Ich denke, es liegt an einer „Dichte“ von Datensätzen mit demselben Schlüssel auf der Festplatte. Ich denke, die Datensätze mit derselben ID werden dicht gespeichert (d. H. Wenige Anzahl von Blöcken) und diejenigen mit demselben Link werden spärlich gespeichert (d. H. , verteilt auf eine große Anzahl von Blöcken). Wenn Sie Datensätze in der Reihenfolge der ID eingefügt haben, kann diese Situation auftreten.
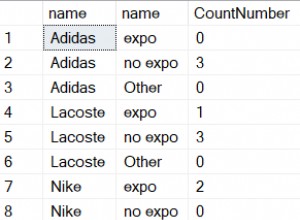
Angenommen:1. es gibt 10.000 Aufzeichnungen,2. sie werden in der Reihenfolge wie (id, link) =(1, 1), (1, 2), ..., (1, 100), (2, 1) ... und 3 gespeichert. 50 Datensätze können in einem Block gespeichert werden.
In der obigen Annahme besteht Block #1~#3 aus den Datensätzen (1, 1)~(1, 50), (1, 51)~(1, 100) und (2, 1)~(2, 50) bzw..
Wenn Sie SELECT * FROM edges WHERE id=1 , nur 2 Blöcke (#1, #2) geladen und gescannt werden. Andererseits SELECT * FROM edges WHERE link=1 benötigt 50 Blöcke (#1, #3, #5,...), obwohl die Anzahl der Zeilen gleich ist.