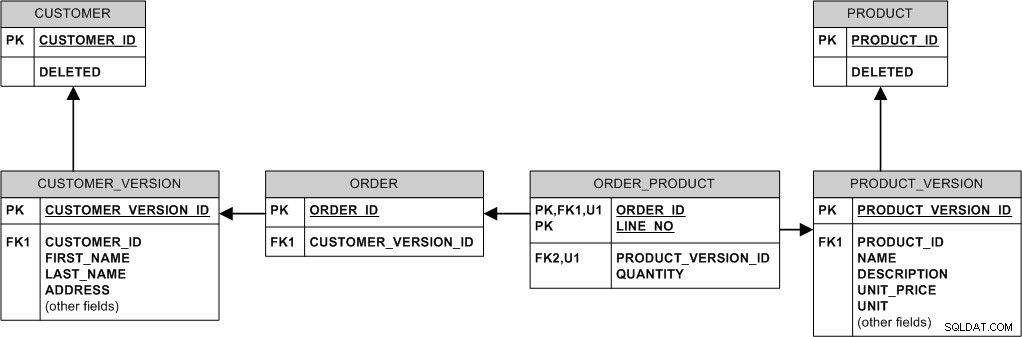
Hier ist eine Möglichkeit, dies zu tun:
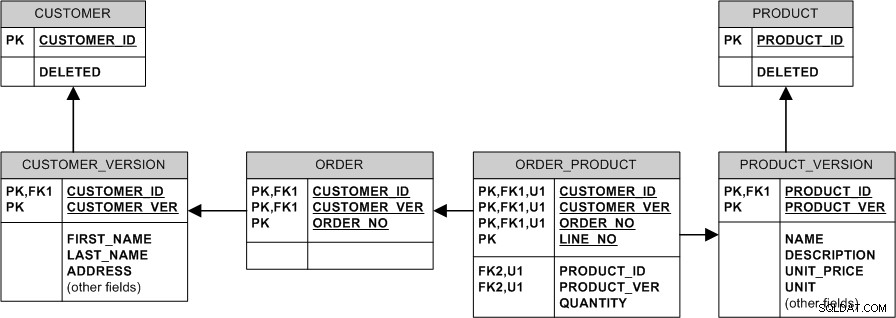
Grundsätzlich ändern oder löschen wir niemals die vorhandenen Daten. Wir "modifizieren" es, indem wir eine neue Version erstellen. Wir "löschen" es, indem wir das DELETED-Flag setzen.
Zum Beispiel:
- Wenn das Produkt den Preis ändert, fügen wir eine neue Zeile in PRODUCT_VERSION ein, während alte Bestellungen mit der alten PRODUCT_VERSION und dem alten Preis verbunden bleiben.
- Wenn der Käufer die Adresse ändert, fügen wir einfach eine neue Zeile in CUSTOMER_VERSION ein und verknüpfen neue Bestellungen damit, während die alten Bestellungen mit der alten Version verknüpft bleiben.
- Wenn ein Produkt gelöscht wird, löschen wir es nicht wirklich – wir setzen einfach das Flag PRODUCT.DELETED, sodass alle Bestellungen, die in der Vergangenheit für dieses Produkt getätigt wurden, in der Datenbank bleiben.
- Wenn der Kunde gelöscht wird (z. B. weil er darum gebeten hat, abgemeldet zu werden), setzen Sie das CUSTOMER.DELETED-Flag.
Vorbehalte:
- Wenn der Produktname eindeutig sein muss, kann dies im obigen Modell nicht deklarativ erzwungen werden. Sie müssen entweder den NAMEN von PRODUCT_VERSION zu PRODUCT „befördern“, ihn dort zu einem Schlüssel machen und die Fähigkeit zur „Entwicklung“ des Produktnamens aufgeben oder die Eindeutigkeit nur für das neueste PRODUCT_VER erzwingen (wahrscheinlich durch Trigger).
- Es besteht ein potenzielles Problem mit der Privatsphäre des Kunden. Wenn ein Kunde aus dem System gelöscht wird, kann es wünschenswert sein, seine Daten physisch aus der Datenbank zu entfernen, und das einfache Festlegen von CUSTOMER.DELETED wird dies nicht tun. Wenn dies ein Problem darstellt, blenden Sie entweder die datenschutzrelevanten Daten in allen Versionen des Kunden aus oder trennen Sie alternativ bestehende Bestellungen vom echten Kunden und verbinden Sie sie erneut mit einem speziellen "anonymen" Kunden und löschen Sie dann physisch alle Kundenversionen.
Dieses Modell verwendet viele identifizierende Beziehungen. Dies führt zu "fetten" Fremdschlüsseln und könnte ein kleines Speicherproblem darstellen, da MySQL keine führende Indexkomprimierung unterstützt (anders als beispielsweise Oracle), aber andererseits InnoDB immer Clustert die Daten auf PK und dieses Clustering kann sich positiv auf die Leistung auswirken. Außerdem sind JOINs weniger notwendig.
Ein äquivalentes Modell mit nicht identifizierenden Beziehungen und Ersatzschlüsseln würde so aussehen: