In meinem letzten Beitrag haben wir gesehen, wie eine Abfrage mit einem skalaren Aggregat vom Optimierer in eine effizientere Form umgewandelt werden kann. Zur Erinnerung, hier ist noch einmal das Schema:
CREATE TABLE dbo.T1 (pk integer PRIMARY KEY, c1 integer NOT NULL);
CREATE TABLE dbo.T2 (pk integer PRIMARY KEY, c1 integer NOT NULL);
CREATE TABLE dbo.T3 (pk integer PRIMARY KEY, c1 integer NOT NULL);
GO
INSERT dbo.T1 (pk, c1)
SELECT n, n
FROM dbo.Numbers AS N
WHERE n BETWEEN 1 AND 50000;
GO
INSERT dbo.T2 (pk, c1)
SELECT pk, c1 FROM dbo.T1;
GO
INSERT dbo.T3 (pk, c1)
SELECT pk, c1 FROM dbo.T1;
GO
CREATE INDEX nc1 ON dbo.T1 (c1);
CREATE INDEX nc1 ON dbo.T2 (c1);
CREATE INDEX nc1 ON dbo.T3 (c1);
GO
CREATE VIEW dbo.V1
AS
SELECT c1 FROM dbo.T1
UNION ALL
SELECT c1 FROM dbo.T2
UNION ALL
SELECT c1 FROM dbo.T3;
GO
-- The test query
SELECT MAX(c1)
FROM dbo.V1; Planungsoptionen
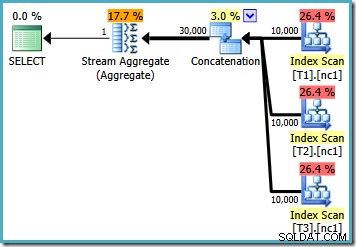
Mit 10.000 Zeilen in jeder der Basistabellen erstellt der Optimierer einen einfachen Plan, der das Maximum berechnet, indem er alle 30.000 Zeilen in ein Aggregat einliest:
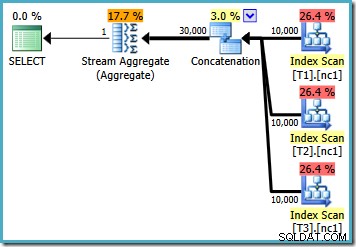
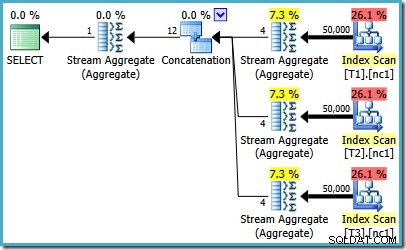
Mit 50.000 Zeilen in jeder Tabelle verbringt der Optimierer etwas mehr Zeit mit dem Problem und findet einen intelligenteren Plan. Es liest nur die oberste Zeile (in absteigender Reihenfolge) aus jedem Index und berechnet dann das Maximum aus nur diesen 3 Zeilen:
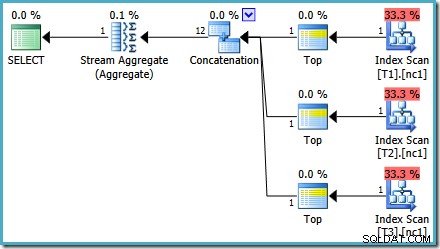
Ein Optimierungsfehler
Vielleicht fällt Ihnen an dieser Schätzung etwas Merkwürdiges auf planen. Der Concatenation-Operator liest eine Zeile aus drei Tabellen und erzeugt irgendwie zwölf Zeilen! Dies ist ein Fehler, der durch einen Fehler in der Kardinalitätsschätzung verursacht wird, den ich im Mai 2011 gemeldet habe. Er ist seit SQL Server 2014 CTP 1 immer noch nicht behoben (selbst wenn der neue Kardinalitätsschätzer verwendet wird), aber ich hoffe, dass er für die behoben wird endgültige Version.
Um zu sehen, wie der Fehler zustande kommt, erinnern Sie sich daran, dass eine der Planalternativen, die vom Optimierer für den Fall mit 50.000 Zeilen berücksichtigt wurden, Teilaggregate unterhalb des Verkettungsoperators aufweist:
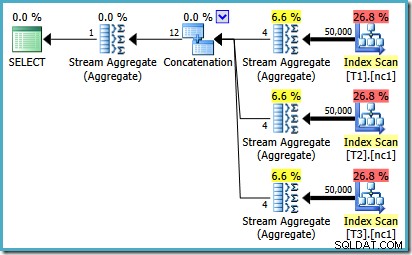
Es ist die Kardinalitätsschätzung für diese partiellen MAX Aggregate, die schuld sind. Sie schätzen vier Zeilen, wobei das Ergebnis garantiert eine Zeile ist. Möglicherweise sehen Sie eine andere Zahl als vier – dies hängt davon ab, wie viele logische Prozessoren dem Optimierer zum Zeitpunkt der Kompilierung des Plans zur Verfügung stehen (siehe den obigen Fehlerlink für weitere Details).
Der Optimierer ersetzt später die partiellen Aggregate durch Top(1)-Operatoren, die die Kardinalitätsschätzung korrekt neu berechnen. Leider spiegelt der Concatenation-Operator immer noch die Schätzungen für die ersetzten Teilaggregate wider (3 * 4 =12). Als Ergebnis erhalten wir eine Verkettung, die 3 Zeilen liest und 12 erzeugt.
TOP statt MAX verwenden
Wenn wir uns den 50.000-Zeilen-Plan noch einmal ansehen, scheint es, dass die größte Verbesserung, die der Optimierer gefunden hat, darin besteht, Top (1)-Operatoren zu verwenden, anstatt alle Zeilen zu lesen und den Maximalwert mit Brute Force zu berechnen. Was passiert, wenn wir etwas Ähnliches versuchen und die Abfrage explizit mit Top umschreiben?
SELECT TOP (1) c1 FROM dbo.V1 ORDER BY c1 DESC;
Der Ausführungsplan für die neue Abfrage lautet:
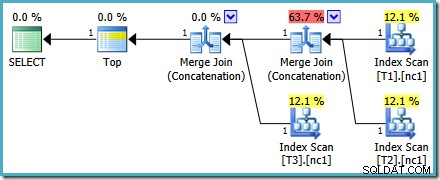
Dieser Plan unterscheidet sich deutlich von dem, den der Optimierer für MAX ausgewählt hat Anfrage. Es verfügt über drei geordnete Index-Scans, zwei im Verkettungsmodus ausgeführte Merge Joins und einen einzelnen Top-Operator. Dieser neue Abfrageplan hat einige interessante Funktionen, die es wert sind, ein wenig im Detail untersucht zu werden.
Plananalyse
Die erste Zeile (in absteigender Indexreihenfolge) wird aus dem Nonclustered-Index jeder Tabelle gelesen, und es wird ein Merge Join verwendet, der im Concatenation-Modus arbeitet. Obwohl der Merge-Join-Operator keinen Join im normalen Sinne durchführt, lässt sich der Verarbeitungsalgorithmus dieses Operators leicht anpassen, um seine Eingaben zu verketten, anstatt Join-Kriterien anzuwenden.
Der Vorteil der Verwendung dieses Operators im neuen Plan besteht darin, dass Merge Concatenation die Sortierreihenfolge über seine Eingaben hinweg beibehält. Im Gegensatz dazu liest ein regulärer Concatenation-Operator nacheinander aus seinen Eingaben. Das folgende Diagramm veranschaulicht den Unterschied (zum Erweitern klicken):
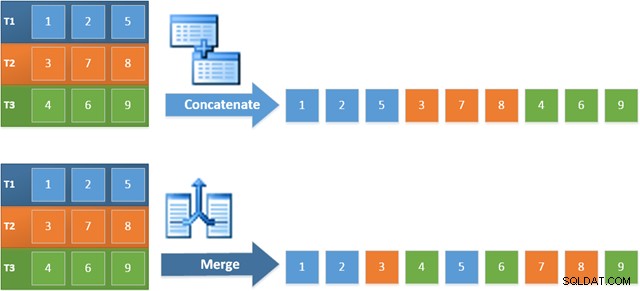
Das reihenfolgeerhaltende Verhalten von Merge Concatenation bedeutet, dass die erste Zeile, die vom Merge-Operator ganz links im neuen Plan erzeugt wird, garantiert die Zeile mit dem höchsten Wert in Spalte c1 in allen drei Tabellen ist. Genauer gesagt funktioniert der Plan wie folgt:
- Eine Zeile wird aus jeder Tabelle gelesen (in absteigender Indexreihenfolge); und
- Jede Zusammenführung führt einen Test durch um zu sehen, welche seiner Eingabezeilen den höheren Wert hat
Dies scheint eine sehr effiziente Strategie zu sein, daher mag es seltsam erscheinen, dass das MAX des Optimierers Plan hat geschätzte Kosten von weniger als der Hälfte des neuen Plans. Der Grund liegt größtenteils darin, dass davon ausgegangen wird, dass eine ordnungserhaltende Merge Concatenation teurer ist als eine einfache Concatenation. Der Optimierer erkennt nicht, dass jede Zusammenführung immer nur maximal eine Zeile sehen kann, und überschätzt daher seine Kosten.
Weitere Kostenprobleme
Genau genommen vergleichen wir hier nicht Äpfel mit Äpfeln, denn die beiden Pläne sind für unterschiedliche Abfragen. Ein solcher Kostenvergleich ist im Allgemeinen nicht zulässig, obwohl SSMS genau das tut, indem er Kostenprozentsätze für verschiedene Auszüge in einem Stapel anzeigt. Aber ich schweife ab.
Wenn Sie sich den neuen Plan in SSMS statt im SQL Sentry Plan Explorer ansehen, sehen Sie etwa Folgendes:
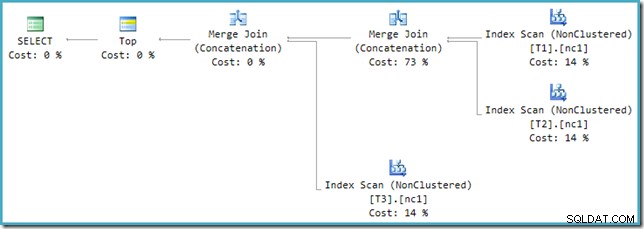
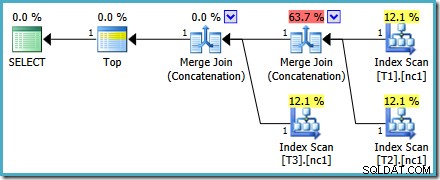
Einer der Merge Join Concatenation-Operatoren hat geschätzte Kosten von 73 %, während der zweite (der mit genau der gleichen Anzahl von Zeilen arbeitet) als überhaupt nichts kostet angezeigt wird. Ein weiteres Zeichen dafür, dass hier etwas nicht stimmt, ist, dass die Prozentsätze der Betreiberkosten in diesem Plan nicht 100 % ergeben.
Optimierer versus Ausführungsmodul
Das Problem liegt in einer Inkompatibilität zwischen dem Optimierer und der Ausführungsmaschine. Im Optimierer können Union und Union All zwei oder mehr Eingaben haben. In der Ausführungs-Engine kann nur der Concatenation-Operator 2 oder mehr akzeptieren Eingänge; Merge Join erfordert genau zwei Eingaben, auch wenn sie so konfiguriert sind, dass sie eine Verkettung statt einer Verknüpfung durchführen.
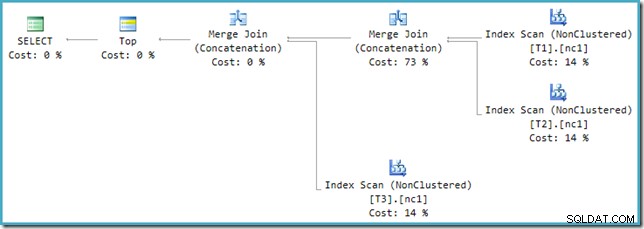
Um diese Inkompatibilität zu beheben, wird eine Neufassung nach der Optimierung angewendet, um den Ausgabebaum des Optimierers in eine Form zu übersetzen, die die Ausführungs-Engine handhaben kann. Wenn eine Union oder Union All mit mehr als zwei Eingaben mit Merge implementiert wird, ist eine Kette von Operatoren erforderlich. Bei drei Eingaben für Union All werden im vorliegenden Fall zwei Merge Unions benötigt:
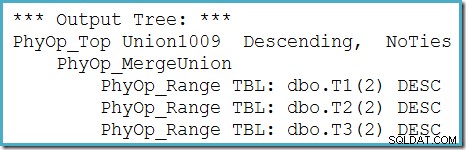
Wir können den Ausgabebaum des Optimierers (mit drei Eingaben für eine physische Zusammenführungsvereinigung) mithilfe des Ablaufverfolgungsflags 8607 sehen:
Ein unvollständiger Fix
Leider ist die Umschreibung nach der Optimierung nicht perfekt implementiert. Es macht ein bisschen ein Durcheinander von den Kostenzahlen. Abgesehen von Rundungsproblemen summieren sich die Plankosten auf 114 %, wobei die zusätzlichen 14 % aus der Eingabe für die zusätzliche Merge-Join-Verkettung stammen, die durch die Umschreibung generiert wird:
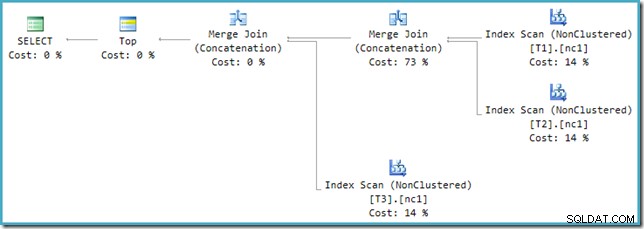
Die Zusammenführung ganz rechts in diesem Plan ist der ursprüngliche Operator im Ausgabebaum des Optimierers. Ihm werden die vollen Kosten der Operation Union All zugewiesen. Die andere Zusammenführung wird durch das Umschreiben hinzugefügt und erhält keine Kosten.
Unabhängig davon, wie wir es betrachten (und es gibt verschiedene Probleme, die sich auf die reguläre Verkettung auswirken), sehen die Zahlen seltsam aus. Plan Explorer tut sein Bestes, um die fehlerhaften Informationen im XML-Plan zu umgehen, indem er zumindest sicherstellt, dass die Summe der Zahlen 100 % ergibt:
Dieses spezielle Kostenproblem wurde in SQL Server 2014 CTP 1 behoben:
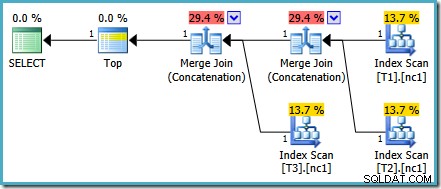
Die Kosten der Merge Concatenation werden nun gleichmäßig zwischen den beiden Betreibern aufgeteilt und die Prozentsätze addieren sich zu 100 %. Da das zugrunde liegende XML korrigiert wurde, kann SSMS auch dieselben Zahlen anzeigen.
Welcher Plan ist besser?
Wenn wir die Abfrage mit MAX schreiben , müssen wir uns darauf verlassen, dass der Optimierer die zusätzliche Arbeit übernimmt, die erforderlich ist, um einen effizienten Plan zu finden. Wenn der Optimierer früh einen scheinbar ausreichend guten Plan findet, kann er einen relativ ineffizienten Plan produzieren, der jede Zeile aus jeder der Basistabellen liest:
Wenn Sie SQL Server 2008 oder SQL Server 2008 R2 ausführen, wählt der Optimierer unabhängig von der Anzahl der Zeilen in den Basistabellen immer noch einen ineffizienten Plan aus. Der folgende Plan wurde auf SQL Server 2008 R2 mit 50.000 Zeilen erstellt:
Selbst mit 50 Millionen Zeilen in jeder Tabelle fügt der Optimierer von 2008 und 2008 R2 nur Parallelität hinzu, er führt nicht die Top-Operatoren ein:
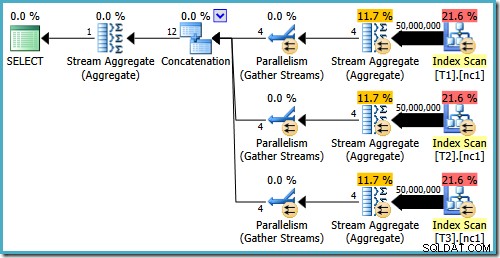
Wie in meinem vorherigen Beitrag erwähnt, ist das Ablaufverfolgungsflag 4199 erforderlich, damit SQL Server 2008 und 2008 R2 den Plan mit Top-Operatoren erstellen. Ab SQL Server 2005 und 2012 ist das Trace-Flag nicht erforderlich:
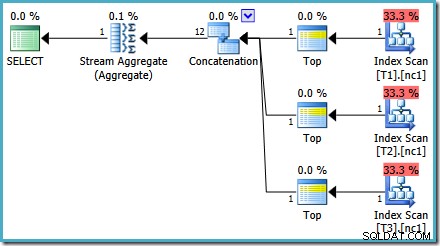
TOP mit ORDER BY
Sobald wir verstehen, was in den vorherigen Ausführungsplänen vor sich geht, können wir eine bewusste (und informierte) Entscheidung treffen, die Abfrage mit einem expliziten TOP mit ORDER BY:
neu zu schreibenSELECT TOP (1) c1 FROM dbo.V1 ORDER BY c1 DESC;
Der resultierende Ausführungsplan kann Kostenprozentsätze aufweisen, die in einigen Versionen von SQL Server seltsam aussehen, aber der zugrunde liegende Plan ist solide. Die Umschreibung nach der Optimierung, die dazu führt, dass die Zahlen ungerade aussehen, wird nach Abschluss der Abfrageoptimierung angewendet, sodass wir sicher sein können, dass die Planauswahl des Optimierers von diesem Problem nicht betroffen war.
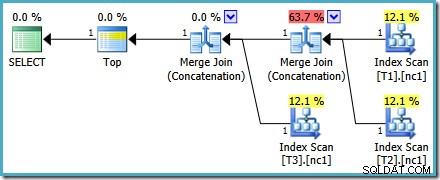
Dieser Plan ändert sich nicht in Abhängigkeit von der Anzahl der Zeilen in der Basistabelle und erfordert keine Generierung von Ablaufverfolgungsflags. Ein kleiner zusätzlicher Vorteil ist, dass dieser Plan vom Optimierer während der ersten Phase der kostenbasierten Optimierung (Suche 0) gefunden wird:
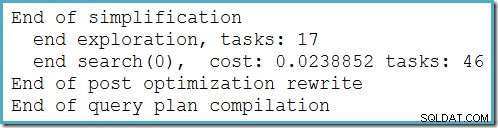
Der beste Plan, der vom Optimierer für MAX ausgewählt wurde Abfrage erforderlich, um zwei Phasen der kostenbasierten Optimierung auszuführen (Suche 0 und Suche 1).
Es gibt einen kleinen semantischen Unterschied zwischen TOP Abfrage und dem ursprünglichen MAX Form, die ich erwähnen sollte. Wenn keine der Tabellen eine Zeile enthält, würde die ursprüngliche Abfrage ein einzelnes NULL erzeugen Ergebnis. Der Ersatz TOP (1) query erzeugt unter den gleichen Umständen überhaupt keine Ausgabe. Dieser Unterschied ist in realen Abfragen oft nicht wichtig, aber man sollte sich dessen bewusst sein. Wir können das Verhalten von TOP replizieren mit MAX ab SQL Server 2008 durch Hinzufügen eines leeren Satzes GROUP BY :
SELECT MAX(c1) FROM dbo.V1 GROUP BY ();
Diese Änderung wirkt sich nicht auf die für MAX generierten Ausführungspläne aus Abfrage auf eine Weise, die für Endbenutzer sichtbar ist.
MAX mit Zusammenführungsverkettung
Angesichts des Erfolgs von Merge Join Concatenation im TOP (1) Ausführungsplan, stellt sich natürlich die Frage, ob derselbe optimale Plan auch für den ursprünglichen MAX generiert werden könnte Abfrage, ob wir den Optimierer zwingen, Merge Concatenation anstelle der regulären Concatenation für UNION ALL zu verwenden Betrieb.
Zu diesem Zweck gibt es einen Abfragehinweis – MERGE UNION – aber leider funktioniert es erst ab SQL Server 2012 korrekt. In früheren Versionen war die UNION Hinweis betrifft nur UNION Abfragen, nicht UNION ALL . Ab SQL Server 2012 können wir Folgendes versuchen:
SELECT MAX(c1) FROM dbo.V1 OPTION (MERGE UNION)
Wir werden mit einem Plan belohnt, der Merge Concatenation bietet. Leider ist es nicht ganz alles, was wir uns erhofft haben:
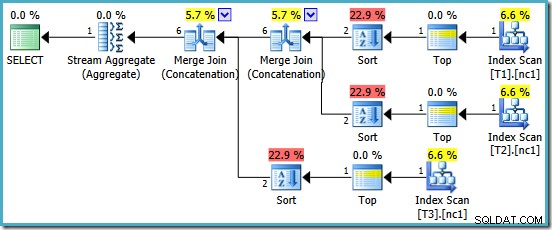
Die interessanten Operatoren in diesem Plan sind die Sorten. Beachten Sie die 1-Zeilen-Eingabekardinalitätsschätzung und die 4-Zeilen-Schätzung für die Ausgabe. Die Ursache sollte Ihnen inzwischen bekannt sein:Es handelt sich um den gleichen Schätzfehler der partiellen aggregierten Kardinalität, den wir bereits besprochen haben.
Das Vorhandensein der Sorten offenbart ein weiteres Problem mit den partiellen Aggregaten. Sie erzeugen nicht nur eine falsche Kardinalitätsschätzung, sie bewahren auch nicht die Indexreihenfolge, die eine Sortierung unnötig machen würde (Merge Concatenation erfordert sortierte Eingaben). Die partiellen Aggregate sind skalare MAX Aggregate, die garantiert eine Zeile erzeugen, also sollte die Frage der Reihenfolge sowieso strittig sein (es gibt nur eine Möglichkeit, eine Zeile zu sortieren!)
Das ist schade, denn ohne die Sorten wäre das ein anständiger Ausführungsplan. Wenn die partiellen Aggregate richtig implementiert wurden, und der MAX geschrieben mit einem GROUP BY () -Klausel, könnten wir sogar hoffen, dass der Optimierer erkennen könnte, dass die drei Tops und das abschließende Stream-Aggregat durch einen einzigen abschließenden Top-Operator ersetzt werden könnten, was genau den gleichen Plan wie das explizite TOP (1) ergibt Anfrage. Der Optimierer enthält diese Transformation heute nicht, und ich nehme nicht an, dass er oft genug nützlich wäre, um seine Einbeziehung in Zukunft lohnenswert zu machen.
Schlussworte
Mit TOP wird MIN nicht immer vorzuziehen sein oder MAX . In manchen Fällen führt dies zu einem deutlich weniger optimalen Plan. Der Punkt dieses Beitrags ist, dass das Verständnis der vom Optimierer angewendeten Transformationen Möglichkeiten zum Umschreiben der ursprünglichen Abfrage vorschlagen kann, die sich als hilfreich erweisen könnten.