Hybrid Cloud ist ein gängiges Architekturdesign in jedem Unternehmen. Dieses Konzept kombiniert Public Cloud, Private Cloud und sogar On-Premise-Lösungen, die es Unternehmen ermöglichen, flexibel zu bleiben, wo sie ihre Daten speichern und wie sie sie verwenden. Es hilft auch bei der Implementierung einer Hochverfügbarkeitsumgebung. Das Problem ist, dass die Bereitstellung einer solchen Umgebung eine schwierige und zeitaufwändige Aufgabe sein kann. In diesem Blog werden wir sehen, was Hybrid Cloud ist, einige Überlegungen, die vor der Verwendung zu berücksichtigen sind, und wie diese Umgebung mithilfe von ClusterControl bereitgestellt wird.
Was ist eine Hybrid Cloud?
Es ist eine Topologie, die eine Mischung aus privater und öffentlicher Cloud und sogar lokalen Diensten verwendet. Es klingt ähnlich wie eine Multi-Cloud-Umgebung, aber der Hauptunterschied besteht darin, dass sich dieses Konzept speziell auf die Kombinationen von öffentlich und privat bezieht, was auch On-Prem umfassen könnte.
Überlegungen zu hybriden Cloud-Datenbanken
Der Wechsel zu einer hybriden Umgebung ist für jedes Unternehmen anders, da sie ihre eigenen einzigartigen Daten, Anforderungen, Einschränkungen und Prozesse haben, die damit einhergehen.
Sehen wir uns einige Überlegungen an, die bei der Planung dieser Art von Topologie zu berücksichtigen sind.
-
Compliance:Stellen Sie sicher, dass Sie einen Anbieter auswählen, der auf Ihre Branche spezialisiert und mit den einzigartigen Compliance-Maßnahmen vertraut ist müssen eingehalten werden, egal ob es sich dabei um HIPAA, FISMA, PCI oder andere Vorschriften handelt, die Ihr Unternehmen unterschreibt. Letztendlich sollte Ihre Datenbankverwaltungsstrategie davon bestimmt werden, welche Architektur die Anforderungen Ihres Unternehmens am besten erfüllt und mit Ihrem Wachstum mitwächst.
-
Workloads:Jede Datenbank hat unterschiedliche Workloads. Einige davon werden in einer öffentlichen Cloud besser abschneiden, einige vor Ort und einige in einer privaten Cloud. Die Kenntnis Ihrer Arbeitslast ist entscheidend, um die beste Mischung für Ihre Datenbanken zu finden.
-
Verwaltung und Wartung:Eine neue Umgebung bedeutet eine neue Möglichkeit, sie zu verwalten und die Daten zu pflegen. Stellen Sie sicher, dass Sie die richtigen Teile haben und die richtigen Leute vorhanden sind, um diese neuen Umgebungen zu verwalten, bevor Sie den Sprung wagen.
So stellen Sie PostgreSQL in einer Hybrid-Cloud-Umgebung bereit
Wir gehen davon aus, dass Sie eine ClusterControl-Installation ausführen und bereits zwei verschiedene Cloud-Provider-Konten erstellt haben, oder ein Konto, wenn Sie Public und Private Cloud bei demselben Cloud-Provider verwenden, oder wenn Sie einen verwenden Kombination aus Cloud- und On-Prem-Umgebungen.
Vorbereiten Ihrer Cloud-Umgebung
Zunächst müssen Sie Ihre Umgebung bei Ihrem Haupt-Cloud-Anbieter erstellen. In diesem Fall verwenden wir AWS mit 2 PostgreSQL-Knoten:

Stellen Sie sicher, dass Sie den SSH- und PostgreSQL-Datenverkehr von Ihrem ClusterControl-Server zugelassen haben Bearbeiten Ihrer Sicherheitsgruppe:

Gehen Sie dann zum sekundären Cloud-Anbieter oder zu den privaten oder lokalen Servern und erstellen Sie mindestens eine virtuelle Maschine, die der Standby-Knoten sein wird.

Und stellen Sie nochmals sicher, dass Sie SSH- und PostgreSQL-Datenverkehr von Ihrem ClusterControl-Server zulassen:

In diesem Fall erlauben wir den Datenverkehr ohne Einschränkung der Quelle, aber es ist nur ein Beispiel und wird im wirklichen Leben nicht empfohlen.
Bereitstellen eines PostgreSQL-Clusters
Gehen Sie zu Ihrem ClusterControl-Server und wählen Sie die Option „Bereitstellen“. Wenn Sie bereits eine PostgreSQL-Instanz ausführen, müssen Sie stattdessen „Vorhandenen Server/Datenbank importieren“ auswählen.
Bei der Auswahl von PostgreSQL müssen Sie Benutzer, Schlüssel oder Passwort und den Port angeben, um sich per SSH mit Ihren PostgreSQL-Knoten zu verbinden. Außerdem benötigen Sie den Namen für Ihren neuen Cluster und wenn Sie möchten, dass ClusterControl die entsprechende Software und Konfigurationen für Sie installiert.
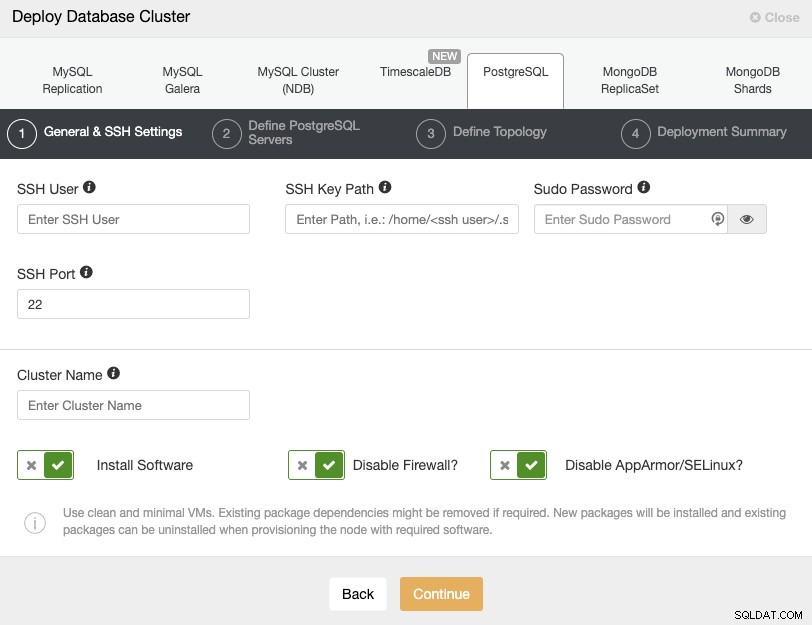
Weitere Informationen zu diesem Schritt finden Sie in den Benutzeranforderungen von ClusterControl.
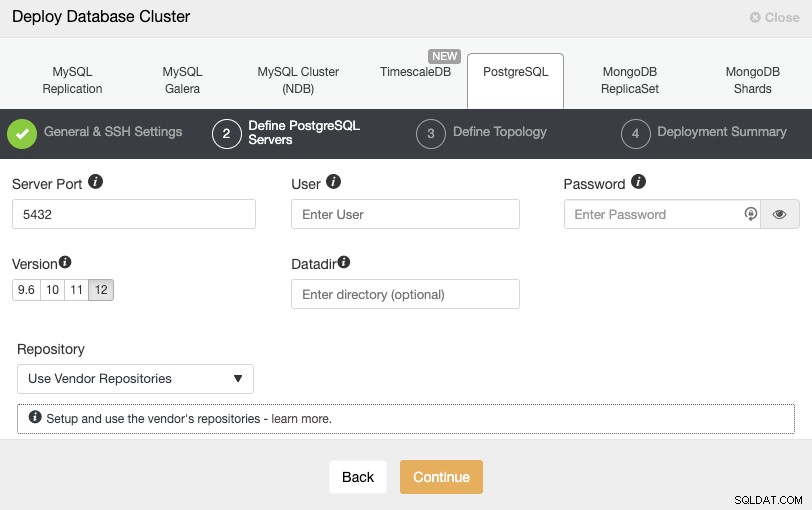
Nachdem Sie die SSH-Zugangsinformationen eingerichtet haben, müssen Sie den Datenbankbenutzer, die Version und das Datadir (optional) definieren. Sie können auch angeben, welches Repository verwendet werden soll. Im nächsten Schritt müssen Sie Ihre Server zu dem Cluster hinzufügen, den Sie erstellen werden.
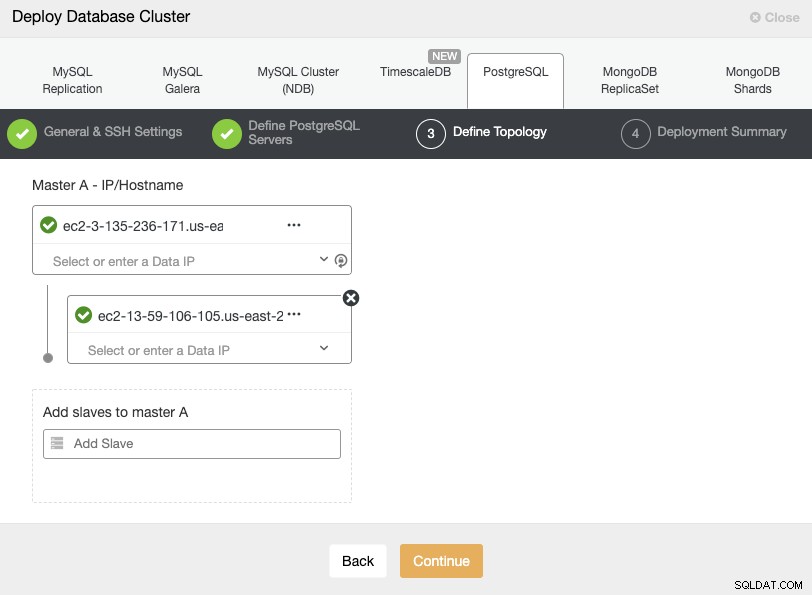
Wenn Sie Ihre Server hinzufügen, können Sie die IP oder den Hostnamen eingeben. In diesem Schritt könnten Sie auch den Knoten hinzufügen, der beim sekundären Cloud-Anbieter oder lokal platziert ist, da ClusterControl keine Einschränkungen hinsichtlich des zu verwendenden Netzwerks hat, aber um es klarer zu machen, werden wir ihn im nächsten hinzufügen Sektion. Die einzige Voraussetzung hier ist, SSH-Zugriff auf den Knoten zu haben.
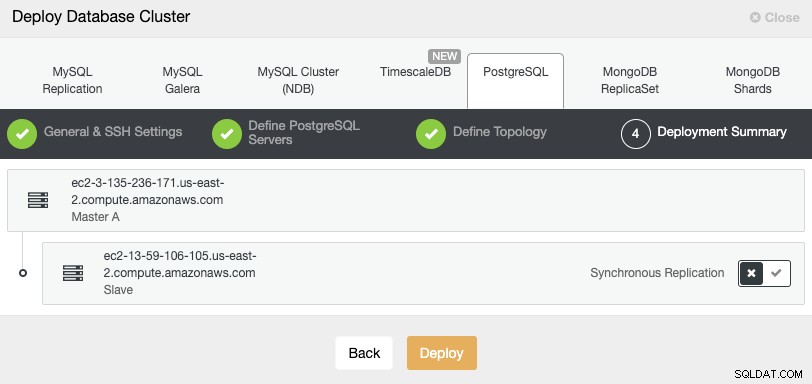
Im letzten Schritt können Sie wählen, ob Ihre Replikation synchron oder asynchron sein soll.
Falls Sie Ihren Remote-Knoten hier hinzufügen, ist es wichtig, die asynchrone Replikation zu verwenden, andernfalls könnte Ihr Cluster von Latenz- oder Netzwerkproblemen betroffen sein.
Sie können den Erstellungsstatus im Aktivitätsmonitor von ClusterControl überwachen.
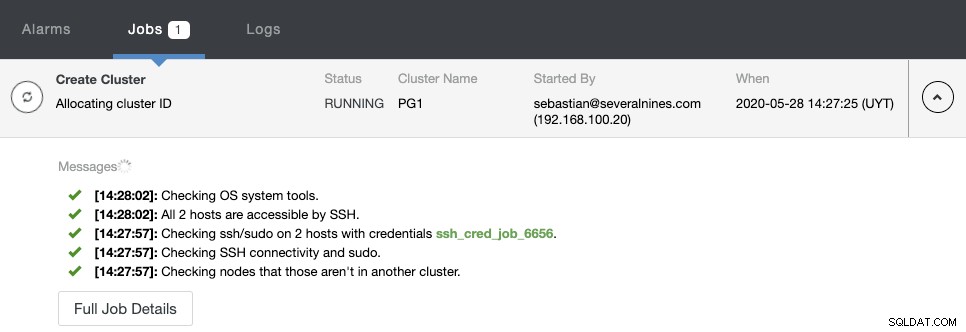
Sobald die Aufgabe abgeschlossen ist, können Sie Ihren neuen PostgreSQL-Cluster im Hauptbildschirm von ClusterControl sehen.

Hinzufügen eines Remote-Standby-Knotens
Sobald Sie Ihren Cluster erstellt haben, können Sie verschiedene Aufgaben darauf ausführen, wie z. B. einen Load Balancer oder einen Replikationsknoten bereitstellen/importieren.
Gehen Sie zu Cluster-Aktionen und wählen Sie „Replikations-Slave hinzufügen“:
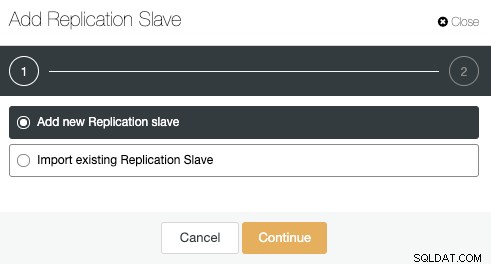
Lassen Sie uns die Option „Neuen Replikations-Slave hinzufügen“ verwenden, da wir davon ausgehen, dass der Remote-Knoten eine Neuinstallation ist, wenn nicht, können Sie stattdessen die Option „Vorhandenen Replikations-Slave importieren“ verwenden.
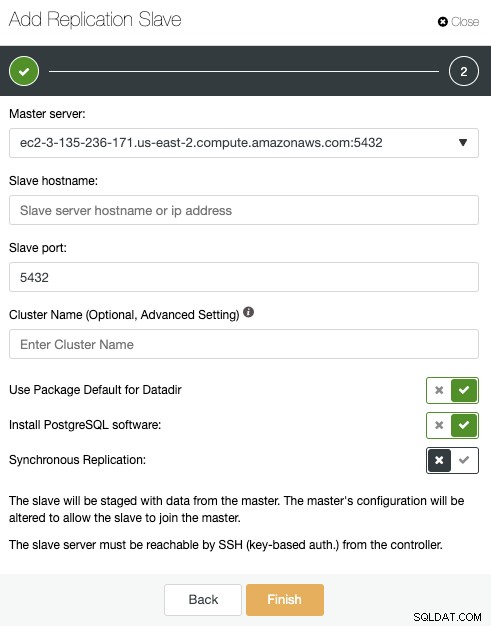
Hier müssen Sie nur Ihren Primärserver auswählen, die IP-Adresse Ihres neuen Standby-Servers und den Datenbankport eingeben. Anschließend können Sie wählen, ob ClusterControl die Software installieren soll und ob die Replikation synchron oder asynchron erfolgen soll. Auch hier gilt:Wenn Sie einen Knoten an einem anderen Standort hinzufügen (anderer Cloud-Anbieter oder lokal), sollten Sie die asynchrone Replikation verwenden, um Probleme im Zusammenhang mit der Netzwerkleistung zu vermeiden.
Auf diese Weise können Sie beliebig viele Replikate hinzufügen und den Leseverkehr mithilfe eines Lastenausgleichs verteilen, den Sie auch mit ClusterControl implementieren können.
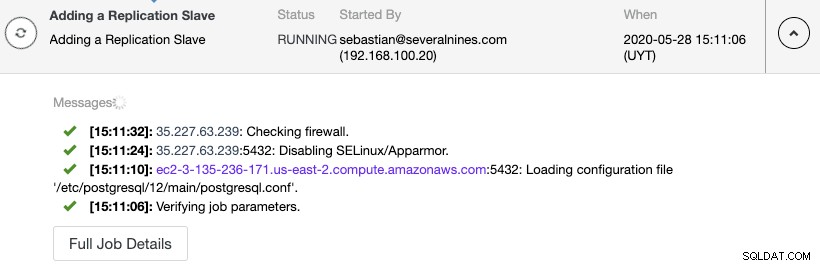
Sie können die Erstellung des Replikationsknotens im Aktivitätsmonitor von ClusterControl überwachen.
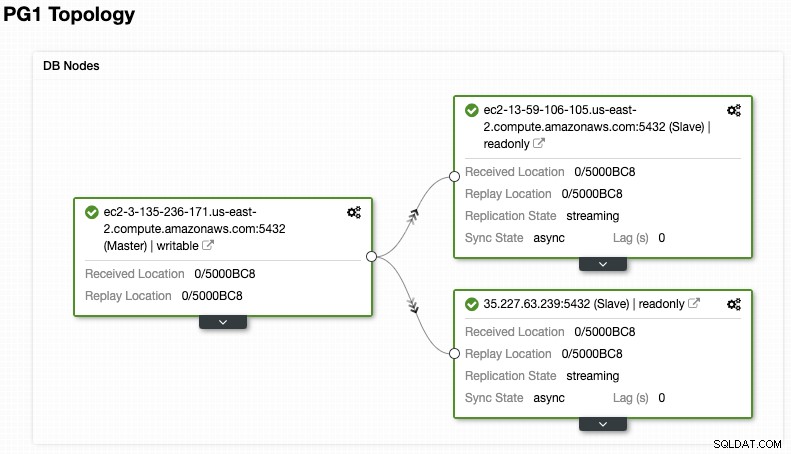
Und überprüfen Sie Ihre endgültige Topologie im Abschnitt "Topologieansicht".
Fazit
Mit diesen ClusterControl-Funktionen können Sie die Replikation in einer Hybrid-Cloud-Umgebung, zwischen verschiedenen Cloud-Anbietern oder sogar zwischen einem Cloud-Anbieter und einer On-Prem-Umgebung für eine PostgreSQL-Datenbank (und verschiedene Technologien) schnell einrichten und die Einrichtung in verwalten eine einfache und freundliche Art und Weise. Über die Kommunikation zwischen den Cloud-Anbietern oder zwischen privater und öffentlicher Cloud müssen Sie aus Sicherheitsgründen den Datenverkehr nur von bekannten Quellen einschränken, um das Risiko eines unbefugten Zugriffs auf Ihr Netzwerk zu verringern.