In den letzten Monaten haben wir bei 2ndQuadrant an der Zusammenführung von PostgreSQL 9.6 in Postgres-XL gearbeitet, was sich aus verschiedenen Gründen als ziemlich herausfordernd herausstellte und aufgrund mehrerer invasiver Upstream-Änderungen mehr Zeit in Anspruch nahm als ursprünglich geplant. Wenn Sie interessiert sind, schauen Sie sich das offizielle Repository hier an (schauen Sie sich vorerst den „Master“-Zweig an).
Es gibt noch einiges zu tun – Zusammenführen einiger verbleibender Bits aus dem Upstream, Beheben bekannter Fehler und Regressionsfehler, Testen usw. Wenn Sie erwägen, zu Postgres-XL beizutragen, ist dies eine ideale Gelegenheit (senden Sie mir eine E-Mail und ich helfe Ihnen bei den ersten Schritten).
Aber insgesamt ist Postgres-XL 9.6 in einigen wichtigen Bereichen eindeutig ein großer Schritt nach vorne.
Neue Funktionen in Postgres-XL 9.6
Welche neuen Funktionen erhält Postgres-XL also durch die Zusammenführung von PostgreSQL 9.6? Ich könnte Sie einfach auf die Versionshinweise der Originalautoren verweisen – die meisten Verbesserungen gelten direkt für XL 9.6, mit Ausnahme derjenigen, die sich auf Funktionen beziehen, die von XL nicht unterstützt werden.
Die wichtigste für den Benutzer sichtbare Verbesserung in PostgreSQL 9.6 war eindeutig die parallele Abfrage, und das gilt auch für Postgres-XL 9.6.
Knoteninterne Parallelität
Vor PostgreSQL 9.6 war Postgres-XL eine der Möglichkeiten, parallele Abfragen zu erhalten (indem mehrere Postgres-XL-Knoten auf demselben Computer platziert wurden). Seit PostgreSQL 9.6 ist dies nicht mehr erforderlich, aber es bedeutet auch, dass Postgres-XL die Fähigkeit zur knoteninternen Parallelität erhält.
Zum Vergleich:Postgres-XL 9.5 ermöglichte Ihnen Folgendes – das Verteilen einer Abfrage auf mehrere Datenknoten, aber jeder Datenknoten unterlag immer noch dem Limit „ein Backend pro Abfrage“, genau wie normales PostgreSQL.
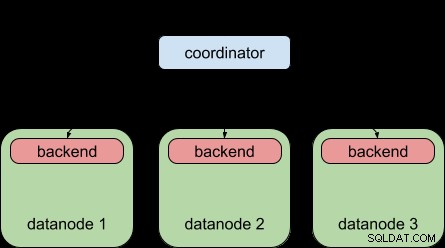
Dank der parallelen Abfragefunktion von PostgreSQL 9.6 kann Postgres-XL 9.6 jetzt Folgendes tun:
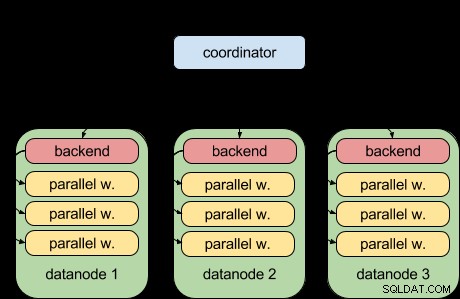
Das heißt, jeder Datenknoten kann nun seinen Teil der Abfrage parallel ausführen, indem er die Upstream-Infrastruktur für parallele Abfragen verwendet. Das ist großartig und macht Postgres-XL viel leistungsfähiger, wenn es um analytische Workloads geht.
Wartung eines Forks
Ich habe erwähnt, dass sich diese Zusammenführung aus mehreren Gründen als herausfordernder herausstellte, als wir ursprünglich erwartet hatten.
Erstens ist die Wartung von Forks im Allgemeinen schwierig, insbesondere wenn das Upstream-Projekt so schnell voranschreitet wie PostgreSQL. Sie müssen spezifische Funktionen für Ihren Fork entwickeln, weshalb Forks überhaupt existieren. Aber du willst auch mit dem Upstream mithalten, sonst gerätst du hoffnungslos ins Hintertreffen. Aus diesem Grund stecken einige der bestehenden Forks immer noch in PostgreSQL 8.x fest und es fehlen alle seither festgeschriebenen Extras.
Zweitens wurde die Zusammenführung in einem großen Klumpen durchgeführt, genau wie alle vorherigen (9.5, 9.2, …). Das heißt, alle Upstream-Commits wurden in einem einzigen git merge-Befehl zusammengeführt. Das wird ziemlich garantiert viele Merge-Konflikte verursachen, in dem Maße, dass der Code nicht einmal kompiliert wird, ganz zu schweigen von laufenden Regressionstests oder ähnlichem.
Bei der ersten Reihe von Korrekturen geht es also darum, sie in einen kompilierbaren Zustand zu bringen, bei der nächsten Reihe geht es darum, sie tatsächlich ohne sofortige Segfaults auszuführen, und schließlich beginnt die „normale“ Fehlerbehebung (Regressionstests ausführen, Probleme beheben, spülen und wiederholen). .
Diese Komplexitäten sind der Fork-Wartung inhärent (und ein Grund, warum Sie wahrscheinlich noch einmal darüber nachdenken sollten, einen weiteren Fork zu starten, und stattdessen direkt entweder zu Postgres und/oder Postgres-XL beitragen).
Aber es gibt Möglichkeiten, die Auswirkungen deutlich zu reduzieren – zum Beispiel planen wir, die nächste Zusammenführung (mit PostgreSQL 10) in kleineren Stücken durchzuführen. Das sollte das Ausmaß von Zusammenführungskonflikten minimieren und es uns ermöglichen, die Fehler viel schneller zu beheben.
Näher an PostgreSQL
Interessanterweise ermöglichte uns die Übernahme der Parallelität vom Upstream auch, viel Code aus der XL-Codebasis zu entfernen – ein Paradebeispiel dafür ist der parallele Aggregatcode, der den XL-spezifischen Code problemlos ersetzte.
Ein weiteres Beispiel für eine Upstream-Änderung, die sich erheblich auf den XL-Code ausgewirkt hat, ist die „Pathifizierung“ des oberen Planers, die spät im 9.6-Entwicklungszyklus vorangetrieben wurde. Dies stellte sich als sehr invasive Änderung heraus (tatsächlich hängen wahrscheinlich einige der offenen Fehler damit zusammen), aber am Ende erlaubte es uns, den Planungscode zu vereinfachen (im Wesentlichen richtige Pfade zu konstruieren, anstatt den resultierenden Plan zu optimieren).
Wenn ich sage, dass wir durch die Zusammenführung den XL-Code vereinfachen und näher an PostgreSQL heranführen konnten, was meine ich damit? Der einfachste Weg, die Änderung zu quantifizieren, besteht darin, „git diff –stat“ gegen den passenden Upstream-Zweig auszuführen und die Zahlen zu vergleichen. Für die Zweige 9.5 und 9.6 sehen die Ergebnisse so aus:
| Version | Dateien geändert | Zusätze | Löschungen |
|---|---|---|---|
| XL 9,5 | 1099 | 234509 | 18336 |
| XL 9,6 | 1051 | 201158 | 17627 |
| delta | -48 (-4,3 %) | -33351 (-14,2 %) | -709 (-3,8 %) |
Die Zusammenführung von 9.6 reduziert das Delta gegenüber dem Upstream deutlich (insgesamt um ~14 %). Woher kommt dieser Unterschied?
Erstens ist ein Teil dieser Reduzierung auf eine echte Code-Vereinfachung zurückzuführen. Ein Paradebeispiel dafür ist Parallel Aggregat, das so ziemlich ein 1:1-Ersatz der ursprünglichen Postgres-XL-Implementierung ist. Also haben wir das einfach herausgerissen und verwenden stattdessen die Upstream-Implementierung. Wir hoffen, in Zukunft mehr solcher Orte zu finden und die Upstream-Implementierung zu verwenden, anstatt unsere eigene zu pflegen.
Zweitens ergibt sich ein Großteil der Reduzierung aus dem Entfernen von totem Code. Wir haben nicht nur einige tote/nicht erreichbare Code-Bits reduziert, wir haben auch einige Quelldateien entdeckt, die nicht einmal kompiliert wurden, und so weiter.
Was kommt als nächstes?
An diesem Punkt haben wir die Änderungen bis zu b5bce6c1 zusammengeführt, wo sich PostgreSQL 9.6 vom Master getrennt hat. Um mit PostgreSQL 9.6.2 Schritt zu halten, müssen wir also die verbleibenden Änderungen im 9.6-Zweig zusammenführen. Wenn man bedenkt, dass es hauptsächlich nur Bugfixes geben sollte, sollte das im Vergleich zum vollständigen Zusammenführen eine (hoffentlich) ziemlich einfache Arbeit sein.
Natürlich wird es Bugs geben. Tatsächlich gibt es zu diesem Zeitpunkt noch einige fehlgeschlagene Regressionstests. Das muss behoben werden, bevor XL 9.6 offiziell veröffentlicht wird. Und wir müssen weitere Tests durchführen. Wenn Sie also daran interessiert sind, Postgres-XL zu helfen, wäre dies äußerst vorteilhaft.
Ein Ärgernis, von dem wir immer wieder hören, sind Pakete oder deren Fehlen. Sie haben vielleicht bemerkt, dass die letzten verfügbaren Pakete ziemlich alt sind, und es gibt nur .rpm, sonst nichts. Wir planen, dies anzugehen und beginnen, aktuelle Pakete in mehreren Varianten anzubieten (z. B. .rpm und .deb).
Wir planen auch, einige Änderungen an der Organisation des Entwicklungsprozesses vorzunehmen, um es einfacher zu machen, am Entwicklungsprozess mitzuwirken und daran teilzunehmen. Das ist wirklich ein separates Thema, das nichts mit dem 9.6-Zweig zu tun hat, also werde ich in ein paar Tagen weitere Details dazu posten.