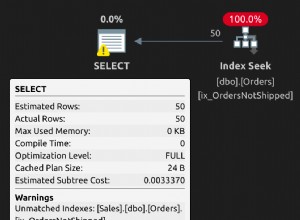
Diese Abfrage sollte sehr weit reichen (viel sein schneller):
WITH school AS (
SELECT s.osm_id AS school_id, text 'school' AS type, s.osm_id, s.name, s.way_geo
FROM planet_osm_point s
, LATERAL (
SELECT 1 FROM planet_osm_point
WHERE ST_DWithin(way_geo, s.way_geo, 500, false)
AND amenity = 'bar'
LIMIT 1 -- bar exists -- most selective first if possible
) b
, LATERAL (
SELECT 1 FROM planet_osm_point
WHERE ST_DWithin(way_geo, s.way_geo, 500, false)
AND amenity = 'restaurant'
LIMIT 1 -- restaurant exists
) r
WHERE s.amenity = 'school'
)
SELECT * FROM (
TABLE school -- schools
UNION ALL -- bars
SELECT s.school_id, 'bar', x.*
FROM school s
, LATERAL (
SELECT osm_id, name, way_geo
FROM planet_osm_point
WHERE ST_DWithin(way_geo, s.way_geo, 500, false)
AND amenity = 'bar'
) x
UNION ALL -- restaurants
SELECT s.school_id, 'rest.', x.*
FROM school s
, LATERAL (
SELECT osm_id, name, way_geo
FROM planet_osm_point
WHERE ST_DWithin(way_geo, s.way_geo, 500, false)
AND amenity = 'restaurant'
) x
) sub
ORDER BY school_id, (type <> 'school'), type, osm_id;
Dies ist nicht das gleiche wie Ihre ursprüngliche Abfrage, aber eher das, was Sie tatsächlich wollen, wie in den Kommentaren diskutiert :
Diese Abfrage gibt also eine Liste dieser Schulen zurück, gefolgt von Bars und Restaurants in der Nähe. Jeder Zeilensatz wird durch die osm_id zusammengehalten der Schule in der Spalte school_id .
Jetzt mit LATERAL Joins, um den räumlichen GiST-Index zu nutzen.
TABLE school ist nur eine Abkürzung für SELECT * FROM school :
Der Ausdruck (type <> 'school') ordnet die Schule in jedem Satz zuerst an, weil:
Die Unterabfrage sub im abschließenden SELECT wird nur benötigt, um nach diesem Ausdruck zu ordnen. Eine UNION Abfrage schränkt einen angehängten ORDER BY ein listet nur Spalten auf, keine Ausdrücke.
Ich konzentriere mich auf die Frage, die Sie für den Zweck dieser Antwort gestellt haben - Ignorieren die erweiterte Anforderung, nach einer der anderen 70 Textspalten zu filtern. Das ist wirklich ein Konstruktionsfehler. Die Suchkriterien sollten auf wenige konzentriert werden Säulen. Oder Sie müssen alle 70 Spalten indizieren, und mehrspaltige Indizes, wie ich sie vorschlagen werde, sind kaum eine Option. Immer noch möglich obwohl ...
Index
Zusätzlich zu den bestehenden:
"idx_planet_osm_point_waygeo" gist (way_geo)
Wenn Sie immer nach derselben Spalte filtern, können Sie einen erstellen mehrspaltiger Index die wenigen Spalten abdecken, an denen Sie interessiert sind, also index- scannt nur möglich werden:
CREATE INDEX planet_osm_point_bar_idx ON planet_osm_point (amenity, name, osm_id)
Postgres 9.5
Das kommende Postgres 9.5 führt wichtige Verbesserungen ein die zufällig genau Ihren Fall ansprechen:
Das ist für Sie besonders interessant. Jetzt können Sie eine Single haben mehrspaltiger (überdeckender) GiST-Index:
CREATE INDEX reservations_range_idx ON reservations
USING gist(amenity, way_geo, name, osm_id)
Und:
Und:
Wieso den? Weil ROLLUP
würde die von mir vorgeschlagene Abfrage vereinfachen. Zugehörige Antwort:
Die erste Alpha-Version wurde am 2. Juli 2015 veröffentlicht. Der erwartete Zeitplan für die Veröffentlichung:
Grundlagen
Achten Sie natürlich darauf, die Grundlagen nicht zu übersehen: