid | | |
state | text | | |
sent_lsn | pg_lsn | | |
write_lsn | pg_lsn | | |
flush_lsn | pg_lsn | | |
replay_lsn | pg_lsn | | |
write_lag | interval | | |
flush_lag | interval | | |
replay_lag | interval | | |
sync_priority | integer | | |
sync_state | text | | | Wo die Felder definiert sind als (enthält PG <10 Version),
- pid :Prozess-ID des Walsender-Prozesses
- usesysid :OID des Benutzers, der für die Streaming-Replikation verwendet wird.
- Benutzername :Name des Benutzers, der für die Streaming-Replikation verwendet wird
- Anwendungsname :Anwendungsname mit Master verbunden
- client_addr :Adresse der Standby-/Streaming-Replikation
- client_hostname :Hostname des Standby.
- client_port :TCP-Portnummer, auf der Standby mit dem WAL-Sender kommuniziert
- backend_start :Startzeit wenn SR mit Master verbunden ist.
- backend_xmin :xmin-Horizont von Standby, gemeldet von hot_standby_feedback.
- Zustand :Aktueller WAL-Senderstatus, d. h. Streaming
- sent_lsn /gesendeter_Standort :Letzter Transaktionsort, der an Standby gesendet wurde.
- write_lsn /write_location :Letzte Transaktion, die im Standby-Modus auf die Festplatte geschrieben wurde
- flush_lsn /flush_location :Letzte Transaktionslöschung auf der Festplatte im Standby.
- replay_lsn /replay_location :Letzte Transaktionslöschung auf der Festplatte im Standby.
- write_lag :Verstrichene Zeit während festgeschriebener WALs vom primären zum Standby (aber noch nicht festgeschrieben im Standby)
- flush_lag :Verstrichene Zeit während festgeschriebener WALs vom primären zum Standby (WALs wurden bereits geleert, aber noch nicht angewendet)
- replay_lag :Verstrichene Zeit während festgeschriebener WALs vom primären zum Standby-Knoten (vollständig festgeschrieben im Standby-Knoten)
- sync_priority :Priorität des Standby-Servers, der als synchroner Standby ausgewählt wird
- sync_state :Sync-Standby-Status (ist es asynchron oder synchron).
Eine Beispielabfrage würde in PostgreSQL 9.6 wie folgt aussehen,
paultest=# select * from pg_stat_replication;
-[ RECORD 1 ]----+------------------------------
pid | 7174
usesysid | 16385
usename | cmon_replication
application_name | pgsql_1_node_1
client_addr | 192.168.30.30
client_hostname |
client_port | 10580
backend_start | 2020-02-20 18:45:52.892062+00
backend_xmin |
state | streaming
sent_location | 1/9FD5D78
write_location | 1/9FD5D78
flush_location | 1/9FD5D78
replay_location | 1/9FD5D78
sync_priority | 0
sync_state | async
-[ RECORD 2 ]----+------------------------------
pid | 7175
usesysid | 16385
usename | cmon_replication
application_name | pgsql_80_node_2
client_addr | 192.168.30.20
client_hostname |
client_port | 60686
backend_start | 2020-02-20 18:45:52.899446+00
backend_xmin |
state | streaming
sent_location | 1/9FD5D78
write_location | 1/9FD5D78
flush_location | 1/9FD5D78
replay_location | 1/9FD5D78
sync_priority | 0
sync_state | asyncHier erfahren Sie im Wesentlichen, welche Standortblöcke in den WAL-Segmenten geschrieben, geleert oder angewendet wurden. Es bietet Ihnen einen detaillierten Überblick über den Replikationsstatus.
Im Standby-Knoten zu verwendende Abfragen
Im Standby-Knoten gibt es unterstützte Funktionen, für die Sie dies in einer Abfrage abmildern und Ihnen einen Überblick über den Zustand Ihrer Standby-Replikation geben können. Dazu können Sie die folgende Abfrage unten ausführen (Abfrage basiert auf PG-Version> 10),
postgres=# select pg_is_in_recovery(),pg_is_wal_replay_paused(), pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn(), pg_last_xact_replay_timestamp();
-[ RECORD 1 ]-----------------+------------------------------
pg_is_in_recovery | t
pg_is_wal_replay_paused | f
pg_last_wal_receive_lsn | 0/2705BDA0
pg_last_wal_replay_lsn | 0/2705BDA0
pg_last_xact_replay_timestamp | 2020-02-21 02:18:54.603677+00In älteren Versionen können Sie die folgende Abfrage verwenden:
postgres=# select pg_is_in_recovery(),pg_last_xlog_receive_location(), pg_last_xlog_replay_location(), pg_last_xact_replay_timestamp();
-[ RECORD 1 ]-----------------+------------------------------
pg_is_in_recovery | t
pg_last_xlog_receive_location | 1/9FD6490
pg_last_xlog_replay_location | 1/9FD6490
pg_last_xact_replay_timestamp | 2020-02-21 08:32:40.485958-06Was sagt die Abfrage? Funktionen werden hier entsprechend definiert,
- pg_is_in_recovery ():(boolean) Wahr, wenn die Wiederherstellung noch läuft.
- pg_last_wal_receive_lsn ()/pg_last_xlog_receive_location(): (pg_lsn) Der Write-Ahead-Protokollspeicherort, der durch Streaming-Replikation empfangen und mit der Festplatte synchronisiert wurde.
- pg_last_wal_replay_lsn ()/pg_last_xlog_replay_location(): (pg_lsn) Der letzte Write-Ahead-Protokollspeicherort, der während der Wiederherstellung wiedergegeben wurde. Wenn die Wiederherstellung noch im Gange ist, wird dies monoton zunehmen.
- pg_last_xact_replay_timestamp (): (Zeitstempel mit Zeitzone) Abrufen des Zeitstempels der letzten während der Wiederherstellung wiedergegebenen Transaktion.
Mit etwas grundlegender Mathematik können Sie diese Funktionen kombinieren. Die am häufigsten verwendeten Funktionen, die von DBAs verwendet werden, sind
SELECT CASE WHEN pg_last_wal_receive_lsn() = pg_last_wal_replay_lsn()
THEN 0
ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
END AS log_delay;
oder in den Versionen PG <10,
SELECT CASE WHEN pg_last_xlog_receive_location() = pg_last_xlog_replay_location()
THEN 0
ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
END AS log_delay;Obwohl diese Abfrage in der Praxis war und von DBAs verwendet wird. Dennoch bietet es Ihnen keinen genauen Überblick über die Verzögerung. Wieso den? Lassen Sie uns dies im nächsten Abschnitt besprechen.
Identifizieren von Verzögerungen, die durch das Fehlen des WAL-Segments verursacht wurden
PostgreSQL-Standby-Knoten, die sich im Wiederherstellungsmodus befinden, melden Ihnen nicht den genauen Zustand Ihrer Replikation. Nur wenn Sie das PG-Protokoll anzeigen, können Sie Informationen darüber sammeln, was vor sich geht. Es gibt keine Abfrage, die Sie ausführen können, um dies festzustellen. In den meisten Fällen entwickeln Organisationen und sogar kleine Institutionen Software von Drittanbietern, damit sie benachrichtigt werden, wenn ein Alarm ausgelöst wird.
Eines davon ist ClusterControl, das Ihnen Beobachtbarkeit bietet, Warnungen sendet, wenn Alarme ausgelöst werden, oder Ihren Knoten im Falle einer Katastrophe oder Katastrophe wiederherstellt. Nehmen wir dieses Szenario:Mein Primär-Standby-Asynchron-Streaming-Replikationscluster ist fehlgeschlagen. Wie würden Sie wissen, ob etwas nicht stimmt? Lassen Sie uns Folgendes kombinieren:
Schritt 1:Bestimmen Sie, ob es eine Verzögerung gibt
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn() = pg_last_wal_replay_lsn()
postgres-# THEN 0
postgres-# ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
postgres-# END AS log_delay;
-[ RECORD 1 ]
log_delay | 0Schritt 2:Ermitteln Sie die vom Primärknoten empfangenen WAL-Segmente und vergleichen Sie sie mit dem Standby-Knoten
## Get the master's current LSN. Run the query below in the master
postgres=# SELECT pg_current_wal_lsn();
-[ RECORD 1 ]------+-----------
pg_current_wal_lsn | 0/925D7E70Für ältere Versionen von PG <10 verwenden Sie pg_current_xlog_location.
## Get the current WAL segments received (flushed or applied/replayed)
postgres=# select pg_is_in_recovery(),pg_is_wal_replay_paused(), pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn(), pg_last_xact_replay_timestamp();
-[ RECORD 1 ]-----------------+------------------------------
pg_is_in_recovery | t
pg_is_wal_replay_paused | f
pg_last_wal_receive_lsn | 0/2705BDA0
pg_last_wal_replay_lsn | 0/2705BDA0
pg_last_xact_replay_timestamp | 2020-02-21 02:18:54.603677+00Das sieht schlecht aus.
Schritt 3:Ermitteln Sie, wie schlimm es sein könnte
Mischen wir nun die Formel aus Schritt 1 und Schritt 2 und erhalten den Unterschied. Wie das geht, PostgreSQL hat eine Funktion namens pg_wal_lsn_diff, die definiert ist als,
pg_wal_lsn_diff(lsn pg_lsn, lsn pg_lsn) / pg_xlog_location_diff (location pg_lsn, location pg_lsn): (numerisch) Berechnen Sie die Differenz zwischen zwei Write-Ahead-Log-Standorten
Lassen Sie uns nun damit die Verzögerung bestimmen. Sie können es in jedem PG-Knoten ausführen, da wir nur die statischen Werte bereitstellen:
postgres=# select pg_wal_lsn_diff('0/925D7E70','0/2705BDA0'); -[ RECORD 1 ]---+-----------
pg_wal_lsn_diff | 1800913104Lassen Sie uns schätzen, wie viel 1800913104 ist, das scheint etwa 1,6 GiB zu sein, die möglicherweise im Standby-Knoten gefehlt haben,
postgres=# select round(1800913104/pow(1024,3.0),2) missing_lsn_GiB;
-[ RECORD 1 ]---+-----
missing_lsn_gib | 1.68Zuletzt können Sie fortfahren oder sich sogar vor der Abfrage die Protokolle ansehen, z. B. mit tail -5f, um zu verfolgen und zu überprüfen, was los ist. Tun Sie dies für beide Primär-/Standby-Knoten. In diesem Beispiel sehen wir, dass es ein Problem gibt,
## Primary
example@sqldat.com:/var/lib/postgresql/11/main# tail -5f log/postgresql-2020-02-21_033512.log
2020-02-21 16:44:33.574 UTC [25023] ERROR: requested WAL segment 000000030000000000000027 has already been removed
...
## Standby
example@sqldat.com:/var/lib/postgresql/11/main# tail -5f log/postgresql-2020-02-21_014137.log
2020-02-21 16:45:23.599 UTC [26976] LOG: started streaming WAL from primary at 0/27000000 on timeline 3
2020-02-21 16:45:23.599 UTC [26976] FATAL: could not receive data from WAL stream: ERROR: requested WAL segment 000000030000000000000027 has already been removed
...Wenn dieses Problem auftritt, ist es besser, Ihre Standby-Knoten neu zu erstellen. In ClusterControl ist es so einfach wie ein Klick. Gehen Sie einfach zum Abschnitt Knoten/Topologie und erstellen Sie den Knoten wie unten beschrieben neu:
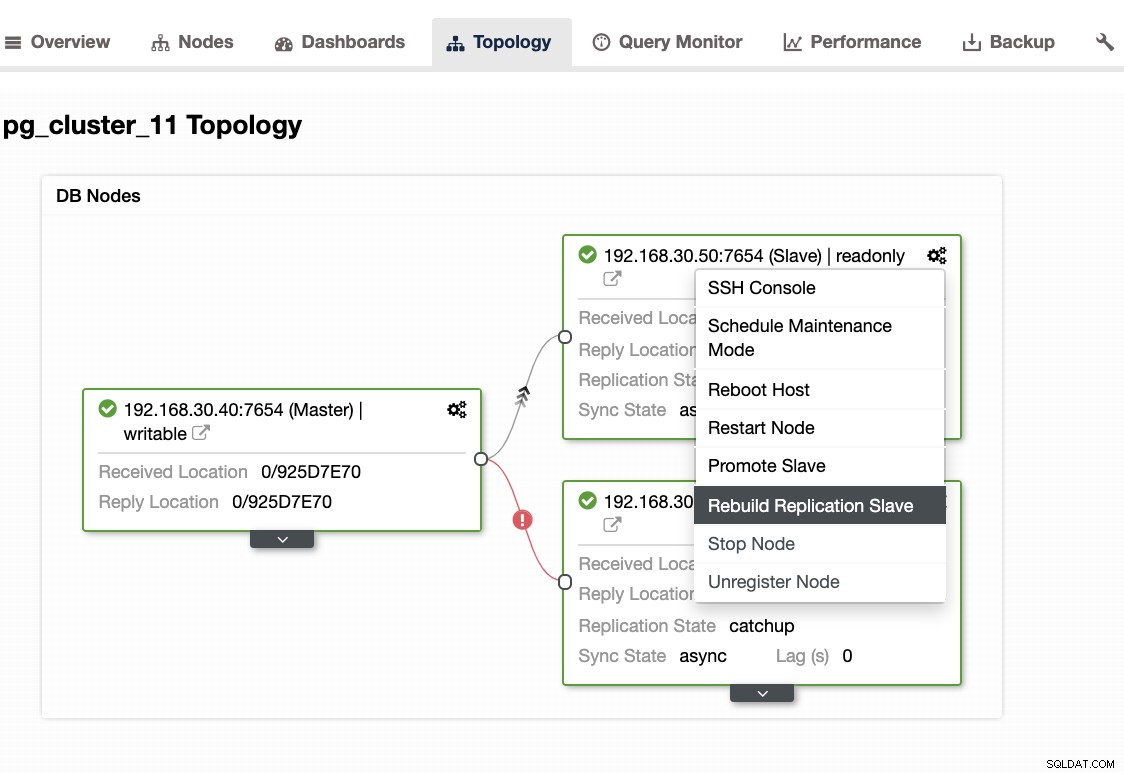
Andere zu überprüfende Dinge
Sie können den gleichen Ansatz in unserem vorherigen Blog (in MySQL) verwenden, indem Sie Systemwerkzeuge wie ps, top, iostat, netstat-Kombination verwenden. Sie können beispielsweise auch das aktuell wiederhergestellte WAL-Segment vom Standby-Knoten abrufen,
example@sqldat.com:/var/lib/postgresql/11/main# ps axufwww|egrep "postgre[s].*startup"
postgres 8065 0.0 8.3 715820 170872 ? Ss 01:41 0:03 \_ postgres: 11/main: startup recovering 000000030000000000000027Wie kann ClusterControl helfen?
ClusterControl bietet eine effiziente Möglichkeit zur Überwachung Ihrer Datenbankknoten von den primären bis zu den Slave-Knoten. Wenn Sie auf die Registerkarte Übersicht gehen, haben Sie bereits die Ansicht Ihres Replikationszustands:
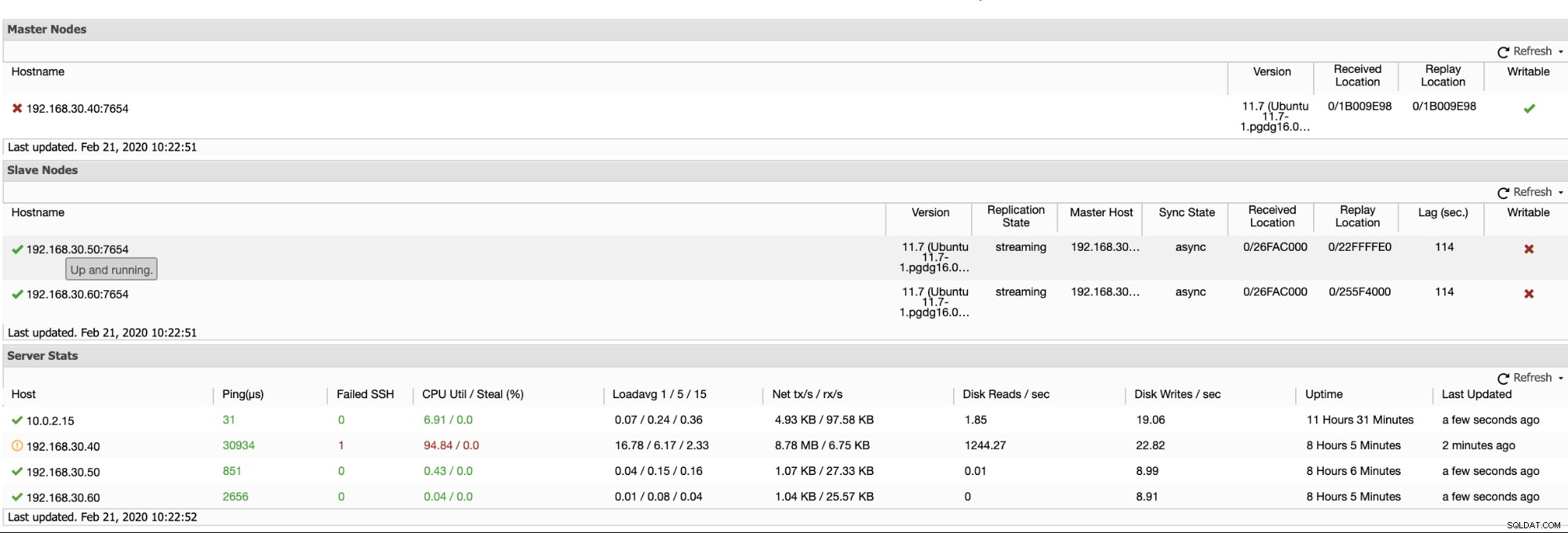
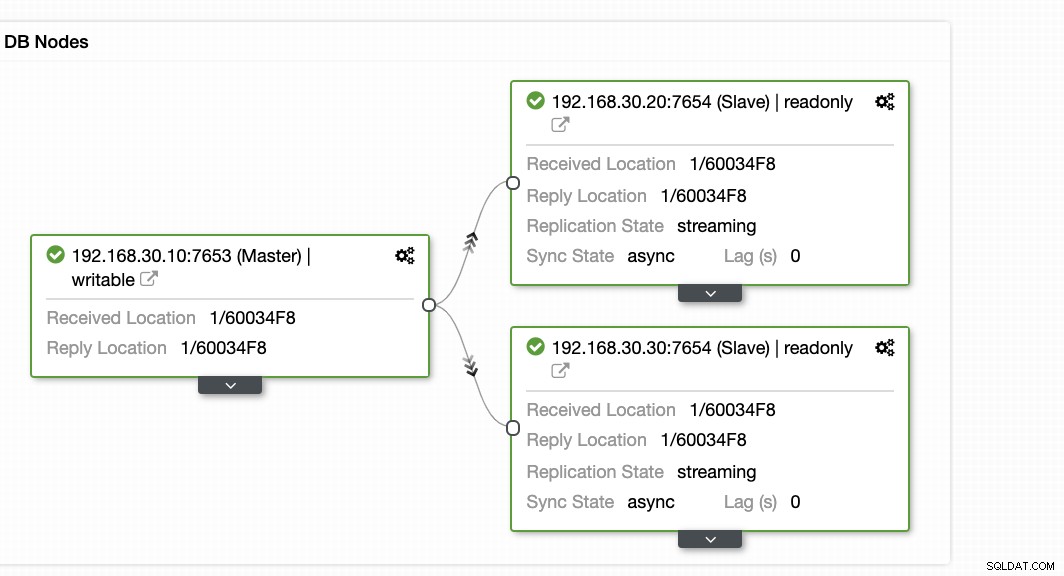
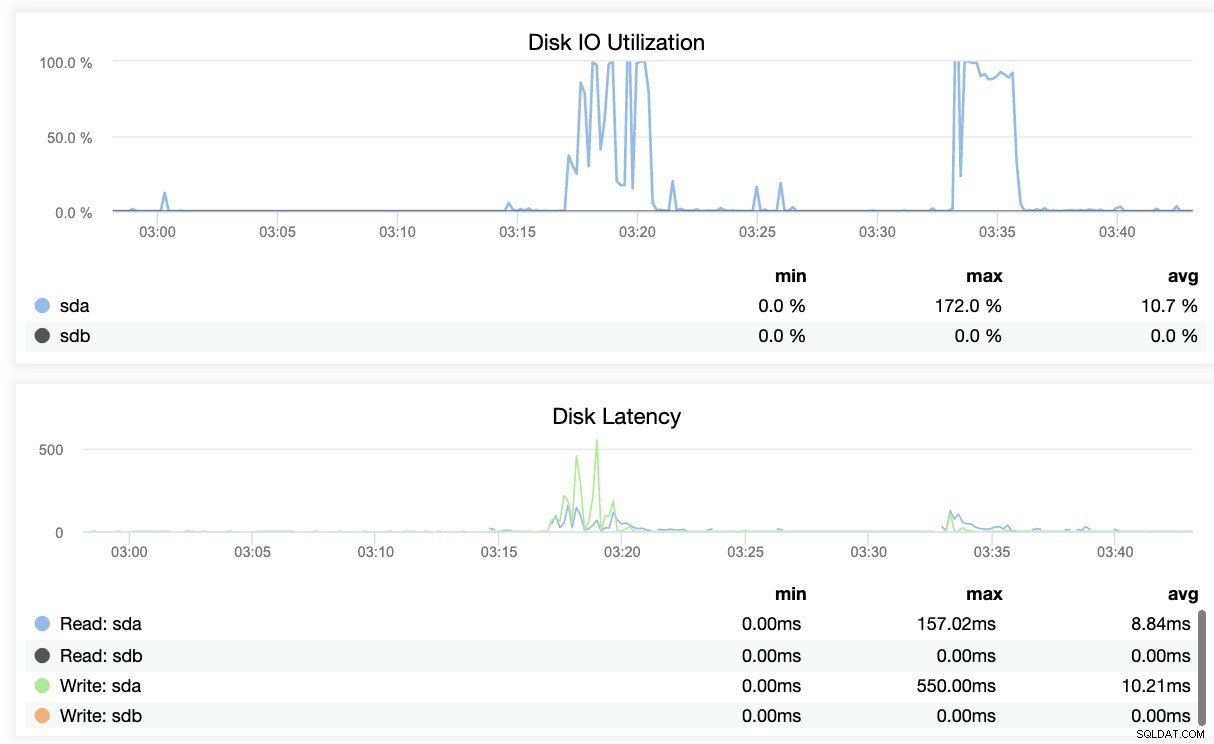
Grundsätzlich zeigen die beiden Screenshots oben, wie die Replikation funktioniert und was aktuell ist WAL-Segmente. Das ist überhaupt nicht. ClusterControl zeigt auch die aktuelle Aktivität Ihres Clusters an.
Fazit
Die Überwachung des Replikationszustands in PostgreSQL kann zu einem anderen Ansatz führen, solange Sie Ihre Anforderungen erfüllen können. Die Verwendung von Tools von Drittanbietern mit Beobachtbarkeit, die Sie im Katastrophenfall benachrichtigen können, ist Ihr perfekter Weg, egal ob Open Source oder Unternehmen. Das Wichtigste ist, dass Sie Ihren Notfallwiederherstellungsplan und die Geschäftskontinuität im Voraus für solche Probleme geplant haben.