Die PostgreSQL-Streaming-Replikation ist eine großartige Möglichkeit, PostgreSQL-Cluster zu skalieren und ihnen dadurch eine hohe Verfügbarkeit zu verleihen. Wie bei jeder Replikation besteht die Idee darin, dass der Slave eine Kopie des Masters ist und dass der Slave ständig mit den Änderungen aktualisiert wird, die auf dem Master aufgetreten sind, indem eine Art Replikationsmechanismus verwendet wird.
Es kann vorkommen, dass der Slave aus irgendeinem Grund nicht mehr mit dem Master synchronisiert ist. Wie kann ich es zurück in die Replikationskette bringen? Wie kann ich sicherstellen, dass der Slave wieder mit dem Master synchron ist? Werfen wir einen Blick in diesen kurzen Blogbeitrag.
Was sehr hilfreich ist, es gibt keine Möglichkeit auf einen Slave zu schreiben wenn er sich im Recovery Modus befindet. Sie können es so testen:
postgres=# SELECT pg_is_in_recovery();
pg_is_in_recovery
-------------------
t
(1 row)
postgres=# CREATE DATABASE mydb;
ERROR: cannot execute CREATE DATABASE in a read-only transactionEs kann immer noch vorkommen, dass der Slave nicht mehr mit dem Master synchronisiert ist. Datenkorruption – weder Hardware noch Software sind ohne Fehler und Probleme. Einige Probleme mit dem Festplattenlaufwerk können eine Datenbeschädigung auf dem Slave auslösen. Einige Probleme mit dem „Vakuum“-Prozess können dazu führen, dass Daten geändert werden. Wie kann man sich von diesem Zustand erholen?
Neuaufbau des Slaves mit pg_basebackup
Der Hauptschritt besteht darin, den Slave mit den Daten des Masters bereitzustellen. Da wir die Streaming-Replikation verwenden, können wir keine logische Sicherung verwenden. Glücklicherweise gibt es ein fertiges Tool, mit dem die Dinge eingerichtet werden können:pg_basebackup. Mal sehen, welche Schritte wir unternehmen müssen, um einen Slave-Server bereitzustellen. Um es deutlich zu machen, verwenden wir PostgreSQL 12 für die Zwecke dieses Blogbeitrags.
Der Anfangszustand ist einfach. Unser Sklave repliziert sich nicht von seinem Meister. Die darin enthaltenen Daten sind beschädigt und können weder verwendet noch vertraut werden. Daher besteht der erste Schritt darin, PostgreSQL auf unserem Slave zu stoppen und die darin enthaltenen Daten zu entfernen:
example@sqldat.com:~# systemctl stop postgresqlOder sogar:
example@sqldat.com:~# killall -9 postgresLassen Sie uns nun den Inhalt der Datei postgresql.auto.conf überprüfen, wir können die in dieser Datei gespeicherten Anmeldeinformationen für die Replikation später für pg_basebackup verwenden:
example@sqldat.com:~# cat /var/lib/postgresql/12/main/postgresql.auto.conf
# Do not edit this file manually!
# It will be overwritten by the ALTER SYSTEM command.
promote_trigger_file='/tmp/failover_5432.trigger'
recovery_target_timeline=latest
primary_conninfo='application_name=pgsql_0_node_1 host=10.0.0.126 port=5432 user=cmon_replication password=qZnVoV7LV97CFX9F'Uns interessiert der Benutzer und das Passwort, die zum Einrichten der Replikation verwendet werden.
Endlich können wir die Daten entfernen:
example@sqldat.com:~# rm -rf /var/lib/postgresql/12/main/*Sobald die Daten entfernt sind, müssen wir pg_basebackup verwenden, um die Daten vom Master abzurufen:
example@sqldat.com:~# pg_basebackup -h 10.0.0.126 -U cmon_replication -Xs -P -R -D /var/lib/postgresql/12/main/
Password:
waiting for checkpointDie verwendeten Flags haben folgende Bedeutung:
- -Xs:Wir möchten WAL streamen, während die Sicherung erstellt wird. Dies hilft, Probleme beim Entfernen von WAL-Dateien zu vermeiden, wenn Sie einen großen Datensatz haben.
- -P: Wir möchten den Fortschritt der Sicherung sehen.
- -R:Wir möchten, dass pg_basebackup die Datei standby.signal erstellt und die Datei postgresql.auto.conf mit Verbindungseinstellungen vorbereitet.
pg_basebackup wartet auf den Prüfpunkt, bevor die Sicherung gestartet wird. Wenn es zu lange dauert, können Sie zwei Optionen verwenden. Erstens ist es möglich, den Checkpoint-Modus in pg_basebackup mit der Option „-c fast“ auf schnell zu setzen. Alternativ können Sie Checkpointing erzwingen, indem Sie Folgendes ausführen:
postgres=# CHECKPOINT;
CHECKPOINTAuf die eine oder andere Weise wird pg_basebackup gestartet. Mit dem Flag -P können wir den Fortschritt verfolgen:
416906/1588478 kB (26%), 0/1 tablespaceceaceSobald die Sicherung fertig ist, müssen wir nur noch sicherstellen, dass dem Inhalt des Datenverzeichnisses der richtige Benutzer und die richtige Gruppe zugewiesen sind - wir haben pg_basebackup als 'root' ausgeführt, daher wollen wir es in 'postgres ':
example@sqldat.com:~# chown -R postgres.postgres /var/lib/postgresql/12/main/Das ist alles, wir können den Slave starten und er sollte mit der Replikation vom Master beginnen.
example@sqldat.com:~# systemctl start postgresqlSie können den Replikationsfortschritt überprüfen, indem Sie die folgende Abfrage auf dem Master ausführen:
postgres=# SELECT * FROM pg_stat_replication;
pid | usesysid | usename | application_name | client_addr | client_hostname | client_port | backend_start | backend_xmin | state | sent_lsn | write_lsn | flush_lsn | replay_lsn | write_lag | flush_lag | replay_lag | sync_priority | sync_state | reply_time
-------+----------+------------------+------------------+-------------+-----------------+-------------+-------------------------------+--------------+-----------+------------+------------+------------+------------+-----------+-----------+------------+---------------+------------+-------------------------------
23565 | 16385 | cmon_replication | pgsql_0_node_1 | 10.0.0.128 | | 51554 | 2020-02-27 15:25:00.002734+00 | | streaming | 2/AA5EF370 | 2/AA5EF2B0 | 2/AA5EF2B0 | 2/AA5EF2B0 | | | | 0 | async | 2020-02-28 13:45:32.594213+00
11914 | 16385 | cmon_replication | 12/main | 10.0.0.127 | | 25058 | 2020-02-28 13:42:09.160576+00 | | streaming | 2/AA5EF370 | 2/AA5EF2B0 | 2/AA5EF2B0 | 2/AA5EF2B0 | | | | 0 | async | 2020-02-28 13:45:42.41722+00
(2 rows)Wie Sie sehen können, replizieren beide Slaves korrekt.
Neuaufbau des Slaves mit ClusterControl
Wenn Sie ein ClusterControl-Benutzer sind, können Sie ganz einfach genau dasselbe erreichen, indem Sie einfach eine Option aus der Benutzeroberfläche auswählen.
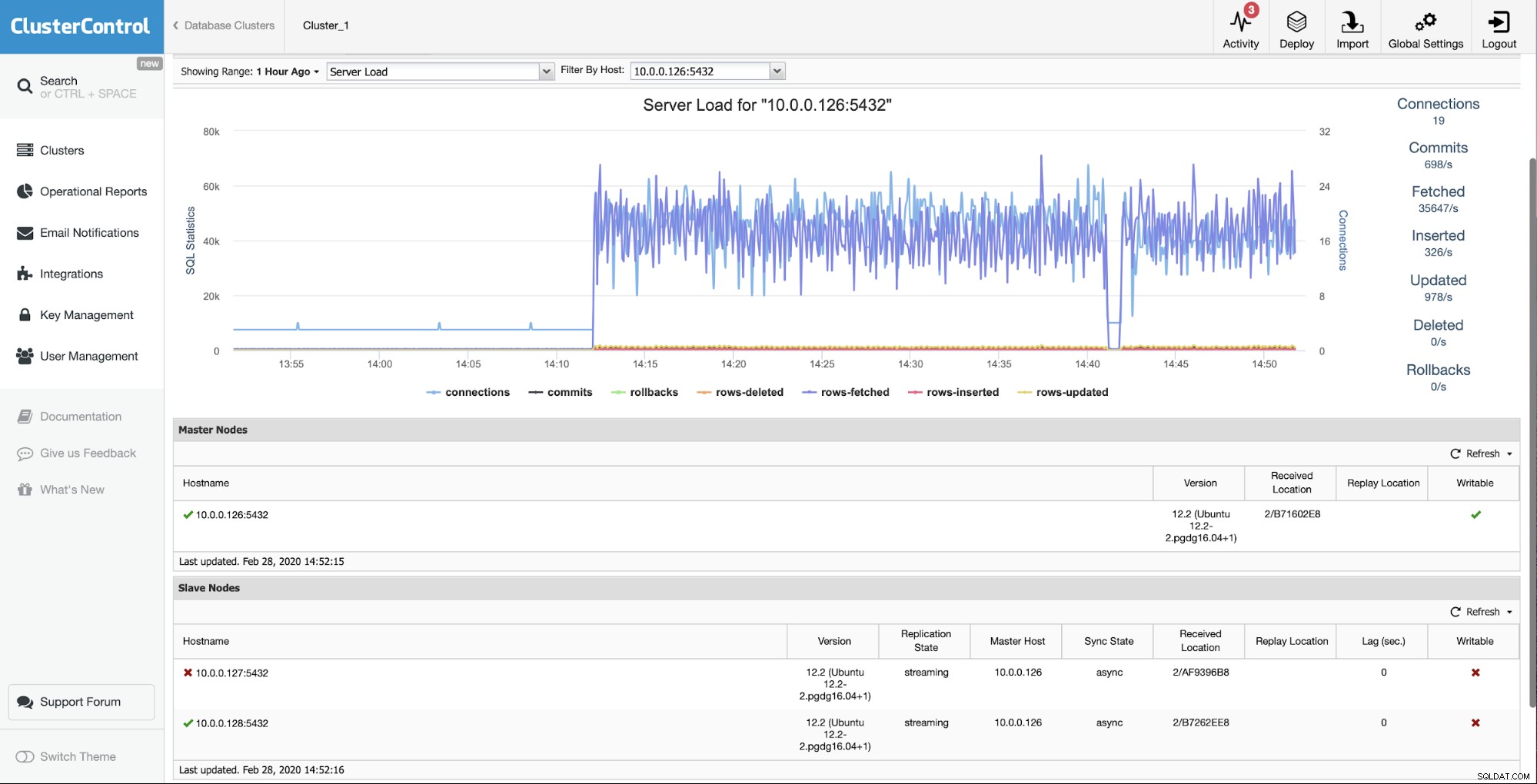
Die Ausgangssituation ist, dass einer der Slaves (10.0.0.127) ist funktioniert nicht und es wird nicht repliziert. Wir hielten den Umbau für die beste Option für uns.
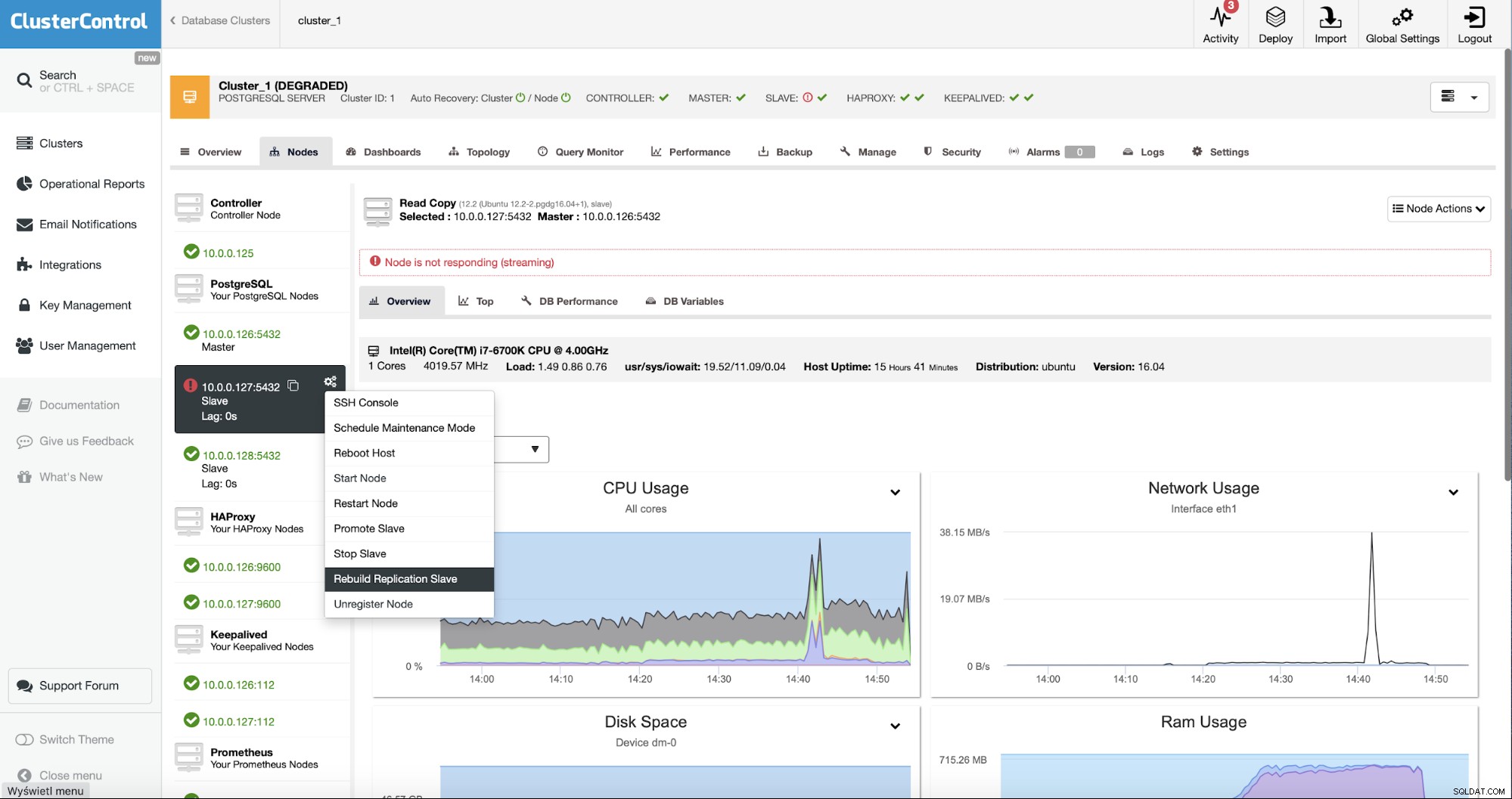
Als ClusterControl-Benutzer müssen wir nur zu den „Nodes ” und führen Sie den Job „Rebuild Replication Slave“ aus.
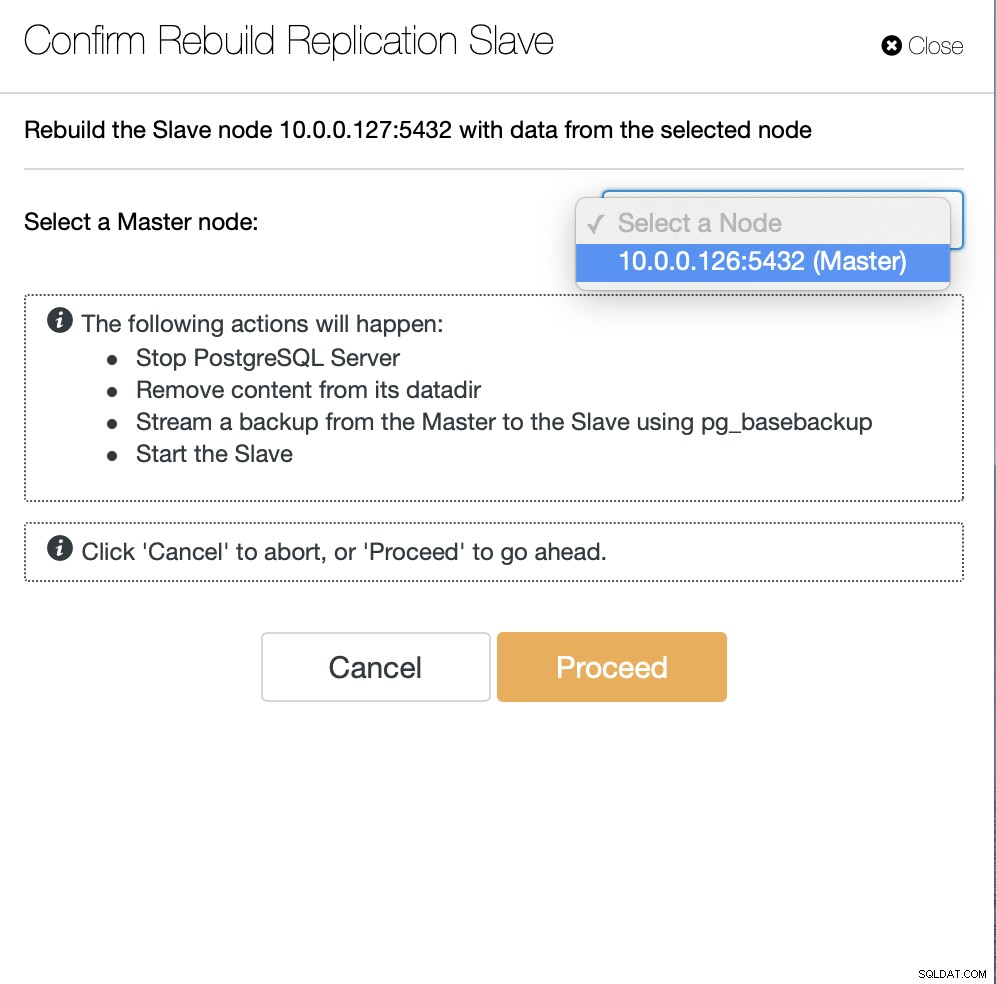
Als Nächstes müssen wir den Knoten auswählen, von dem aus der Slave neu erstellt werden soll, und das ist alles. ClusterControl verwendet pg_basebackup, um den Replikations-Slave einzurichten und die Replikation zu konfigurieren, sobald die Daten übertragen werden.
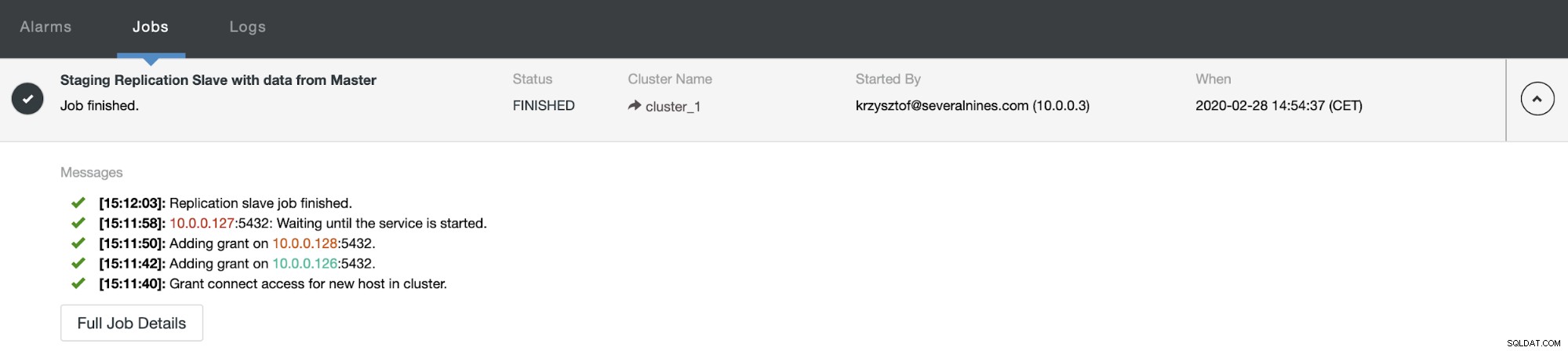
Nach einiger Zeit ist der Job abgeschlossen und der Slave ist wieder in der Replikationskette:
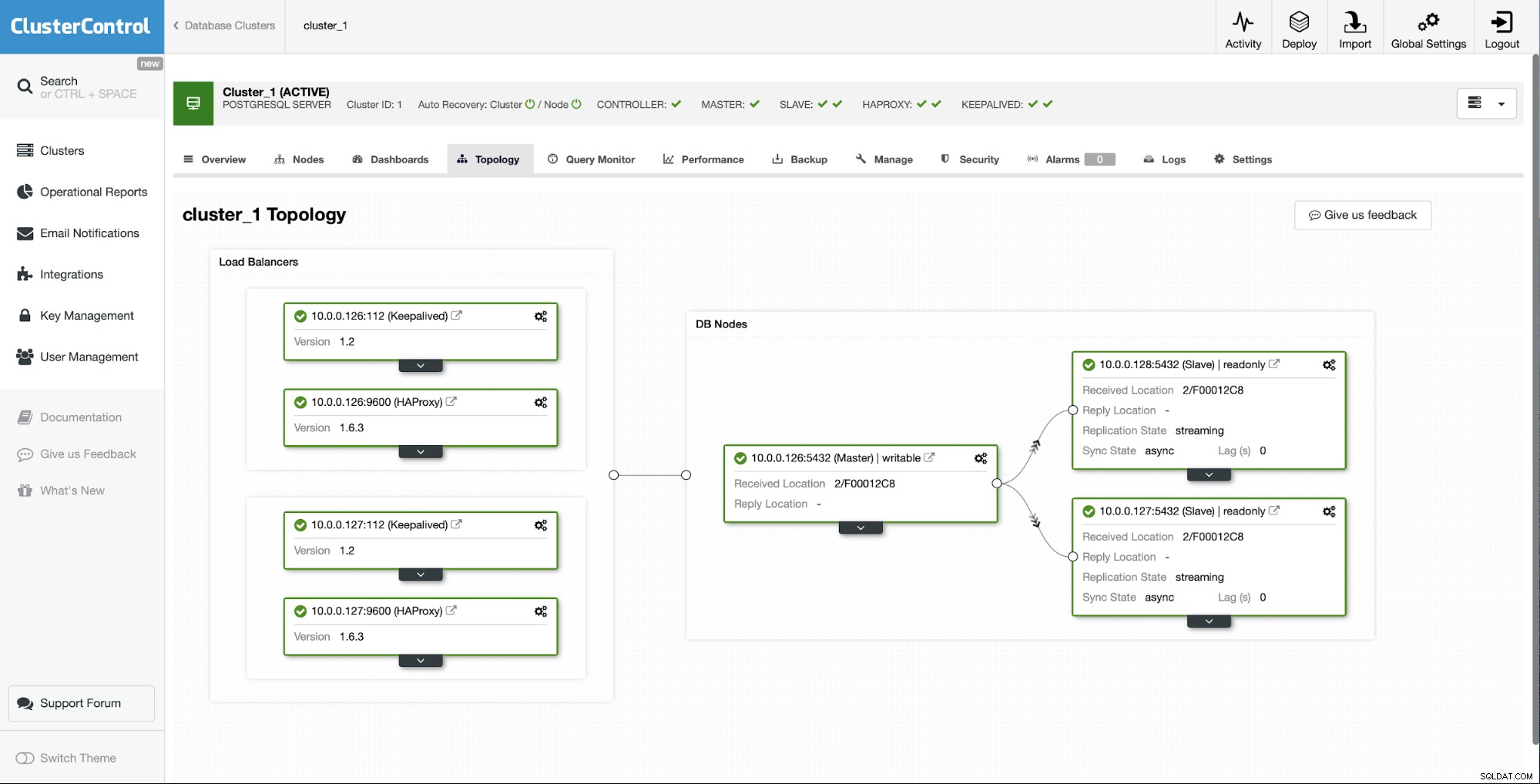
Wie Sie sehen können, haben wir es dank ClusterControl mit nur wenigen Klicks geschafft, unseren ausgefallenen Slave wieder aufzubauen und ihn wieder in den Cluster zu bringen.



