Die Verwendung einer Multi-Cloud- oder Multi-Rechenzentrum-Umgebung ist nützlich für geografisch verteilte Topologien oder sogar für einen Disaster-Recovery-Plan, und tatsächlich wird es heutzutage immer beliebter, daher das Konzept des Split-Brain wird auch immer wichtiger, da das Risiko, dass es in einem solchen Szenario zunimmt, zunimmt. Sie müssen ein Split-Brain verhindern, um potenzielle Datenverluste oder Dateninkonsistenzen zu vermeiden, die ein großes Problem für das Unternehmen darstellen könnten.
In diesem Blog werden wir sehen, was ein Split-Brain ist und wie ClusterControl Ihnen helfen kann, dieses wichtige Problem zu vermeiden.
Was ist Split-Brain?
In der PostgreSQL-Welt tritt Split-Brain auf, wenn mehr als ein primärer Knoten gleichzeitig verfügbar ist (ohne dass ein Drittanbieter-Tool eine Multi-Master-Umgebung hat), der der Anwendung das Schreiben ermöglicht in beiden Knoten. In diesem Fall haben Sie auf jedem Knoten unterschiedliche Informationen, was zu Dateninkonsistenzen im Cluster führt. Das Beheben dieses Problems kann schwierig sein, da Sie Daten zusammenführen müssen, was manchmal nicht möglich ist.
PostgreSQL Split-Brain in einer Multi-Cloud-Topologie
Nehmen wir an, Sie haben die folgende Multi-Cloud-Topologie für PostgreSQL (was heutzutage eine ziemlich verbreitete Topologie ist):
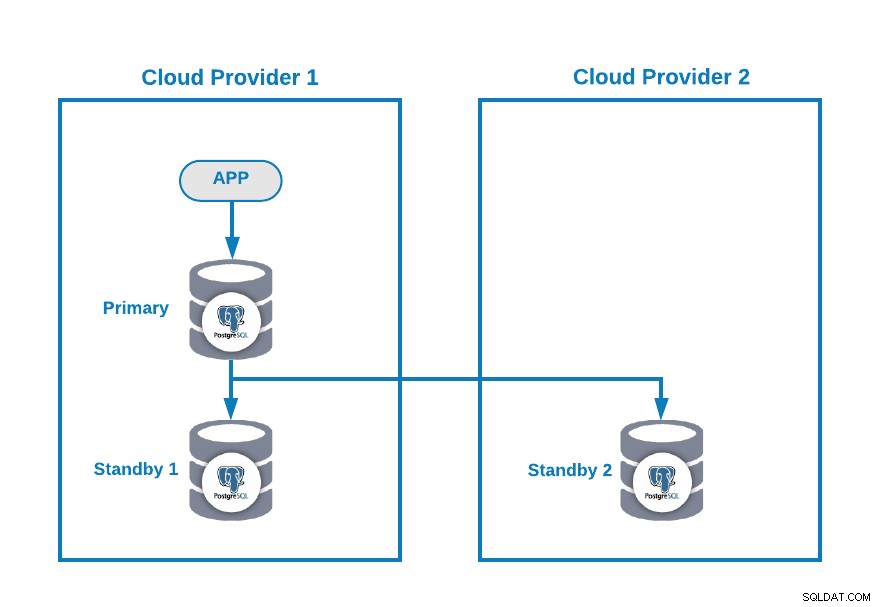
Natürlich können Sie diese Umgebung verbessern, indem Sie beispielsweise eine Anwendungsserver im Cloud-Anbieter 2, aber in diesem Fall verwenden wir diese Grundkonfiguration.
Wenn Ihr primärer Knoten ausgefallen ist, sollte einer der Standby-Knoten als neuer primärer Knoten hochgestuft werden und Sie sollten die IP-Adresse in Ihrer Anwendung ändern, um diesen neuen primären Knoten zu verwenden.
Es gibt verschiedene Möglichkeiten, dies automatisch zu machen. Sie können beispielsweise eine Ihrem primären Knoten zugewiesene virtuelle IP-Adresse verwenden und diese überwachen. Wenn dies fehlschlägt, stufen Sie einen der Standby-Knoten hoch und migrieren Sie die virtuelle IP-Adresse auf diesen neuen primären Knoten, sodass Sie nichts an Ihrer Anwendung ändern müssen und dies mit Ihrem eigenen Skript oder Tool vornehmen können.
Im Moment haben Sie kein Problem, aber… wenn Ihr alter primärer Knoten zurückkommt, müssen Sie sicherstellen, dass Sie nicht zwei primäre Knoten gleichzeitig im selben Cluster haben .
Die gebräuchlichsten Methoden zur Vermeidung dieser Situation sind:
- STONITH:Schieß den anderen Knoten in den Kopf.
- SMITH:Schieß mir in den Kopf.
PostgreSQL bietet keine Möglichkeit, diesen Prozess zu automatisieren. Sie müssen es selbst schaffen.
Wie man Split-Brain in PostgreSQL mit ClusterControl vermeidet
Sehen wir uns nun an, wie ClusterControl Ihnen bei dieser Aufgabe helfen kann.
Erstens können Sie damit Ihre PostgreSQL Multi-Cloud-Umgebung auf einfache Weise bereitstellen oder importieren, wie Sie in diesem Blogbeitrag sehen können.
Dann können Sie Ihre Topologie verbessern, indem Sie einen Load Balancer (HAProxy) hinzufügen, was Sie auch mit ClusterControl nach diesem Blog tun können. Sie werden also so etwas haben:
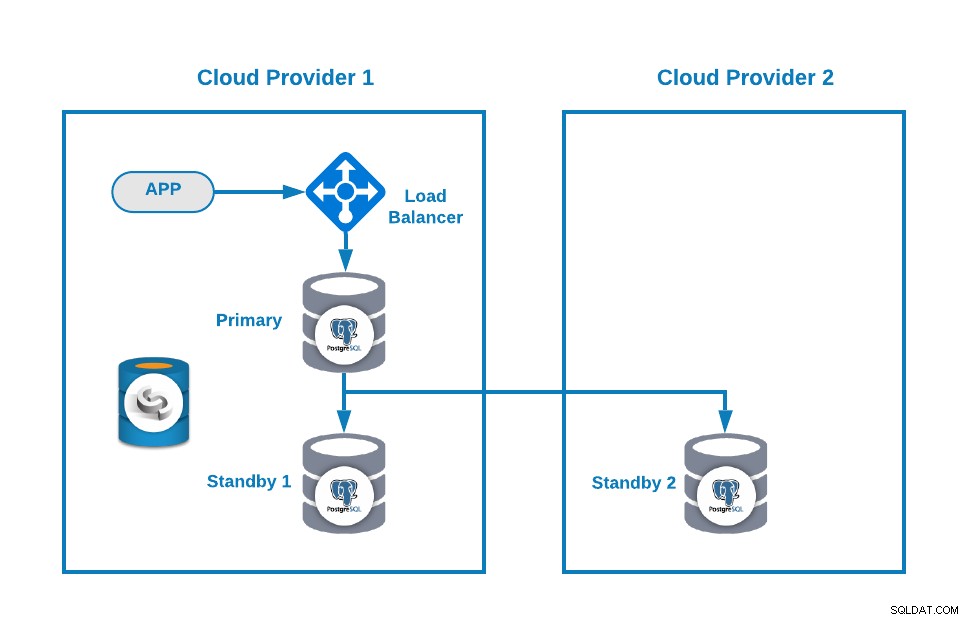
ClusterControl verfügt über eine automatische Failover-Funktion, die Master-Ausfälle erkennt und einen Standby-Modus fördert Knoten mit den aktuellsten Daten als neuer Primärknoten. Es führt auch ein Failover für die restlichen Standby-Knoten durch, um vom neuen primären Knoten zu replizieren.
HAProxy wird von ClusterControl standardmäßig mit zwei verschiedenen Ports konfiguriert, einem Read-Write und einem Read-Only. Im Lese-Schreib-Port ist Ihr primärer Knoten online und der Rest Ihrer Knoten offline, und im schreibgeschützten Port sind sowohl der primäre als auch der Standby-Knoten online. Auf diese Weise können Sie den Leseverkehr zwischen Ihren Knoten ausgleichen, aber Sie stellen sicher, dass zum Zeitpunkt des Schreibens der Lese-Schreib-Port verwendet wird und in den primären Knoten schreibt, der der Server ist, der online ist.
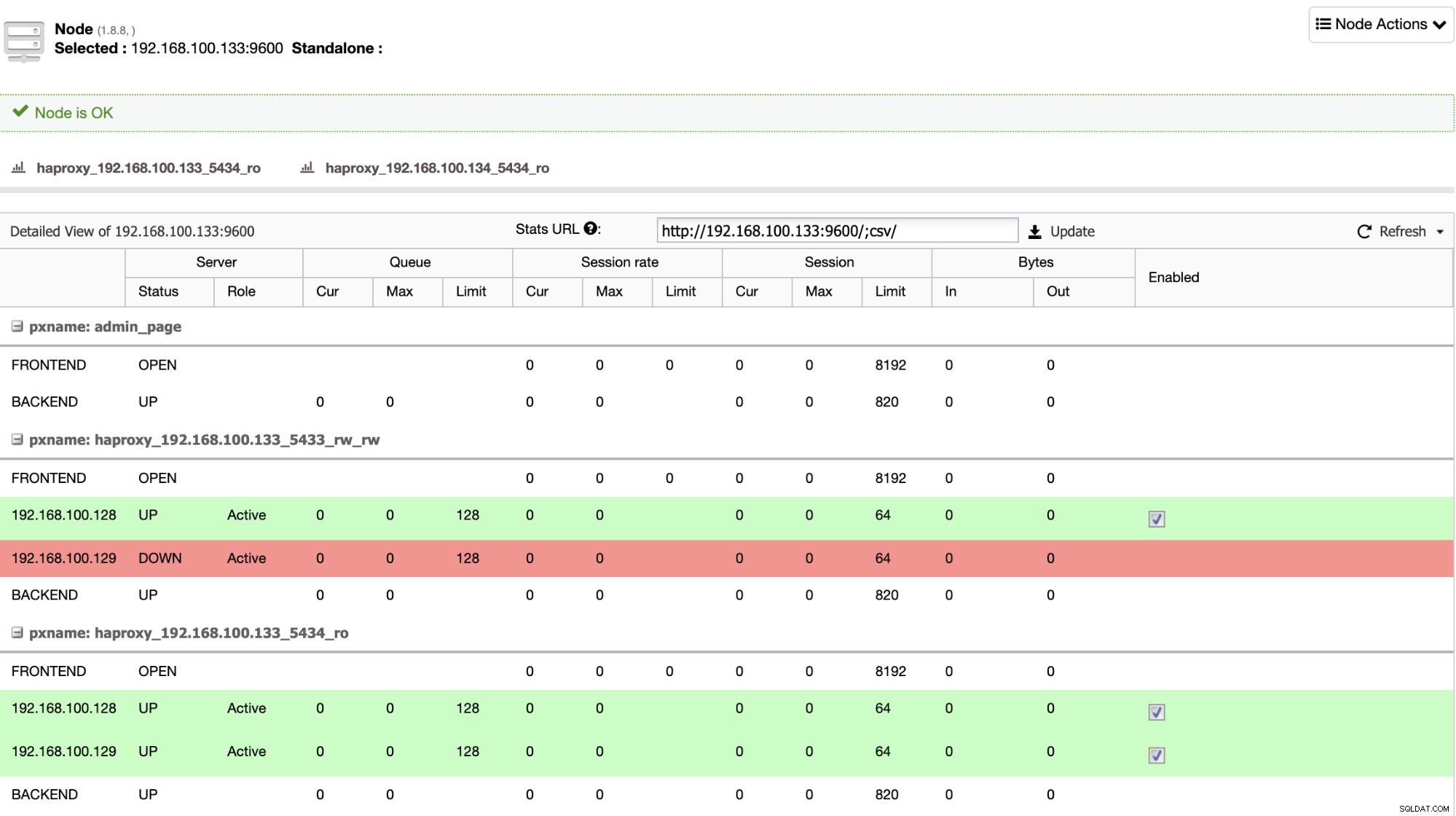
Wenn HAProxy erkennt, dass einer Ihrer Knoten, entweder primär oder Standby, ist nicht zugänglich ist, wird es automatisch als offline markiert und beim Senden von Datenverkehr nicht berücksichtigt. Diese Prüfung erfolgt durch Zustandsprüfungsskripte, die von ClusterControl zum Zeitpunkt der Bereitstellung konfiguriert werden. Diese prüfen, ob die Instanzen aktiv sind, ob sie sich in der Wiederherstellung befinden oder schreibgeschützt sind.
Wenn Ihr alter primärer Knoten zurückkommt, wird ClusterControl auch vermeiden, ihn zu starten, um ein potenzielles Split-Brain zu verhindern, falls Sie eine direkte Verbindung haben, die den Load Balancer nicht verwendet, aber Sie können ihn hinzufügen automatisch oder manuell über die ClusterControl-Benutzeroberfläche oder -CLI als Standby-Knoten zum Cluster hinzufügen, dann können Sie ihn so hochstufen, dass er dieselbe Topologie hat, die Sie vor dem Problem ausgeführt haben.
Fazit
Wenn die Option „Autorecovery“ aktiviert ist, führt ClusterControl dieses automatische Failover durch und benachrichtigt Sie über das Problem. Auf diese Weise können Ihre Systeme ohne Ihr Eingreifen in Sekundenschnelle wiederhergestellt werden, und Sie vermeiden ein Split-Brain in einer PostgreSQL-Multi-Cloud-Umgebung.
Sie können Ihre Hochverfügbarkeitsumgebung auch verbessern, indem Sie mithilfe der in diesem Blog beschriebenen CMON-HA-Funktion weitere ClusterControl-Knoten hinzufügen.