Ich würde etwas Ähnliches vorschlagen wie e4c5 vorgeschlagen , aber ich würde auch:
-
Generieren Sie einen Index zum Datum der Ränge, damit das Erhalten aller Ränge an einem einzelnen Tag optimiert werden kann.
-
Markieren Sie das Datum und den Schüler als
unique_together. Dadurch wird verhindert, dass am selben Datum zwei Ränge für denselben Schüler erfasst werden.
Die Modelle würden wie folgt aussehen:
from django.db import models
class Grade(models.Model):
pass # Whatever you need here...
class Student(models.Model):
name = models.CharField(max_length=20)
grade = models.ForeignKey(Grade)
class Rank(models.Model):
class Meta(object):
unique_together = (("date", "student"), )
date = models.DateField(db_index=True)
student = models.ForeignKey(Student)
value = models.IntegerField()
In einer vollwertigen Anwendung würde ich auch einige Eindeutigkeitsbeschränkungen für Grade erwarten und Student aber das in der Frage dargestellte Problem liefert nicht genügend Details zu diesen Modellen.
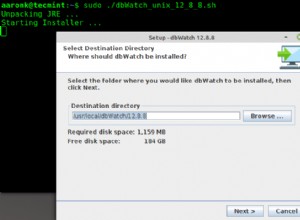
Sie könnten dann jeden Tag eine Aufgabe mit cron ausführen oder welchen Task-Manager Sie verwenden möchten (Sellerie ist auch eine Option), um einen Befehl wie den folgenden auszuführen, der die Ränge gemäß einer Berechnung aktualisiert und die alten Datensätze löscht. Der folgende Code ist eine Illustration wie es gemacht werden kann. Der eigentliche Code sollte so konzipiert sein, dass er im Allgemeinen idempotent ist (der folgende Code ist nicht, weil die Rangberechnung zufällig ist), sodass der Befehl einfach erneut ausgeführt werden kann, wenn der Server mitten in einem Update neu gestartet wird. Hier ist der Code:
import random
import datetime
from optparse import make_option
from django.utils.timezone import utc
from django.core.management.base import BaseCommand
from school.models import Rank, Student
def utcnow():
return datetime.datetime.utcnow().replace(tzinfo=utc)
class Command(BaseCommand):
help = "Compute ranks and cull the old ones"
option_list = BaseCommand.option_list + (
make_option('--fake-now',
default=None,
help='Fake the now value to X days ago.'),
)
def handle(self, *args, **options):
now = utcnow()
fake_now = options["fake_now"]
if fake_now is not None:
now -= datetime.timedelta(days=int(fake_now))
print "Setting now to: ", now
for student in Student.objects.all():
# This simulates a rank computation for the purpose of
# illustration.
rank_value = random.randint(1, 1000)
try:
rank = Rank.objects.get(student=student, date=now)
except Rank.DoesNotExist:
rank = Rank(
student=student, date=now)
rank.value = rank_value
rank.save()
# Delete all ranks older than 180 days.
Rank.objects.filter(
date__lt=now - datetime.timedelta(days=180)).delete()
Warum nicht Essiggurken?
Mehrere Gründe:
-
Es ist eine verfrühte Optimierung und insgesamt wahrscheinlich überhaupt keine Optimierung. Einige Operationen können schneller sein, aber andere Operationen wird langsamer. Wenn die Ränge in ein Feld auf
Studenteingelegt werden dann bedeutet das Laden eines bestimmten Schülers in den Speicher, dass alle Ranginformationen zusammen mit diesem Schüler in den Speicher geladen werden. Dies kann durch die Verwendung von.values()abgemildert werden oder.values_list()aber dann bekommst duStudentnicht mehr Instanzen aus der Datenbank. WarumStudenthaben Instanzen und nicht nur auf die Rohdatenbank zugreifen? -
Wenn ich die Felder in
Rankändere , ermöglichen die Migrationsfunktionen von Django problemlos die Durchführung der erforderlichen Änderungen, wenn ich die neue Version meiner Anwendung bereitstelle. Wenn die Ranginformationen in ein Feld eingelegt werden, muss ich jede Strukturänderung verwalten, indem ich benutzerdefinierten Code schreibe. -
Die Datenbanksoftware kann nicht auf Werte in einer Gurke zugreifen, daher müssen Sie benutzerdefinierten Code schreiben, um darauf zuzugreifen. Wenn Sie mit dem obigen Modell Schüler nach heutigem Rang auflisten möchten (und die Ränge für heute bereits berechnet wurden), können Sie Folgendes tun:
for r in Rank.objects.filter(date=utcnow()).order_by("value")\ .prefetch_related(): print r.student.nameWenn Sie Gurken verwenden, müssen Sie alle
Studentscannen und heben Sie die Ränge auf, um den für den gewünschten Tag zu extrahieren, und verwenden Sie dann eine Python-Datenstruktur, um die Schüler nach Rang zu ordnen. Sobald dies erledigt ist, müssen Sie diese Struktur durchlaufen, um die Namen in die richtige Reihenfolge zu bringen.