Letztes Jahr habe ich eine Lösung vorgestellt, um lesbare Secondaries für Verfügbarkeitsgruppen zu simulieren, ohne in die Enterprise Edition zu investieren. Nicht, um die Leute davon abzuhalten, die Enterprise Edition zu kaufen, da es viele Vorteile außerhalb von AGs gibt, aber mehr noch für diejenigen, die überhaupt keine Chance haben, die Enterprise Edition zu haben:
- Lesbare Secondaries mit kleinem Budget
Ich versuche, ein unermüdlicher Fürsprecher für die Kunden der Standard Edition zu sein; Es ist fast ein Running Gag, dass sich diese Ausgabe als Ganzes – angesichts der Anzahl der Funktionen, die sie in jeder neuen Version erhält – auf dem Weg der Abwertung befindet. In privaten Besprechungen mit Microsoft habe ich darauf gedrängt, dass Funktionen auch in die Standard Edition aufgenommen werden, insbesondere mit Funktionen, die für kleine Unternehmen viel vorteilhafter sind als für Unternehmen mit unbegrenztem Hardwarebudget.
Kunden der Enterprise Edition profitieren von den Verwaltbarkeits- und Leistungsvorteilen der Tabellenpartitionierung, aber diese Funktion ist in der Standard Edition nicht verfügbar. Kürzlich kam mir die Idee, dass es eine Möglichkeit gibt, zumindest einige der Vorteile der Partitionierung in jeder Edition zu erreichen, und zwar ohne partitionierte Ansichten. Das soll nicht heißen, dass partitionierte Sichten keine erwägenswerte Option sind; diese werden von anderen gut beschrieben, darunter Daniel Hutmacher (Partitionierte Ansichten über Tabellenpartitionierung) und Kimberly Tripp (Partitionierte Tabellen vs. Partitionierte Ansichten – Warum gibt es sie überhaupt noch?). Meine Idee ist nur etwas einfacher umzusetzen.
Dein neuer Held:Gefilterte Indizes
Nun, ich weiß, diese Funktion ist für manche ein Wort mit vier Buchstaben; Bevor Sie fortfahren, sollten Sie mit gefilterten Indizes zufrieden sein oder sich zumindest ihrer Einschränkungen bewusst sein. Etwas Lektüre, um Ihnen ein faires Gleichgewicht zu verschaffen, bevor ich versuche, sie Ihnen zu verkaufen:
- Ich spreche über mehrere Mängel in Wie gefilterte Indizes eine leistungsfähigere Funktion sein könnten, und weise auf viele Connect-Elemente hin, die Sie abstimmen können;
- Paul White (@SQL_Kiwi) spricht über Optimierungsprobleme in Optimizer Limitations with Filtered Indexes und auch in An Unexpected Side-Effect of Adding a Filtered Index; und,
- Jes Borland (@grrl_geek) sagt uns, was Sie mit gefilterten Indizes tun können (und was nicht).
Alle lesen? Und du bist immer noch hier? Großartig.
Die TL;DR davon ist, dass Sie gefilterte Indizes verwenden können, um alle Ihre „heißen Daten“ in einer separaten physischen Struktur und sogar auf separater zugrunde liegender Hardware zu speichern (Sie haben möglicherweise ein schnelles SSD- oder PCIe-Laufwerk zur Verfügung, aber es kann nicht nicht die ganze Tabelle).
Ein kurzes Beispiel
Es gibt viele Anwendungsfälle, in denen ein Teil der Daten viel häufiger abgefragt wird als der Rest – denken Sie an ein Einzelhandelsgeschäft, das Bestellungen verwaltet, eine Bäckerei, die die Lieferung von Hochzeitstorten plant, oder ein Fußballstadion, das Besucher- und Konzessionsdaten misst. In diesen Fällen geht es bei den meisten oder allen alltäglichen Abfrageaktivitäten um "aktuelle" Daten.
Halten wir es einfach; Wir erstellen eine Datenbank mit einer sehr engen Orders-Tabelle:
CREATE DATABASE PoorManPartition;GO USE PoorManPartition;GO CREATE TABLE dbo.Orders( OrderID INT IDENTITY(1,1) PRIMARY KEY, OrderDate DATE NOT NULL DEFAULT SYSUTCDATETIME(), OrderTotal DECIMAL(8,2) --, .. .andere Spalten...);
Nehmen wir nun an, Sie haben genug Platz auf Ihrem schnellen Speicher, um die Daten eines Monats aufzubewahren (mit viel Spielraum, um Saisonalität und zukünftiges Wachstum zu berücksichtigen). Wir können eine neue Dateigruppe hinzufügen und eine Datendatei auf dem schnellen Laufwerk ablegen.
ALTER DATABASE PoorManPartition ADD FILEGROUP HotData;GO ALTER DATABASE PoorManPartition ADD FILE ( Name =N'HotData', FileName =N'Z:\folder\HotData.mdf', Size =100MB, FileGrowth =25MB) TO FILEGROUP HotData;
Lassen Sie uns nun einen gefilterten Index für unsere HotData-Dateigruppe erstellen, wobei der Filter alles ab Anfang November 2015 enthält und die gemeinsamen Spalten, die an zeitbasierten Abfragen beteiligt sind, sich in der Schlüssel- oder Include-Liste befinden:
CREATE INDEX FilteredIndex ON dbo.Orders(OrderDate) INCLUDE(OrderTotal) WHERE OrderDate>='20151101' AND OrderDate <'20151201' ON HotData;
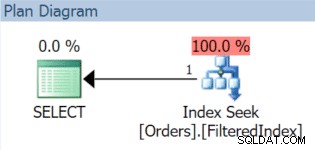
Wir können ein paar Zeilen einfügen und den Ausführungsplan überprüfen, um sicherzustellen, dass abgedeckte Abfragen tatsächlich den Index verwenden können:
INSERT dbo.Orders(OrderDate) VALUES('20151001'),('20151103'),('20151127');GO SELECT index_id, rows FROM sys.partitions WHERE object_id =OBJECT_ID(N'dbo.Orders'); /* Ergebnisse:index_id rows -------- ---- 1 3 2 2*/ SELECT OrderID, OrderDate, OrderTotal FROM dbo.Orders WHERE OrderDate>='20151102' AND OrderDate <'20151106';
Der resultierende Ausführungsplan verwendet tatsächlich den gefilterten Index (obwohl das Filterprädikat in der Abfrage nicht genau mit der Indexdefinition übereinstimmt):
Jetzt rollt der 1. Dezember herum, und es ist Zeit, unsere November-Daten auszutauschen und durch Dezember zu ersetzen. Wir können den gefilterten Index einfach mit einem neuen Filterprädikat neu erstellen und DROP_EXISTING verwenden Möglichkeit:
CREATE INDEX FilteredIndex ON dbo.Orders(OrderDate) INCLUDE(OrderTotal) WHERE OrderDate>='20151201' AND OrderDate <'20160101' WITH (DROP_EXISTING =ON) ON HotData;
Jetzt können wir ein paar weitere Zeilen hinzufügen, die Partitionsstatistiken überprüfen und unsere vorherige Abfrage und eine neue ausführen, um die verwendeten Indizes zu überprüfen:
INSERT dbo.Orders(OrderDate) VALUES('20151202'),('20151205');GO SELECT index_id, rows FROM sys.partitions WHERE object_id =OBJECT_ID(N'dbo.Orders'); /* Ergebnisse:index_id rows -------- ---- 1 5 2 2*/ SELECT OrderID, OrderDate, OrderTotal FROM dbo.Orders WHERE OrderDate>='20151102' AND OrderDate <'20151106'; WÄHLEN Sie OrderID, OrderDate, OrderTotal FROM dbo.Orders WHERE OrderDate>='20151202' AND OrderDate <'20151204';
In diesem Fall erhalten wir einen Clustered-Index-Scan mit der November-Abfrage:
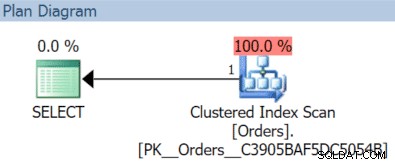
(Aber das wäre anders, wenn wir einen separaten, nicht gefilterten Index mit OrderDate als Schlüssel hätten.)
Und ich werde es nicht noch einmal zeigen, aber mit der Dezember-Abfrage erhalten wir die gleiche gefilterte Indexsuche wie zuvor.
Sie können auch mehrere Indizes verwalten, einen für den aktuellen Monat, einen für den Vormonat usw., und Sie können sie einfach separat verwalten (am 1. Dezember löschen Sie einfach den Index von Oktober und lassen beispielsweise den von November in Ruhe). . Sie können auch mehrere Indizes mit kürzeren oder längeren Zeitspannen (aktuelle und vorherige Woche, aktuelles und vorheriges Quartal) usw. verwalten. Die Lösung ist ziemlich flexibel.
Aufgrund der Einschränkungen gefilterter Indizes werde ich nicht versuchen, dies als perfekte Lösung oder als vollständigen Ersatz für die Tabellenpartitionierung oder partitionierte Ansichten darzustellen. Das Auswechseln einer Partition ist beispielsweise eine Metadatenoperation, während ein Index mit DROP_EXISTING neu erstellt wird kann eine Menge Protokollierung haben (und da Sie nicht die Enterprise Edition verwenden, kann sie nicht online ausgeführt werden). Möglicherweise stellen Sie auch fest, dass partitionierte Ansichten schneller sind – es gibt mehr Arbeit bei der Verwaltung separater physischer Tabellen und der Einschränkungen, die die partitionierte Ansicht ermöglichen, aber die Auszahlung in Bezug auf die Abfrageleistung könnte in einigen Fällen besser sein.
Automatisierung
Die Neuerstellung des Index kann ganz einfach automatisiert werden, indem ein einfacher Job verwendet wird, der etwa einmal im Monat (oder was auch immer Ihre "heiße" Fenstergröße ist) Folgendes ausführt:
DECLARE @sql NVARCHAR(MAX), @dt DATE =DATEADD(DAY, 1-DAY(GETDATE()), GETDATE()); SET @sql =N'CREATE INDEX FilteredIndex ON dbo.Orders(OrderDate) INCLUDE(OrderTotal) WHERE OrderDate>=''' + CONVERT(CHAR(8), @dt, 112) + N''' WITH (DROP_EXISTING =ON ) ON HotData;'; EXEC PoorManPartition.sys.sp_executesql @sql;
Sie könnten auch Monate im Voraus mehrere Indizes erstellen, ähnlich wie zukünftige Partitionen im Voraus erstellt werden – schließlich belegen die zukünftigen Indizes keinen Speicherplatz, bis es Daten gibt, die für ihre Prädikate relevant sind. Und Sie können einfach die Indizes löschen, die die älteren Daten segmentiert haben, die Sie jetzt kalt machen möchten.
Rückblick
Nachdem ich diesen Artikel beendet hatte, stieß ich natürlich auf einen weiteren Beitrag von Kimberly Tripp, den Sie lesen sollten, bevor Sie mit irgendetwas fortfahren, was ich hier befürworte (und den ich gelesen hatte, bevor ich anfing):
- Wie wäre es mit gefilterten Indizes statt Partitionierung?
Aus mehreren Gründen ist Kimberly viel mehr für partitionierte Ansichten, um etwas Ähnliches wie die Partitionierung in der Standard Edition zu implementieren. Für bestimmte Szenarien fasziniert mich die Verwendung gefilterter Indizes jedoch immer noch genug, um mit meinen Experimenten fortzufahren. Einer der Bereiche, in denen gefilterte Indizes von Vorteil sein können, ist, wenn Ihre „heißen“ Daten mehrere Kriterien haben – nicht nur nach Datum, sondern auch nach anderen Attributen (vielleicht möchten Sie schnelle Abfragen für alle Bestellungen aus diesem Monat, die für eine bestimmte Ebene gelten des Kunden oder über einem bestimmten Dollarbetrag).
Als Nächstes…
In einem zukünftigen Beitrag werde ich mit diesem Konzept auf einem High-End-System mit etwas realer Lautstärke und Arbeitslast spielen. Ich möchte Leistungsunterschiede zwischen dieser Lösung, einem nicht gefilterten abdeckenden Index, einer partitionierten Ansicht und einer partitionierten Tabelle entdecken. Innerhalb einer VM auf einem Laptop mit nur verfügbaren SSDs würde es wahrscheinlich keine realistischen oder fairen Tests in großem Maßstab geben.