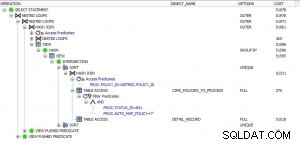
Tabellenpartitionierung hilft überhaupt nicht .
Aber ja, es gibt einen guten Weg:Upgrade auf eine aktuelle Version von Postgres. Es gab viele Verbesserungen für GiST-Indizes, insbesondere für das pg_trgm-Modul und für Big Data im Allgemeinen. Sollte mit Postgres 10 wesentlich schneller sein.
Ihre Suche nach "nächster Nachbar" sieht bis auf ein kleines LIMIT korrekt aus Verwenden Sie stattdessen diese äquivalente Abfrage:
SELECT address, similarity(address, '981 maun st') AS sml
FROM addresses
WHERE address % '981 maun st'
ORDER BY address <-> '981 maun st'
LIMIT 10;