Failover ist die Fähigkeit eines Systems, weiter zu arbeiten, selbst wenn ein Fehler auftritt. Es schlägt vor, dass die Funktionen des Systems von sekundären Komponenten übernommen werden, wenn die primären Komponenten ausfallen oder wenn sie benötigt werden. Wenn Sie es also in eine PostgreSQL-Multi-Cloud-Umgebung übersetzen, bedeutet dies, dass Sie bei einem Ausfall Ihres primären Knotens (oder aus einem anderen Grund, den wir im nächsten Abschnitt erwähnen werden) bei Ihrem primären Cloud-Anbieter in der Lage sein müssen, den Standby-Knoten hochzustufen im sekundären, um die Systeme am Laufen zu halten.
Im Allgemeinen bieten Ihnen alle Cloud-Anbieter eine Failover-Option bei demselben Cloud-Anbieter, aber es könnte möglich sein, dass Sie ein Failover zu einem anderen anderen Cloud-Anbieter benötigen. Natürlich können Sie dies manuell tun, aber Sie können auch einige der ClusterControl-Funktionen wie Auto-Failover verwenden oder Slave-Aktionen fördern, um dies auf freundliche und einfache Weise zu tun.
In diesem Blog erfahren Sie, warum Sie ein Failover benötigen sollten, wie Sie es manuell durchführen und wie Sie ClusterControl für diese Aufgabe verwenden. Wir gehen davon aus, dass Sie eine ClusterControl-Installation ausführen und Ihren Datenbank-Cluster bereits bei zwei verschiedenen Cloud-Anbietern erstellt haben.
Wofür wird Failover verwendet?
Es gibt mehrere mögliche Verwendungen von Failover.
Master-Fehler
Wenn Ihr primärer Knoten ausgefallen ist oder sogar wenn Ihr Haupt-Cloud-Anbieter Probleme hat, müssen Sie ein Failover durchführen, um die Verfügbarkeit Ihres Systems sicherzustellen. In diesem Fall könnte es notwendig sein, dies automatisch zu tun, um die Ausfallzeit zu verringern.
Migration
Wenn Sie Ihre Systeme von einem Cloud-Anbieter zu einem anderen migrieren möchten, indem Sie Ihre Ausfallzeiten minimieren, können Sie Failover verwenden. Sie können ein Replikat im sekundären Cloud-Anbieter erstellen, und sobald es synchronisiert ist, müssen Sie Ihr System stoppen, Ihr Replikat hochstufen und ein Failover durchführen, bevor Sie Ihr System auf den neuen primären Knoten im sekundären Cloud-Anbieter verweisen.
Wartung
Wenn Sie Wartungsaufgaben auf Ihrem primären PostgreSQL-Knoten durchführen müssen, können Sie Ihr Replikat heraufstufen, die Aufgabe ausführen und Ihren alten primären Knoten als Standby-Knoten neu erstellen.
Danach können Sie den alten Primärknoten heraufstufen und den Wiederherstellungsprozess auf dem Standby-Knoten wiederholen, wobei Sie zum ursprünglichen Zustand zurückkehren.
Auf diese Weise können Sie an Ihrem Server arbeiten, ohne Gefahr zu laufen, offline zu sein oder Informationen zu verlieren, während Sie Wartungsaufgaben durchführen.
Upgrades
Es ist möglich, Ihre PostgreSQL-Version (seit PostgreSQL 10) oder sogar Ihr Betriebssystem mit logischer Replikation ohne Ausfallzeit zu aktualisieren, wie es mit anderen Engines möglich ist.
Die Schritte wären die gleichen wie bei der Migration zu einem neuen Cloud-Anbieter, nur dass Ihr Replikat in einer neueren PostgreSQL- oder OS-Version wäre und Sie die logische Replikation verwenden müssten, da Sie kein Streaming verwenden können Replikation zwischen verschiedenen Versionen.
Failover betrifft nicht nur die Datenbank, sondern auch die Anwendung. Woher wissen sie, mit welcher Datenbank sie sich verbinden müssen? Wahrscheinlich möchten Sie Ihre Anwendung nicht ändern müssen, da dies Ihre Ausfallzeit nur verlängert. Sie können also einen Load Balancer konfigurieren, der automatisch auf den heraufgestuften Server verweist, wenn Ihr primärer Knoten ausfällt.
Eine einzelne Load Balancer-Instanz zu haben ist nicht die beste Option, da sie zu einem Single Point of Failure werden kann. Daher können Sie auch ein Failover für den Load Balancer implementieren, indem Sie einen Dienst wie Keepalived verwenden. Auf diese Weise migriert Keepalived die virtuelle IP auf Ihren sekundären Load Balancer, wenn Sie ein Problem mit Ihrem primären Load Balancer haben, und alles funktioniert transparent weiter.
Eine weitere Option ist die Verwendung von DNS. Indem Sie den Standby-Knoten im sekundären Cloud-Anbieter heraufstufen, ändern Sie direkt die IP-Adresse des Hostnamens, die auf den primären Knoten verweist. Auf diese Weise vermeiden Sie, dass Sie Ihre Anwendung ändern müssen, und obwohl dies nicht automatisch möglich ist, ist es eine Alternative, wenn Sie keinen Load Balancer implementieren möchten.
Manuelles Failover von PostgreSQL
Bevor Sie ein manuelles Failover durchführen, müssen Sie den Replikationsstatus überprüfen. Es ist möglich, dass der Standby-Knoten bei einem Failover aufgrund eines Netzwerkfehlers, einer hohen Auslastung oder eines anderen Problems nicht auf dem neuesten Stand ist. Daher müssen Sie sicherstellen, dass Ihr Standby-Knoten alle (oder fast alle Informationen. Wenn Sie mehr als einen Standby-Knoten haben, sollten Sie auch prüfen, welcher der fortschrittlichste Knoten ist, und ihn für das Failover auswählen.
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn()=pg_last_wal_replay_lsn()
postgres-# THEN 0
postgres-# ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
postgres-# END AS log_delay;
log_delay
-----------
0
(1 row)Wenn Sie den neuen primären Knoten auswählen, können Sie zuerst den Befehl pg_lsclusters ausführen, um die Clusterinformationen abzurufen:
$ pg_lsclusters
Ver Cluster Port Status Owner Data directory Log file
12 main 5432 online,recovery postgres /var/lib/postgresql/12/main log/postgresql-%Y-%m-%d_%H%M%S.logDann müssen Sie nur noch den Befehl pg_ctlcluster mit der Promote-Aktion ausführen:
$ pg_ctlcluster 12 main promoteAnstelle des vorherigen Befehls können Sie den Befehl pg_ctl auf diese Weise ausführen:
$ /usr/lib/postgresql/12/bin/pg_ctl promote -D /var/lib/postgresql/12/main/
waiting for server to promote.... done
server promotedDann wird Ihr Standby-Knoten zum primären Knoten heraufgestuft und Sie können ihn validieren, indem Sie die folgende Abfrage in Ihrem neuen primären Knoten ausführen:
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
f
(1 row)Wenn das Ergebnis „f“ ist, ist es Ihr neuer primärer Knoten.
Nun müssen Sie die primäre Datenbank-IP-Adresse in Ihrer Anwendung, Load Balancer, DNS oder der von Ihnen verwendeten Implementierung ändern, was, wie bereits erwähnt, eine manuelle Änderung zu einer Verlängerung der Ausfallzeit führt. Sie müssen auch sicherstellen, dass Ihre Konnektivität zwischen den Cloud-Anbietern ordnungsgemäß funktioniert, die Anwendung auf den neuen primären Knoten zugreifen kann, der Anwendungsbenutzer über Berechtigungen verfügt, um von einem anderen Cloud-Anbieter darauf zuzugreifen, und Sie den/die Standby-Knoten neu erstellen sollten der Remote- oder sogar beim lokalen Cloud-Anbieter, um von der neuen primären Seite zu replizieren, andernfalls haben Sie bei Bedarf keine neue Failover-Option.
Failover von PostgreSQL mit ClusterControl
ClusterControl hat eine Reihe von Funktionen im Zusammenhang mit PostgreSQL-Replikation und automatischem Failover. Wir gehen davon aus, dass Sie Ihren ClusterControl-Server installiert haben und er Ihre Multi-Cloud-PostgreSQL-Umgebung verwaltet.
Mit ClusterControl können Sie beliebig viele Standby-Knoten oder Load-Balancer-Knoten ohne Netzwerk-IP-Einschränkung hinzufügen. Das bedeutet, dass es nicht erforderlich ist, dass sich der Standby-Knoten im selben primären Knotennetzwerk oder sogar im selben Cloud-Anbieter befindet. In Bezug auf Failover ermöglicht Ihnen ClusterControl, dies manuell oder automatisch zu tun.
Manuelles Failover
Um ein manuelles Failover durchzuführen, gehen Sie zu ClusterControl -> Select Cluster -> Nodes und wählen Sie in den Node Actions eines Ihrer Standby-Nodes "Promote Slave".
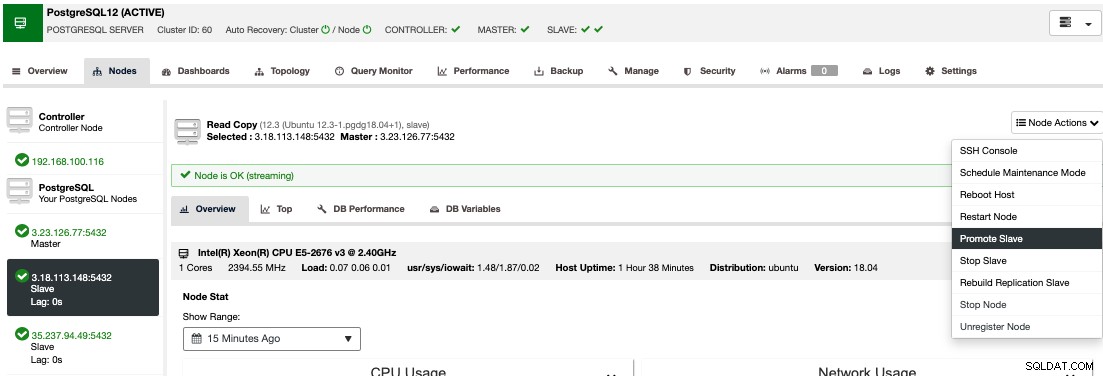
Auf diese Weise wird Ihr Standby-Knoten nach einigen Sekunden zum primären, und was vorher Ihr primäres war, wird zu einem Standby-Gerät. Wenn sich Ihr Replikat also bei einem anderen Cloud-Anbieter befand, ist Ihr neuer primärer Knoten dort und läuft.
Automatisches Failover
Bei automatischem Failover erkennt ClusterControl Ausfälle im primären Knoten und befördert einen Standby-Knoten mit den aktuellsten Daten zum neuen primären Knoten. Es funktioniert auch auf den restlichen Standby-Knoten, damit sie von diesem neuen Primärknoten replizieren.

Wenn die Option „Autorecovery“ aktiviert ist, führt ClusterControl ein automatisches Failover durch und benachrichtigen Sie über das Problem. Auf diese Weise können Ihre Systeme innerhalb von Sekunden und ohne Ihr Eingreifen wiederhergestellt werden.
ClusterControl bietet Ihnen die Möglichkeit, eine Whitelist/Blacklist zu konfigurieren, um zu definieren, wie Ihre Server bei der Entscheidung über einen Hauptkandidaten berücksichtigt (oder nicht) berücksichtigt werden sollen.
ClusterControl führt auch mehrere Überprüfungen des Failover-Prozesses durch, zum Beispiel, wenn es Ihnen gelingt, Ihren alten ausgefallenen Primärknoten wiederherzustellen, wird er nicht automatisch wieder in den Cluster eingeführt, weder als Primärknoten noch als Primärknoten Als Standby müssen Sie dies manuell tun. Dadurch wird die Möglichkeit eines Datenverlusts oder einer Inkonsistenz vermieden, falls Ihre Standby-Verbindung (die Sie heraufgestuft haben) zum Zeitpunkt des Ausfalls verzögert war. Möglicherweise möchten Sie das Problem auch im Detail analysieren, aber wenn Sie es zu Ihrem Cluster hinzufügen, gehen möglicherweise Diagnoseinformationen verloren.
Load Balancer
Wie wir bereits erwähnt haben, ist der Load Balancer ein wichtiges Tool, das Sie für Ihr Failover in Betracht ziehen sollten, insbesondere wenn Sie automatisches Failover in Ihrer Datenbanktopologie verwenden möchten.
Damit das Failover sowohl für den Benutzer als auch für die Anwendung transparent ist, benötigen Sie eine Komponente dazwischen, da es nicht ausreicht, einen neuen primären Knoten hochzustufen. Dafür können Sie HAProxy + Keepalived verwenden.
Um diese Lösung mit ClusterControl zu implementieren, gehen Sie auf Ihrem PostgreSQL-Cluster zu Cluster Actions -> Load Balancer hinzufügen -> HAProxy. Falls Sie Failover für Ihren Load Balancer implementieren möchten, müssen Sie mindestens zwei HAProxy-Instanzen konfigurieren und dann Keepalived konfigurieren (Cluster Actions -> Load Balancer hinzufügen -> Keepalived). Weitere Informationen zu dieser Implementierung finden Sie in diesem Blogbeitrag.
Danach haben Sie die folgende Topologie:

HAProxy ist standardmäßig mit zwei verschiedenen Ports konfiguriert, einem Lese-/Schreib- und einem eine schreibgeschützt.
Im Lese-Schreib-Port haben Sie Ihren primären Knoten als online und die restlichen Knoten als offline. Im schreibgeschützten Port sind sowohl der primäre als auch der Standby-Knoten online. Auf diese Weise können Sie den Leseverkehr zwischen den Knoten ausgleichen. Beim Schreiben wird der Lese-Schreib-Port verwendet, der auf den aktuellen primären Knoten zeigt.

Wenn HAProxy erkennt, dass einer der Knoten, entweder primär oder Standby, ist nicht zugänglich ist, wird es automatisch als offline markiert. HAProxy sendet keinen Datenverkehr an ihn. Diese Prüfung erfolgt durch Zustandsprüfungsskripte, die von ClusterControl zum Zeitpunkt der Bereitstellung konfiguriert werden. Diese prüfen, ob die Instanzen aktiv sind, ob sie gerade wiederhergestellt werden oder schreibgeschützt sind.
Wenn ClusterControl einen neuen primären Knoten hochstuft, markiert HAProxy den alten als offline (für beide Ports) und stellt den heraufgestuften Knoten im Lese-/Schreibport online. Auf diese Weise funktionieren Ihre Systeme weiterhin normal.
Wenn der aktive HAProxy (der eine virtuelle IP-Adresse zugewiesen hat, mit der sich Ihre Systeme verbinden) ausfällt, migriert Keepalived diese virtuelle IP automatisch auf den passiven HAProxy. Das bedeutet, dass Ihre Systeme dann normal weiter funktionieren können.
Cluster-zu-Cluster-Replikation in der Cloud
Um eine Multi-Cloud-Umgebung zu haben, können Sie die ClusterControl Add Slave-Aktion über Ihrem PostgreSQL-Cluster verwenden, aber auch die Cluster-zu-Cluster-Replikationsfunktion. Im Moment hat diese Funktion eine Einschränkung für PostgreSQL, die es Ihnen erlaubt, nur einen Remote-Knoten zu haben, aber wir arbeiten daran, diese Einschränkung bald in einer zukünftigen Version zu entfernen.
Um es bereitzustellen, können Sie den Abschnitt „Cluster-zu-Cluster-Replikation in der Cloud“ in diesem Blogbeitrag lesen.

Wenn es vorhanden ist, können Sie den zu generierenden Remote-Cluster heraufstufen ein unabhängiger PostgreSQL-Cluster mit einem primären Knoten, der auf dem sekundären Cloud-Anbieter ausgeführt wird.

Falls Sie es also brauchen, wird derselbe Cluster ausgeführt in wenigen Sekunden bei einem neuen Cloud-Anbieter.
Fazit
Ein automatischer Failover-Prozess ist zwingend erforderlich, wenn Sie so wenig Ausfallzeiten wie möglich haben möchten, und auch die Verwendung verschiedener Technologien wie HAProxy und Keepalived wird dieses Failover verbessern.
Die oben erwähnten ClusterControl-Funktionen ermöglichen Ihnen ein schnelles Failover zwischen verschiedenen Cloud-Anbietern und eine einfache und benutzerfreundliche Verwaltung der Einrichtung.
Das Wichtigste, was Sie berücksichtigen sollten, bevor Sie einen Failover-Prozess zwischen verschiedenen Cloud-Anbietern durchführen, ist die Konnektivität. Sie müssen sicherstellen, dass Ihre Anwendung oder Ihre Datenbankverbindungen im Falle eines Failovers über den Haupt-, aber auch über den sekundären Cloud-Anbieter wie gewohnt funktionieren, und Sie dürfen aus Sicherheitsgründen den Datenverkehr nur von bekannten Quellen, also nur zwischen der Cloud, einschränken Anbieter und erlauben es nicht von einer externen Quelle.