Wie Sie vielleicht in meinem vorherigen Blog bemerkt haben, waren die letzten Monate damit beschäftigt, Postgres-XL mit der neuesten Version 9.5 von PostgreSQL auf den neuesten Stand zu bringen. Nachdem wir eine halbwegs stabile Version von Postgres-XL 9.5 hatten, haben wir unsere Aufmerksamkeit darauf gerichtet, die Leistung dieser brandneuen Version von Postgres-XL zu messen. Unsere Wahl des Benchmarks wird weitgehend von der laufenden Arbeit am AXLE-Projekt beeinflusst, das von der Europäischen Union im Rahmen der Fördervereinbarung 318633 finanziert wird. Da wir TPC BENCHMARK™ H verwenden, um die Leistung aller anderen im Rahmen dieses Projekts durchgeführten Arbeiten zu messen, haben wir uns dafür entschieden Verwenden Sie denselben Benchmark zur Bewertung von Postgres-XL. Es passt auch zu Postgres-XL, da TPC-H versucht, OLAP-Workloads zu messen, etwas, das Postgres-XL gut machen sollte.
1. Einrichtung des Postgres-XL-Clusters
Nachdem der Benchmark festgelegt war, bestand eine weitere große Herausforderung darin, die richtigen Ressourcen zum Testen zu finden. Wir hatten keinen Zugriff auf eine große Gruppe physischer Maschinen. Also taten wir, was die meisten tun würden. Wir haben uns entschieden, Amazon AWS für die Einrichtung des Postgres-XL-Clusters zu verwenden. AWS bietet eine große Auswahl an Instanzen, wobei jeder Instanztyp unterschiedliche Rechen- oder E/A-Leistung bietet.
Diese Seite auf AWS zeigt verschiedene verfügbare Instanztypen, verfügbare Ressourcen und ihre Preise für verschiedene Regionen. Es muss beachtet werden, dass die Preise und die Verfügbarkeit von Region zu Region variieren können, daher ist es wichtig, dass Sie sich alle Regionen ansehen. Da Postgres-XL eine geringe Latenz und einen hohen Durchsatz zwischen seinen Komponenten erfordert, ist es auch wichtig, alle Instanzen in derselben Region zu instanziieren. Für unseren 3 TB TPC-H haben wir uns für einen 16-Datenknoten-Cluster von i2.xlarge-AWS-Instanzen entschieden. Diese Instanzen haben jeweils 4 vCPU, 30 GB RAM und 800 GB SSD, ausreichend Speicherplatz, um alle verteilten Tabellen, replizierten Tabellen (die mit zunehmender Größe des Clusters mehr Platz beanspruchen), die darauf befindlichen Indizes zu speichern und dennoch genügend freien Speicherplatz zu lassen im temporären Tablespace für CREATE INDEX und andere Abfragen.
2. Benchmark-Setup
2.1 TPC Benchmark™ H
Der Benchmark enthält 22 Abfragen mit dem Zweck, große Datenmengen zu untersuchen, Abfragen mit einem hohen Grad an Komplexität auszuführen und Antworten auf kritische Geschäftsfragen zu geben. Wir möchten darauf hinweisen, dass die vollständige TPC Benchmark™ H-Spezifikation eine Vielzahl von Tests wie Last, Leistung und Durchsatz behandelt Prüfungen. Für unsere Tests haben wir nur einzelne Abfragen ausgeführt und nicht die vollständige Testsuite. TPC Benchmark™ H besteht aus einer Reihe von Geschäftsabfragen, die entwickelt wurden, um Systemfunktionalitäten in einer Weise auszuführen, die für komplexe Geschäftsanalyseanwendungen repräsentativ ist. Diesen Abfragen wurde ein realistischer Kontext gegeben, der die Aktivität eines Großhandelslieferanten darstellt, um dem Leser zu helfen, sich intuitiv auf die Komponenten des Benchmarks zu beziehen.
2.2 Datenbankentitäten, -beziehungen und -merkmale
Die Komponenten der TPC-H-Datenbank sind so definiert, dass sie aus acht separaten und individuellen Tabellen (den Basistabellen) bestehen. Die Beziehungen zwischen den Spalten dieser Tabellen sind im folgenden Diagramm dargestellt. 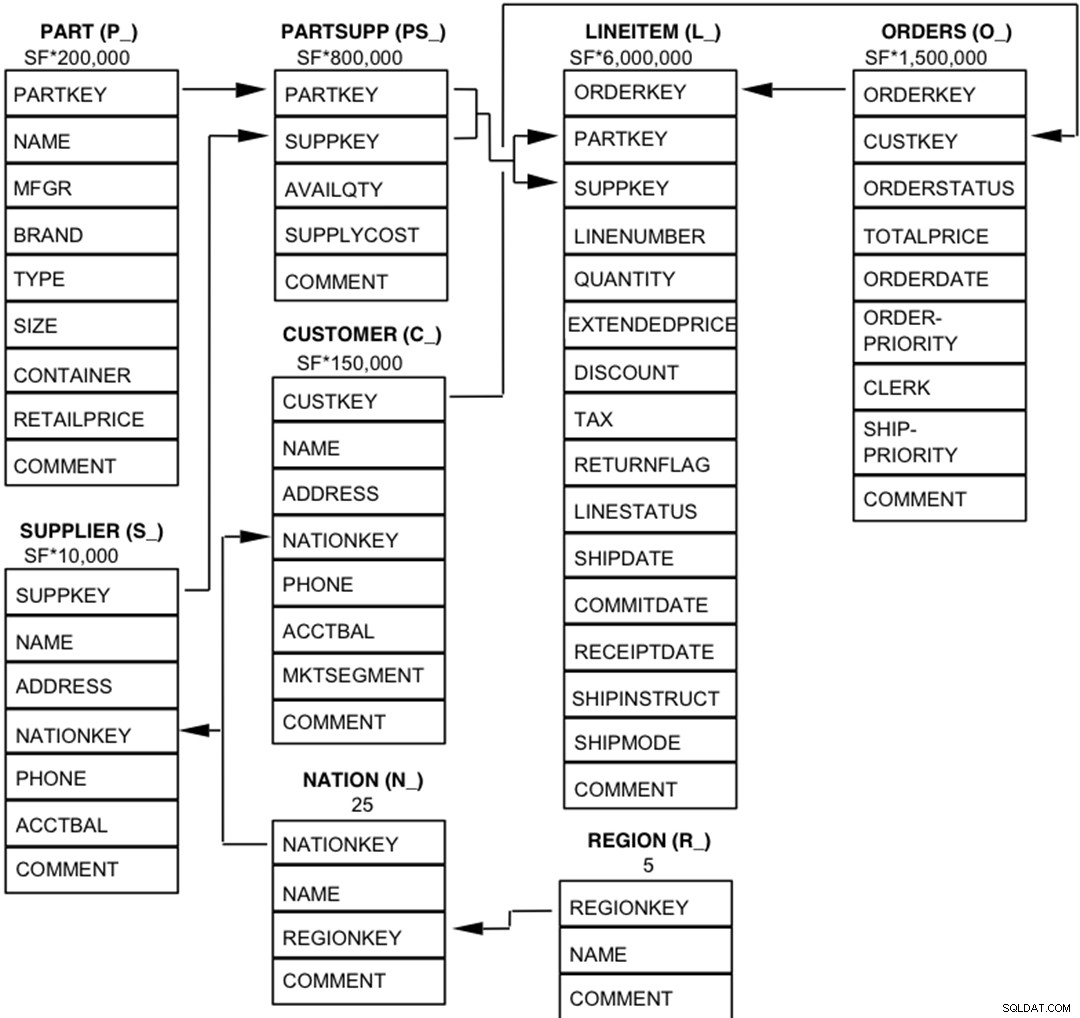 Legende :
Legende :
- Die Klammern hinter jedem Tabellennamen enthalten das Präfix der Spaltennamen für diese Tabelle;
- Die Pfeile zeigen in die Richtung der 1:n-Beziehungen zwischen Tabellen
- Die Zahl/Formel unter jedem Tabellennamen repräsentiert die Kardinalität (Anzahl der Zeilen) der Tabelle. Einige werden durch SF, den Skalierungsfaktor, faktorisiert, um die gewählte Datenbankgröße zu erhalten. Die Kardinalität für die Tabelle LINEITEM ist ungefähr
2.3 Datenverteilung für Postgres-XL
Wir haben alle 22 Abfragen im Benchmark analysiert und die folgende Datenverteilungsstrategie für verschiedene Tabellen im Benchmark entwickelt.
| Tabellenname | Vertriebsstrategie |
| LINEITEM | HASH (l_orderkey) |
| BESTELLUNGEN | HASH (o_orderkey) |
| TEIL | HASH (p_partkey) |
| PARTSUPP | HASH (ps_partkey) |
| KUNDE | REPLIZIERT |
| LIEFERANT | REPLIZIERT |
| NATION | REPLIZIERT |
| REGION | WIEDERHOLT |
Beachten Sie, dass LINEITEM und ORDERS, die größten Tabellen im Benchmark, oft auf dem ORDERKEY verbunden sind. Daher ist es sehr sinnvoll, diese Tabellen auf dem ORDERKEY zusammenzufassen. In ähnlicher Weise werden PART und PARTSUPP häufig auf PARTKEY verknüpft und daher in der PARTKEY-Spalte zusammengefasst. Der Rest der Tabellen wird repliziert, um sicherzustellen, dass sie bei Bedarf lokal verknüpft werden können.
3. Benchmark-Ergebnisse
3.1 Belastungstest
Wir haben die Ergebnisse eines 3-TB-TPC-H-Lasttests auf PostgreSQL 9.6 mit dem 16-Knoten-Postgres-XL-Cluster verglichen. Die folgenden Diagramme zeigen die Leistungsmerkmale von Postgres-XL.
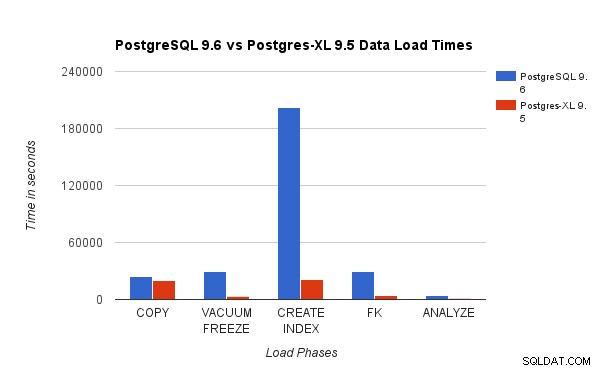 Das obige Diagramm zeigt die Zeit, die benötigt wird, um verschiedene Phasen eines Lasttests mit PostgreSQL und Postgres-XL abzuschließen. Wie Sie sehen, schneidet Postgres-XL für COPY etwas besser ab und für alle anderen Fälle viel besser. Hinweis Hinweis:Wir haben festgestellt, dass der Koordinator während der COPY-Phase viel Rechenleistung benötigt, insbesondere wenn mehr als ein COPY-Stream gleichzeitig ausgeführt wird. Um dem entgegenzuwirken, wurde der Koordinator auf einer rechenoptimierten AWS-Instance mit 16 vCPU ausgeführt. Alternativ hätten wir auch mehrere Koordinatoren ausführen und die Rechenlast zwischen ihnen verteilen können.
Das obige Diagramm zeigt die Zeit, die benötigt wird, um verschiedene Phasen eines Lasttests mit PostgreSQL und Postgres-XL abzuschließen. Wie Sie sehen, schneidet Postgres-XL für COPY etwas besser ab und für alle anderen Fälle viel besser. Hinweis Hinweis:Wir haben festgestellt, dass der Koordinator während der COPY-Phase viel Rechenleistung benötigt, insbesondere wenn mehr als ein COPY-Stream gleichzeitig ausgeführt wird. Um dem entgegenzuwirken, wurde der Koordinator auf einer rechenoptimierten AWS-Instance mit 16 vCPU ausgeführt. Alternativ hätten wir auch mehrere Koordinatoren ausführen und die Rechenlast zwischen ihnen verteilen können.
3.2 Leistungstest
Wir haben auch die Abfragelaufzeiten für den 3-TB-Benchmark auf PostgreSQL 9.6 und Postgres-XL 9.5 verglichen. Das folgende Diagramm zeigt die Leistungsmerkmale der Abfrageausführung in den beiden Setups.
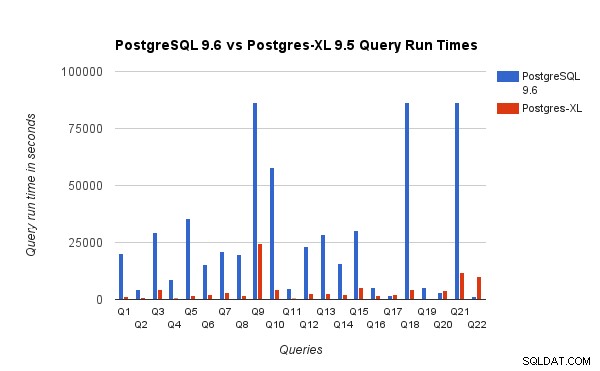 Wir haben festgestellt, dass Abfragen auf Postgres-XL im Durchschnitt etwa 6,4-mal schneller liefen und mindestens 25 % der Abfragen zeigten eine nahezu lineare Leistungsverbesserung, mit anderen Worten, sie arbeiteten auf diesem 16-Knoten-Postgres-XL-Cluster fast 16-mal schneller. Darüber hinaus zeigten mindestens 50 % der Abfragen eine 10-fache Leistungssteigerung. Wir haben die Abfrageleistungen weiter analysiert und sind zu dem Schluss gekommen, dass Abfragen, die gut über alle verfügbaren Datenknoten verteilt sind, sodass ein minimaler Datenaustausch zwischen Knoten und ohne wiederholte Remoteausführungsaufrufe stattfindet, in Postgres-XL sehr gut skalieren. Solche Abfragen haben normalerweise oben einen Remote Subquery Scan-Knoten, und der Unterbaum unter dem Knoten wird parallel auf einem oder mehreren Knoten ausgeführt. Es ist auch üblich, einige andere Knoten, wie z. B. einen Limit-Knoten oder einen Aggregate-Knoten, über dem Remote Subquery Scan-Knoten zu haben. Selbst solche Abfragen funktionieren auf Postgres-XL sehr gut. Abfrage Q1 ist ein Beispiel für eine Abfrage, die sehr gut mit Postgres-XL skalieren sollte. Andererseits funktionieren Abfragen, die einen großen Austausch von Tupeln zwischen datanode-datanode und/oder coordinator-datanode erfordern, in Postgres-XL möglicherweise nicht gut. Ebenso können Abfragen, die viele knotenübergreifende Verbindungen erfordern, ebenfalls eine schlechte Leistung zeigen. Sie werden beispielsweise feststellen, dass die Leistung von Q22 im Vergleich zu einem PostgreSQL-Server mit einem Knoten schlecht ist. Als wir den Abfrageplan für Q22 analysierten, stellten wir fest, dass der Abfrageplan drei Ebenen von verschachtelten Remote Subquery Scan-Knoten enthält, wobei jeder Knoten die gleiche Anzahl von Verbindungen zu den Datenknoten öffnet. Darüber hinaus hat der Nest Loop Anti Join eine innere Beziehung mit einem Remote Subquery Scan-Knoten der obersten Ebene und muss daher für jedes Tupel der äußeren Beziehung eine Remote-Unterabfrage ausführen. Dies führt zu einer schlechten Leistung der Abfrageausführung.
Wir haben festgestellt, dass Abfragen auf Postgres-XL im Durchschnitt etwa 6,4-mal schneller liefen und mindestens 25 % der Abfragen zeigten eine nahezu lineare Leistungsverbesserung, mit anderen Worten, sie arbeiteten auf diesem 16-Knoten-Postgres-XL-Cluster fast 16-mal schneller. Darüber hinaus zeigten mindestens 50 % der Abfragen eine 10-fache Leistungssteigerung. Wir haben die Abfrageleistungen weiter analysiert und sind zu dem Schluss gekommen, dass Abfragen, die gut über alle verfügbaren Datenknoten verteilt sind, sodass ein minimaler Datenaustausch zwischen Knoten und ohne wiederholte Remoteausführungsaufrufe stattfindet, in Postgres-XL sehr gut skalieren. Solche Abfragen haben normalerweise oben einen Remote Subquery Scan-Knoten, und der Unterbaum unter dem Knoten wird parallel auf einem oder mehreren Knoten ausgeführt. Es ist auch üblich, einige andere Knoten, wie z. B. einen Limit-Knoten oder einen Aggregate-Knoten, über dem Remote Subquery Scan-Knoten zu haben. Selbst solche Abfragen funktionieren auf Postgres-XL sehr gut. Abfrage Q1 ist ein Beispiel für eine Abfrage, die sehr gut mit Postgres-XL skalieren sollte. Andererseits funktionieren Abfragen, die einen großen Austausch von Tupeln zwischen datanode-datanode und/oder coordinator-datanode erfordern, in Postgres-XL möglicherweise nicht gut. Ebenso können Abfragen, die viele knotenübergreifende Verbindungen erfordern, ebenfalls eine schlechte Leistung zeigen. Sie werden beispielsweise feststellen, dass die Leistung von Q22 im Vergleich zu einem PostgreSQL-Server mit einem Knoten schlecht ist. Als wir den Abfrageplan für Q22 analysierten, stellten wir fest, dass der Abfrageplan drei Ebenen von verschachtelten Remote Subquery Scan-Knoten enthält, wobei jeder Knoten die gleiche Anzahl von Verbindungen zu den Datenknoten öffnet. Darüber hinaus hat der Nest Loop Anti Join eine innere Beziehung mit einem Remote Subquery Scan-Knoten der obersten Ebene und muss daher für jedes Tupel der äußeren Beziehung eine Remote-Unterabfrage ausführen. Dies führt zu einer schlechten Leistung der Abfrageausführung.
4. Ein paar AWS-Lektionen
Beim Benchmarking von Postgres-XL haben wir einige Lektionen über die Verwendung von AWS gelernt. Wir dachten, dass sie für jeden nützlich sein werden, der Postgres-XL auf AWS verwenden/testen möchte.
- AWS bietet verschiedene Arten von Instanzen an. Sie müssen Ihre Arbeitslast und den erforderlichen Speicherplatz sorgfältig abwägen, bevor Sie sich für einen bestimmten Instanztyp entscheiden.
- An die meisten speicheroptimierten Instanzen sind flüchtige Laufwerke angehängt. Sie müssen für diese Festplatten nichts zusätzlich bezahlen, sie sind an die Instanz angehängt und bieten oft eine bessere Leistung als EBS. Sie müssen sie jedoch explizit einhängen, um sie verwenden zu können. Beachten Sie jedoch, dass die auf diesen Datenträgern gespeicherten Daten nicht dauerhaft sind und gelöscht werden, wenn die Instanz gestoppt wird. Stellen Sie also sicher, dass Sie auf diese Situation vorbereitet sind. Da wir AWS hauptsächlich zum Benchmarking verwendet haben, haben wir uns für diese kurzlebigen Festplatten entschieden.
- Wenn Sie EBS verwenden, stellen Sie sicher, dass Sie geeignete bereitgestellte IOPS auswählen. Ein zu niedriger Wert führt zu sehr langsamen E/A, aber ein sehr hoher Wert kann Ihre AWS-Rechnung erheblich erhöhen, insbesondere wenn es um eine große Anzahl von Knoten geht.
- Stellen Sie sicher, dass Sie die Instanzen in derselben Zone starten, um die Latenz zu verringern und den Durchsatz für Verbindungen zwischen ihnen zu verbessern.
- Stellen Sie sicher, dass Sie Instanzen so konfigurieren, dass sie ein privates Netzwerk verwenden, um miteinander zu kommunizieren.
- Sehen Sie sich Spot-Instanzen an. Sie sind relativ billiger. Da AWS Spot-Instances nach Belieben beenden kann, sollten Sie beispielsweise darauf vorbereitet sein, wenn der Spot-Preis über Ihrem maximalen Gebotspreis liegt. Postgres-XL kann teilweise oder vollständig unbrauchbar werden, je nachdem, welche Knoten beendet werden. AWS unterstützt ein Konzept von launch_group. Wenn mehrere Instanzen in derselben launch_group, gruppiert sind wenn AWS beschließt, eine Instanz zu beenden, werden alle Instanzen beendet.
5. Fazit
Wir können durch verschiedene Benchmarks zeigen, dass Postgres-XL wirklich gut für eine große Menge realer, komplexer Abfragen skaliert werden kann. Diese Benchmarks helfen uns, die Leistungsfähigkeit von Postgres-XL als effektive Lösung für OLAP-Workloads zu demonstrieren. Unsere Experimente zeigen auch, dass es einige Leistungsprobleme mit Postgres-XL gibt, insbesondere bei sehr großen Clustern und wenn der Planer eine schlechte Wahl eines Plans trifft. Wir haben auch beobachtet, dass sich die Leistung verschlechtert, wenn eine sehr große Anzahl gleichzeitiger Verbindungen zu einem Datenknoten besteht. Wir werden weiterhin an diesen Leistungsproblemen arbeiten. Wir möchten auch die Fähigkeit von Postgres-XL als OLTP-Lösung testen, indem wir geeignete Workloads verwenden.