Einfachere Alternative zu Ihrer geposteten Antwort. Sollte viel besser funktionieren.
Diese Funktion ruft eine Zeile aus einer bestimmten Tabelle ab (in_table_name ) und Primärschlüsselwert (in_row_pk ) und fügt sie als neue Zeile in dieselbe Tabelle ein, wobei einige Werte ersetzt werden (in_override_values ). Der neue Primärschlüsselwert wird standardmäßig zurückgegeben (pk_new ).
CREATE OR REPLACE FUNCTION f_clone_row(in_table_name regclass
, in_row_pk int
, in_override_values hstore
, OUT pk_new int) AS
$func$
DECLARE
_pk text; -- name of PK column
_cols text; -- list of names of other columns
BEGIN
-- Get name of PK column
SELECT INTO _pk a.attname
FROM pg_catalog.pg_index i
JOIN pg_catalog.pg_attribute a ON a.attrelid = i.indrelid
AND a.attnum = i.indkey[0] -- 1 PK col!
WHERE i.indrelid = 't'::regclass
AND i.indisprimary;
-- Get list of columns excluding PK column
_cols := array_to_string(ARRAY(
SELECT quote_ident(attname)
FROM pg_catalog.pg_attribute
WHERE attrelid = in_table_name -- regclass used as OID
AND attnum > 0 -- exclude system columns
AND attisdropped = FALSE -- exclude dropped columns
AND attname <> _pk -- exclude PK column
), ',');
-- INSERT cloned row with override values, returning new PK
EXECUTE format('
INSERT INTO %1$I (%2$s)
SELECT %2$s
FROM (SELECT (t #= $1).* FROM %1$I t WHERE %3$I = $2) x
RETURNING %3$I'
, in_table_name, _cols, _pk)
USING in_override_values, in_row_pk -- use override values directly
INTO pk_new; -- return new pk directly
END
$func$ LANGUAGE plpgsql;
Aufruf:
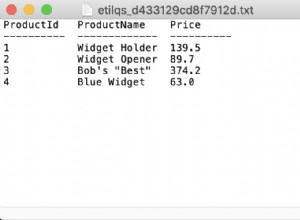
SELECT f_clone_row('t', 1, '"col1"=>"foo_new","col2"=>"bar_new"'::hstore);
-
Verwenden Sie
regclassals Eingabeparametertyp, sodass zunächst nur gültige Tabellennamen verwendet werden können und eine SQL-Injection ausgeschlossen ist. Die Funktion schlägt auch früher und eleganter fehl, wenn Sie einen ungültigen Tabellennamen angeben sollten. -
Verwenden Sie ein
OUTParameter (pk_new), um die Syntax zu vereinfachen. -
Der nächste Wert für den Primärschlüssel muss nicht manuell ermittelt werden. Es wird automatisch eingefügt und im Nachhinein zurückgegeben. Das ist nicht nur einfacher und schneller, Sie vermeiden auch verschwendete oder falsche Sequenznummern.
-
Verwenden Sie
format()um die Zusammenstellung der dynamischen Abfragezeichenfolge zu vereinfachen und weniger fehleranfällig zu machen. Beachten Sie, wie ich Positionsparameter für Bezeichner bzw. Zeichenfolgen verwende. -
Ich baue auf Ihrer impliziten Annahme auf dass zulässige Tabellen eine einzelne Primärschlüsselspalte vom Typ Integer mit einem Spaltenstandard haben . Typischerweise
serialSpalten. -
Schlüsselelement der Funktion ist das abschließende
INSERT:- Fügen Sie Überschreibungswerte mit der vorhandenen Zeile zusammen, indem Sie
#=Betreiber in einer Unterauswahl und zerlegen Sie die resultierende Zeile sofort. - Dann können Sie im Haupt-
SELECTnur relevante Spalten auswählen . - Lassen Sie Postgres den Standardwert für den PK zuweisen und erhalten Sie ihn mit dem
RETURNINGzurück Klausel. - Schreiben Sie den zurückgegebenen Wert in
OUTParameter direkt. - Alles in einem einzigen SQL-Befehl erledigt, das ist im Allgemeinen am schnellsten.
- Fügen Sie Überschreibungswerte mit der vorhandenen Zeile zusammen, indem Sie