Das Thema Caching tauchte bereits vor 22 Jahren in PostgreSQL auf, und damals lag der Fokus auf der Datenbankzuverlässigkeit.
Schnell vorwärts bis 2020, die Plattenteller sind noch tiefer in virtualisierten Umgebungen, Hypervisoren und zugehörigen Speichergeräten verborgen. Darüber hinaus schreien vernetzte, verteilte Anwendungen, die auf globaler Ebene operieren, nach Verbindungen mit geringer Latenz und plötzlichem Optimieren von Server-Caches, und SQL-Abfragen konkurrieren darum, sicherzustellen, dass die Ergebnisse innerhalb von Millisekunden an Clients zurückgegeben werden. Caches auf Anwendungsebene und In-Memory-Caches werden geboren, und Leseabfragen werden jetzt in der Nähe der Anwendungsserver gespeichert. Dadurch werden E/A-Vorgänge auf Schreibvorgänge reduziert und die Netzwerklatenz drastisch verbessert. Mit einem Haken. Implementierungen sind für ihre eigene Cache-Verwaltung verantwortlich, was manchmal zu Leistungseinbußen führt.
Caching von Schreibvorgängen ist eine viel kompliziertere Angelegenheit, wie im PostgreSQL-Wiki erklärt.
Dieser Blog gibt einen Überblick über die In-Memory-Abfrage-Caches und Load-Balancer, die mit PostgreSQL verwendet werden.
PostgreSQL-Lastenausgleich
Die Idee des Lastenausgleichs entstand 1999 zur gleichen Zeit wie das Caching, als Bruce Momjiam schrieb:
[...] es ist möglich, dass wir in naher Zukunft _sehr_ beliebt werden.
Die Grundlage für die Implementierung des Lastausgleichs in PostgreSQL wird durch die integrierte Hot-Standby-Funktion bereitgestellt. Die einzige Voraussetzung ist, dass die Anwendung das Failover handhabt, und hier kommen Lösungen von Drittanbietern ins Spiel. Wir werden uns einige dieser Lösungen in den nächsten Abschnitten ansehen.
Load-Balancing-Abfragen können nur konsistente Ergebnisse zurückgeben, solange die synchrone Replikationsverzögerung gering gehalten wird. In der Praxis können selbst hochmoderne Netzwerkinfrastrukturen wie AWS Verzögerungen im zweistelligen Millisekundenbereich aufweisen:
Wir beobachten normalerweise Verzögerungszeiten im Bereich von 10 Millisekunden. [...] Unter typischen Bedingungen ist jedoch eine Replikationsverzögerung von weniger als einer Minute üblich. [...]
Regionsübergreifende Replikate mit logischer Replikation werden durch die Änderungs-/Anwendungsrate und Verzögerungen bei der Netzwerkkommunikation zwischen den ausgewählten Regionen beeinflusst. Regionsübergreifende Replikate, die die Aurora Global Database verwenden, haben eine typische Verzögerung von weniger als einer Sekunde.
Wie bereits erwähnt, verlassen sich die Lösungen von Drittanbietern auf Kernfunktionen von PostgreSQL. Beispielsweise wird der Lastausgleich von Leseanfragen durch mehrere synchrone Standbys erreicht.
Lösungen
pgpool-II
pgpool-II ist ein funktionsreiches Produkt, das sowohl Lastausgleich als auch In-Memory-Abfrage-Caching bietet. Es ist ein Drop-in-Ersatz, es sind keine Änderungen auf der Anwendungsseite erforderlich.
Als Load-Balancer untersucht pgpool-II jede SQL-Abfrage – um Load-Balancing zu erhalten, müssen SELECT-Abfragen mehrere Bedingungen erfüllen.
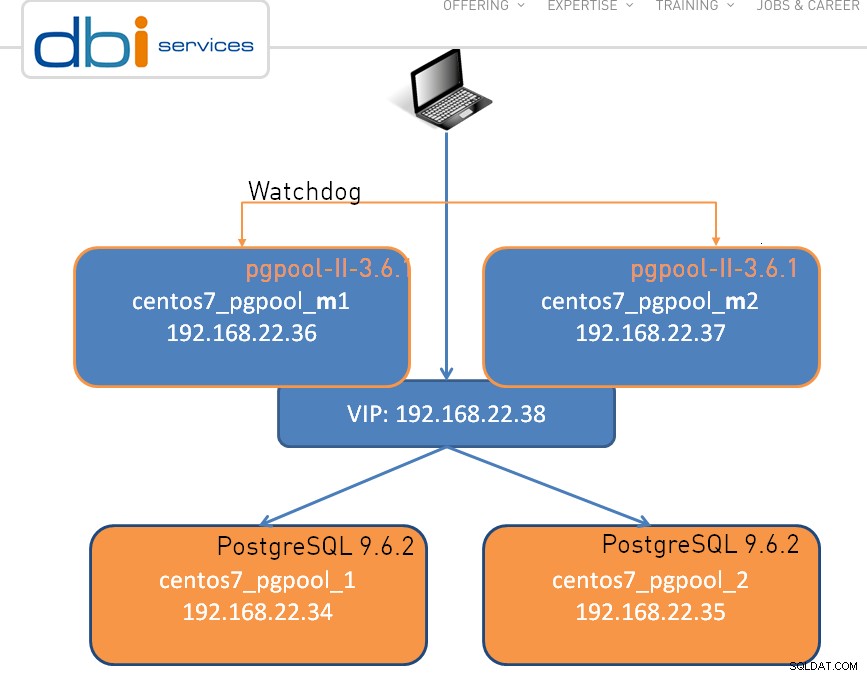
Die Einrichtung kann so einfach wie ein Knoten sein, unten gezeigt ist ein Dual-Knoten-Cluster:
Wie bei jeder großartigen Software gibt es gewisse Einschränkungen , und pgpool-II macht da keine Ausnahme:
- Es verarbeitet keine Abfragen mit mehreren Anweisungen.
- SELECT-Abfragen für temporäre Tabellen erfordern den SQL-Kommentar /*NO LOAD BALANCE*/.
Anwendungen, die in Hochleistungsumgebungen ausgeführt werden, profitieren von einer gemischten Konfiguration, bei der pgBouncer der Verbindungspooler ist und pgpool-II den Lastausgleich und das Caching übernimmt. Das Ergebnis ist eine beeindruckende 4-fache Durchsatzsteigerung und 40-prozentige Latenzreduzierung:
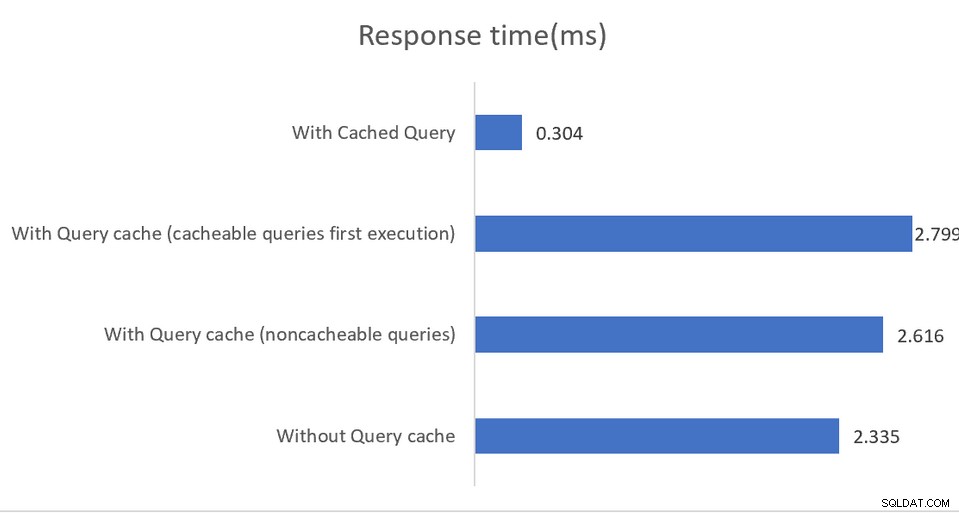
In-Memory-Caching funktioniert wiederum nur bei Leseabfragen mit cached Daten werden entweder im Shared Memory oder in einer externen Memcache-Installation gespeichert. Während die Dokumentation die verschiedenen Konfigurationsoptionen ziemlich gut erklärt, schlägt sie indirekt vor, dass Implementierungen die SHOW POOL CACHE-Ausgabe überwachen müssen, um bei Trefferquoten zu warnen, die unter die 70-%-Marke fallen, an welchem Punkt der durch das Caching erzielte Leistungsgewinn verloren geht.
Bucardo
Bucardo ist ein in Perl und PL/Perl geschriebenes PostgreSQL-Replikationstool.
Ich habe Bucardo erwähnt, weil Load-Balancing eines seiner Features ist, eine Internetsuche aber laut PostgreSQL-Wiki keine relevanten Ergebnisse liefert. Zur Verdeutlichung bin ich zur offiziellen Dokumentation gegangen, die detailliert erklärt, wie die Software tatsächlich funktioniert:

Damit ist ziemlich klar, dass Bucardo kein Load Balancer ist wurde von den Leuten bei Database Soup darauf hingewiesen.
HAProxy
HAProxy ist ein Allzweck-Load-Balancer, der auf TCP-Ebene arbeitet (für Datenbankverbindungen). Zustandsprüfungen stellen sicher, dass Abfragen nur an aktive Knoten gesendet werden.
Im Vergleich zu pgpool-II müssen Anwendungen, die HAProxy als Load-Balancer verwenden, darauf aufmerksam gemacht werden, dass der Endpunkt Anfragen an Reader-Knoten weiterleitet.
Apache Ignite
Apache Ignite ist ein Second-Level-Cache, der ANSI-99-SQL versteht und ACID-Transaktionen unterstützt. Apache Ignite versteht das PostgreSQL Frontend/Backend-Protokoll nicht und daher müssen Anwendungen entweder eine Persistenzschicht wie Hibernate ORM verwenden. Als Alternative zum Ändern von Anwendungen bietet Apache Ignite eine „Memcached-Integration“_, die die Memcached-PostgreSQL-Erweiterung erfordert. Leider ist letztere Option nicht mit neueren Versionen von PostgreSQL kompatibel, da die pgmemcache-Erweiterung zuletzt im Jahr 2017 aktualisiert wurde.
Heimdall-Daten
Als kommerzielles Produkt erfüllt Heimdall Data beide Kriterien:Load Balancing und Caching. Es ist ein ausgereiftes Produkt, das bereits auf der PGCon 2017 auf PostgreSQL-Konferenzen vorgestellt wurde:

Weitere Details und eine Produktdemo finden Sie im Blog zu Azure für PostgreSQL .
Fazit
Im heutigen verteilten Computing sind Query Caching und Load Balancing für die Leistungsoptimierung von PostgreSQL genauso wichtig wie die bekannten GUCs, OS-Kernel, Speicher und Abfrageoptimierung. Während pgpool-II und Heimdall Data die Open Source bzw. die kommerziell bevorzugten Lösungen sind, gibt es Fälle, in denen speziell entwickelte Tools als Bausteine verwendet werden können, um ähnliche Ergebnisse zu erzielen.