Einführung
Erreichen von minimaler Protokollierung mit INSERT...SELECT in ein leeres Clustered-Index-Ziel ist nicht ganz so einfach wie im Data Performance Loading Guide beschrieben .
Dieser Beitrag enthält neue Details über die Anforderungen für minimale Protokollierung wenn das Einfügeziel ein leerer herkömmlicher gruppierter Index ist. (Das Wort „traditionell“ dort schließt columnstore aus und speicheroptimiert („Hekaton“) geclusterte Tische). Informationen zu den Bedingungen, die gelten, wenn die Zieltabelle ein Heap ist, finden Sie im vorherigen Artikel dieser Reihe.
Zusammenfassung für geclusterte Tabellen
Der Leitfaden zur Leistung beim Laden von Daten enthält eine allgemeine Zusammenfassung der Bedingungen, die für minimale Protokollierung erforderlich sind in geclusterte Tabellen:
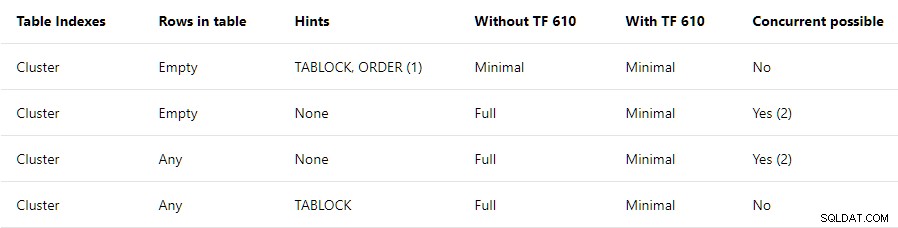
Dieser Beitrag befasst sich mit der obersten Reihe . Es besagt, dass TABLOCK und ORDER Hinweise sind erforderlich, mit einem Hinweis, der besagt:
Bei Verwendung von BULK INSERT muss der Bestellhinweis verwendet werden.
Leeres Ziel mit Tabellensperre
Die oberste Zeile der Zusammenfassung schlägt vor, dass alle Einfügungen in einen leeren gruppierten Index werden minimal protokolliert solange TABLOCK und ORDER Hinweise sind angegeben. Der TABLOCK Hinweis ist erforderlich, um RowSetBulk zu aktivieren Einrichtung, wie sie für Haufentisch-Massenladungen verwendet wird. Eine ORDER Der Hinweis ist erforderlich, um sicherzustellen, dass die Zeilen beim Clustered Index Insert ankommen Planoperator in Schlüsselreihenfolge des Zielindex . Ohne diese Garantie fügt SQL Server möglicherweise Indexzeilen hinzu, die nicht korrekt sortiert sind, was nicht gut wäre.
Im Gegensatz zu anderen Massenlademethoden ist dies nicht möglich um die erforderliche ORDER anzugeben Hinweis auf ein INSERT...SELECT Erklärung. Dieser Hinweis ist nicht dasselbe wie die Verwendung eines ORDER BY -Klausel auf INSERT...SELECT Erklärung. Ein ORDER BY -Klausel auf einem INSERT garantiert nur die Art und Weise irgendeine Identität Es werden Werte zugewiesen, nicht die Reihenfolge beim Einfügen von Zeilen.
Für INSERT...SELECT , trifft SQL Server seine eigene Feststellung ob sichergestellt werden soll, dass Zeilen dem Clustered Index Insert präsentiert werden Operator in Schlüsselreihenfolge oder nicht. Das Ergebnis dieser Bewertung ist in Ausführungsplänen über DMLRequestSort sichtbar Eigenschaft der Einfügung Operator. Der DMLRequestSort Eigenschaft muss auf true gesetzt werden für INSERT...SELECT in einen minimal protokollierten Index . Wenn es auf false gesetzt ist , minimale Protokollierung kann nicht vorkommen.
DMLRequestSort haben auf true setzen ist die einzig akzeptable Garantie der Einfügereihenfolge für SQL Server. Man könnte den Ausführungsplan inspizieren und vorhersagen dass Zeilen in der Reihenfolge der Clustered-Indizes ankommen sollen/werden/müssen, aber ohne die spezifischen internen Garantien bereitgestellt von DMLRequestSort , diese Bewertung zählt nichts.
Wenn DMLRequestSort ist wahr , SQL Server darf Führen Sie eine explizite Sortierung ein Bediener im Ausführungsplan. Wenn es die Sortierung intern auf andere Weise gewährleisten kann, wird die Sortierung kann weggelassen werden. Wenn sowohl sortierte als auch nicht sortierte Alternativen verfügbar sind, erstellt der Optimierer eine kostenbasierte Auswahl. Die Kostenanalyse berücksichtigt keine minimale Protokollierung direkt; es wird von den erwarteten Vorteilen der sequentiellen E/A und der Vermeidung der Seitenaufteilung angetrieben.
DMLRequestSort-Bedingungen
Beide der folgenden Tests müssen bestanden werden, damit SQL Server DMLRequestSort festlegen kann auf wahr beim Einfügen in einen leeren gruppierten Index mit angegebener Tabellensperre:
- Eine Schätzung von mehr als 250 Zeilen auf der Eingabeseite des Clustered Index Insert Operator; und
- Eine Schätzung Datengröße von mehr als 2 Seiten . Die geschätzte Datengröße ist keine Ganzzahl, daher würde ein Ergebnis von 2.001 Seiten diese Bedingung erfüllen.
(Dies erinnert Sie möglicherweise an die Bedingungen für die minimale Protokollierung im Heap , aber die erforderliche geschätzte Die Datengröße beträgt hier zwei statt acht Seiten.)
Berechnung der Datengröße
Die geschätzte Datengröße Die Berechnung unterliegt hier denselben Macken, die im vorherigen Artikel für Heaps beschrieben wurden, außer dass die 8-Byte-RID ist nicht vorhanden.
Für SQL Server 2012 und früher bedeutet dies 5 zusätzliche Bytes pro Zeile werden in die Berechnung der Datengröße einbezogen:Ein Byte für ein internes Bit Flag und vier Bytes für den uniquifier (Wird in der Berechnung auch für eindeutige Indizes verwendet, die keinen Uniquifier speichern ).
Für SQL Server 2014 und höher der uniquifier wird für unique korrekt weggelassen Indizes, aber das ein zusätzliche Byte für das interne Bit Flag bleibt erhalten.
Demo
Das folgende Skript sollte auf einer SQL Server-Entwicklungsinstanz in einer neuen Testdatenbank ausgeführt werden eingestellt, um den SIMPLE zu verwenden oder BULK_LOGGED Wiederherstellungsmodell.
Die Demo lädt mit INSERT...SELECT 268 Zeilen in eine brandneue gruppierte Tabelle mit TABLOCK , und Berichte zu den generierten Transaktionsprotokolldatensätzen.
IF OBJECT_ID(N'dbo.Test', N'U') IS NOT NULL
BEGIN
DROP TABLE dbo.Test;
END;
GO
CREATE TABLE dbo.Test
(
id integer NOT NULL IDENTITY
CONSTRAINT [PK dbo.Test (id)]
PRIMARY KEY,
c1 integer NOT NULL,
padding char(45) NOT NULL
DEFAULT ''
);
GO
-- Clear the log
CHECKPOINT;
GO
-- Insert rows
INSERT dbo.Test WITH (TABLOCK)
(c1)
SELECT TOP (268)
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV;
GO
-- Show log entries
SELECT
FD.Operation,
FD.Context,
FD.[Log Record Length],
FD.[Log Reserve],
FD.AllocUnitName,
FD.[Transaction Name],
FD.[Lock Information],
FD.[Description]
FROM sys.fn_dblog(NULL, NULL) AS FD;
GO
-- Count the number of fully-logged rows
SELECT
[Fully Logged Rows] = COUNT_BIG(*)
FROM sys.fn_dblog(NULL, NULL) AS FD
WHERE
FD.Operation = N'LOP_INSERT_ROWS'
AND FD.Context = N'LCX_CLUSTERED'
AND FD.AllocUnitName = N'dbo.Test.PK dbo.Test (id)';
(Wenn Sie das Skript auf SQL Server 2012 oder früher ausführen, ändern Sie die TOP Klausel im Skript von 268 bis 252, aus Gründen, die gleich erklärt werden.)
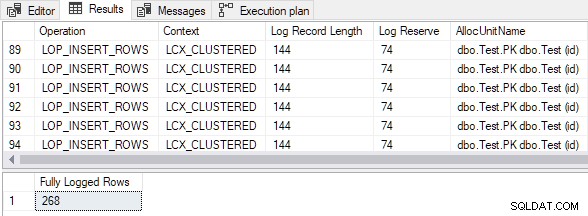
Die Ausgabe zeigt, dass alle eingefügten Zeilen vollständig protokolliert wurden trotz leer gruppierte Zieltabelle und TABLOCK Hinweis:
Berechnete Insert-Datengröße
Die Eigenschaften des Ausführungsplans des Clustered Index Insert Operator zeigen, dass DMLRequestSort auf false gesetzt ist . Dies liegt daran, dass, obwohl die geschätzte Anzahl einzufügender Zeilen mehr als 250 beträgt (was die erste Anforderung erfüllt), die berechnete Datengröße nicht zwei 8-KB-Seiten überschreiten.
Die Berechnungsdetails (ab SQL Server 2014) lauten wie folgt:
- Gesamtzahl fester Länge Spaltengröße =54 Byte :
- Geben Sie id 104
bitein =1 Byte (intern). - Geben Sie id 56
integerein =4 Bytes (idSpalte). - Geben Sie id 56
integerein =4 Bytes (c1Spalte). - Geben Sie id 175
char(45)ein =45 Bytes (paddingSpalte).
- Geben Sie id 104
- Null-Bitmap =3 Byte .
- Zeilenkopf Overhead =4 Byte .
- Berechnete Zeilengröße =54 + 3 + 4 =61 Byte .
- Berechnete Datengröße =61 Byte * 268 Zeilen =16.348 Byte .
- Berechnete Datenseiten =16.384 / 8192 =1,99560546875 .
Die berechnete Zeilengröße (61 Bytes) unterscheidet sich von der tatsächlichen Zeilenspeichergröße (60 Bytes) durch das zusätzliche Byte interner Metadaten, das im Einfügungsstrom vorhanden ist. Die Berechnung berücksichtigt auch nicht die 96 Bytes, die auf jeder Seite vom Seitenkopf verwendet werden, oder andere Dinge wie den Mehraufwand für die Zeilenversionierung. Dieselbe Berechnung auf SQL Server 2012 fügt weitere 4 Bytes pro Zeile für den Uniquifier hinzu (was, wie bereits erwähnt, nicht in eindeutigen Indizes vorhanden ist). Die zusätzlichen Bytes bedeuten, dass voraussichtlich weniger Zeilen auf jede Seite passen:
- Berechnete Zeilengröße =61 + 4 =65 Byte .
- Berechnete Datengröße =65 Byte * 252 Zeilen =16.380 Byte
- Berechnete Datenseiten =16.380 / 8192 =1,99951171875 .
Ändern des TOP -Klausel von 268 Zeilen auf 269 (oder von 252 auf 253 für 2012) macht die Berechnung der erwarteten Datengröße gerade Tipp über die Mindestschwelle von 2 Seiten:
- SQL Server 2014
- 61 Byte * 269 Zeilen =16.409 Byte.
- 16.409 / 8192 =2,0030517578125 Seiten.
- SQL Server 2012
- 65 Byte * 253 Zeilen =16.445 Byte.
- 16.445 / 8192 =2,0074462890625 Seiten.
Wobei nun auch die zweite Bedingung erfüllt ist, DMLRequestSort auf true gesetzt ist , und minimale Protokollierung erreicht wird, wie in der Ausgabe unten gezeigt:
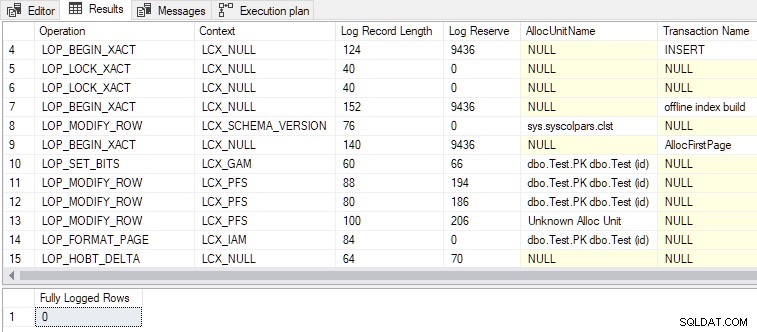
Einige andere interessante Punkte:
- Es werden insgesamt 79 Protokolldatensätze generiert, verglichen mit 328 für die vollständig protokollierte Version. Weniger Protokolldatensätze sind das erwartete Ergebnis einer minimalen Protokollierung.
- Der
LOP_BEGIN_XACTAufzeichnungen in der minimal protokollierten Datensätze belegen vergleichsweise viel Logspace (jeweils 9436 Byte). - Einer der in den Protokolldatensätzen aufgeführten Transaktionsnamen ist „Offline-Indexerstellung“ . Obwohl wir nicht darum gebeten haben, einen Index als solchen zu erstellen, ist das Massenladen von Zeilen in einen leeren Index im Wesentlichen derselbe Vorgang.
- Die vollständig protokollierte insert nimmt eine exklusive Sperre auf Tabellenebene (
Tab-X), während die minimal protokolliert insert übernimmt die Schemaänderung (Sch-M) genau wie ein „echter“ Offline-Indexaufbau. - Massenladen einer leeren gruppierten Tabelle mit
INSERT...SELECTmitTABLOCKundDMRequestSortauf true setzen verwendet denRowsetBulkMechanismus, genau wie der minimal protokollierte haufenweise getan im vorigen Artikel.
Kardinalitätsschätzungen
Achten Sie auf niedrige Kardinalitätsschätzungen bei Clustered Index Insert Operator. Wenn einer der Schwellenwerte zum Festlegen von DMLRequestSort erforderlich ist auf wahr aufgrund einer ungenauen Kardinalitätsschätzung nicht erreicht wird, wird die Einfügung vollständig protokolliert , unabhängig von der tatsächlichen Anzahl der Zeilen und der Gesamtdatengröße, die zur Ausführungszeit angetroffen wurden.
Zum Beispiel das Ändern von TOP -Klausel im Demoskript, um eine Variable zu verwenden, führt zu einer Rate mit fester Kardinalität von 100 Zeilen, was unter dem Minimum von 251 Zeilen liegt:
-- Insert rows
DECLARE @NumRows bigint = 269;
INSERT dbo.Test WITH (TABLOCK)
(c1)
SELECT TOP (@NumRows)
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV; Caching planen
Der DMLRequestSort Die Eigenschaft wird als Teil des zwischengespeicherten Plans gespeichert. Wenn ein zwischengespeicherter Plan wiederverwendet wird , der Wert von DMLRequestSort wird nicht neu berechnet zur Ausführungszeit, es sei denn, es erfolgt eine Neukompilierung. Beachten Sie, dass für TRIVIAL keine Neukompilierungen stattfinden Pläne basierend auf Änderungen in Statistiken oder Tabellenkardinalitäten.
Eine Möglichkeit, unerwartetes Verhalten aufgrund von Caching zu vermeiden, ist die Verwendung einer OPTION (RECOMPILE) Hinweis. Dadurch wird die richtige Einstellung für DMLRequestSort sichergestellt wird auf Kosten einer Kompilierung bei jeder Ausführung neu berechnet.
Trace-Flag
Es ist möglich, DMLRequestSort zu erzwingen auf true gesetzt werden durch die Einstellung undokumentiert und nicht unterstützt Trace-Flag 2332, wie ich in Optimieren von T-SQL-Abfragen geschrieben habe, die Daten ändern. Leider nicht beeinflussen die minimale Protokollierung Berechtigung für leere gruppierte Tabellen – die Einfügung muss immer noch auf mehr als 250 Zeilen und 2 Seiten geschätzt werden. Dieses Trace-Flag wirkt sich auf andere minimale Protokollierung aus Szenarien, die im letzten Teil dieser Serie behandelt werden.
Zusammenfassung
Massenladen eines leeren gruppierter Index mit INSERT...SELECT verwendet den RowsetBulk wieder Mechanismus zum Massenladen von Heap-Tabellen. Dies erfordert eine Tabellensperre (normalerweise erreicht mit einem TABLOCK Hinweis) und eine ORDER Hinweis. Es gibt keine Möglichkeit, einen ORDER hinzuzufügen Hinweis auf ein INSERT...SELECT Erklärung. Als Folge wird eine minimale Protokollierung erreicht in eine leere gruppierte Tabelle erfordert, dass DMLRequestSort Eigenschaft des Clustered Index Insert Operator ist auf true gesetzt . Dies garantiert an SQL Server, die dem Insert präsentiert werden Der Operator kommt in der Reihenfolge der Zielindexschlüssel an. Der Effekt ist derselbe wie bei Verwendung des ORDER Hinweis für andere Bulk-Insert-Methoden wie BULK INSERT verfügbar und bcp .
Damit für DMLRequestSort auf true gesetzt werden , muss Folgendes vorhanden sein:
- Mehr als 250 Zeilen geschätzt eingefügt werden; und
- Eine Schätzung Datengröße von mehr als zwei Seiten einfügen .
Die geschätzte Berechnung der Datengröße einfügen nicht dem Ergebnis der Multiplikation der geschätzten Zeilenanzahl des Ausführungsplans entsprechen und geschätzte Zeilengröße Eigenschaften am Eingang zum Insert Operator. Die interne Berechnung enthält (fälschlicherweise) eine oder mehrere interne Spalten im Einfügungsstrom, die nicht im endgültigen Index beibehalten werden. Die interne Berechnung berücksichtigt auch keine Seitenkopfzeilen oder andere Overheads wie die Zeilenversionierung.
Beim Testen oder Debuggen von minimaler Protokollierung Probleme, achten Sie auf niedrige Kardinalitätsschätzungen und denken Sie daran, dass die Einstellung von DMLRequestSort wird als Teil des Ausführungsplans zwischengespeichert.
Der letzte Teil dieser Serie beschreibt die Bedingungen, die erforderlich sind, um eine minimale Protokollierung zu erreichen ohne Verwendung von RowsetBulk Mechanismus. Diese entsprechen direkt den neuen Einrichtungen, die unter Ablaufverfolgungsflag 610 zu SQL Server 2008 hinzugefügt und dann ab SQL Server 2016 standardmäßig aktiviert wurden.