Obwohl in Zukunft die meisten Datenbankserver (insbesondere diejenigen, die OLTP-ähnliche Workloads verarbeiten) einen Flash-basierten Speicher verwenden werden, sind wir noch nicht so weit – Flash-Speicher ist immer noch erheblich teurer als herkömmliche Festplatten, und so viele Systeme verwenden eine Mischung von SSD- und HDD-Laufwerken. Das bedeutet jedoch, dass wir entscheiden müssen, wie wir die Datenbank aufteilen – was soll auf den sich drehenden Rost (HDD) gehen und was ist ein guter Kandidat für den Flash-Speicher, der teurer ist, aber viel besser mit zufälligen E/A umgehen kann.
Es gibt Lösungen, die versuchen, dies automatisch auf Speicherebene zu handhaben, indem SSDs automatisch als Cache verwendet werden, wodurch der aktive Teil der Daten automatisch auf SSD gehalten wird. Storage Appliances / SANs erledigen dies oft intern, es gibt hybride SATA/SAS-Laufwerke mit großer HDD und kleiner SSD in einem einzigen Paket, und natürlich gibt es Lösungen, um dies direkt auf dem Host zu tun – zum Beispiel gibt es dm-Cache in Linux, LVM hat 2014 auch eine solche Fähigkeit (aufgebaut auf dem dm-Cache) bekommen, und natürlich hat ZFS L2ARC.
Aber lassen Sie uns all diese automatischen Optionen ignorieren, und sagen wir, wir haben zwei Geräte direkt an das System angeschlossen – eines basiert auf HDDs, das andere auf Flash-Basis. Wie sollten Sie die Datenbank aufteilen, um den größten Nutzen aus dem teuren Flash zu ziehen? Ein häufig verwendetes Muster besteht darin, dies nach Objekttyp zu tun, insbesondere Tabellen vs. Indizes. Was im Allgemeinen sinnvoll ist, aber wir sehen oft Leute, die Indizes auf dem SSD-Speicher platzieren, da Indizes mit zufälligen I/Os verbunden sind. Auch wenn dies vernünftig erscheinen mag, stellt sich heraus, dass dies genau das Gegenteil von dem ist, was Sie tun sollten.
Lassen Sie mich Ihnen einen Benchmark zeigen …
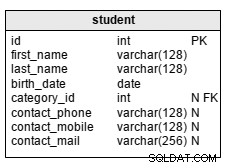
Lassen Sie mich dies auf einem System demonstrieren, das sowohl HDD-Speicher (RAID10 aus 4x 10k-SAS-Laufwerken) als auch ein einzelnes SSD-Gerät (Intel S3700) enthält. Das System verfügt über 16 GB RAM, also verwenden wir pgbench mit den Maßstäben 300 (=4,5 GB) und 3000 (=45 GB), also eines, das problemlos in RAM und ein Vielfaches von RAM passt. Dann platzieren wir Tabellen und Indizes auf verschiedenen Speichersystemen (unter Verwendung von Tablespaces) und messen die Leistung. Der Datenbank-Cluster wurde hinsichtlich der Hardware-Ressourcen sinnvoll konfiguriert (Shared Buffer, WAL-Limits etc.). Die WAL wurde auf einem separaten SSD-Gerät platziert, das an einen RAID-Controller angeschlossen war, der mit den SAS-Laufwerken geteilt wurde.
Auf dem kleinen Datensatz (4,5 GB) sehen die Ergebnisse so aus (beachten Sie, dass die y-Achse bei 3000 tps beginnt):
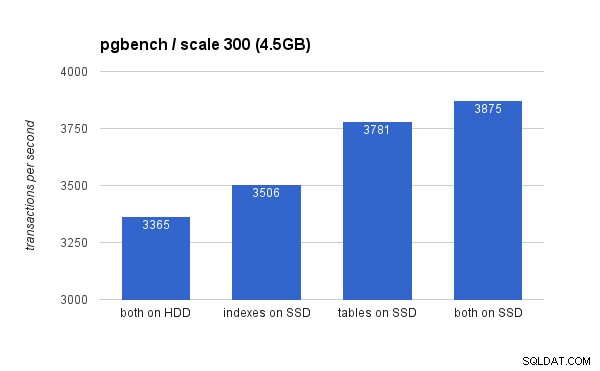
Das Platzieren der Indizes auf SSD bietet eindeutig einen geringeren Nutzen im Vergleich zur Verwendung der SSD für Tabellen. Während der Datensatz problemlos in den Arbeitsspeicher passt, müssen die Änderungen schließlich auf die Festplatte geschrieben werden, und obwohl der RAID-Controller über einen Schreibcache verfügt, kann er nicht wirklich mit dem Flash-Speicher konkurrieren. Neue RAID-Controller würden wahrscheinlich etwas besser abschneiden, aber auch neue SSD-Laufwerke.
Auf dem großen Datensatz sind die Unterschiede viel signifikanter (diesmal beginnt die y-Achse bei 0):
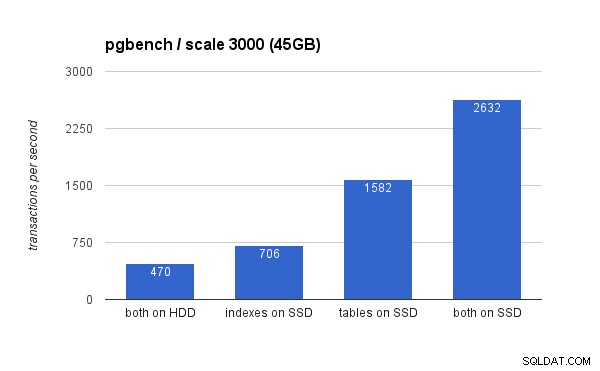
Das Platzieren der Indizes auf SSD führt zu einer erheblichen Leistungssteigerung (fast 50 %, wenn man HDD-Speicher als Grundlage nimmt), aber das Verschieben von Tabellen auf die SSD übertrifft dies leicht, indem es mehr als 200 % gewinnt. Wenn Sie sowohl Tabellen als auch Indizes auf SSDs platzieren, können Sie die Leistung natürlich weiter verbessern – aber wenn Sie das tun könnten, müssen Sie sich keine Gedanken über die anderen Fälle machen.
Aber warum?
Eine bessere Leistung durch das Platzieren von Tabellen auf SSDs zu erzielen, mag ein wenig kontraintuitiv erscheinen, also warum verhält es sich so? Nun, es ist wahrscheinlich eine Kombination aus mehreren Faktoren:
- Indizes sind normalerweise viel kleiner als Tabellen und passen daher leichter in den Speicher
- Die Seiten in Indexebenen (im Baum) sind normalerweise ziemlich heiß und bleiben daher im Speicher
- beim Scannen und Indexieren ist ein Großteil der eigentlichen E/A sequentiell (insbesondere für Blattseiten)
Die Folge davon ist, dass überraschend viele I/Os gegen Indizes entweder gar nicht stattfinden (dank Caching) oder sequentiell sind. Andererseits sind Indizes eine großartige Quelle für zufällige Ein-/Ausgaben für die Tabellen.
Es ist allerdings komplizierter …
Natürlich war dies nur ein einfaches Beispiel, und die Schlussfolgerungen könnten beispielsweise für wesentlich unterschiedliche Workloads unterschiedlich sein. Da SSDs teurer sind, haben Systeme tendenziell mehr Speicherplatz auf HDD-Laufwerken als auf SSD-Laufwerken, sodass Tabellen möglicherweise nicht auf die SSD passen, während Indizes dies tun würden. In diesen Fällen ist eine aufwändigere Platzierung erforderlich – zum Beispiel nicht nur die Art des Objekts zu berücksichtigen, sondern auch wie oft es verwendet wird (und nur die stark genutzten Tabellen auf SSDs zu verschieben) oder sogar Teilmengen von Tabellen (z. B. durch schrittweises Verschieben alter Daten von SSD auf HDD).