Es müssen viele leistungsstarke Tools als Sicherungs- und Wiederherstellungsoption für PostgreSQL im Allgemeinen verfügbar sein; Barman, PgBackRest, BART sind in diesem Zusammenhang nur einige zu nennen. Was unsere Aufmerksamkeit erregte, war, dass Barman ein Werkzeug ist, das schnell mit dem Produktionseinsatz und den Markttrends Schritt hält.
Sei es eine Docker-basierte Bereitstellung, die Notwendigkeit, Backups in einem anderen Cloud-Speicher zu speichern oder eine hochgradig anpassbare Disaster-Recovery-Architektur zu benötigen - Barman ist in all diesen Fällen ein sehr starker Konkurrent.
Dieser Blog untersucht Barman mit wenigen Annahmen zur Bereitstellung, jedoch sollte dies auf keinen Fall als nur möglicher Funktionsumfang betrachtet werden. Barman geht weit über das hinaus, was wir in diesem Blog erfassen können, und muss weiter untersucht werden, wenn „Sichern und Wiederherstellen einer PostgreSQL-Instanz“ in Betracht gezogen wird.
Annahme einer DR-bereiten Bereitstellung
RPO=0 ist im Allgemeinen mit Kosten verbunden - die synchrone Bereitstellung von Standby-Servern würde dies häufig erreichen, wirkt sich dann jedoch häufig auf den TPS des primären Servers aus.
Wie PostgreSQL bietet Barman zahlreiche Bereitstellungsoptionen, um Ihre Anforderungen in Bezug auf RPO und Leistung zu erfüllen. Denken Sie an die Einfachheit der Bereitstellung, RPO =0 oder Leistungseinbußen von nahezu null; Barmann passt in alle hinein.
Wir haben die folgende Bereitstellung in Betracht gezogen, um eine Notfallwiederherstellungslösung für unsere Sicherungs- und Wiederherstellungsarchitektur einzurichten.
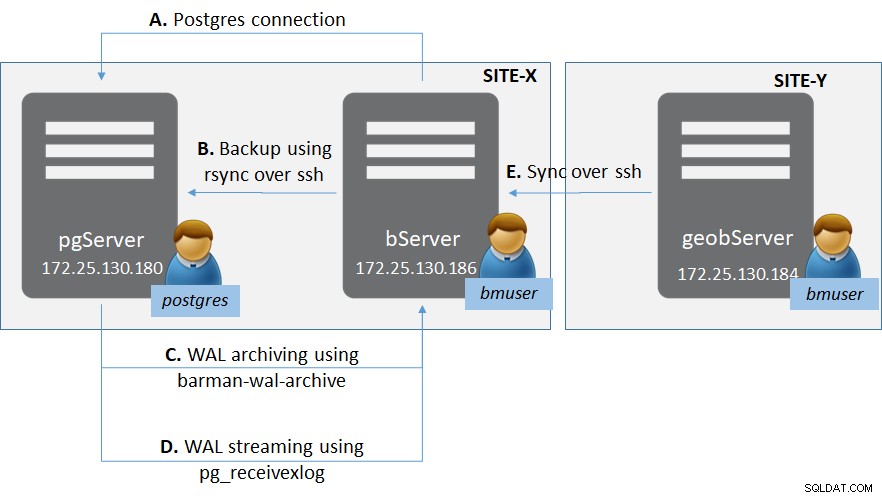 Abbildung 1:PostgreSQL-Bereitstellung mit Barman
Abbildung 1:PostgreSQL-Bereitstellung mit BarmanEs gibt zwei Seiten (wie allgemein für Disaster-Recovery-Standorte) - Standort-X und Standort-Y.
In Site-X gibt es:
- Ein Server „pgServer“, der eine PostgreSQL-Serverinstanz pgServer hostet, und ein Betriebssystembenutzer „postgres“
- PostgreSQL-Instanz auch zum Hosten einer Superuser-Rolle „bmuser“
- Ein Server „bServer“, auf dem die Barman-Binärdateien gehostet werden, und ein Betriebssystembenutzer „bmuser“
In Site-Y gibt es:
- Ein Server „geobServer“, auf dem die Barman-Binärdateien gehostet werden, und ein Betriebssystembenutzer „bmuser“
Bei diesem Setup sind mehrere Verbindungstypen beteiligt.
- Zwischen „bServer“ und „pgServer“:
- Konnektivität auf Verwaltungsebene von Barman zur PostgreSQL-Instanz
- rsync-Konnektivität, um eine tatsächliche Basissicherung von Barman zur PostgreSQL-Instanz durchzuführen
- WAL-Archivierung mit barman-wal-archive von der PostgreSQL-Instanz zu Barman
- WAL-Streaming mit pg_receivexlog bei Barman
- Zwischen „bServer“ und „geobserver“:
- Synchronisation zwischen Barman-Servern zur Bereitstellung von Geo-Replikation
Verbindung zuerst
Die primäre Konnektivität zwischen den Servern erfolgt über ssh. Um es passwortlos zu machen, werden ssh-Schlüssel verwendet. Lassen Sie uns die ssh-Schlüssel erstellen und austauschen.
Auf pgServer:
example@sqldat.com$ ssh-keygen -q -t rsa -N '' -f ~/.ssh/id_rsa <<<y 2>&1 >/dev/null
example@sqldat.com$ ssh-copy-id -i ~/.ssh/id_rsa.pub example@sqldat.com
example@sqldat.com$ ssh example@sqldat.com "chmod 600 ~/.ssh/authorized_keys"Auf bServer:
example@sqldat.com$ ssh-keygen -q -t rsa -N '' -f ~/.ssh/id_rsa <<<y 2>&1 >/dev/null
example@sqldat.com$ ssh-copy-id -i ~/.ssh/id_rsa.pub example@sqldat.com
example@sqldat.com$ ssh example@sqldat.com "chmod 600 ~/.ssh/authorized_keys"Auf geobServer:
example@sqldat.com$ ssh-keygen -q -t rsa -N '' -f ~/.ssh/id_rsa <<<y 2>&1 >/dev/null
example@sqldat.com$ ssh-copy-id -i ~/.ssh/id_rsa.pub example@sqldat.com
example@sqldat.com$ ssh example@sqldat.com "chmod 600 ~/.ssh/authorized_keys"PostgreSQL-Instanzkonfiguration
Es gibt zwei Hauptdinge, die wir brauchen, um eine Postgres-Instanz neu zu erstellen - Das Basisverzeichnis und die danach generierten WAL-/Transaktionsprotokolle. Der Barmann-Server verfolgt sie intelligent. Was wir brauchen, ist sicherzustellen, dass richtige Feeds generiert werden, damit Barman diese Artefakte sammeln kann.
Fügen Sie folgende Zeilen zu postgresql.conf hinzu:
listen_addresses = '172.25.130.180' #as per above deployment assumption
wal_level = replica #or higher
archive_mode = on
archive_command = 'barman-wal-archive -U bmuser bserver pgserver %p'Der Archivierungsbefehl stellt sicher, dass, wenn WAL von der Postgres-Instanz archiviert werden soll, das Dienstprogramm barman-wal-archive es an den Barman-Server übermittelt. Es sollte beachtet werden, dass das Paket barman-cli daher auf ‚pgServer‘ verfügbar gemacht werden sollte. Es gibt eine weitere Option zur Verwendung von rsync, wenn wir das Dienstprogramm barman-wal-archive nicht verwenden möchten.
Fügen Sie Folgendes zu pg_hba.conf hinzu:
host all all 172.25.130.186/32 md5
host replication all 172.25.130.186/32 md5Es erlaubt grundsätzlich eine Replikation und eine normale Verbindung von ‚bmserver‘ zu dieser Postgres-Instanz.
Starten Sie jetzt einfach die Instanz neu und erstellen Sie eine Superuser-Rolle namens bmuser:
example@sqldat.com$ pg_ctl restart
example@sqldat.com$ createuser -s -P bmuser Bei Bedarf können wir die Verwendung von bmuser auch als Superuser vermeiden; dafür müssten diesem Benutzer Berechtigungen zugewiesen werden. Für das obige Beispiel haben wir auch bmuser als Passwort verwendet. Aber das ist so ziemlich alles, soweit eine PostgreSQL-Instanzkonfiguration erforderlich ist.
Barkeeper-Konfiguration
Barman hat drei grundlegende Komponenten in seiner Konfiguration:
- Globale Konfiguration
- Konfiguration auf Serverebene
- Benutzer, der den Barkeeper leiten wird
Da Barman in unserem Fall mit rpm installiert wird, haben wir unsere globalen Konfigurationsdateien unter:
gespeichert/etc/barman.confWir wollten die Konfiguration auf Serverebene im Home-Verzeichnis von bmuser speichern, daher hatte unsere globale Konfigurationsdatei den folgenden Inhalt:
[barman]
barman_user = bmuser
configuration_files_directory = /home/bmuser/barman.d
barman_home = /home/bmuser
barman_lock_directory = /home/bmuser/run
log_file = /home/bmuser/barman.log
log_level = INFOKonfiguration des primären Barkeeper-Servers
In der obigen Bereitstellung haben wir uns entschieden, den primären Barman-Server im selben Rechenzentrum/Standort zu halten, wo die PostgreSQL-Instanz aufbewahrt wird. Der Vorteil davon ist, dass es im Bedarfsfall zu weniger Verzögerungen und einer schnelleren Wiederherstellung kommt. Unnötig zu erwähnen, dass auch auf dem PostgreSQL-Server weniger Rechenleistung und/oder Netzwerkbandbreite benötigt werden.
Damit Barman die PostgreSQL-Instanz auf dem pgServer verwalten kann, müssen wir eine Konfigurationsdatei (die wir pgserver.conf genannt haben) mit folgendem Inhalt hinzufügen:
[pgserver]
description = "Example pgserver configuration"
ssh_command = ssh example@sqldat.com
conninfo = host=pgserver user=bmuser dbname=postgres
backup_method = rsync
reuse_backup = link
backup_options = concurrent_backup
parallel_jobs = 2
archiver = on
archiver_batch_size = 50
path_prefix = "/usr/pgsql-12/bin"
streaming_conninfo = host=pgserver user=bmuser dbname=postgres
streaming_archiver=on
create_slot = autoUnd eine .pgpass-Datei, die die Anmeldeinformationen für bmuser in der PostgreSQL-Instanz enthält:
echo 'pgserver:5432:*:bmuser:bmuser' > ~/.pgpass Um die wichtigen Konfigurationselemente etwas besser zu verstehen:
- ssh_command :Wird verwendet, um eine Verbindung herzustellen, über die rsync ausgeführt wird
- conninfo :Verbindungszeichenfolge, damit Barman eine Verbindung mit dem Postgres-Server herstellen kann
- reuse_backup :Um eine inkrementelle Sicherung mit weniger Speicherplatz zuzulassen
- backup_method :Methode zum Sichern des Basisverzeichnisses
- path_prefix :Ort, an dem pg_receivexlog-Binärdateien gespeichert sind
- streaming_conninfo :Verbindungszeichenfolge zum Streamen von WAL
- create_slot :Um sicherzustellen, dass Slots von einer Postgres-Instanz erstellt wurden
Passive Barkeeper-Serverkonfiguration
Die Konfiguration einer Georeplikations-Site ist ziemlich einfach. Alles, was es braucht, ist eine SSH-Verbindungsinformation, über die diese passive Knotenseite die Replikation durchführt.
Interessant ist, dass solch ein passiver Knoten im Mix-Modus arbeiten kann; mit anderen Worten - sie können als aktive Barman-Server fungieren, um Backups für PostgreSQL-Sites durchzuführen, und gleichzeitig als Replikation/kaskadierte Site für andere Barman-Server fungieren.
Da diese Instanz von Barman (auf Site-Y) in unserem Fall nur ein passiver Knoten sein muss, brauchen wir nur die Datei /home/bmuser/barman.d/pgserver.conf zu erstellen mit folgender Konfiguration:
[pgserver]
description = "Geo-replication or sync for pgserver"
primary_ssh_command = ssh example@sqldat.comUnter der Annahme, dass die Schlüssel ausgetauscht wurden und die globale Konfiguration auf diesem Knoten wie zuvor erwähnt erfolgt ist, sind wir mit der Konfiguration ziemlich fertig.
Und hier ist unsere erste Sicherung und Wiederherstellung
Stellen Sie auf dem bserver sicher, dass der Hintergrundprozess zum Empfangen von WAL ausgelöst wurde; und überprüfen Sie dann die Konfiguration des Servers:
example@sqldat.com$ barman cron
example@sqldat.com$ barman check pgserverDie Prüfung sollte für alle Teilschritte OK sein. Wenn nicht, siehe /home/bmuser/barman.log.
Sicherungsbefehl an Barman ausgeben, um sicherzustellen, dass es eine Basis-DATEN gibt, auf die WAL angewendet werden kann:
example@sqldat.com$ barman backup pgserverStellen Sie auf dem „geobmserver“ sicher, dass die Replikation erfolgt, indem Sie die folgenden Befehle ausführen:
example@sqldat.com$ barman cron
example@sqldat.com$ barman list-backup pgserverDer Cron sollte in die Crontab-Datei eingefügt werden (falls nicht vorhanden). Der Einfachheit halber habe ich es hier nicht gezeigt. Der letzte Befehl zeigt, dass der Sicherungsordner auch auf dem geobmserver erstellt wurde.
Lassen Sie uns nun auf der Postgres-Instanz einige Dummy-Daten erstellen:
example@sqldat.com$ psql -U postgres -c "CREATE TABLE dummy_data( i INTEGER);"
example@sqldat.com$ psql -U postgres -c "insert into dummy_data values ( generate_series (1, 1000000 ));"Die Replikation der WAL von der PostgreSQL-Instanz kann mit dem folgenden Befehl angezeigt werden:
example@sqldat.com$ psql -U postgres -c "SELECT * from pg_stat_replication ;”Um eine Instanz auf Site-Y neu zu erstellen, stellen Sie zunächst sicher, dass WAL-Einträge umgeschaltet werden. oder dieses Beispiel, um eine saubere Wiederherstellung zu erstellen:
example@sqldat.com$ barman switch-xlog --force --archive pgserverLassen Sie uns auf Site-X eine eigenständige PostgreSQL-Instanz aufrufen, um zu prüfen, ob die Sicherung in Ordnung ist:
example@sqldat.com$ barman cron
barman recover --get-wal pgserver latest /tmp/dataBearbeiten Sie nun die Dateien postgresql.conf und postgresql.auto.conf nach Bedarf. Im Folgenden werden die für dieses Beispiel vorgenommenen Änderungen erläutert:
- postgresql.conf :listen_addresses kommentiert, um standardmäßig localhost zu verwenden
- postgresql.auto.conf :sudo bmuser von restore_command entfernt
Rufen Sie diese DATEN in /tmp/data auf und überprüfen Sie die Existenz Ihrer Datensätze.
Fazit
Das war nur die Spitze eines Eisbergs. Barman ist aufgrund der Funktionen, die es bietet, viel tiefer als dies - z. fungiert als synchronisierter Standby, Hook-Skripte und so weiter. Unnötig zu erwähnen, dass die gesamte Dokumentation untersucht werden sollte, um sie gemäß den Anforderungen Ihrer Produktionsumgebung zu konfigurieren.