Während es verschiedene Möglichkeiten gibt, Ihre PostgreSQL-Datenbank wiederherzustellen, ist dies einer der bequemsten Ansätze, um Ihre Daten aus einem logischen Backup wiederherzustellen. Logische Backups spielen eine wichtige Rolle für die Notfall- und Wiederherstellungsplanung (DRP). Logische Sicherungen sind Sicherungen, die beispielsweise mit pg_dump oder pg_dumpall erstellt werden, die SQL-Anweisungen generieren, um alle Tabellendaten zu erhalten, die in eine Binärdatei geschrieben werden.
Es wird auch empfohlen, regelmäßig logische Backups auszuführen, falls Ihre physischen Backups fehlschlagen oder nicht verfügbar sind. Bei PostgreSQL kann die Wiederherstellung problematisch sein, wenn Sie sich nicht sicher sind, welche Tools Sie verwenden sollen. Das Sicherungstool pg_dump wird üblicherweise mit dem Wiederherstellungstool pg_restore gekoppelt.
pg_dump und pg_restore agieren gemeinsam, wenn ein Notfall eintritt und Sie Ihre Daten wiederherstellen müssen. Während sie dem Hauptzweck des Sicherns und Wiederherstellens dienen, müssen Sie einige zusätzliche Aufgaben ausführen, wenn Sie Ihren Cluster wiederherstellen und ein Failover durchführen müssen (wenn Ihr aktiver primärer oder Master aufgrund eines Hardwarefehlers oder einer Beschädigung des VM-Systems stirbt). Am Ende werden Sie Tools von Drittanbietern finden und verwenden, die Failover oder automatische Cluster-Wiederherstellung handhaben können.
In diesem Blog werfen wir einen Blick darauf, wie pg_restore funktioniert, und vergleichen es damit, wie ClusterControl die Sicherung und Wiederherstellung Ihrer Daten handhabt, falls ein Notfall eintritt.
Mechanismen von pg_restore
pg_restore ist nützlich, wenn Sie die folgenden Aufgaben erhalten:
- gepaart mit pg_dump zum Generieren von SQL-generierten Dateien mit Daten, Zugriffsrollen, Datenbank- und Tabellendefinitionen
- Stellen Sie eine PostgreSQL-Datenbank aus einem von pg_dump erstellten Archiv in einem der Nicht-Klartext-Formate wieder her.
- Es wird die Befehle ausgeben, die notwendig sind, um die Datenbank wieder in den Zustand zu versetzen, in dem sie sich zum Zeitpunkt der Speicherung befand.
- kann die Elemente auswählen oder sogar neu anordnen, bevor sie basierend auf der Archivdatei wiederhergestellt werden
- Die Archivdateien sind so konzipiert, dass sie über Architekturen hinweg portierbar sind.
- pg_restore kann in zwei Modi betrieben werden.
- Wenn ein Datenbankname angegeben ist, stellt pg_restore eine Verbindung zu dieser Datenbank her und stellt Archivinhalte direkt in der Datenbank wieder her.
- oder es wird ein Skript erstellt, das die zum Neuaufbau der Datenbank erforderlichen SQL-Befehle enthält, und in eine Datei oder Standardausgabe geschrieben. Seine Skriptausgabe entspricht dem von pg_dump generierten Format
- Einige der Optionen, die die Ausgabe steuern, sind daher analog zu pg_dump-Optionen.
Sobald Sie die Daten wiederhergestellt haben, ist es am besten und ratsam, ANALYZE für jede wiederhergestellte Tabelle auszuführen, damit der Optimierer nützliche Statistiken hat. Obwohl es READ LOCK erwirbt, müssen Sie dies möglicherweise während eines geringen Datenverkehrs oder während Ihres Wartungszeitraums ausführen.
Vorteile von pg_restore
pg_dump und pg_restore zusammen haben Funktionen, die für einen DBA bequem zu verwenden sind.
- pg_dump und pg_restore können durch Angabe der Option -j parallel ausgeführt werden. Mit -j/--jobs
können Sie angeben, wie viele parallel laufende Jobs ausgeführt werden können, insbesondere zum Laden von Daten, zum Erstellen von Indizes oder zum Erstellen von Einschränkungen mit mehreren gleichzeitigen Jobs. - Es ist ziemlich praktisch zu benutzen, Sie können bestimmte Datenbanken oder Tabellen selektiv sichern oder laden
- Es ermöglicht und bietet dem Benutzer Flexibilität hinsichtlich der bestimmten Datenbank, des Schemas oder der Neuordnung der auszuführenden Prozeduren basierend auf der Liste. Sie können die SQL-Sequenz sogar lose generieren und laden, wie ACLs oder Privilegien gemäß Ihren Anforderungen verhindern. Es gibt viele Optionen für Ihre Bedürfnisse.
- Es bietet Ihnen die Möglichkeit, SQL-Dateien wie pg_dump aus einem Archiv zu generieren. Dies ist sehr praktisch, wenn Sie in eine andere Datenbank oder einen anderen Host laden möchten, um eine separate Umgebung bereitzustellen.
- Anhand der generierten Sequenz von SQL-Prozeduren leicht verständlich.
- Es ist eine bequeme Möglichkeit, Daten in eine Replikationsumgebung zu laden. Sie müssen Ihr Replikat nicht erneut bereitstellen, da es sich bei den Anweisungen um SQL handelt, die auf die Standby- und Wiederherstellungsknoten repliziert wurden.
Einschränkungen von pg_restore
Für logische Sicherungen sind die offensichtlichen Einschränkungen von pg_restore zusammen mit pg_dump die Leistung und Geschwindigkeit bei der Verwendung der Tools. Es kann praktisch sein, wenn Sie eine Test- oder Entwicklungsdatenbankumgebung bereitstellen und Ihre Daten laden möchten, aber es ist nicht anwendbar, wenn Ihr Datensatz sehr groß ist. PostgreSQL muss Ihre Daten einzeln ausgeben oder Ihre Daten sequenziell von der Datenbank-Engine ausführen und anwenden. Obwohl Sie dies locker flexibel gestalten können, um die Geschwindigkeit zu erhöhen, indem Sie -j angeben oder --single-transaction verwenden, um Auswirkungen auf Ihre Datenbank zu vermeiden, muss das Laden mit SQL immer noch von der Engine geparst werden.
Zusätzlich gibt die PostgreSQL-Dokumentation die folgenden Einschränkungen an, mit unseren Ergänzungen, da wir diese Tools beobachtet haben (pg_dump und pg_restore):
- Wenn Daten in einer bereits vorhandenen Tabelle wiederhergestellt werden und die Option --disable-triggers verwendet wird, gibt pg_restore Befehle aus, um Trigger für Benutzertabellen zu deaktivieren, bevor die Daten eingefügt werden, und gibt dann Befehle aus, um sie wieder zu aktivieren nachdem die Daten eingefügt wurden. Wenn die Wiederherstellung mittendrin abgebrochen wird, verbleiben die Systemkataloge möglicherweise im falschen Zustand.
- pg_restore kann große Objekte nicht selektiv wiederherstellen; zum Beispiel nur die für eine bestimmte Tabelle. Wenn ein Archiv große Objekte enthält, werden alle großen Objekte wiederhergestellt, oder keines davon, wenn sie mit -L, -t oder anderen Optionen ausgeschlossen werden.
- Bei beiden Tools wird erwartet, dass sie eine enorme Größe (Dateien, Verzeichnisse oder Tar-Archive) erzeugen, insbesondere für eine riesige Datenbank.
- Bei pg_dump verarbeitet pg_dump keine großen Objekte, wenn eine einzelne Tabelle oder als einfacher Text ausgegeben wird. Große Objekte müssen mit der gesamten Datenbank in einem der Nicht-Text-Archivformate gesichert werden.
- Wenn Sie von diesen Tools erstellte Tar-Archive haben, beachten Sie, dass Tar-Archive auf eine Größe von weniger als 8 GB beschränkt sind. Dies ist eine inhärente Einschränkung des tar-Dateiformats. Daher kann dieses Format nicht verwendet werden, wenn die Textdarstellung einer Tabelle diese Größe überschreitet. Die Gesamtgröße eines tar-Archivs und aller anderen Ausgabeformate ist nicht begrenzt, außer möglicherweise durch das Betriebssystem.
Verwendung von pg_restore
Die Verwendung von pg_restore ist ziemlich praktisch und einfach zu verwenden. Da es zusammen mit pg_dump verwendet wird, funktionieren beide Tools ausreichend gut, solange die Zielausgabe zum anderen passt. Beispielsweise ist das folgende pg_dump für pg_restore nicht nützlich,
[example@sqldat.com ~]# pg_dump --format=p --create -U dbapgadmin -W -d paultest -f plain.sql
Password: Dieses Ergebnis ist ein psql-kompatibles Ergebnis, das wie folgt aussieht:
[example@sqldat.com ~]# less plain.sql
--
-- PostgreSQL database dump
--
-- Dumped from database version 12.2
-- Dumped by pg_dump version 12.2
SET statement_timeout = 0;
SET lock_timeout = 0;
SET idle_in_transaction_session_timeout = 0;
SET client_encoding = 'UTF8';
SET standard_conforming_strings = on;
SELECT pg_catalog.set_config('search_path', '', false);
SET check_function_bodies = false;
SET xmloption = content;
SET client_min_messages = warning;
SET row_security = off;
--
-- Name: paultest; Type: DATABASE; Schema: -; Owner: postgres
--
CREATE DATABASE paultest WITH TEMPLATE = template0 ENCODING = 'UTF8' LC_COLLATE = 'en_US.UTF-8' LC_CTYPE = 'en_US.UTF-8';
ALTER DATABASE paultest OWNER TO postgres;Aber dies wird für pg_restore fehlschlagen, da es kein einfaches Format gibt, dem zu folgen ist:
[example@sqldat.com ~]# pg_restore -U dbapgadmin --format=p -C -W -d postgres plain.sql
pg_restore: error: unrecognized archive format "p"; please specify "c", "d", or "t"
[example@sqldat.com ~]# pg_restore -U dbapgadmin --format=c -C -W -d postgres plain.sql
pg_restore: error: did not find magic string in file headerLassen Sie uns nun zu weiteren nützlichen Begriffen für pg_restore gehen.
pg_restore:Löschen und Wiederherstellen
Betrachten Sie eine einfache Verwendung von pg_restore, bei der Sie eine Datenbank gelöscht haben, z. B.
postgres=# drop database maxtest;
DROP DATABASE
postgres=# \l+
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
-----------+----------+----------+-------------+-------------+-----------------------+---------+------------+--------------------------------------------
paultest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 83 MB | pg_default |
postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 8209 kB | pg_default | default administrative connection database
template0 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +| 8049 kB | pg_default | unmodifiable empty database
| | | | | postgres=CTc/postgres | | |
template1 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | postgres=CTc/postgres+| 8193 kB | pg_default | default template for new databases
| | | | | =c/postgres | | |
(4 rows)Eine Wiederherstellung mit pg_restore ist sehr einfach,
[example@sqldat.com ~]# sudo -iu postgres pg_restore -C -d postgres /opt/pg-files/dump/f.dump Das -C/--create hier gibt an, dass die Datenbank erstellt wird, sobald sie im Header gefunden wird. Das -d postgres zeigt auf die Postgres-Datenbank, bedeutet aber nicht, dass es die Tabellen für die Postgres-Datenbank erstellt. Voraussetzung ist, dass die Datenbank vorhanden ist. Wenn -C nicht angegeben ist, werden Tabellen und Datensätze in dieser Datenbank gespeichert, auf die mit dem Argument -d verwiesen wird.
Selektive Wiederherstellung nach Tabelle
Das Wiederherstellen einer Tabelle mit pg_restore ist einfach und unkompliziert. Beispielsweise haben Sie zwei Tabellen, nämlich die Tabellen „b“ und „d“. Angenommen, Sie führen den folgenden pg_dump-Befehl unten aus,
[example@sqldat.com ~]# pg_dump --format=d --create -U dbapgadmin -W -d paultest -f pgdump_inserts
Password:Wobei der Inhalt dieses Verzeichnisses wie folgt aussehen wird,
[example@sqldat.com ~]# ls -alth pgdump_inserts/
total 16M
-rw-r--r--. 1 root root 14M May 15 20:27 3696.dat.gz
drwx------. 2 root root 59 May 15 20:27 .
-rw-r--r--. 1 root root 2.5M May 15 20:27 3694.dat.gz
-rw-r--r--. 1 root root 4.0K May 15 20:27 toc.dat
dr-xr-x---. 5 root root 275 May 15 20:27 ..Wenn Sie eine Tabelle wiederherstellen möchten (nämlich "d" in diesem Beispiel),
[example@sqldat.com ~]# pg_restore -U postgres -Fd -d paultest -t d pgdump_inserts/Soll haben,
paultest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | d | table | postgres | 51 MB |
(1 row)pg_restore:Kopieren von Datenbanktabellen in eine andere Datenbank
Sie können sogar den Inhalt Ihrer bestehenden Datenbank kopieren und ihn in Ihrer Zieldatenbank haben. Zum Beispiel habe ich die folgenden Datenbanken,
paultest=# \l+ (paultest|maxtest)
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
----------+----------+----------+-------------+-------------+-------------------+---------+------------+-------------
maxtest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 84 MB | pg_default |
paultest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 8273 kB | pg_default |
(2 rows)Die Paultest-Datenbank ist eine leere Datenbank, während wir kopieren, was in der Maxtest-Datenbank ist,
maxtest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | d | table | postgres | 51 MB |
(1 row)
maxtest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | b | table | postgres | 69 MB |
public | d | table | postgres | 51 MB |
(2 rows)Um es zu kopieren, müssen wir die Daten aus der maxtest-Datenbank wie folgt ausgeben,
[example@sqldat.com ~]# pg_dump --format=t --create -U dbapgadmin -W -d maxtest -f pgdump_data.tar
Password: Laden oder stellen Sie es dann wie folgt wieder her
Jetzt haben wir Daten in der Paultest-Datenbank und die Tabellen wurden entsprechend gespeichert.
postgres=# \l+ (paultest|maxtest)
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
----------+----------+----------+-------------+-------------+-------------------+--------+------------+-------------
maxtest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 153 MB | pg_default |
paultest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 154 MB | pg_default |
(2 rows)
paultest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | b | table | postgres | 69 MB |
public | d | table | postgres | 51 MB |
(2 rows)Generiere eine SQL-Datei mit Neuordnung
Ich habe eine Menge Verwendung mit pg_restore gesehen, aber es scheint, dass diese Funktion normalerweise nicht gezeigt wird. Ich fand diesen Ansatz sehr interessant, da er es Ihnen ermöglicht, basierend auf dem, was Sie nicht einschließen möchten, zu bestellen und dann eine SQL-Datei aus der Reihenfolge zu generieren, mit der Sie fortfahren möchten.
Zum Beispiel verwenden wir das Beispiel pgdump_data.tar, das wir zuvor generiert haben, und erstellen eine Liste. Führen Sie dazu den folgenden Befehl aus:
[example@sqldat.com ~]# pg_restore -l pgdump_data.tar > my.listDies erzeugt eine Datei wie unten gezeigt:
[example@sqldat.com ~]# cat my.list
;
; Archive created at 2020-05-15 20:48:24 UTC
; dbname: maxtest
; TOC Entries: 13
; Compression: 0
; Dump Version: 1.14-0
; Format: TAR
; Integer: 4 bytes
; Offset: 8 bytes
; Dumped from database version: 12.2
; Dumped by pg_dump version: 12.2
;
;
; Selected TOC Entries:
;
204; 1259 24811 TABLE public b postgres
202; 1259 24757 TABLE public d postgres
203; 1259 24760 SEQUENCE public d_id_seq postgres
3698; 0 0 SEQUENCE OWNED BY public d_id_seq postgres
3560; 2604 24762 DEFAULT public d id postgres
3691; 0 24811 TABLE DATA public b postgres
3689; 0 24757 TABLE DATA public d postgres
3699; 0 0 SEQUENCE SET public d_id_seq postgres
3562; 2606 24764 CONSTRAINT public d d_pkey postgresOrdnen wir es jetzt neu oder sagen wir, ich habe die Erstellung von SEQUENCE und auch die Erstellung der Einschränkung entfernt. Dies würde wie folgt aussehen,
TL;DR
...
;203; 1259 24760 SEQUENCE public d_id_seq postgres
;3698; 0 0 SEQUENCE OWNED BY public d_id_seq postgres
TL;DR
….
;3562; 2606 24764 CONSTRAINT public d d_pkey postgresUm die Datei im SQL-Format zu generieren, gehen Sie einfach wie folgt vor:
[example@sqldat.com ~]# pg_restore -L my.list --file /tmp/selective_data.out pgdump_data.tar Jetzt wird die Datei /tmp/selective_data.out eine von SQL generierte Datei sein und diese ist lesbar, wenn Sie psql verwenden, aber nicht pg_restore. Das Tolle daran ist, dass Sie mit Hilfe von pg_restore eine SQL-Datei gemäß Ihrer Vorlage erstellen können, auf der Daten nur aus einem vorhandenen Archiv oder einer Sicherung, die mit pg_dump erstellt wurde, wiederhergestellt werden können.
PostgreSQL-Wiederherstellung mit ClusterControl
ClusterControl verwendet pg_restore oder pg_dump nicht als Teil seines Funktionsumfangs. Wir verwenden pg_dumpall, um logische Backups zu erstellen, und leider ist die Ausgabe nicht mit pg_restore kompatibel.
Es gibt mehrere andere Möglichkeiten, ein Backup in PostgreSQL zu erstellen, wie unten gezeigt.
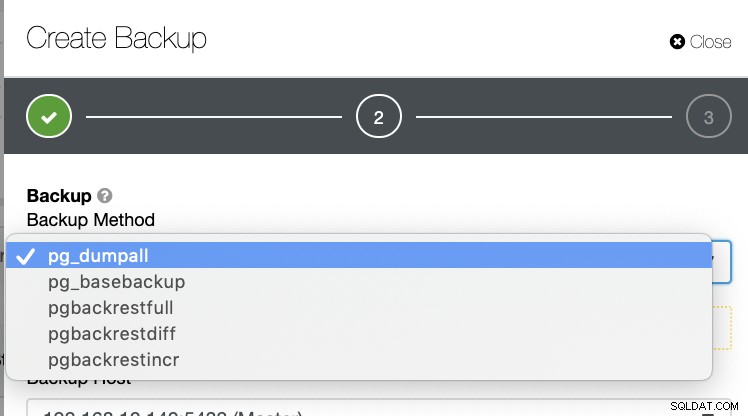
Es gibt keinen solchen Mechanismus, mit dem Sie selektiv eine Tabelle, eine Datenbank, oder von einer Datenbank in eine andere Datenbank kopieren.
ClusterControl unterstützt Point-in-Time Recovery (PITR), aber damit können Sie die Datenwiederherstellung nicht so flexibel verwalten wie mit pg_restore. Für alle Backup-Methoden sind nur pg_basebackup und pgbackrest PITR-fähig.
Wie ClusterControl die Wiederherstellung handhabt, ist, dass es die Fähigkeit hat, einen ausgefallenen Cluster wiederherzustellen, solange die automatische Wiederherstellung wie unten gezeigt aktiviert ist.

Sobald der Master ausfällt, kann der Slave den Cluster automatisch wiederherstellen, während ClusterControl ausgeführt wird das Failover (das automatisch erfolgt). Für den Teil der Datenwiederherstellung besteht Ihre einzige Option darin, eine clusterweite Wiederherstellung durchzuführen, was bedeutet, dass sie aus einer vollständigen Sicherung stammt. Es gibt keine Möglichkeit, die Zieldatenbank oder -tabelle, die Sie nur wiederherstellen wollten, selektiv wiederherzustellen. Wenn Sie das tun möchten, stellen Sie die vollständige Sicherung wieder her, das geht ganz einfach mit ClusterControl. Sie können wie unten gezeigt zu den Backup-Tabs gehen,
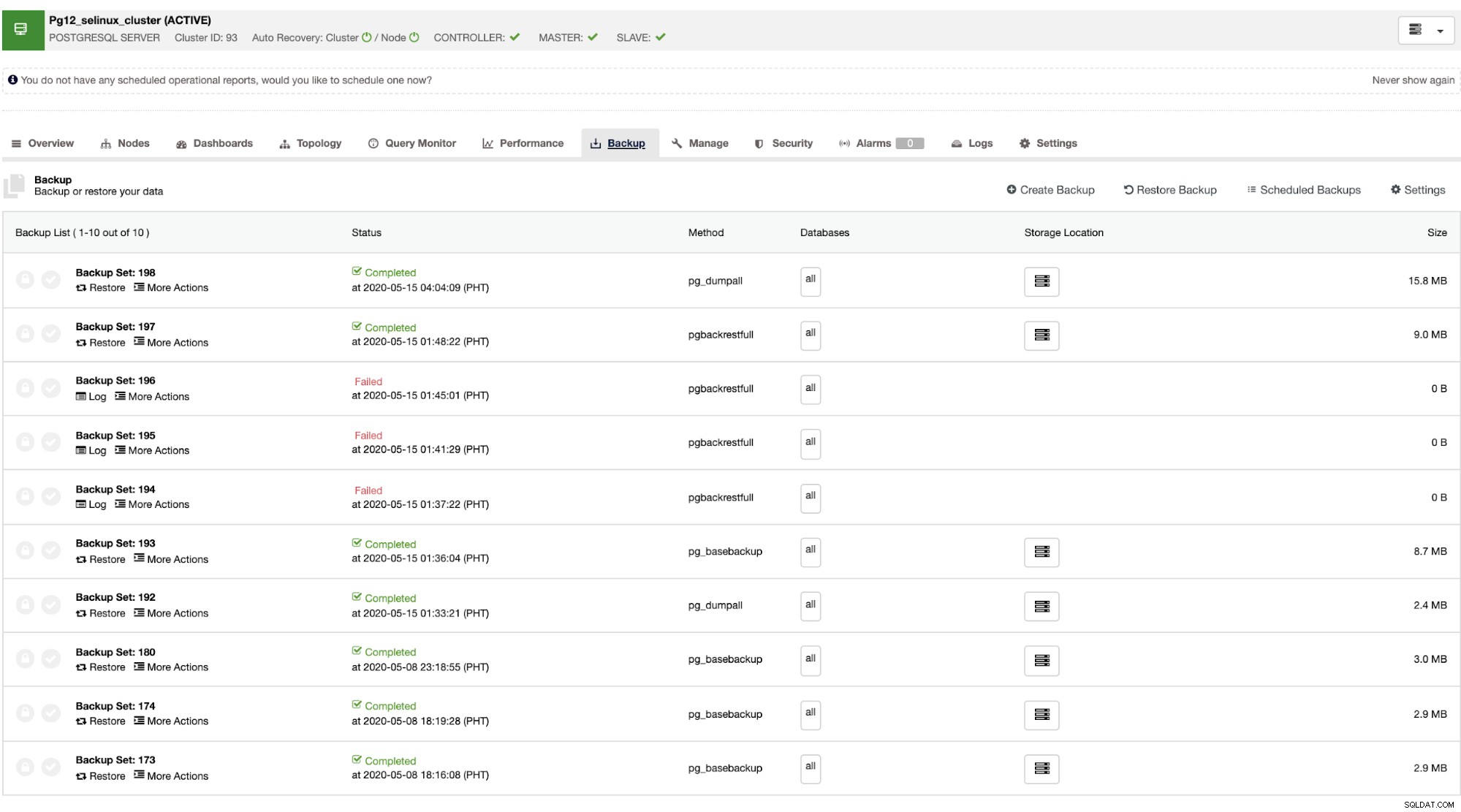
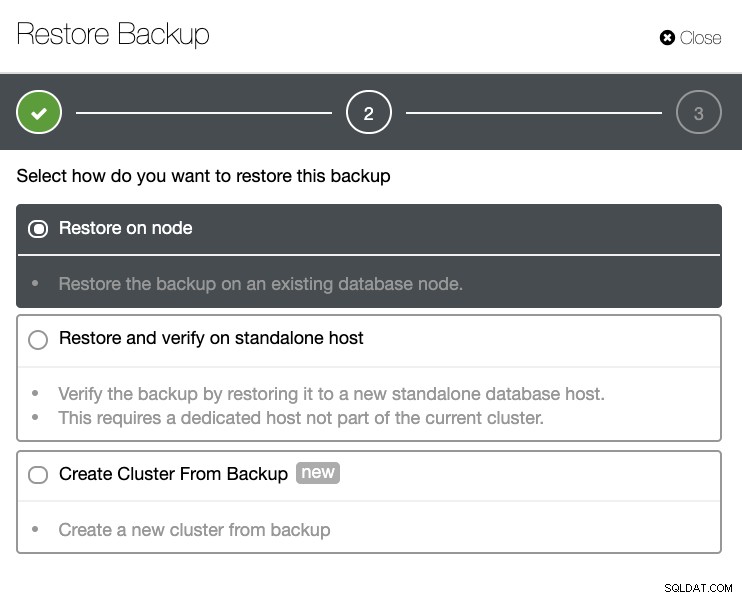
Sie erhalten eine vollständige Liste erfolgreicher und fehlgeschlagener Sicherungen. Dann kann es wiederhergestellt werden, indem Sie das Ziel-Backup auswählen und auf die Schaltfläche "Wiederherstellen" klicken. Dies ermöglicht Ihnen die Wiederherstellung auf einem vorhandenen Knoten, der in ClusterControl registriert ist, oder die Überprüfung auf einem eigenständigen Knoten oder die Erstellung eines Clusters aus der Sicherung.
Fazit
Die Verwendung von pg_dump und pg_restore vereinfacht den Backup/Dump- und Wiederherstellungsansatz. Für eine umfangreiche Datenbankumgebung ist dies jedoch möglicherweise keine ideale Komponente für die Notfallwiederherstellung. Für ein minimales Auswahl- und Wiederherstellungsverfahren bietet Ihnen die Verwendung der Kombination von pg_dump und pg_restore die Möglichkeit, Ihre Daten entsprechend Ihren Anforderungen zu sichern und zu laden.
Für Produktionsumgebungen (insbesondere für Unternehmensarchitekturen) können Sie den ClusterControl-Ansatz verwenden, um eine Sicherung und Wiederherstellung mit automatischer Wiederherstellung zu erstellen.
Eine Kombination von Ansätzen ist auch ein guter Ansatz. Dies hilft Ihnen, Ihre RTO und RPO zu senken und gleichzeitig die flexibelste Methode zur Wiederherstellung Ihrer Daten bei Bedarf zu nutzen.