Python und SQL sind zwei der wichtigsten Sprachen für Datenanalysten.
In diesem Artikel werde ich Sie durch alles führen, was Sie wissen müssen, um Python und SQL zu verbinden.
Sie erfahren, wie Sie Daten aus relationalen Datenbanken direkt in Ihre Pipelines für maschinelles Lernen ziehen, Daten aus Ihrer Python-Anwendung in einer eigenen Datenbank speichern oder was auch immer Ihnen sonst noch ein Anwendungsfall einfällt.
Gemeinsam werden wir Folgendes abdecken:
- Warum lernen, wie man Python und SQL zusammen verwendet?
- So richten Sie Ihre Python-Umgebung und Ihren MySQL-Server ein
- Verbindung zum MySQL-Server in Python herstellen
- Erstellen einer neuen Datenbank
- Erstellen von Tabellen und Tabellenbeziehungen
- Tabellen mit Daten füllen
- Daten lesen
- Aktualisieren von Datensätzen
- Datensätze löschen
- Erstellen von Datensätzen aus Python-Listen
- Wiederverwendbare Funktionen erstellen, um all dies in Zukunft für uns zu erledigen
Das ist eine Menge sehr nützlicher und sehr cooler Sachen. Fangen wir an!
Eine kurze Anmerkung, bevor wir beginnen:In diesem GitHub-Repository ist ein Jupyter-Notebook verfügbar, das den gesamten in diesem Tutorial verwendeten Code enthält. Mitcodieren wird dringend empfohlen!
Die Datenbank und der SQL-Code, die hier verwendet werden, stammen alle aus meiner vorherigen Reihe „Einführung in SQL“, die auf Towards Data Science veröffentlicht wurde (kontaktieren Sie mich, wenn Sie Probleme beim Anzeigen der Artikel haben, und ich kann Ihnen einen Link senden, um sie kostenlos anzuzeigen).
Wenn Sie mit SQL und den Konzepten hinter relationalen Datenbanken nicht vertraut sind, würde ich Sie auf diese Serie verweisen (außerdem gibt es hier auf freeCodeCamp natürlich eine Menge toller Sachen!)
Warum Python mit SQL?
Für Datenanalysten und Datenwissenschaftler hat Python viele Vorteile. Eine große Auswahl an Open-Source-Bibliotheken machen es zu einem unglaublich nützlichen Tool für jeden Datenanalysten.
Wir haben Pandas, NumPy und Vaex für die Datenanalyse, Matplotlib, Seaborn und Bokeh für die Visualisierung und TensorFlow, scikit-learn und PyTorch für maschinelle Lernanwendungen (und viele, viele mehr).
Mit seiner (relativ) einfachen Lernkurve und Vielseitigkeit ist es kein Wunder, dass Python eine der am schnellsten wachsenden Programmiersprachen ist.
Wenn wir also Python für die Datenanalyse verwenden, lohnt es sich zu fragen:Woher kommen all diese Daten?
Obwohl es eine große Vielfalt an Quellen für Datensätze gibt, werden Daten in vielen Fällen – insbesondere in Unternehmen – in einer relationalen Datenbank gespeichert. Relationale Datenbanken sind eine äußerst effiziente, leistungsstarke und weit verbreitete Möglichkeit, Daten aller Art zu erstellen, zu lesen, zu aktualisieren und zu löschen.
Die am weitesten verbreiteten Managementsysteme für relationale Datenbanken (RDBMS) – Oracle, MySQL, Microsoft SQL Server, PostgreSQL, IBM DB2 – verwenden alle die Structured Query Language (SQL), um auf die Daten zuzugreifen und Änderungen daran vorzunehmen.
Beachten Sie, dass jedes RDBMS eine etwas andere Variante von SQL verwendet, sodass SQL-Code, der für eines geschrieben wurde, normalerweise nicht ohne (normalerweise ziemlich geringfügige) Änderungen in einem anderen funktioniert. Die Konzepte, Strukturen und Abläufe sind jedoch weitgehend identisch.
Für einen arbeitenden Datenanalysten bedeutet dies, dass ein starkes Verständnis von SQL von enormer Bedeutung ist. Zu wissen, wie man Python und SQL zusammen verwendet, verschafft Ihnen einen noch größeren Vorteil bei der Arbeit mit Ihren Daten.
Der Rest dieses Artikels wird Ihnen genau zeigen, wie wir das tun können.
Erste Schritte
Anforderungen &Installation
Um zusammen mit diesem Tutorial zu programmieren, müssen Sie Ihre eigene Python-Umgebung einrichten.
Ich verwende Anaconda, aber es gibt viele Möglichkeiten, dies zu tun. Wenn Sie weitere Hilfe benötigen, googlen Sie einfach nach "How to install Python". Sie können Binder auch zum Codieren zusammen mit dem zugehörigen Jupyter Notebook verwenden.
Wir werden den MySQL Community Server verwenden, da er kostenlos ist und in der Branche weit verbreitet ist. Wenn Sie Windows verwenden, hilft Ihnen diese Anleitung bei der Einrichtung. Hier sind auch Anleitungen für Mac- und Linux-Benutzer (obwohl sie je nach Linux-Distribution variieren können).
Sobald Sie diese eingerichtet haben, müssen wir sie dazu bringen, miteinander zu kommunizieren.
Dazu müssen wir die MySQL Connector Python-Bibliothek installieren. Folgen Sie dazu den Anweisungen oder verwenden Sie einfach pip:
pip install mysql-connector-pythonWir werden auch Pandas verwenden, stellen Sie also sicher, dass Sie das auch installiert haben.
pip install pandasBibliotheken importieren
Wie bei jedem Projekt in Python wollen wir als allererstes unsere Bibliotheken importieren.
Es empfiehlt sich, alle Bibliotheken, die wir verwenden werden, zu Beginn des Projekts zu importieren, damit die Leute, die unseren Code lesen oder überprüfen, ungefähr wissen, was auf sie zukommt, damit es keine Überraschungen gibt.
Für dieses Tutorial werden wir nur zwei Bibliotheken verwenden - MySQL Connector und pandas.
import mysql.connector
from mysql.connector import Error
import pandas as pdWir importieren die Error-Funktion separat, damit wir für unsere Funktionen einfachen Zugriff darauf haben.
Verbinden mit MySQL Server
Zu diesem Zeitpunkt sollten wir MySQL Community Server auf unserem System eingerichtet haben. Jetzt müssen wir Code in Python schreiben, mit dem wir eine Verbindung zu diesem Server herstellen können.
def create_server_connection(host_name, user_name, user_password):
connection = None
try:
connection = mysql.connector.connect(
host=host_name,
user=user_name,
passwd=user_password
)
print("MySQL Database connection successful")
except Error as err:
print(f"Error: '{err}'")
return connectionDas Erstellen einer wiederverwendbaren Funktion für solchen Code ist Best Practice, damit wir diese mit minimalem Aufwand immer wieder verwenden können. Sobald dies einmal geschrieben ist, können Sie es auch in Zukunft in all Ihren Projekten wiederverwenden, also werden Sie in Zukunft dankbar sein!
Lassen Sie uns das Zeile für Zeile durchgehen, damit wir verstehen, was hier passiert:
In der ersten Zeile benennen wir die Funktion (create_server_connection) und die Argumente, die diese Funktion annehmen wird (host_name, user_name und user_password).
Die nächste Zeile schließt alle bestehenden Verbindungen, damit der Server nicht durch mehrere offene Verbindungen verwirrt wird.
Als Nächstes verwenden wir einen Python-Try-Except-Block, um potenzielle Fehler zu behandeln. Der erste Teil versucht, mithilfe der Methode mysql.connector.connect() eine Verbindung zum Server herzustellen, wobei die vom Benutzer in den Argumenten angegebenen Details verwendet werden. Wenn dies funktioniert, druckt die Funktion eine fröhliche kleine Erfolgsmeldung.
Der except-Teil des Blocks gibt den Fehler aus, den MySQL Server in dem unglücklichen Fall zurückgibt, dass ein Fehler vorliegt.
Wenn die Verbindung schließlich erfolgreich ist, gibt die Funktion ein Verbindungsobjekt zurück.
Wir nutzen dies in der Praxis, indem wir den Ausgang der Funktion einer Variablen zuweisen, die dann zu unserem Verbindungsobjekt wird. Wir können dann andere Methoden (z. B. Cursor) darauf anwenden und andere nützliche Objekte erstellen.
connection = create_server_connection("localhost", "root", pw)Dies sollte eine Erfolgsmeldung erzeugen:

Erstellen einer neuen Datenbank
Nachdem wir nun eine Verbindung hergestellt haben, besteht unser nächster Schritt darin, eine neue Datenbank auf unserem Server zu erstellen.
In diesem Tutorial werden wir dies nur einmal tun, aber wir werden dies wieder als wiederverwendbare Funktion schreiben, damit wir eine nette nützliche Funktion haben, die wir für zukünftige Projekte wiederverwenden können.
def create_database(connection, query):
cursor = connection.cursor()
try:
cursor.execute(query)
print("Database created successfully")
except Error as err:
print(f"Error: '{err}'")Diese Funktion benötigt zwei Argumente, connection (unser Verbindungsobjekt) und query (eine SQL-Abfrage, die wir im nächsten Schritt schreiben werden). Es führt die Abfrage im Server über die Verbindung aus.
Wir verwenden die Cursor-Methode für unser Verbindungsobjekt, um ein Cursor-Objekt zu erstellen (MySQL Connector verwendet ein objektorientiertes Programmierparadigma, daher gibt es viele Objekte, die Eigenschaften von übergeordneten Objekten erben).
Dieses Cursorobjekt hat Methoden wie execute, executemany (die wir in diesem Tutorial verwenden werden) zusammen mit mehreren anderen nützlichen Methoden.
Wenn es hilft, können wir uns das Cursor-Objekt so vorstellen, dass es uns Zugriff auf den blinkenden Cursor in einem MySQL-Server-Terminalfenster gewährt.
Als nächstes definieren wir eine Abfrage zum Erstellen der Datenbank und rufen die Funktion auf:

Alle in diesem Tutorial verwendeten SQL-Abfragen werden in meiner Einführung in die SQL-Tutorialreihe erläutert, und der vollständige Code ist im zugehörigen Jupyter Notebook in diesem GitHub-Repository zu finden, daher werde ich hier keine Erklärungen dazu geben, was der SQL-Code tut Anleitung.
Dies ist jedoch vielleicht die einfachste mögliche SQL-Abfrage. Wenn Sie Englisch lesen können, können Sie wahrscheinlich herausfinden, was es tut!
Das Ausführen der create_database-Funktion mit den obigen Argumenten führt dazu, dass eine Datenbank namens „school“ auf unserem Server erstellt wird.
Warum heißt unsere Datenbank „Schule“? Vielleicht wäre jetzt ein guter Zeitpunkt, sich genauer anzusehen, was wir in diesem Tutorial implementieren werden.
Unsere Datenbank
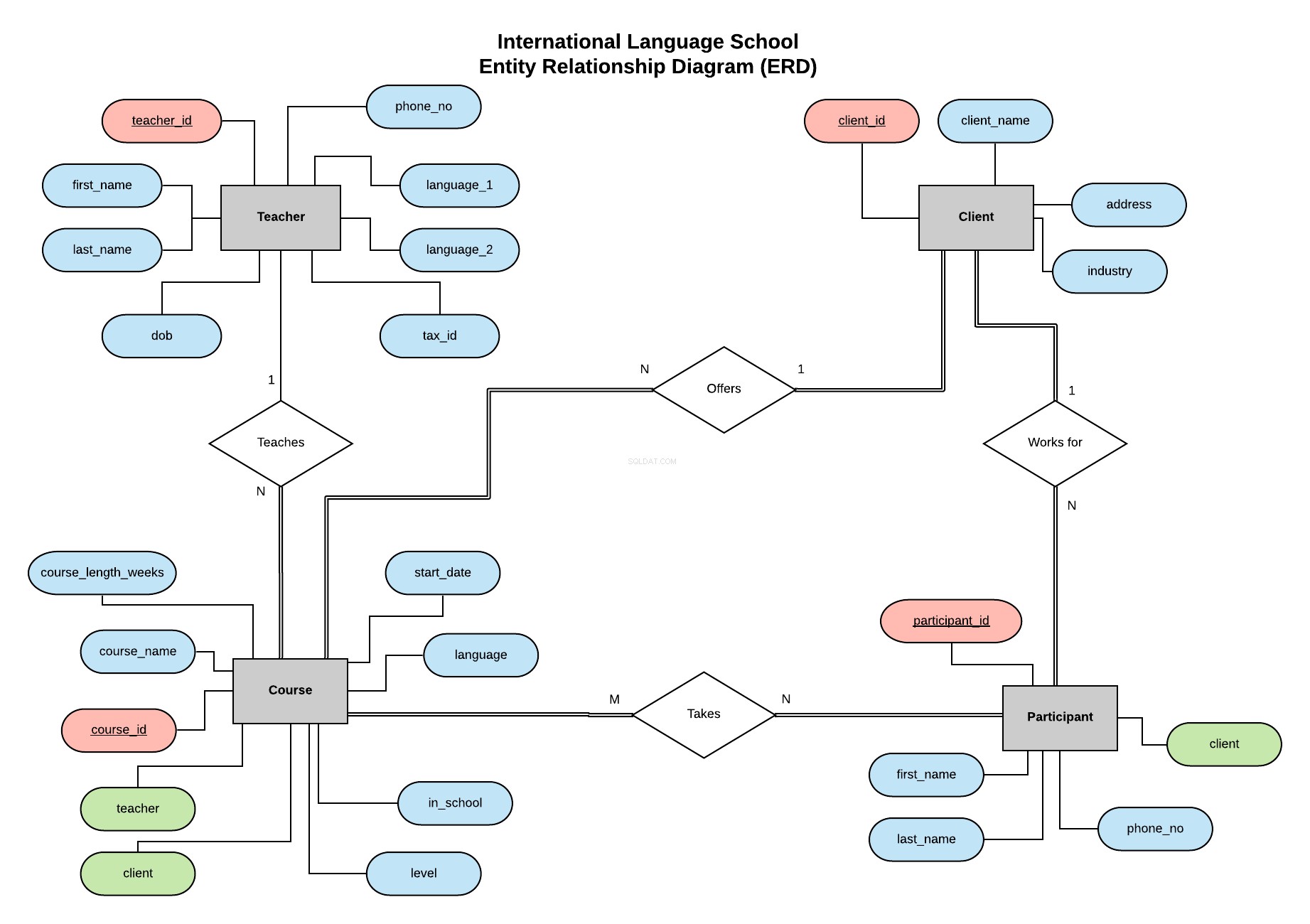
Nach dem Vorbild meiner vorherigen Serie werden wir die Datenbank für die International Language School implementieren – eine fiktive Sprachschule, die professionellen Sprachunterricht für Firmenkunden anbietet.
Dieses Entitätsbeziehungsdiagramm (ERD) legt unsere Entitäten (Lehrer, Kunde, Kurs und Teilnehmer) dar und definiert die Beziehungen zwischen ihnen.
Alle Informationen darüber, was ein ERD ist und was bei der Erstellung und Gestaltung einer Datenbank zu beachten ist, finden Sie in diesem Artikel.
Der rohe SQL-Code, die Datenbankanforderungen und die Daten, die in die Datenbank aufgenommen werden sollen, sind alle in diesem GitHub-Repository enthalten, aber Sie werden auch alles sehen, wenn wir dieses Tutorial durchgehen.
Verbindung zur Datenbank herstellen
Nachdem wir nun eine Datenbank in MySQL Server erstellt haben, können wir unsere Funktion create_server_connection ändern, um eine direkte Verbindung zu dieser Datenbank herzustellen.
Beachten Sie, dass es möglich ist – tatsächlich üblich –, mehrere Datenbanken auf einem MySQL-Server zu haben, also möchten wir uns immer und automatisch mit der Datenbank verbinden, an der wir interessiert sind.
Wir können das so machen:
def create_db_connection(host_name, user_name, user_password, db_name):
connection = None
try:
connection = mysql.connector.connect(
host=host_name,
user=user_name,
passwd=user_password,
database=db_name
)
print("MySQL Database connection successful")
except Error as err:
print(f"Error: '{err}'")
return connectionDies ist genau die gleiche Funktion, aber jetzt nehmen wir ein weiteres Argument – den Datenbanknamen – und übergeben es als Argument an die connect()-Methode.
Erstellen einer Abfrageausführungsfunktion
Die letzte Funktion, die wir (vorerst) erstellen werden, ist äußerst wichtig – eine Abfrageausführungsfunktion. Dies nimmt unsere SQL-Abfragen, die in Python als Zeichenfolgen gespeichert sind, und übergibt sie an die Methode cursor.execute(), um sie auf dem Server auszuführen.
def execute_query(connection, query):
cursor = connection.cursor()
try:
cursor.execute(query)
connection.commit()
print("Query successful")
except Error as err:
print(f"Error: '{err}'")Diese Funktion ist genau die gleiche wie unsere create_database-Funktion von früher, außer dass sie die Methode connection.commit() verwendet, um sicherzustellen, dass die in unseren SQL-Abfragen beschriebenen Befehle implementiert werden.
Dies wird unsere Arbeitstierfunktion sein, die wir (zusammen mit create_db_connection) verwenden werden, um Tabellen zu erstellen, Beziehungen zwischen diesen Tabellen herzustellen, die Tabellen mit Daten zu füllen und Datensätze in unserer Datenbank zu aktualisieren und zu löschen.
Wenn Sie ein SQL-Experte sind, können Sie mit dieser Funktion alle komplexen Befehle und Abfragen, die Sie möglicherweise herumliegen haben, direkt aus einem Python-Skript ausführen. Dies kann ein sehr leistungsfähiges Tool zur Verwaltung Ihrer Daten sein.
Tabellen erstellen
Jetzt sind wir bereit, SQL-Befehle auf unserem Server auszuführen und mit dem Aufbau unserer Datenbank zu beginnen. Als erstes wollen wir die notwendigen Tabellen erstellen.
Beginnen wir mit unserer Teacher-Tabelle:
create_teacher_table = """
CREATE TABLE teacher (
teacher_id INT PRIMARY KEY,
first_name VARCHAR(40) NOT NULL,
last_name VARCHAR(40) NOT NULL,
language_1 VARCHAR(3) NOT NULL,
language_2 VARCHAR(3),
dob DATE,
tax_id INT UNIQUE,
phone_no VARCHAR(20)
);
"""
connection = create_db_connection("localhost", "root", pw, db) # Connect to the Database
execute_query(connection, create_teacher_table) # Execute our defined queryZunächst weisen wir unseren hier ausführlich erklärten SQL-Befehl einer Variablen mit passendem Namen zu.
In diesem Fall verwenden wir die dreifache Anführungszeichennotation von Python für mehrzeilige Zeichenfolgen, um unsere SQL-Abfrage zu speichern, und geben sie dann in unsere execute_query-Funktion ein, um sie zu implementieren.
Beachten Sie, dass diese mehrzeilige Formatierung ausschließlich zum Nutzen der Menschen dient, die unseren Code lesen. Weder SQL noch Python 'kümmert' sich darum, ob der SQL-Befehl so verteilt ist. Solange die Syntax korrekt ist, werden beide Sprachen sie akzeptieren.
Zum Wohle der Menschen, die Ihren Code lesen werden (auch wenn das nur Sie in der Zukunft sein werden!), ist es jedoch sehr nützlich, dies zu tun, um den Code lesbarer und verständlicher zu machen.
Das gleiche gilt für die GROSSBUCHSTABEN von Operatoren in SQL. Dies ist eine weit verbreitete Konvention, die dringend empfohlen wird, aber die tatsächliche Software, die den Code ausführt, unterscheidet nicht zwischen Groß- und Kleinschreibung und behandelt „CREATE TABLE Teacher“ und „Create Table Teacher“ als identische Befehle.

Das Ausführen dieses Codes gibt uns unsere Erfolgsmeldungen. Wir können dies auch im MySQL Server Command Line Client überprüfen:
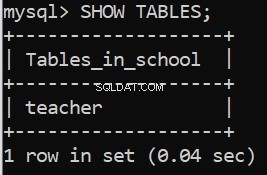
Toll! Lassen Sie uns nun die verbleibenden Tabellen erstellen.
create_client_table = """
CREATE TABLE client (
client_id INT PRIMARY KEY,
client_name VARCHAR(40) NOT NULL,
address VARCHAR(60) NOT NULL,
industry VARCHAR(20)
);
"""
create_participant_table = """
CREATE TABLE participant (
participant_id INT PRIMARY KEY,
first_name VARCHAR(40) NOT NULL,
last_name VARCHAR(40) NOT NULL,
phone_no VARCHAR(20),
client INT
);
"""
create_course_table = """
CREATE TABLE course (
course_id INT PRIMARY KEY,
course_name VARCHAR(40) NOT NULL,
language VARCHAR(3) NOT NULL,
level VARCHAR(2),
course_length_weeks INT,
start_date DATE,
in_school BOOLEAN,
teacher INT,
client INT
);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, create_client_table)
execute_query(connection, create_participant_table)
execute_query(connection, create_course_table)Dadurch werden die vier Tabellen erstellt, die für unsere vier Entitäten erforderlich sind.
Jetzt wollen wir die Beziehungen zwischen ihnen definieren und eine weitere Tabelle erstellen, um die Viele-zu-Viele-Beziehung zwischen den Teilnehmer- und Kurstabellen zu handhaben (siehe hier für weitere Details).
Wir machen das genau so:
alter_participant = """
ALTER TABLE participant
ADD FOREIGN KEY(client)
REFERENCES client(client_id)
ON DELETE SET NULL;
"""
alter_course = """
ALTER TABLE course
ADD FOREIGN KEY(teacher)
REFERENCES teacher(teacher_id)
ON DELETE SET NULL;
"""
alter_course_again = """
ALTER TABLE course
ADD FOREIGN KEY(client)
REFERENCES client(client_id)
ON DELETE SET NULL;
"""
create_takescourse_table = """
CREATE TABLE takes_course (
participant_id INT,
course_id INT,
PRIMARY KEY(participant_id, course_id),
FOREIGN KEY(participant_id) REFERENCES participant(participant_id) ON DELETE CASCADE,
FOREIGN KEY(course_id) REFERENCES course(course_id) ON DELETE CASCADE
);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, alter_participant)
execute_query(connection, alter_course)
execute_query(connection, alter_course_again)
execute_query(connection, create_takescourse_table)Jetzt werden unsere Tabellen zusammen mit den entsprechenden Einschränkungen, Primärschlüssel- und Fremdschlüsselbeziehungen erstellt.
Befüllen der Tabellen
Der nächste Schritt besteht darin, den Tabellen einige Datensätze hinzuzufügen. Wieder verwenden wir execute_query, um unsere vorhandenen SQL-Befehle in den Server einzuspeisen. Beginnen wir wieder mit der Teacher-Tabelle.
pop_teacher = """
INSERT INTO teacher VALUES
(1, 'James', 'Smith', 'ENG', NULL, '1985-04-20', 12345, '+491774553676'),
(2, 'Stefanie', 'Martin', 'FRA', NULL, '1970-02-17', 23456, '+491234567890'),
(3, 'Steve', 'Wang', 'MAN', 'ENG', '1990-11-12', 34567, '+447840921333'),
(4, 'Friederike', 'Müller-Rossi', 'DEU', 'ITA', '1987-07-07', 45678, '+492345678901'),
(5, 'Isobel', 'Ivanova', 'RUS', 'ENG', '1963-05-30', 56789, '+491772635467'),
(6, 'Niamh', 'Murphy', 'ENG', 'IRI', '1995-09-08', 67890, '+491231231232');
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, pop_teacher)Funktioniert das? Wir können in unserem MySQL-Befehlszeilenclient erneut nachsehen:
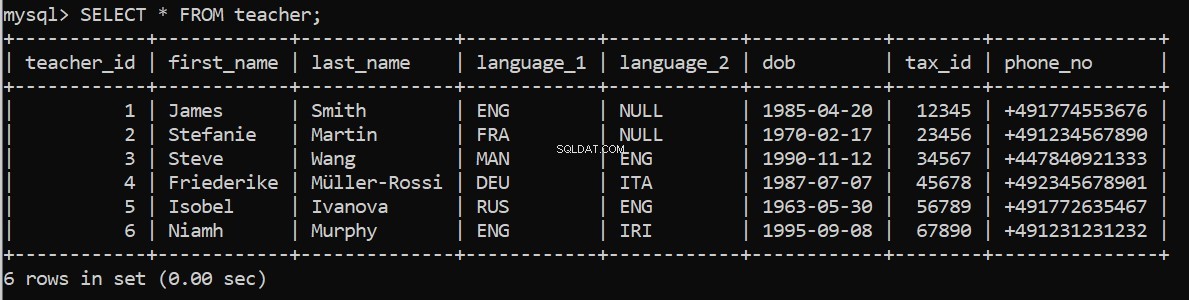
Füllen Sie nun die verbleibenden Tabellen.
pop_client = """
INSERT INTO client VALUES
(101, 'Big Business Federation', '123 Falschungstraße, 10999 Berlin', 'NGO'),
(102, 'eCommerce GmbH', '27 Ersatz Allee, 10317 Berlin', 'Retail'),
(103, 'AutoMaker AG', '20 Künstlichstraße, 10023 Berlin', 'Auto'),
(104, 'Banko Bank', '12 Betrugstraße, 12345 Berlin', 'Banking'),
(105, 'WeMoveIt GmbH', '138 Arglistweg, 10065 Berlin', 'Logistics');
"""
pop_participant = """
INSERT INTO participant VALUES
(101, 'Marina', 'Berg','491635558182', 101),
(102, 'Andrea', 'Duerr', '49159555740', 101),
(103, 'Philipp', 'Probst', '49155555692', 102),
(104, 'René', 'Brandt', '4916355546', 102),
(105, 'Susanne', 'Shuster', '49155555779', 102),
(106, 'Christian', 'Schreiner', '49162555375', 101),
(107, 'Harry', 'Kim', '49177555633', 101),
(108, 'Jan', 'Nowak', '49151555824', 101),
(109, 'Pablo', 'Garcia', '49162555176', 101),
(110, 'Melanie', 'Dreschler', '49151555527', 103),
(111, 'Dieter', 'Durr', '49178555311', 103),
(112, 'Max', 'Mustermann', '49152555195', 104),
(113, 'Maxine', 'Mustermann', '49177555355', 104),
(114, 'Heiko', 'Fleischer', '49155555581', 105);
"""
pop_course = """
INSERT INTO course VALUES
(12, 'English for Logistics', 'ENG', 'A1', 10, '2020-02-01', TRUE, 1, 105),
(13, 'Beginner English', 'ENG', 'A2', 40, '2019-11-12', FALSE, 6, 101),
(14, 'Intermediate English', 'ENG', 'B2', 40, '2019-11-12', FALSE, 6, 101),
(15, 'Advanced English', 'ENG', 'C1', 40, '2019-11-12', FALSE, 6, 101),
(16, 'Mandarin für Autoindustrie', 'MAN', 'B1', 15, '2020-01-15', TRUE, 3, 103),
(17, 'Français intermédiaire', 'FRA', 'B1', 18, '2020-04-03', FALSE, 2, 101),
(18, 'Deutsch für Anfänger', 'DEU', 'A2', 8, '2020-02-14', TRUE, 4, 102),
(19, 'Intermediate English', 'ENG', 'B2', 10, '2020-03-29', FALSE, 1, 104),
(20, 'Fortgeschrittenes Russisch', 'RUS', 'C1', 4, '2020-04-08', FALSE, 5, 103);
"""
pop_takescourse = """
INSERT INTO takes_course VALUES
(101, 15),
(101, 17),
(102, 17),
(103, 18),
(104, 18),
(105, 18),
(106, 13),
(107, 13),
(108, 13),
(109, 14),
(109, 15),
(110, 16),
(110, 20),
(111, 16),
(114, 12),
(112, 19),
(113, 19);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, pop_client)
execute_query(connection, pop_participant)
execute_query(connection, pop_course)
execute_query(connection, pop_takescourse)Tolle! Jetzt haben wir eine Datenbank komplett mit Relationen, Constraints und Datensätzen in MySQL erstellt, indem wir nichts als Python-Befehle verwenden.
Wir sind dies Schritt für Schritt durchgegangen, um es verständlich zu halten. Aber an diesem Punkt können Sie sehen, dass dies alles sehr einfach in ein Python-Skript geschrieben und in einem Befehl im Terminal ausgeführt werden könnte. Starkes Zeug.
Lesen von Daten
Jetzt haben wir eine funktionale Datenbank, mit der wir arbeiten können. Als Datenanalyst kommen Sie wahrscheinlich in Kontakt mit bestehenden Datenbanken in den Organisationen, in denen Sie arbeiten. Es ist sehr nützlich zu wissen, wie man Daten aus diesen Datenbanken zieht, damit sie dann in Ihre Python-Datenpipeline eingespeist werden können. Daran werden wir als nächstes arbeiten.
Dazu benötigen wir eine weitere Funktion, diesmal mit cursor.fetchall() anstelle von cursor.commit(). Mit dieser Funktion lesen wir Daten aus der Datenbank und nehmen keine Änderungen vor.
def read_query(connection, query):
cursor = connection.cursor()
result = None
try:
cursor.execute(query)
result = cursor.fetchall()
return result
except Error as err:
print(f"Error: '{err}'")Auch hier werden wir dies auf sehr ähnliche Weise wie execute_query implementieren. Lassen Sie es uns mit einer einfachen Abfrage ausprobieren, um zu sehen, wie es funktioniert.
q1 = """
SELECT *
FROM teacher;
"""
connection = create_db_connection("localhost", "root", pw, db)
results = read_query(connection, q1)
for result in results:
print(result)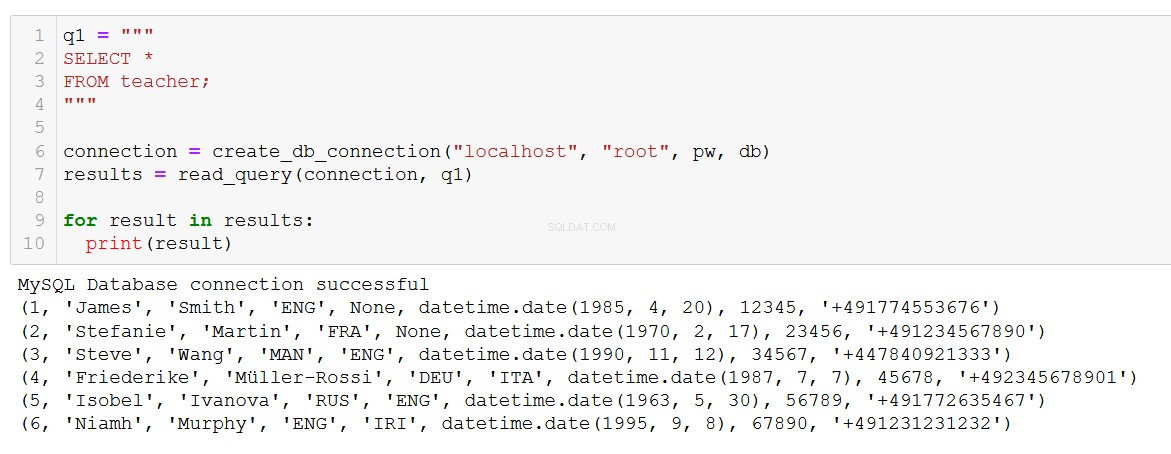
Genau das, was wir erwarten. Die Funktion funktioniert auch mit komplexeren Abfragen, wie dieser, die einen JOIN in den Kurs- und Kundentabellen beinhaltet.
q5 = """
SELECT course.course_id, course.course_name, course.language, client.client_name, client.address
FROM course
JOIN client
ON course.client = client.client_id
WHERE course.in_school = FALSE;
"""
connection = create_db_connection("localhost", "root", pw, db)
results = read_query(connection, q5)
for result in results:
print(result)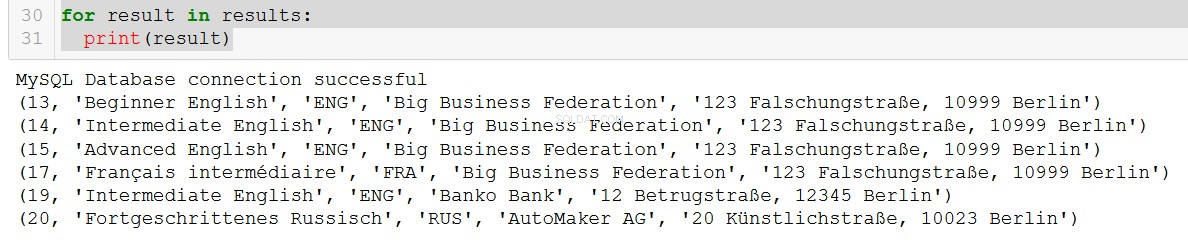
Sehr schön.
Für unsere Datenpipelines und Workflows in Python möchten wir diese Ergebnisse möglicherweise in verschiedenen Formaten erhalten, um sie nützlicher zu machen oder für uns zu bearbeiten.
Lassen Sie uns ein paar Beispiele durchgehen, um zu sehen, wie wir das machen können.
Ausgabe in eine Liste formatieren
#Initialise empty list
from_db = []
# Loop over the results and append them into our list
# Returns a list of tuples
for result in results:
result = result
from_db.append(result)
Ausgabe in eine Liste von Listen formatieren
# Returns a list of lists
from_db = []
for result in results:
result = list(result)
from_db.append(result)
Ausgabe in einen Pandas-Datenrahmen formatieren
Für Datenanalysten, die Python verwenden, ist Pandas unser schöner und vertrauenswürdiger alter Freund. Es ist sehr einfach, die Ausgabe unserer Datenbank in einen DataFrame zu konvertieren, und von dort aus sind die Möglichkeiten endlos!
# Returns a list of lists and then creates a pandas DataFrame
from_db = []
for result in results:
result = list(result)
from_db.append(result)
columns = ["course_id", "course_name", "language", "client_name", "address"]
df = pd.DataFrame(from_db, columns=columns)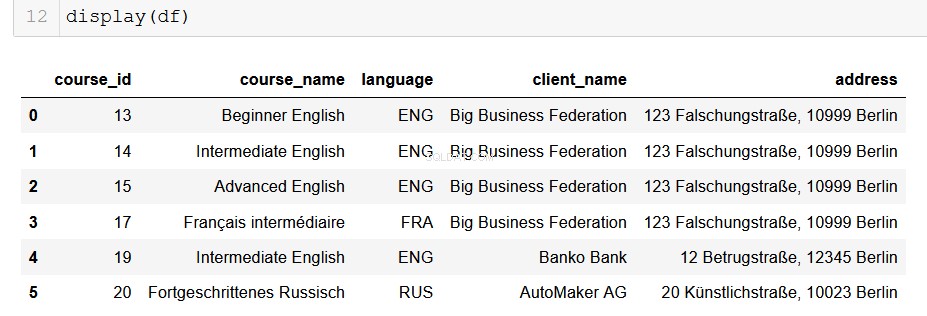
Hoffentlich können Sie die Möglichkeiten sehen, die sich hier vor Ihnen entfalten. Mit nur wenigen Codezeilen können wir problemlos alle Daten, die wir verarbeiten können, aus den relationalen Datenbanken, in denen sie gespeichert sind, extrahieren und in unsere hochmodernen Datenanalyse-Pipelines ziehen. Das ist wirklich hilfreich.
Datensätze aktualisieren
Wenn wir eine Datenbank pflegen, müssen wir manchmal Änderungen an bestehenden Datensätzen vornehmen. In diesem Abschnitt werden wir uns ansehen, wie das geht.
Nehmen wir an, das ILS wird darüber informiert, dass einer seiner bestehenden Kunden, die Big Business Federation, sein Büro in den Fingiertweg 23, 14534 Berlin verlegt. In diesem Fall muss der Datenbankadministrator (das sind wir!) einige Änderungen vornehmen.
Glücklicherweise können wir dies mit unserer execute_query-Funktion zusammen mit der SQL-UPDATE-Anweisung tun.
update = """
UPDATE client
SET address = '23 Fingiertweg, 14534 Berlin'
WHERE client_id = 101;
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, update)Beachten Sie, dass die WHERE-Klausel hier sehr wichtig ist. Wenn wir diese Abfrage ohne die WHERE-Klausel ausführen, werden alle Adressen für alle Datensätze in unserer Client-Tabelle auf 23 Fingiertweg aktualisiert. Das ist ganz und gar nicht das, was wir beabsichtigen.
Beachten Sie auch, dass wir in der UPDATE-Abfrage "WHERE client_id =101" verwendet haben. Möglich wäre auch "WHERE client_name ='Big Business Federation'" oder "WHERE address ='123 Falschungstraße, 10999 Berlin'" oder sogar "WHERE address LIKE '%Falschung%'".
Wichtig ist, dass die WHERE-Klausel es uns ermöglicht, den Datensatz (oder die Datensätze), den wir aktualisieren möchten, eindeutig zu identifizieren.
Löschen von Datensätzen
Es ist auch möglich, unsere execute_query-Funktion zu verwenden, um Datensätze zu löschen, indem Sie DELETE verwenden.
Bei der Verwendung von SQL mit relationalen Datenbanken müssen wir bei der Verwendung des DELETE-Operators vorsichtig sein. Dies ist nicht Windows, es gibt kein "Möchten Sie das wirklich löschen?" Warn-Popup, und es gibt keinen Papierkorb. Sobald wir etwas löschen, ist es wirklich weg.
Trotzdem müssen wir manchmal Dinge wirklich löschen. Schauen wir uns das einmal an, indem wir einen Kurs aus unserer Kurstabelle löschen.
Erinnern wir uns zuerst daran, welche Kurse wir haben.
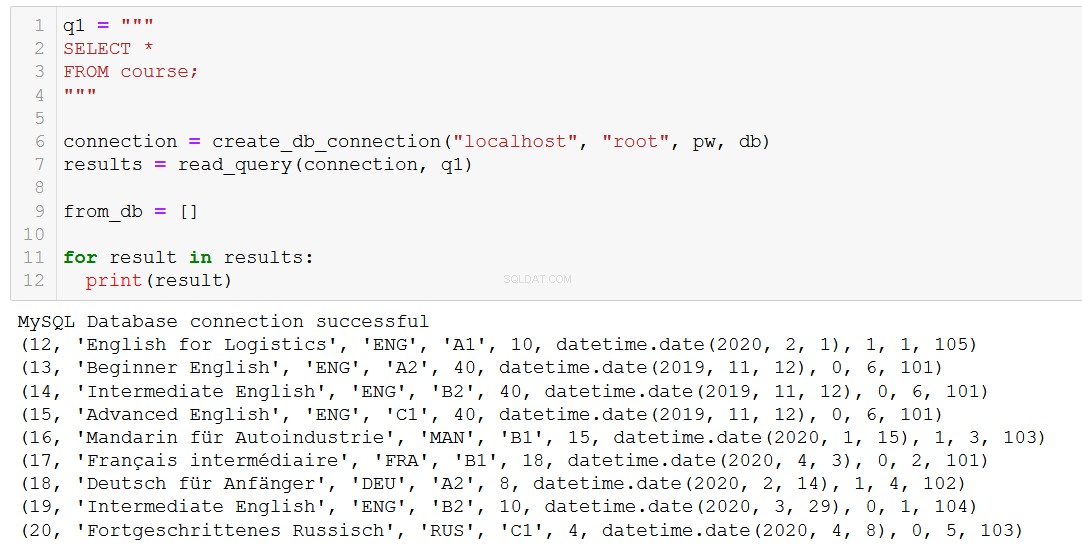
Nehmen wir an, Kurs 20 „Fortgeschrittenes Russisch“ geht zu Ende, also müssen wir ihn aus unserer Datenbank entfernen.
Zu diesem Zeitpunkt werden Sie überhaupt nicht überrascht sein, wie wir dies tun - speichern Sie den SQL-Befehl als Zeichenfolge und füttern Sie ihn dann in unsere Arbeitstier-Funktion execute_query.
delete_course = """
DELETE FROM course
WHERE course_id = 20;
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, delete_course)Lassen Sie uns überprüfen, ob die beabsichtigte Wirkung erzielt wurde:
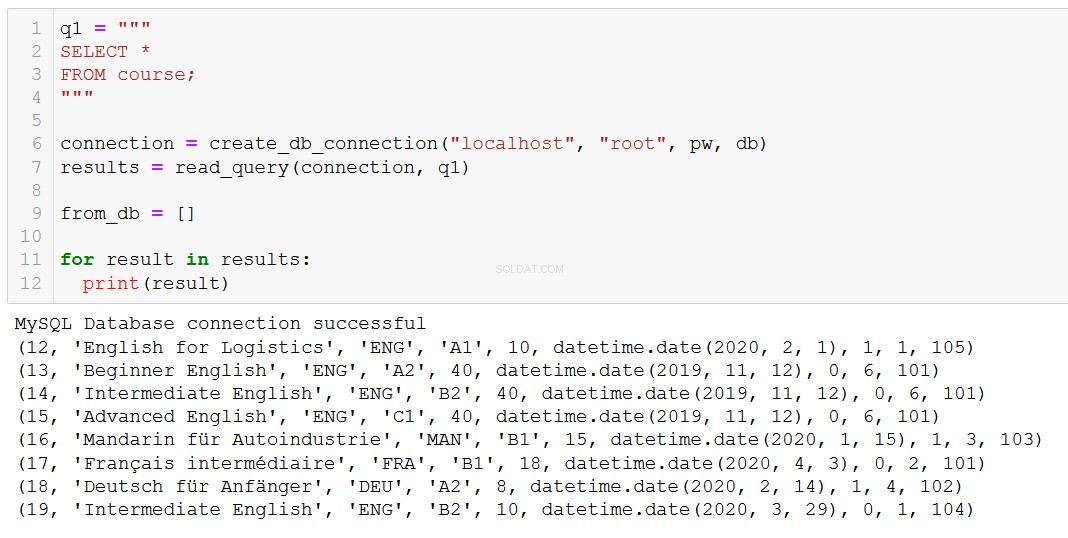
„Advanced Russian“ ist weg, wie wir erwartet haben.
Dies funktioniert auch mit dem Löschen ganzer Spalten mit DROP COLUMN und ganzer Tabellen mit DROP TABLE-Befehlen, aber wir werden diese in diesem Tutorial nicht behandeln.
Experimentieren Sie jedoch mit ihnen - es spielt keine Rolle, ob Sie eine Spalte oder Tabelle aus einer Datenbank für eine fiktive Schule löschen, und es ist eine gute Idee, sich mit diesen Befehlen vertraut zu machen, bevor Sie in eine Produktionsumgebung wechseln.
Oh CRUD
An diesem Punkt sind wir nun in der Lage, die vier Hauptoperationen für die persistente Datenspeicherung abzuschließen.
Wir haben gelernt, wie man:
- Erstellen - völlig neue Datenbanken, Tabellen und Datensätze
- Lesen – Extrahieren Sie Daten aus einer Datenbank und speichern Sie diese Daten in mehreren Formaten
- Aktualisieren - Änderungen an bestehenden Datensätzen in der Datenbank vornehmen
- Löschen - Datensätze entfernen, die nicht mehr benötigt werden
Dies sind fantastisch nützliche Dinge, die man tun kann.
Bevor wir hier fertig werden, müssen wir noch eine weitere sehr praktische Fähigkeit erlernen.
Erstellen von Datensätzen aus Listen
Beim Füllen unserer Tabellen haben wir gesehen, dass wir den SQL-Befehl INSERT in unserer Funktion execute_query verwenden können, um Datensätze in unsere Datenbank einzufügen.
Angesichts der Tatsache, dass wir Python verwenden, um unsere SQL-Datenbank zu manipulieren, wäre es nützlich, eine Python-Datenstruktur (z. B. eine Liste) zu nehmen und diese direkt in unsere Datenbank einzufügen.
Dies könnte nützlich sein, wenn wir beispielsweise Protokolle der Benutzeraktivität in einer Social-Media-App speichern möchten, die wir in Python geschrieben haben, oder Eingaben von Benutzern in ein von uns erstelltes Wiki. Es gibt so viele mögliche Verwendungen dafür, wie Sie sich vorstellen können.
Diese Methode ist auch sicherer, wenn unsere Datenbank zu irgendeinem Zeitpunkt für unsere Benutzer offen ist, da sie dazu beiträgt, SQL-Injection-Angriffe zu verhindern, die unsere gesamte Datenbank beschädigen oder sogar zerstören können.
Dazu schreiben wir eine Funktion, die die Methode executemany() verwendet, anstatt der einfacheren Methode execute(), die wir bisher verwendet haben.
def execute_list_query(connection, sql, val):
cursor = connection.cursor()
try:
cursor.executemany(sql, val)
connection.commit()
print("Query successful")
except Error as err:
print(f"Error: '{err}'")Jetzt haben wir die Funktion, wir müssen einen SQL-Befehl ('sql') und eine Liste mit den Werten definieren, die wir in die Datenbank eingeben wollen ('val'). Die Werte müssen als Liste von Tupeln gespeichert werden, was eine ziemlich übliche Art ist, Daten in Python zu speichern.
Um zwei neue Lehrer zur Datenbank hinzuzufügen, können wir Code wie diesen schreiben:
sql = '''
INSERT INTO teacher (teacher_id, first_name, last_name, language_1, language_2, dob, tax_id, phone_no)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
'''
val = [
(7, 'Hank', 'Dodson', 'ENG', None, '1991-12-23', 11111, '+491772345678'),
(8, 'Sue', 'Perkins', 'MAN', 'ENG', '1976-02-02', 22222, '+491443456432')
]Beachten Sie hier, dass wir im 'sql'-Code das '%s' als Platzhalter für unseren Wert verwenden. Die Ähnlichkeit mit dem Platzhalter '%s' für einen String in Python ist rein zufällig (und ehrlich gesagt sehr verwirrend), wir wollen '%s' für alle Datentypen (Strings, Ints, Datumsangaben usw.) mit MySQL Python verwenden Verbinder.
Sie können eine Reihe von Fragen zu Stackoverflow sehen, bei denen jemand verwirrt war und versucht hat, '%d'-Platzhalter für ganze Zahlen zu verwenden, weil er dies in Python gewohnt ist. Dies funktioniert hier nicht - wir müssen ein '%s' für jede Spalte verwenden, der wir einen Wert hinzufügen möchten.
Die Funktion executemany nimmt dann jedes Tupel in unserer 'val'-Liste und fügt den relevanten Wert für diese Spalte anstelle des Platzhalters ein und führt den SQL-Befehl für jedes in der Liste enthaltene Tupel aus.
Dies kann für mehrere Datenzeilen durchgeführt werden, solange sie korrekt formatiert sind. In unserem Beispiel werden wir zur Veranschaulichung nur zwei neue Lehrer hinzufügen, aber im Prinzip können wir so viele hinzufügen, wie wir möchten.
Lassen Sie uns fortfahren und diese Abfrage ausführen und die Lehrer zu unserer Datenbank hinzufügen.
connection = create_db_connection("localhost", "root", pw, db)
execute_list_query(connection, sql, val)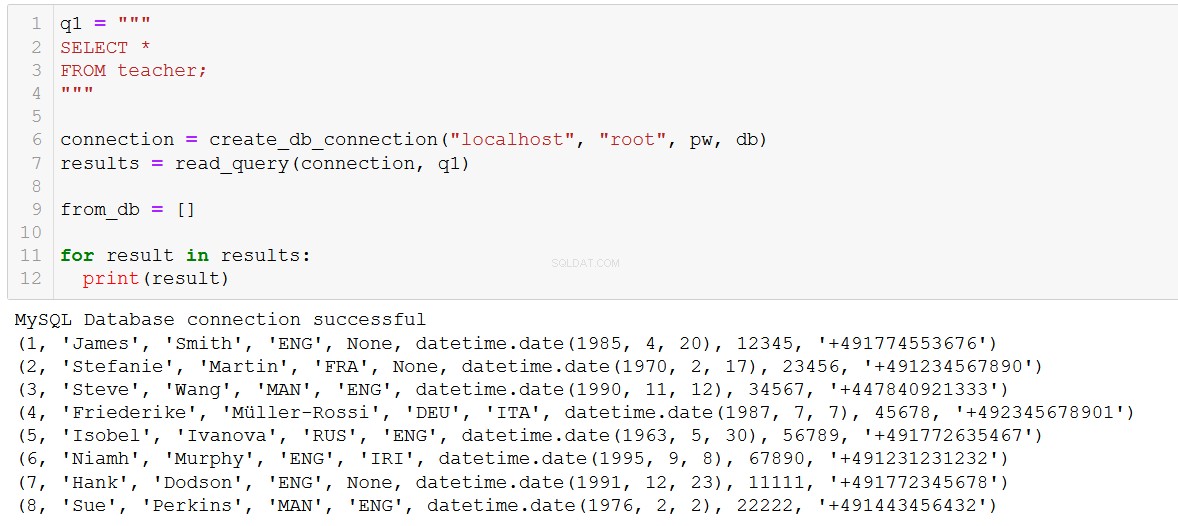
Willkommen beim ILS, Hank und Sue!
This is yet another deeply useful function, allowing us to take data generated in our Python scripts and applications, and enter them directly into our database.
Conclusion
We have covered a lot of ground in this tutorial.
We have learned how to use Python and MySQL Connector to create an entirely new database in MySQL Server, create tables within that database, define the relationships between those tables, and populate them with data.
We have covered how to Create, Read, Update and Delete data in our database.
We have looked at how to extract data from existing databases and load them into pandas DataFrames, ready for analysis and further work taking advantage of all the possibilities offered by the PyData stack.
Going in the other direction, we have also learned how to take data generated by our Python scripts and applications, and write those into a database where they can be safely stored for later retrieval and manipulation.
I hope this tutorial has helped you to see how we can use Python and SQL together to be able to manipulate data even more effectively!
If you'd like to see more of my projects and work, please visit my website at craigdoesdata.de. If you have any feedback on this tutorial, please contact me directly - all feedback is warmly received!