Beim Optimieren von postgresql.conf , haben Sie vielleicht bemerkt, dass es eine Option namens full_page_writes gibt . Der Kommentar daneben sagt etwas über teilweises Schreiben von Seiten aus, und die Leute lassen ihn im Allgemeinen auf on eingestellt – was eine gute Sache ist, wie ich später in diesem Beitrag erklären werde. Es ist jedoch hilfreich zu verstehen, was das Schreiben ganzer Seiten bewirkt, da die Auswirkungen auf die Leistung erheblich sein können.
Im Gegensatz zu meinem vorherigen Beitrag zum Checkpoint-Tuning ist dies keine Anleitung zum Tuning des Servers. Es gibt nicht viel, was Sie wirklich optimieren können, aber ich werde Ihnen zeigen, wie einige Entscheidungen auf Anwendungsebene (z. B. die Auswahl von Datentypen) mit ganzseitigen Schreibvorgängen interagieren können.
Teilschreibvorgänge / zerrissene Seiten
Worüber schreiben also ganzseitige Texte? Als Kommentar in postgresql.conf sagt, dass es eine Möglichkeit ist, sich von teilweisen Seitenschreibvorgängen zu erholen – PostgreSQL verwendet (standardmäßig) 8-kB-Seiten, aber andere Teile des Stapels verwenden unterschiedliche Chunk-Größen. Linux-Dateisysteme verwenden normalerweise 4-kB-Seiten (es ist möglich, kleinere Seiten zu verwenden, aber 4 kB ist das Maximum bei x86), und auf Hardwareebene verwendeten die alten Laufwerke 512-B-Sektoren, während neue Geräte Daten oft in größeren Blöcken schreiben (oft 4 kB oder sogar 8 kB). .
Wenn also PostgreSQL die 8-kB-Seite schreibt, können die anderen Schichten des Speicherstapels diese in kleinere Teile aufteilen, die separat verwaltet werden. Dies stellt ein Problem hinsichtlich der Schreibatomarität dar. Die 8-kB-PostgreSQL-Seite kann in zwei 4-kB-Dateisystemseiten und dann in 512-B-Sektoren aufgeteilt werden. Was nun, wenn der Server abstürzt (Stromausfall, Kernel-Bug, …)?
Selbst wenn der Server ein Speichersystem verwendet, das für solche Ausfälle ausgelegt ist (SSDs mit Kondensatoren, RAID-Controller mit Batterien, …), hat der Kernel die Daten bereits in 4-kB-Seiten aufgeteilt. Es ist also möglich, dass die Datenbank eine 8-kB-Datenseite geschrieben hat, aber nur ein Teil davon vor dem Absturz auf die Festplatte gelangte.
An dieser Stelle denken Sie jetzt wahrscheinlich, dass wir genau deshalb das Transaktionsprotokoll (WAL) haben, und Sie haben Recht! Nach dem Starten des Servers liest die Datenbank WAL (seit dem letzten abgeschlossenen Prüfpunkt) und wendet die Änderungen erneut an, um sicherzustellen, dass die Datendateien vollständig sind. Einfach.
Aber es gibt einen Haken – die Wiederherstellung wendet die Änderungen nicht blind an, sie muss oft die Datenseiten lesen usw. Dies setzt voraus, dass die Seite nicht bereits in irgendeiner Weise beschädigt ist, beispielsweise aufgrund eines teilweisen Schreibens. Was ein bisschen widersprüchlich erscheint, denn um Datenbeschädigungen zu beheben, gehen wir davon aus, dass keine Datenbeschädigung vorliegt.
Ganzseitige Schreibvorgänge sind eine Möglichkeit, dieses Rätsel zu umgehen – wenn eine Seite zum ersten Mal nach einem Prüfpunkt geändert wird, wird die gesamte Seite in WAL geschrieben. Dies garantiert, dass während der Wiederherstellung der erste WAL-Datensatz, der eine Seite berührt, die gesamte Seite enthält, wodurch die Notwendigkeit entfällt, die – möglicherweise beschädigte – Seite aus der Datendatei zu lesen.
Verstärkung schreiben
Die negative Folge davon ist natürlich eine erhöhte WAL-Größe – wenn Sie ein einzelnes Byte auf der 8-kB-Seite ändern, wird das Ganze in WAL protokolliert. Das Schreiben ganzer Seiten erfolgt nur beim ersten Schreiben nach einem Checkpoint, daher ist es eine Möglichkeit, die Häufigkeit von Checkpoints zu verringern, um die Situation zu verbessern – normalerweise gibt es nach einem Checkpoint einen kurzen „Burst“ von ganzseitigen Schreibvorgängen und dann relativ wenige ganzseitige Schreibvorgänge bis zum Ende eines Checkpoints.
UUID vs. BIGSERIAL-Schlüssel
Es gibt jedoch einige unerwartete Wechselwirkungen mit Designentscheidungen, die auf Anwendungsebene getroffen werden. Nehmen wir an, wir haben eine einfache Tabelle mit Primärschlüssel, entweder BIGSERIAL oder UUID , und wir fügen Daten darin ein. Wird es einen Unterschied in der Menge der generierten WAL geben (vorausgesetzt, wir fügen die gleiche Anzahl von Zeilen ein)?
Es scheint vernünftig zu erwarten, dass beide Fälle ungefähr die gleiche Menge an WAL produzieren, aber wie die folgenden Diagramme veranschaulichen, gibt es in der Praxis einen großen Unterschied.
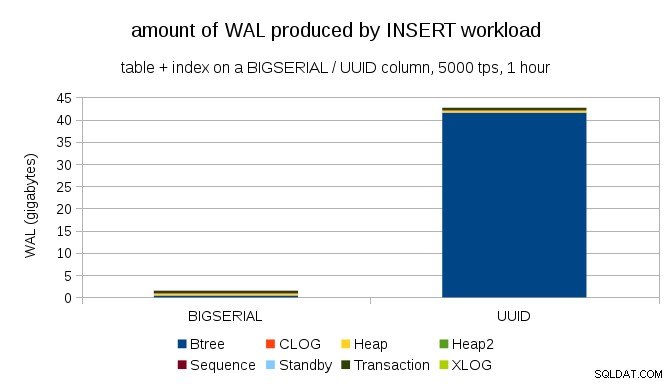
Dies zeigt die WAL-Menge, die während eines 1-stündigen Benchmarks produziert wird, gedrosselt auf 5000 Einfügungen pro Sekunde. Mit BIGSERIAL Primärschlüssel erzeugt dies ~2 GB WAL, während mit UUID Es sind mehr als 40 GB. Das ist ein ziemlich signifikanter Unterschied, und ganz klar ist der größte Teil der WAL mit dem Index verbunden, der den Primärschlüssel unterstützt. Sehen wir uns die Arten von WAL-Einträgen an.
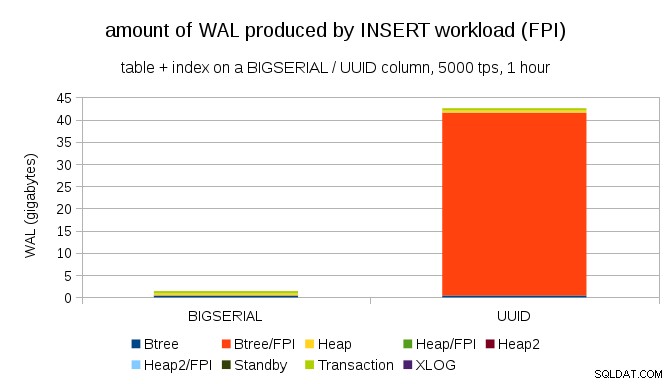
Die überwiegende Mehrheit der Aufzeichnungen sind eindeutig Ganzseitenbilder (FPI), d. h. das Ergebnis von Ganzseitenschreibvorgängen. Aber warum passiert das?
Das liegt natürlich an der inhärenten UUID Zufälligkeit. Mit BIGSERIAL new sind sequentiell und werden daher in die gleichen Blattseiten im btree-Index eingefügt. Da nur die erste Änderung an einer Seite das Schreiben der ganzen Seite auslöst, sind nur ein winziger Bruchteil der WAL-Datensätze FPIs. Mit UUID es ist natürlich ein ganz anderer Fall – die Werte sind überhaupt nicht sequentiell, tatsächlich berührt jede Einfügung wahrscheinlich eine völlig neue Blattindex-Blattseite (vorausgesetzt, der Index ist groß genug).
Die Datenbank kann nicht viel tun – die Arbeitslast ist einfach zufällig und löst viele ganzseitige Schreibvorgänge aus.
Es ist nicht schwierig, auch mit BIGSERIAL eine ähnliche Schreibverstärkung zu erhalten Schlüssel natürlich. Es erfordert nur einen anderen Arbeitsaufwand – zum Beispiel mit UPDATE Workload, zufällige Aktualisierung von Datensätzen mit gleichmäßiger Verteilung, sieht das Diagramm wie folgt aus:
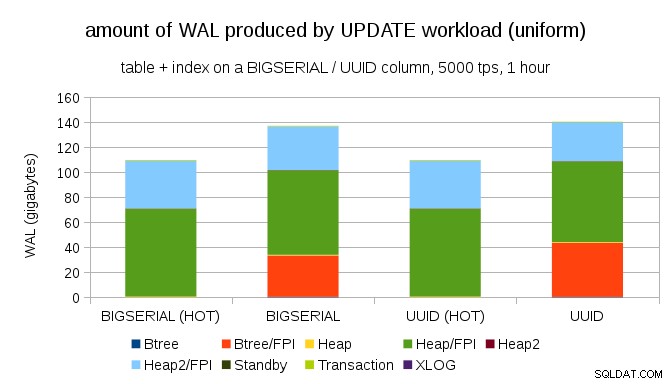
Plötzlich sind die Unterschiede zwischen den Datentypen verschwunden – der Zugriff erfolgt in beiden Fällen zufällig, was dazu führt, dass fast genau die gleiche Menge an WAL produziert wird. Ein weiterer Unterschied besteht darin, dass der größte Teil der WAL mit „Heap“ verknüpft ist, also mit Tabellen und nicht mit Indizes. Die „HOT“-Fälle wurden entwickelt, um eine HOT UPDATE-Optimierung zu ermöglichen (d. h. Aktualisierung, ohne einen Index berühren zu müssen), wodurch der gesamte indexbezogene WAL-Verkehr so gut wie eliminiert wird.
Aber Sie könnten argumentieren, dass die meisten Anwendungen nicht den gesamten Datensatz aktualisieren. Normalerweise ist nur ein kleiner Teil der Daten „aktiv“ – die Leute greifen nur auf Beiträge der letzten Tage in einem Diskussionsforum, offene Bestellungen in einem E-Shop usw. zu. Wie verändert das die Ergebnisse?
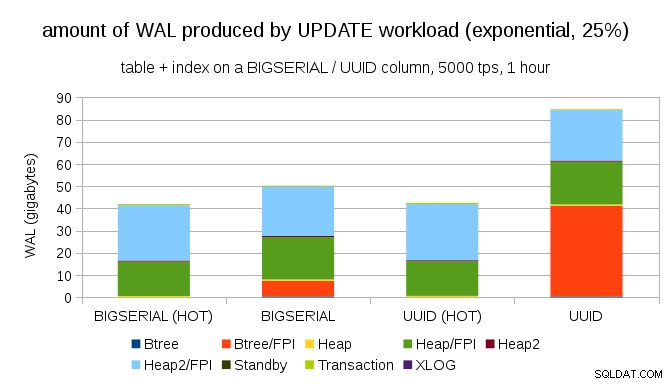
Glücklicherweise unterstützt pgbench ungleichmäßige Verteilungen, und zum Beispiel sieht das Diagramm bei einer exponentiellen Verteilung, die 1 % Teilmenge der Daten berührt, in etwa 25 % der Fälle so aus:
Und nachdem Sie die Verteilung noch verzerrter gemacht haben, berühren Sie die 1 %-Teilmenge in etwa 75 % der Fälle:
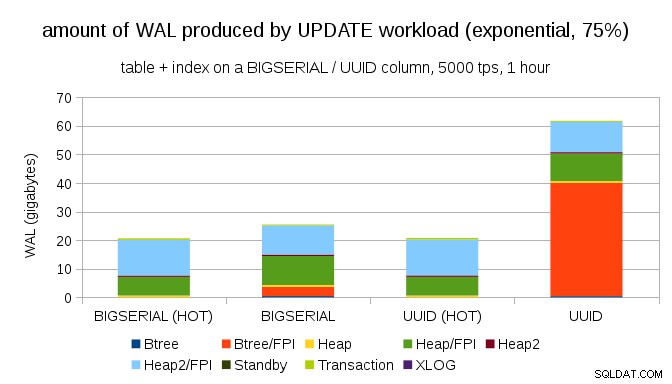
Dies zeigt erneut, wie groß der Unterschied bei der Auswahl der Datentypen sein kann, und auch, wie wichtig das Tuning für HOT-Updates ist.
8kB- und 4kB-Seiten
Eine interessante Frage ist, wie viel WAL-Traffic wir einsparen könnten, indem wir kleinere Seiten in PostgreSQL verwenden (was das Kompilieren eines benutzerdefinierten Pakets erfordert). Im besten Fall können bis zu 50 % WAL eingespart werden, da nur 4-kB- statt 8-kB-Seiten geloggt werden. Für den Workload mit gleichmäßig verteilten UPDATEs sieht das so aus:
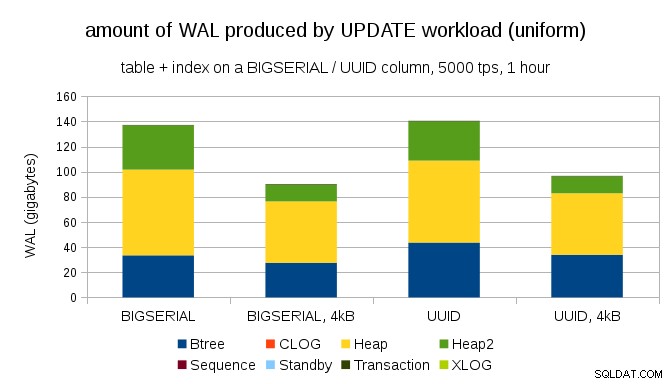
Die Einsparung beträgt also nicht genau 50 %, aber die Reduzierung von ~140 GB auf ~90 GB ist immer noch ziemlich signifikant.
Brauchen wir immer noch ganzseitige Texte?
Es mag lächerlich erscheinen, nachdem die Gefahr des teilweisen Schreibens erklärt wurde, aber vielleicht ist das Deaktivieren des Schreibens ganzer Seiten eine praktikable Option, zumindest in einigen Fällen.
Erstens frage ich mich, ob moderne Linux-Dateisysteme immer noch anfällig für partielle Schreibvorgänge sind? Der Parameter wurde in PostgreSQL 8.1 eingeführt, das 2005 veröffentlicht wurde, also machen einige der vielen Dateisystemverbesserungen, die seitdem eingeführt wurden, dies möglicherweise zu einem Nicht-Problem. Wahrscheinlich nicht universell für beliebige Workloads, aber vielleicht wäre die Annahme einer zusätzlichen Bedingung (z. B. die Verwendung einer Seitengröße von 4 KB in PostgreSQL) ausreichend? Außerdem überschreibt PostgreSQL niemals nur eine Teilmenge der 8-kB-Seite – es wird immer die ganze Seite ausgeschrieben.
Ich habe in letzter Zeit viele Tests durchgeführt, um einen teilweisen Schreibvorgang auszulösen, und es ist mir noch nicht gelungen, einen einzigen Fall zu verursachen. Natürlich ist das nicht wirklich ein Beweis dafür, dass das Problem nicht existiert. Aber selbst wenn es immer noch ein Problem ist, können Datenprüfsummen ein ausreichender Schutz sein (das Problem wird dadurch nicht behoben, aber Sie werden zumindest wissen, dass es eine defekte Seite gibt).
Zweitens verlassen sich viele Systeme heutzutage auf Streaming-Replikate – anstatt auf den Neustart des Servers nach einem Hardwareproblem zu warten (was ziemlich lange dauern kann) und dann mehr Zeit mit der Wiederherstellung zu verbringen, schalten die Systeme einfach in einen Hot-Standby. Wenn die Datenbank auf der ausgefallenen Primärdatenbank entfernt (und dann von der neuen Primärdatenbank geklont) wird, sind teilweise Schreibvorgänge kein Problem.
Aber ich schätze, wenn wir anfingen, das zu empfehlen, dann „Ich weiß nicht, wie die Daten beschädigt wurden, ich habe gerade full_page_writes=off auf den Systemen gesetzt!“ würde einer der häufigsten Sätze kurz vor dem Tod für DBAs werden (zusammen mit „Ich habe diese Schlange auf Reddit gesehen, sie ist nicht giftig.“).
Zusammenfassung
Es gibt nicht viel, was Sie tun können, um ganzseitige Schreibvorgänge direkt zu optimieren. Bei den meisten Workloads finden die meisten ganzseitigen Schreibvorgänge direkt nach einem Prüfpunkt statt und verschwinden dann bis zum nächsten Prüfpunkt. Daher ist es wichtig, Checkpoints so einzustellen, dass sie nicht zu oft vorkommen.
Einige Entscheidungen auf Anwendungsebene können die Zufälligkeit von Schreibvorgängen in Tabellen und Indizes erhöhen – zum Beispiel sind UUID-Werte von Natur aus zufällig und verwandeln sogar eine einfache INSERT-Arbeitslast in zufällige Indexaktualisierungen. Das in den Beispielen verwendete Schema war eher trivial – in der Praxis wird es Sekundärindizes, Fremdschlüssel usw. geben. Aber die Verwendung von BIGSERIAL-Primärschlüsseln intern (und das Beibehalten der UUID als Ersatzschlüssel) würde zumindest die Schreibverstärkung reduzieren.
Ich bin wirklich an Diskussionen über die Notwendigkeit ganzseitiger Schreibvorgänge auf aktuellen Kerneln / Dateisystemen interessiert. Leider habe ich nicht viele Ressourcen gefunden. Wenn Sie also relevante Informationen haben, lassen Sie es mich wissen.