Ansible ist einfach großartig und PostgreSQL ist sicherlich fantastisch, mal sehen, wie sie wunderbar zusammenarbeiten!

====================Ankündigung zur Hauptsendezeit! ====================
Die PGConf Europe 2015 findet dieses Jahr vom 27. bis 30. Oktober in Wien statt.
Ich nehme an, Sie interessieren sich möglicherweise für Konfigurationsmanagement, Server-Orchestrierung, automatisierte Bereitstellung (deshalb lesen Sie diesen Blogbeitrag, richtig?) und Sie arbeiten gerne mit PostgreSQL (auf jeden Fall) auf AWS (optional), dann möchten Sie vielleicht an meinem Vortrag „Managing PostgreSQL with Ansible“ am 28. Oktober, 15-15:50 Uhr teilnehmen.
Bitte sehen Sie sich den großartigen Zeitplan an und verpassen Sie nicht die Chance, an Europas größter PostgreSQL-Veranstaltung teilzunehmen!
Ich hoffe, wir sehen uns dort, ja, ich trinke gerne Kaffee nach Vorträgen 🙂
====================Ankündigung zur Hauptsendezeit! ====================
Was ist Ansible und wie funktioniert es?
Das Motto von Ansible lautet „einfache, agentenlose und leistungsstarke Open-Source-IT-Automatisierung“. ” durch Zitieren aus Ansible-Dokumenten.
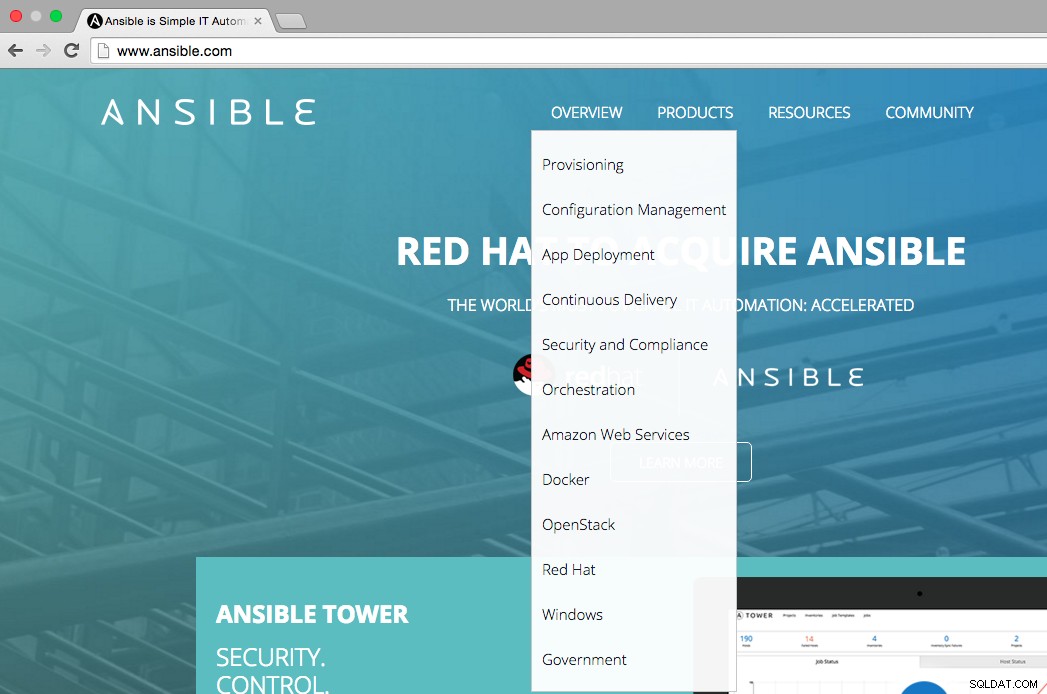
Wie aus der folgenden Abbildung ersichtlich ist, gibt die Homepage von Ansible an, dass die Hauptnutzungsbereiche von Ansible wie folgt sind:Bereitstellung, Konfigurationsmanagement, App-Bereitstellung, kontinuierliche Bereitstellung, Sicherheit und Compliance, Orchestrierung. Das Übersichtsmenü zeigt auch, auf welchen Plattformen wir Ansible integrieren können, z. B. AWS, Docker, OpenStack, Red Hat, Windows.
Sehen wir uns die wichtigsten Anwendungsfälle von Ansible an, um zu verstehen, wie es funktioniert und wie hilfreich es für IT-Umgebungen ist.
Bereitstellung
Ansible ist Ihr treuer Freund, wenn Sie alles in Ihrem System automatisieren möchten. Es ist agentenlos und Sie können Ihre Dinge (z. B. Server, Load Balancer, Switches, Firewalls) einfach über SSH verwalten. Unabhängig davon, ob Ihre Systeme auf Bare-Metal- oder Cloud-Servern laufen, Ansible ist für Sie da und hilft Ihnen bei der Bereitstellung Ihrer Instanzen. Seine idempotenten Eigenschaften stellen sicher, dass Sie immer in dem Zustand sind, den Sie sich gewünscht (und erwartet) haben.
Konfigurationsverwaltung
Eines der schwierigsten Dinge ist, sich bei sich wiederholenden operativen Aufgaben nicht zu wiederholen, und hier kommt mir wieder Ansible als Retter in den Sinn. In der guten alten Zeit, als die Zeiten schlecht waren, schrieben Systemadministratoren viele, viele Skripte und verbanden sich mit vielen, vielen Servern, um sie anzuwenden, und das war offensichtlich nicht das Beste in ihrem Leben. Wie wir alle wissen, sind manuelle Aufgaben fehleranfällig und führen zu einer heterogenen Umgebung statt einer homogenen und überschaubareren Umgebung, was unser Leben definitiv stressiger macht.
Mit Ansible können Sie einfache Playbooks schreiben (mit Hilfe einer sehr informativen Dokumentation und der Unterstützung seiner riesigen Community) und sobald Sie Ihre Aufgaben geschrieben haben, können Sie eine breite Palette von Modulen aufrufen (z. B. AWS, Nagios, PostgreSQL, SSH, APT, File Module). Dadurch können Sie sich auf kreativere Aktivitäten konzentrieren als auf die manuelle Verwaltung von Konfigurationen.
App-Bereitstellung
Wenn die Artefakte bereit sind, ist es super einfach, sie auf einer Reihe von Servern bereitzustellen. Da Ansible über SSH kommuniziert, ist es nicht erforderlich, Daten aus einem Repository auf jedem Server abzurufen oder sich mit alten Methoden wie dem Kopieren von Dateien über FTP herumzuärgern. Ansible kann Artefakte synchronisieren und sicherstellen, dass nur neue oder aktualisierte Dateien übertragen und veraltete Dateien entfernt werden. Dies beschleunigt auch Dateiübertragungen und spart viel Bandbreite.
Neben der Übertragung von Dateien hilft Ansible auch dabei, Server für den Produktionseinsatz vorzubereiten. Vor der Übertragung kann es die Überwachung pausieren, Server von Load Balancern entfernen und Dienste stoppen. Nach der Bereitstellung kann es Dienste starten, Server zu Load Balancern hinzufügen und die Überwachung wieder aufnehmen.
All dies muss nicht für alle Server auf einmal geschehen. Ansible kann auf einer Teilmenge von Servern gleichzeitig arbeiten, um Bereitstellungen ohne Ausfallzeiten bereitzustellen. Beispielsweise kann es gleichzeitig 5 Server gleichzeitig bereitstellen und dann auf den nächsten 5 Servern bereitstellen, wenn diese fertig sind.
Nach der Implementierung dieses Szenarios kann es überall ausgeführt werden. Entwickler oder Mitglieder des QA-Teams können zu Testzwecken Bereitstellungen auf ihren eigenen Computern vornehmen. Um eine Bereitstellung aus irgendeinem Grund rückgängig zu machen, benötigt Ansible außerdem nur den Speicherort der letzten bekannten funktionierenden Artefakte. Es kann sie dann problemlos auf Produktionsservern erneut bereitstellen, um das System wieder in einen stabilen Zustand zu versetzen.
Kontinuierliche Lieferung
Continuous Delivery bedeutet einen schnellen und einfachen Ansatz für Releases. Um dieses Ziel zu erreichen, ist es entscheidend, die besten Tools zu verwenden, die häufige Releases ohne Ausfallzeiten ermöglichen und so wenig menschliches Eingreifen wie möglich erfordern. Da wir oben über die Anwendungsbereitstellungsfunktionen von Ansible erfahren haben, ist es recht einfach, Bereitstellungen ohne Ausfallzeiten durchzuführen. Die andere Voraussetzung für Continuous Delivery sind weniger manuelle Prozesse und das bedeutet Automatisierung. Ansible kann jede Aufgabe automatisieren, von der Bereitstellung von Servern bis hin zur Konfiguration von Diensten, um produktionsreif zu werden. Nach dem Erstellen und Testen von Szenarien in Ansible wird es trivial, sie vor ein Continuous-Integration-System zu stellen und Ansible seine Arbeit erledigen zu lassen.
Sicherheit und Compliance
Sicherheit wird immer als das Wichtigste angesehen, aber die Sicherheit von Systemen ist eines der am schwierigsten zu erreichenden Dinge. Sie müssen sich sowohl der Sicherheit Ihrer Daten als auch der Daten Ihrer Kunden sicher sein. Um die Sicherheit Ihrer Systeme zu gewährleisten, reicht es nicht aus, Sicherheit zu definieren. Sie müssen in der Lage sein, diese Sicherheit anzuwenden und Ihre Systeme ständig zu überwachen, um sicherzustellen, dass sie diese Sicherheit einhalten.
Ansible ist einfach zu bedienen, egal ob es darum geht, Firewall-Regeln einzurichten, Benutzer und Gruppen zu sperren oder benutzerdefinierte Sicherheitsrichtlinien anzuwenden. Es ist von Natur aus sicher, da Sie dieselbe Konfiguration wiederholt anwenden können, und es werden nur die notwendigen Änderungen vorgenommen, um das System wieder konform zu machen.
Orchestrierung
Ansible stellt sicher, dass alle gegebenen Aufgaben in der richtigen Reihenfolge sind und stellt eine Harmonie zwischen allen verwalteten Ressourcen her. Die Orchestrierung komplexer Multi-Tier-Bereitstellungen ist mit den Konfigurationsverwaltungs- und Bereitstellungsfunktionen von Ansible einfacher. Wenn Sie beispielsweise die Bereitstellung eines Software-Stacks in Betracht ziehen, sind Bedenken wie das Sicherstellen, dass alle Datenbankserver bereit sind, bevor Anwendungsserver aktiviert werden, oder das Konfigurieren des Netzwerks, bevor Server zum Load Balancer hinzugefügt werden, keine komplizierten Probleme mehr.
Ansible hilft auch bei der Orchestrierung anderer Orchestrierungstools wie CloudFormation von Amazon, Heat von OpenStack, Swarm von Docker usw. Anstatt verschiedene Plattformen, Sprachen und Regeln zu lernen; Benutzer können sich nur auf die YAML-Syntax und die leistungsstarken Module von Ansible konzentrieren.
Was ist ein Ansible-Modul?
Module oder Modulbibliotheken bieten Ansible-Mittel zum Steuern oder Verwalten von Ressourcen auf lokalen oder Remote-Servern. Sie erfüllen eine Vielzahl von Funktionen. Beispielsweise kann ein Modul für den Neustart einer Maschine verantwortlich sein oder einfach eine Nachricht auf dem Bildschirm anzeigen.
Ansible ermöglicht es Benutzern, ihre eigenen Module zu schreiben, und bietet auch sofort einsatzbereite Kern- oder Extramodule.
Was ist mit Ansible-Playbooks?
Mit Ansible können wir unsere Arbeit auf verschiedene Arten organisieren. In seiner direktesten Form können wir mit Ansible-Modulen arbeiten, indem wir die Datei „ansible ” Befehlszeilentool und die Inventardatei.
Inventar
Eines der wichtigsten Konzepte ist das Inventar . Wir benötigen eine Bestandsdatei, damit Ansible weiß, welche Server für die Verbindung über SSH benötigt werden, welche Verbindungsinformationen erforderlich sind und optional welche Variablen diesen Servern zugeordnet sind.
Die Inventardatei hat ein INI-ähnliches Format. In der Bestandsdatei können wir mehr als einen Host angeben und sie unter mehr als einer Hostgruppe gruppieren.
Unsere Beispiel-Inventardatei hosts.ini sieht wie folgt aus:
[dbservers]
db.example.com
Hier haben wir einen einzelnen Host namens „db.example.com“ in einer Hostgruppe namens „dbservers“. In die Bestandsdatei können wir auch benutzerdefinierte SSH-Ports, SSH-Benutzernamen, SSH-Schlüssel, Proxy-Informationen, Variablen usw. aufnehmen.
Da wir eine Bestandsdatei bereit haben, können wir den „Befehl von Ansible aufrufen, um die Betriebszeiten unserer Datenbankserver anzuzeigen “-Modul und führen Sie das „uptime ” Befehl auf diesen Servern:
ansible dbservers -i hosts.ini -m command -a "uptime"
Hier haben wir Ansible angewiesen, Hosts aus der hosts.ini-Datei zu lesen, sie mit SSH zu verbinden, die „uptime ” Befehl auf jedem von ihnen und geben Sie dann ihre Ausgabe auf dem Bildschirm aus. Diese Art der Modulausführung wird als Ad-hoc-Befehl bezeichnet .
Die Ausgabe des Befehls sieht folgendermaßen aus:
example@sqldat.com ~/blog/ansible-loves-postgresql # ansible dbservers -i hosts.ini -m command -a "uptime"
db.example.com | success | rc=0 >>
21:16:24 up 93 days, 9:17, 4 users, load average: 0.08, 0.03, 0.05
Wenn unsere Lösung jedoch mehr als einen einzelnen Schritt enthält, wird es schwierig, sie nur mit Ad-hoc-Befehlen zu verwalten.
Hier kommen Ansible-Playbooks. Es ermöglicht uns, unsere Lösung in einer Playbook-Datei zu organisieren, indem wir alle Schritte mithilfe von Aufgaben, Variablen, Rollen, Vorlagen, Handlern und einem Inventar integrieren.
Werfen wir einen kurzen Blick auf einige dieser Begriffe, um zu verstehen, wie sie uns helfen können.
Aufgaben
Ein weiteres wichtiges Konzept sind Aufgaben. Jede Ansible-Aufgabe enthält einen Namen, ein aufzurufendes Modul, Modulparameter und optional Vor-/Nachbedingungen. Sie ermöglichen es uns, Ansible-Module aufzurufen und Informationen an aufeinanderfolgende Aufgaben weiterzugeben.
Variablen
Es gibt auch Variablen. Sie sind sehr nützlich für die Wiederverwendung von Informationen, die wir bereitgestellt oder gesammelt haben. Wir können sie entweder im Inventar, in externen YAML-Dateien oder in Playbooks definieren.
Playbook
Ansible Playbooks werden mit der YAML-Syntax geschrieben. Es kann mehr als ein Stück enthalten. Jedes Spiel enthält Namen von Hostgruppen, mit denen eine Verbindung hergestellt werden soll, und Aufgaben, die es ausführen muss. Es kann auch Variablen/Rollen/Handler enthalten, falls definiert.
Jetzt können wir uns ein sehr einfaches Playbook ansehen, um zu sehen, wie es strukturiert werden kann:
---
- hosts: dbservers
gather_facts: no
vars:
who: World
tasks:
- name: say hello
debug: msg="Hello {{ who }}"
- name: retrieve the uptime
command: uptimeIn diesem sehr einfachen Playbook haben wir Ansible gesagt, dass es auf Servern laufen soll, die in der Hostgruppe „dbservers“ definiert sind. Wir haben eine Variable namens „Wer“ erstellt und dann unsere Aufgaben definiert. Beachten Sie, dass wir in der ersten Aufgabe, in der wir eine Debug-Meldung ausgeben, die Variable „who“ verwendet und Ansible veranlasst haben, „Hello World“ auf dem Bildschirm auszugeben. In der zweiten Aufgabe haben wir Ansible angewiesen, sich mit jedem Host zu verbinden und dann dort den Befehl „uptime“ auszuführen.
Ansible PostgreSQL-Module
Ansible stellt eine Reihe von Modulen für PostgreSQL bereit. Einige von ihnen befinden sich unter den Kernmodulen, während andere unter den Zusatzmodulen zu finden sind.
Alle PostgreSQL-Module erfordern, dass das Python-Paket psycopg2 auf demselben Computer wie der PostgreSQL-Server installiert ist. Psycopg2 ist ein PostgreSQL-Datenbankadapter in der Programmiersprache Python.
Auf Debian/Ubuntu-Systemen kann das Paket psycopg2 mit dem folgenden Befehl installiert werden:
apt-get install python-psycopg2
Nun werden wir diese Module im Detail untersuchen. Als Beispiel werden wir auf einem PostgreSQL-Server auf dem Host db.example.com arbeiten auf Port 5432 mit postgres Benutzer und ein leeres Passwort.
postgresql_db
Dieses Kernmodul erstellt oder entfernt eine bestimmte PostgreSQL-Datenbank. In Ansible-Terminologie stellt es sicher, dass eine bestimmte PostgreSQL-Datenbank vorhanden oder nicht vorhanden ist.
Die wichtigste Option ist der erforderliche Parameter „name “. Es repräsentiert den Namen der Datenbank in einem PostgreSQL-Server. Ein weiterer wichtiger Parameter ist „state “. Es erfordert einen von zwei Werten:present oder abwesend . Dadurch können wir eine Datenbank erstellen oder entfernen, die durch den im Namen angegebenen Wert identifiziert wird Parameter.
Einige Arbeitsabläufe erfordern möglicherweise auch die Angabe von Verbindungsparametern wie login_host , Port , Anmeldebenutzer und login_password .
Lassen Sie uns eine Datenbank mit dem Namen „module_test“ erstellen ” auf unserem PostgreSQL-Server, indem Sie unserer Playbook-Datei die folgenden Zeilen hinzufügen:
- postgresql_db: name=module_test
state=present
login_host=db.example.com
port=5432
login_user=postgres
Hier haben wir eine Verbindung zu unserem Testdatenbankserver unter db.example.com hergestellt mit dem Benutzer; postgres . Es muss jedoch nicht das postgres sein user als Benutzername kann alles sein.
Das Entfernen der Datenbank ist so einfach wie das Erstellen:
- postgresql_db: name=module_test
state=absent
login_host=db.example.com
port=5432
login_user=postgres
Beachten Sie den „abwesend“-Wert im „state“-Parameter.
postgresql_ext
PostgreSQL ist dafür bekannt, sehr nützliche und leistungsstarke Erweiterungen zu haben. Eine neuere Erweiterung ist beispielsweise tsm_system_rows Dies hilft beim Abrufen der genauen Anzahl von Zeilen beim Tablesampling. (Für weitere Informationen können Sie meinen vorherigen Post über Tablesampling-Methoden lesen.)
Dieses Extras-Modul fügt oder entfernt PostgreSQL-Erweiterungen aus einer Datenbank. Es erfordert zwei obligatorische Parameter:db und Name . Die db Parameter bezieht sich auf den Datenbanknamen und den Namen Parameter bezieht sich auf den Erweiterungsnamen. Wir haben auch den Zustand Parameter, der anwesend sein muss oder abwesend Werte und dieselben Verbindungsparameter wie im Modul postgresql_db.
Beginnen wir mit der Erstellung der Erweiterung, über die wir gesprochen haben:
- postgresql_ext: db=module_test
name=tsm_system_rows
state=present
login_host=db.example.com
port=5432
login_user=postgres
postgresql_user
Dieses Kernmodul ermöglicht das Hinzufügen oder Entfernen von Benutzern und Rollen aus einer PostgreSQL-Datenbank.
Es ist ein sehr leistungsfähiges Modul, da es zwar sicherstellt, dass ein Benutzer in der Datenbank vorhanden ist, aber gleichzeitig auch die Änderung von Berechtigungen oder Rollen ermöglicht.
Beginnen wir mit einem Blick auf die Parameter. Der einzige obligatorische Parameter hier ist „name “, was sich auf einen Benutzer- oder Rollennamen bezieht. Außerdem ist, wie in den meisten Ansible-Modulen, der „state ”-Parameter ist wichtig. Es kann eines von anwesend haben oder abwesend Werte und sein Standardwert ist vorhanden .
Zusätzlich zu den Verbindungsparametern wie in vorherigen Modulen sind einige andere wichtige optionale Parameter:
- db :Name der Datenbank, in der Berechtigungen erteilt werden
- Passwort :Passwort des Benutzers
- privat :Privilegien im Format „priv1/priv2“ oder Tabellenprivilegien im Format „table:priv1,priv2,…“
- role_attr_flags :Rollenattribute. Mögliche Werte sind:
- [KEIN]SUPERUSER
- [NO]CREATEROLE
- [NO]CREATEUSER
- [NO]CREATEDB
- [NEIN]ERBEN
- [KEIN]LOGIN
- [KEINE]REPLIKATION
Um einen neuen Benutzer namens ada zu erstellen mit Passwort lovelace und ein Verbindungsprivileg zur Datenbank module_test , können wir Folgendes zu unserem Playbook hinzufügen:
- postgresql_user: db=module_test
name=ada
password=lovelace
state=present
priv=CONNECT
login_host=db.example.com
port=5432
login_user=postgres
Nachdem wir den Benutzer nun bereit haben, können wir ihm einige Rollen zuweisen. So erlauben Sie „ada“, sich anzumelden und Datenbanken zu erstellen:
- postgresql_user: name=ada
role_attr_flags=LOGIN,CREATEDB
login_host=db.example.com
port=5432
login_user=postgres
Wir können auch globale oder tabellenbasierte Berechtigungen wie „INSERT“ erteilen “, „AKTUALISIEREN “, „AUSWÄHLEN “ und „LÖSCHEN ” mit dem priv Parameter. Ein wichtiger zu beachtender Punkt ist, dass ein Benutzer nicht entfernt werden kann, bevor nicht alle gewährten Privilegien widerrufen wurden.
postgresql_privs
Dieses Kernmodul gewährt oder widerruft Berechtigungen für PostgreSQL-Datenbankobjekte. Unterstützte Objekte sind:Tabelle , Reihenfolge , Funktion , Datenbank , Schema , Sprache , Tabellenbereich und Gruppe .
Erforderliche Parameter sind „Datenbank“; Name der Datenbank, für die Berechtigungen gewährt/entzogen werden sollen, und „Rollen“; eine durch Kommas getrennte Liste von Rollennamen.
Die wichtigsten optionalen Parameter sind:
- tippen :Typ des Objekts, für das Berechtigungen festgelegt werden sollen. Kann einer der folgenden sein:Tabelle, Sequenz, Funktion, Datenbank, Schema, Sprache, Tablespace, Gruppe . Der Standardwert ist table .
- Objekte :Datenbankobjekte zum Festlegen von Berechtigungen. Kann mehrere Werte haben. In diesem Fall werden Objekte durch ein Komma getrennt.
- privat :Kommagetrennte Liste von Berechtigungen, die gewährt oder widerrufen werden sollen. Mögliche Werte sind:ALL , AUSWÄHLEN , AKTUALISIEREN , EINFÜGEN .
Sehen wir uns an, wie dies funktioniert, indem Sie alle Berechtigungen für die Datei „public“ gewähren “-Schema in „ada “:
- postgresql_privs: db=module_test
privs=ALL
type=schema
objs=public
role=ada
login_host=db.example.com
port=5432
login_user=postgres
postgresql_lang
Eine der sehr leistungsstarken Funktionen von PostgreSQL ist die Unterstützung für praktisch jede Sprache, die als prozedurale Sprache verwendet werden kann. Dieses Extras-Modul fügt prozedurale Sprachen mit einer PostgreSQL-Datenbank hinzu, entfernt oder ändert sie.
Der einzige obligatorische Parameter ist „lang “; Name der Verfahrenssprache, die hinzugefügt oder entfernt werden soll. Weitere wichtige Optionen sind „db “; Name der Datenbank, zu der die Sprache hinzugefügt oder aus der sie entfernt wird, und „Vertrauen “; Option, um die Sprache für die ausgewählte Datenbank als vertrauenswürdig oder nicht vertrauenswürdig festzulegen.
Lassen Sie uns die PL/Python-Sprache für unsere Datenbank aktivieren:
- postgresql_lang: db=module_test
lang=plpython2u
state=present
login_host=db.example.com
port=5432
login_user=postgres
Alles zusammenfassen
Nachdem wir nun wissen, wie ein Ansible-Playbook aufgebaut ist und welche PostgreSQL-Module uns zur Verfügung stehen, können wir unser Wissen nun in einem Ansible-Playbook bündeln.
Die endgültige Form unseres Playbooks main.yml sieht wie folgt aus:
---
- hosts: dbservers
sudo: yes
sudo_user: postgres
gather_facts: yes
vars:
dbname: module_test
dbuser: postgres
tasks:
- name: ensure the database is present
postgresql_db: >
state=present
db={{ dbname }}
login_user={{ dbuser }}
- name: ensure the tsm_system_rows extension is present
postgresql_ext: >
name=tsm_system_rows
state=present
db={{ dbname }}
login_user={{ dbuser }}
- name: ensure the user has access to database
postgresql_user: >
name=ada
password=lovelace
state=present
priv=CONNECT
db={{ dbname }}
login_user={{ dbuser }}
- name: ensure the user has necessary privileges
postgresql_user: >
name=ada
role_attr_flags=LOGIN,CREATEDB
login_user={{ dbuser }}
- name: ensure the user has schema privileges
postgresql_privs: >
privs=ALL
type=schema
objs=public
role=ada
db={{ dbname }}
login_user={{ dbuser }}
- name: ensure the postgresql-plpython-9.4 package is installed
apt: name=postgresql-plpython-9.4 state=latest
sudo_user: root
- name: ensure the PL/Python language is available
postgresql_lang: >
lang=plpython2u
state=present
db={{ dbname }}
login_user={{ dbuser }}
Jetzt können wir unser Playbook mit dem Befehl „ansible-playbook“ ausführen:
example@sqldat.com ~/blog/ansible-loves-postgresql # ansible-playbook -i hosts.ini main.yml
PLAY [dbservers] **************************************************************
GATHERING FACTS ***************************************************************
ok: [db.example.com]
TASK: [ensure the database is present] ****************************************
changed: [db.example.com]
TASK: [ensure the tsm_system_rows extension is present] ***********************
changed: [db.example.com]
TASK: [ensure the user has access to database] ********************************
changed: [db.example.com]
TASK: [ensure the user has necessary privileges] ******************************
changed: [db.example.com]
TASK: [ensure the user has schema privileges] *********************************
changed: [db.example.com]
TASK: [ensure the postgresql-plpython-9.4 package is installed] ***************
changed: [db.example.com]
TASK: [ensure the PL/Python language is available] ****************************
changed: [db.example.com]
PLAY RECAP ********************************************************************
db.example.com : ok=8 changed=7 unreachable=0 failed=0
Sie finden das Inventar und die Playbook-Datei in meinem GitHub-Repository, das für diesen Blogpost erstellt wurde. Es gibt auch ein weiteres Playbook namens „remove.yml“, das alles rückgängig macht, was wir im Hauptplaybook gemacht haben.
Weitere Informationen zu Ansible:
- Schauen Sie sich ihre gut geschriebenen Dokumente an.
- Sehen Sie sich das Ansible-Schnellstartvideo an, das eine wirklich hilfreiche Anleitung ist.
- Folgen Sie ihrem Webinar-Zeitplan, es gibt einige coole kommende Webinare auf der Liste.