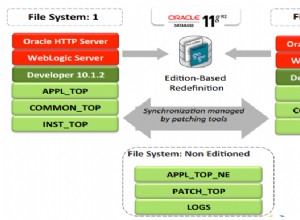
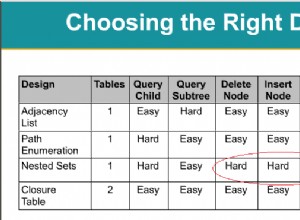
Versuchen Sie Folgendes:
id2 = csv.reader(open(os.path.join(perf_dir,id_files[1])))
h = tuple(next(id2))
create = '''CREATE TABLE id2 (%s varchar, %s int PRIMARY KEY, %s int)''' % h
insert = '''INSERT INTO id2 (%s, %s, %s) VALUES (%%s, %%s, %%s)''' % h
...
cr.executemany(insert, id2)
Übergeben Sie den SQL-Befehl nur einmal für alle Zeilen. Beachten Sie neben dem Leistungsaufwand durch die Ausgabe zusätzlicher SQL-Befehle, dass die Größe der SQL-Zeichenfolge selbst (in Byte) wahrscheinlich die Größe der zu testenden echten Daten in den Schatten stellt.
Die Verwendung von id2 als Generator ohne das Array sollte auch vermeiden, den gesamten Datensatz in den Speicher zu laden.