Leistung ist bei vielen Verbraucherprodukten wie E-Commerce, Zahlungssystemen, Spielen, Transport-Apps usw. äußerst wichtig. Obwohl Datenbanken intern durch mehrere Mechanismen optimiert werden, um ihre Leistungsanforderungen in der modernen Welt zu erfüllen, hängt viel auch vom Anwendungsentwickler ab – schließlich weiß nur ein Entwickler, welche Abfragen die Anwendung ausführen muss.
Entwickler, die sich mit relationalen Datenbanken befassen, haben Indizierung verwendet oder zumindest davon gehört, und es ist ein sehr verbreitetes Konzept in der Datenbankwelt. Der wichtigste Teil ist jedoch zu verstehen, was indiziert werden soll und wie die Indizierung die Antwortzeit auf Abfragen verbessern wird. Dazu müssen Sie verstehen, wie Sie Ihre Datenbanktabellen abfragen werden. Ein richtiger Index kann nur erstellt werden, wenn Sie genau wissen, wie Ihre Abfrage- und Datenzugriffsmuster aussehen.
In einfacher Terminologie ordnet ein Index Suchschlüssel entsprechenden Daten auf der Festplatte zu, indem er verschiedene In-Memory- und On-Disk-Datenstrukturen verwendet. Der Index wird verwendet, um die Suche zu beschleunigen, indem die Anzahl der zu suchenden Datensätze reduziert wird.
Meistens wird ein Index auf den Spalten erstellt, die im WHERE angegeben sind Klausel einer Abfrage, da die Datenbank Daten aus den Tabellen basierend auf diesen Spalten abruft und filtert. Wenn Sie keinen Index erstellen, scannt die Datenbank alle Zeilen, filtert die übereinstimmenden Zeilen heraus und gibt das Ergebnis zurück. Bei Millionen von Datensätzen kann dieser Scanvorgang viele Sekunden dauern und diese hohe Reaktionszeit macht APIs und Anwendungen langsamer und unbrauchbar. Sehen wir uns ein Beispiel an –
Wir werden MySQL mit einer standardmäßigen InnoDB-Datenbank-Engine verwenden, obwohl die in diesem Artikel erläuterten Konzepte auch auf anderen Datenbankservern wie Oracle, MSSQL usw. mehr oder weniger gleich sind.
Erstellen Sie eine Tabelle namens index_demo mit folgendem Schema:
CREATE TABLE index_demo (
name VARCHAR(20) NOT NULL,
age INT,
pan_no VARCHAR(20),
phone_no VARCHAR(20)
);Wie überprüfen wir, ob wir die InnoDB-Engine verwenden?
Führen Sie den folgenden Befehl aus:
SHOW TABLE STATUS WHERE name = 'index_demo' \G;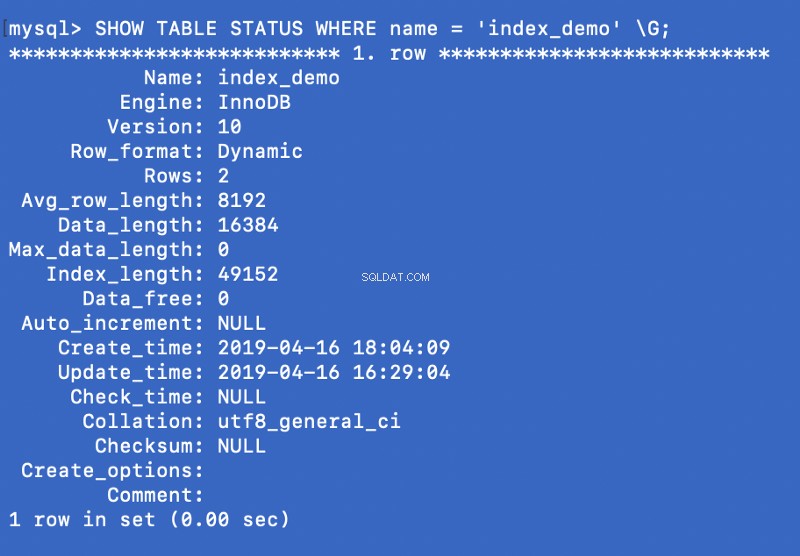
Die Engine Spalte im obigen Screenshot stellt die Engine dar, die zum Erstellen der Tabelle verwendet wird. Hier InnoDB verwendet wird.
Fügen Sie nun einige zufällige Daten in die Tabelle ein, meine Tabelle mit 5 Zeilen sieht wie folgt aus:
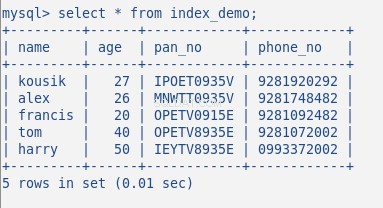
Ich habe bisher keinen Index auf dieser Tabelle erstellt. Lassen Sie uns dies mit dem Befehl überprüfen:SHOW INDEX . Es gibt 0 Ergebnisse zurück.

In diesem Moment, wenn wir ein einfaches SELECT ausführen Abfrage, da es keinen benutzerdefinierten Index gibt, durchsucht die Abfrage die gesamte Tabelle, um das Ergebnis herauszufinden:
EXPLAIN SELECT * FROM index_demo WHERE name = 'alex';
EXPLAIN zeigt, wie die Abfrage-Engine plant, die Abfrage auszuführen. Im obigen Screenshot sehen Sie, dass die rows Spalte gibt 5 zurück &possible_keys gibt null zurück . possible_keys stellt dar, was alle verfügbaren Indizes sind, die in dieser Abfrage verwendet werden können. Der key Spalte stellt dar, welcher Index von allen möglichen Indizes in dieser Abfrage tatsächlich verwendet wird.
Primärschlüssel:
Die obige Abfrage ist sehr ineffizient. Lassen Sie uns diese Abfrage optimieren. Wir machen die phone_no Spalte ein PRIMARY KEY vorausgesetzt, dass in unserem System keine zwei Benutzer mit derselben Telefonnummer existieren können. Berücksichtigen Sie beim Erstellen eines Primärschlüssels Folgendes:
- Ein Primärschlüssel sollte Teil vieler wichtiger Abfragen in Ihrer Anwendung sein.
- Der Primärschlüssel ist eine Einschränkung, die jede Zeile in einer Tabelle eindeutig identifiziert. Wenn mehrere Spalten Teil des Primärschlüssels sind, sollte diese Kombination für jede Zeile eindeutig sein.
- Primärschlüssel sollte Nicht-Null sein. Machen Sie niemals nullfähige Felder zu Ihrem Primärschlüssel. Nach ANSI-SQL-Standards sollten Primärschlüssel miteinander vergleichbar sein, und Sie sollten auf jeden Fall feststellen können, ob der Primärschlüssel-Spaltenwert für eine bestimmte Zeile größer, kleiner oder gleich dem Wert einer anderen Zeile ist. Seit
NULLbedeutet in SQL-Standards einen undefinierten Wert, Sie könnenNULLnicht deterministisch vergleichen mit jedem anderen Wert, also logischNULList nicht erlaubt. - Der ideale Primärschlüsseltyp sollte eine Zahl wie
INTsein oderBIGINTweil Integer-Vergleiche schneller sind, also wird das Durchlaufen des Index sehr schnell sein.
Oft definieren wir eine id Feld als AUTO INCREMENT in Tabellen &verwenden Sie diesen als Primärschlüssel, aber die Wahl eines Primärschlüssels hängt von den Entwicklern ab.
Was ist, wenn Sie selbst keinen Primärschlüssel erstellen?
Es ist nicht zwingend erforderlich, selbst einen Primärschlüssel zu erstellen. Wenn Sie keinen Primärschlüssel definiert haben, erstellt InnoDB implizit einen für Sie, da InnoDB per Design einen Primärschlüssel in jeder Tabelle haben muss. Sobald Sie also später einen Primärschlüssel für diese Tabelle erstellen, löscht InnoDB den zuvor automatisch definierten Primärschlüssel.
Da wir noch keinen Primärschlüssel definiert haben, sehen wir uns an, was InnoDB standardmäßig für uns erstellt hat:
SHOW EXTENDED INDEX FROM index_demo;
EXTENDED zeigt alle Indizes, die nicht vom Benutzer verwendet werden können, aber vollständig von MySQL verwaltet werden.
Hier sehen wir, dass MySQL einen zusammengesetzten Index (wir werden zusammengesetzte Indizes später besprechen) auf DB_ROW_ID definiert hat , DB_TRX_ID , DB_ROLL_PTR , &alle in der Tabelle definierten Spalten. In Ermangelung eines benutzerdefinierten Primärschlüssels wird dieser Index verwendet, um Datensätze eindeutig zu finden.
Was ist der Unterschied zwischen Schlüssel und Index?
Obwohl die Begriffe key &index werden austauschbar verwendet, key bedeutet eine Einschränkung, die dem Verhalten der Spalte auferlegt wird. In diesem Fall besteht die Einschränkung darin, dass der Primärschlüssel ein nicht nullfähiges Feld ist, das jede Zeile eindeutig identifiziert. Andererseits index ist eine spezielle Datenstruktur, die die Datensuche über die Tabelle erleichtert.
Lassen Sie uns nun den primären Index auf phone_no erstellen &Untersuchen Sie den erstellten Index:
ALTER TABLE index_demo ADD PRIMARY KEY (phone_no);
SHOW INDEXES FROM index_demo;
Beachten Sie, dass CREATE INDEX kann nicht zum Erstellen eines Primärindex verwendet werden, aber ALTER TABLE verwendet wird.

Im obigen Screenshot sehen wir, dass ein primärer Index für die Spalte phone_no erstellt wird . Die Spalten der folgenden Bilder werden wie folgt beschrieben:
Table :Die Tabelle, auf der der Index erstellt wird.
Non_unique :Wenn der Wert 1 ist, ist der Index nicht eindeutig, wenn der Wert 0 ist, ist der Index eindeutig.
Key_name :Der Name des erstellten Indexes. Der Name des Primärindex ist immer PRIMARY in MySQL, unabhängig davon, ob Sie beim Erstellen des Indexes einen Indexnamen angegeben haben oder nicht.
Seq_in_index :Die Sequenznummer der Spalte im Index. Wenn mehrere Spalten Teil des Indexes sind, wird die Sequenznummer basierend auf der Reihenfolge der Spalten während der Indexerstellung zugewiesen. Die Sequenznummer beginnt bei 1.
Collation :wie die Spalte im Index sortiert ist. A bedeutet aufsteigend, D bedeutet absteigend, NULL bedeutet nicht sortiert.
Cardinality :Die geschätzte Anzahl eindeutiger Werte im Index. Mehr Kardinalität bedeutet höhere Chancen, dass der Abfrageoptimierer den Index für Abfragen auswählt.
Sub_part :Das Indexpräfix. Es ist NULL wenn die gesamte Spalte indiziert ist. Andernfalls wird die Anzahl der indizierten Bytes angezeigt, falls die Spalte teilweise indiziert ist. Wir werden den partiellen Index später definieren.
Packed :Zeigt an, wie der Schlüssel verpackt ist; NULL wenn nicht.
Null :YES ob die Spalte NULL enthalten darf Werte und leer, wenn nicht.
Index_type :Gibt an, welche Indizierungsdatenstruktur für diesen Index verwendet wird. Einige mögliche Kandidaten sind — BTREE , HASH , RTREE , oder FULLTEXT .
Comment :Die Informationen über den Index, die nicht in einer eigenen Spalte beschrieben sind.
Index_comment :Der Kommentar für den Index, der angegeben wurde, als Sie den Index mit dem COMMENT erstellt haben Attribut.
Sehen wir uns nun an, ob dieser Index die Anzahl der Zeilen reduziert, die nach einer bestimmten phone_no durchsucht werden im WHERE Klausel einer Abfrage.
EXPLAIN SELECT * FROM index_demo WHERE phone_no = '9281072002';
Beachten Sie in diesem Schnappschuss, dass die rows Spalte hat 1 zurückgegeben nur die possible_keys &key beide geben PRIMARY zurück . Es bedeutet also im Wesentlichen, dass der primäre Index mit dem Namen PRIMARY verwendet wird (der Name wird automatisch zugewiesen, wenn Sie den Primärschlüssel erstellen), der Abfrageoptimierer geht einfach direkt zum Datensatz und ruft ihn ab. Es ist sehr effizient. Genau dafür ist ein Index da – um den Suchbereich auf Kosten von zusätzlichem Speicherplatz zu minimieren.
Clustered-Index:
Ein clustered index zusammen mit den Daten im gleichen Tabellenbereich oder in der gleichen Plattendatei angeordnet ist. Sie können davon ausgehen, dass ein geclusterter Index ein B-Tree ist Index, dessen Blattknoten die eigentlichen Datenblöcke auf der Festplatte sind, da sich Index und Daten zusammen befinden. Diese Art von Index organisiert die Daten auf der Festplatte physisch gemäß der logischen Reihenfolge des Indexschlüssels.
Was bedeutet physische Datenorganisation?
Physisch werden Daten auf der Festplatte über Tausende oder Millionen von Festplatten-/Datenblöcken organisiert. Für einen Clustered-Index ist es nicht zwingend erforderlich, dass alle Festplattenblöcke ansteckend gespeichert werden. Physische Datenblöcke werden vom Betriebssystem immer hierhin und dorthin verschoben, wann immer es nötig ist. Ein Datenbanksystem hat keine absolute Kontrolle darüber, wie der physische Datenraum verwaltet wird, aber innerhalb eines Datenblocks können Datensätze in der logischen Reihenfolge des Indexschlüssels gespeichert oder verwaltet werden. Das folgende vereinfachte Diagramm erklärt es:
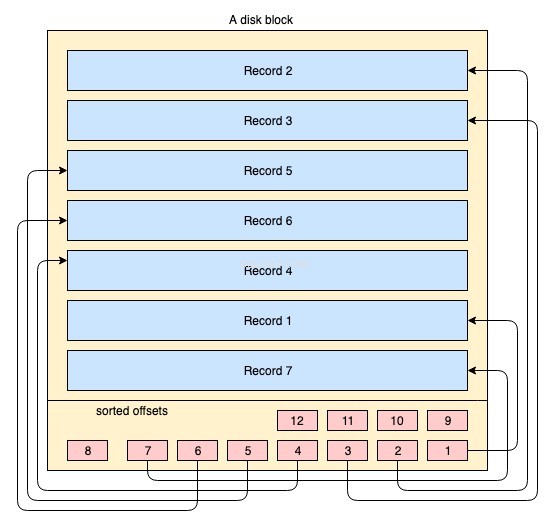
- Das gelbe große Rechteck repräsentiert einen Plattenblock / Datenblock
- Die blauen Rechtecke stellen Daten dar, die als Zeilen innerhalb dieses Blocks gespeichert sind
- Der Fußbereich stellt den Index des Blocks dar, in dem sich rote kleine Rechtecke in sortierter Reihenfolge eines bestimmten Schlüssels befinden. Diese kleinen Blöcke sind nichts anderes als eine Art Zeiger, die auf Offsets der Datensätze zeigen.
Datensätze werden in beliebiger Reihenfolge auf dem Plattenblock gespeichert. Wenn neue Datensätze hinzugefügt werden, werden sie im nächsten verfügbaren Platz hinzugefügt. Immer wenn ein bestehender Datensatz aktualisiert wird, entscheidet das Betriebssystem, ob dieser Datensatz noch an derselben Position Platz findet oder diesem Datensatz eine neue Position zugewiesen werden muss.
Die Position der Datensätze wird also vollständig vom Betriebssystem gehandhabt und es besteht keine eindeutige Beziehung zwischen der Reihenfolge von zwei Datensätzen. Um die Datensätze in der logischen Reihenfolge des Schlüssels abzurufen, enthalten Plattenseiten einen Indexabschnitt in der Fußzeile, der Index enthält eine Liste von Offset-Zeigern in der Reihenfolge des Schlüssels. Jedes Mal, wenn ein Datensatz geändert oder erstellt wird, wird der Index angepasst.
Auf diese Weise müssen Sie sich wirklich nicht darum kümmern, die physischen Aufzeichnungen in einer bestimmten Reihenfolge zu organisieren, sondern es wird ein kleiner Indexabschnitt in dieser Reihenfolge verwaltet und das Abrufen oder Verwalten von Aufzeichnungen wird sehr einfach.
Vorteil des geclusterten Index:
Dieses Ordnen oder Zusammenstellen zusammengehöriger Daten macht einen gruppierten Index tatsächlich schneller. Wenn Daten von der Festplatte abgerufen werden, wird der vollständige Block, der die Daten enthält, vom System gelesen, da unser Festplatten-IO-System Daten in Blöcken schreibt und liest. Bei Bereichsabfragen ist es also durchaus möglich, dass die zusammengeführten Daten im Arbeitsspeicher gepuffert werden. Angenommen, Sie lösen die folgende Abfrage aus:
SELECT * FROM index_demo WHERE phone_no > '9010000000' AND phone_no < '9020000000'
Ein Datenblock wird in den Speicher geholt, wenn die Abfrage ausgeführt wird. Angenommen, der Datenblock enthält phone_no im Bereich von 9010000000 bis 9030000000 . Der von Ihnen in der Abfrage angeforderte Bereich ist also nur eine Teilmenge der im Block vorhandenen Daten. Wenn Sie jetzt die nächste Abfrage auslösen, um alle Telefonnummern im Bereich zu erhalten, sagen wir ab 9015000000 bis 9019000000 , müssen Sie keine weiteren Blöcke von der Festplatte holen. Die vollständigen Daten befinden sich im aktuellen Datenblock, also clustered_index reduziert die Anzahl der Festplatten-E/A, indem zusammengehörige Daten so weit wie möglich im selben Datenblock zusammengefasst werden. Diese reduzierte Datenträger-E/A führt zu einer Verbesserung der Leistung.
Wenn Sie also den Primärschlüssel gut durchdacht haben und Ihre Abfragen auf dem Primärschlüssel basieren, wird die Leistung superschnell sein.
Einschränkungen des Clustered-Index:
Da ein Clustered-Index die physische Organisation der Daten beeinflusst, kann es nur einen Clustered-Index pro Tabelle geben.
Beziehung zwischen Primärschlüssel und Clustered-Index:
Sie können einen Clustered-Index nicht manuell mit InnoDB in MySQL erstellen. MySQL wählt es für Sie aus. Aber wie wählt es aus? Die folgenden Auszüge stammen aus der MySQL-Dokumentation:
Wenn Sie einenPRIMARY KEYdefinieren auf Ihrem Tisch,InnoDBverwendet es als gruppierten Index. Definieren Sie einen Primärschlüssel für jede Tabelle, die Sie erstellen. Wenn es keine logisch eindeutige Spalte oder Spaltengruppe gibt, die nicht null ist, fügen Sie eine neue Spalte mit automatischer Inkrementierung hinzu, deren Werte automatisch ausgefüllt werden.
Wenn Sie keinenPRIMARY KEYdefinieren für Ihre Tabelle findet MySQL den erstenUNIQUEIndex, bei dem alle SchlüsselspaltenNOT NULLsind undInnoDBverwendet es als gruppierten Index.
Wenn die Tabelle keinenPRIMARY KEYhat oder passendesUNIQUEindex,InnoDBgeneriert intern einen versteckten gruppierten Index namensGEN_CLUST_INDEXin einer synthetischen Spalte, die Zeilen-ID-Werte enthält. Die Zeilen sind nach der ID sortiert, dieInnoDBweist den Zeilen in einer solchen Tabelle zu. Die Zeilen-ID ist ein 6-Byte-Feld, das monoton zunimmt, wenn neue Zeilen eingefügt werden. Somit befinden sich die nach der Zeilen-ID geordneten Zeilen physisch in der Einfügereihenfolge.
Kurz gesagt, die MySQL InnoDB-Engine verwaltet den Primärindex tatsächlich als geclusterten Index, um die Leistung zu verbessern, sodass der Primärschlüssel und der tatsächliche Datensatz auf der Festplatte zusammen geclustert werden.
Struktur des Primärschlüssels (clustered) Index:
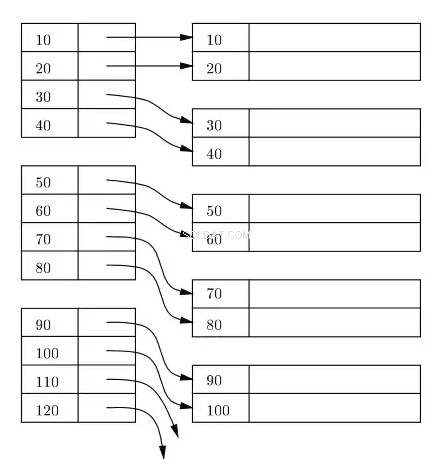
Ein Index wird normalerweise als B+-Baum auf der Festplatte und im Arbeitsspeicher verwaltet, und jeder Index wird in Blöcken auf der Festplatte gespeichert. Diese Blöcke werden Indexblöcke genannt. Die Einträge im Indexblock sind immer nach dem Index/Suchschlüssel sortiert. Der Blattindexblock des Indexes enthält einen Zeilenlokator. Für den primären Index bezieht sich der Zeilen-Locator auf die virtuelle Adresse des entsprechenden physischen Speicherorts der Datenblöcke auf der Festplatte, wo sich Zeilen befinden, die gemäß dem Indexschlüssel sortiert werden.
Im folgenden Diagramm repräsentieren die Rechtecke auf der linken Seite Indexblöcke auf Blattebene und die Rechtecke auf der rechten Seite die Datenblöcke. Logischerweise scheinen die Datenblöcke in einer sortierten Reihenfolge angeordnet zu sein, aber wie bereits zuvor beschrieben, können die tatsächlichen physischen Standorte hier und da verstreut sein.
Ist es möglich, einen primären Index auf einem nicht-primären Schlüssel zu erstellen?
In MySQL wird automatisch ein Primärindex erstellt, und wir haben oben bereits beschrieben, wie MySQL den Primärindex auswählt. Aber in der Datenbankwelt ist es eigentlich nicht notwendig, einen Index für die Primärschlüsselspalte zu erstellen – der Primärindex kann auch für jede Nicht-Primärschlüsselspalte erstellt werden. Aber wenn sie auf dem Primärschlüssel erstellt werden, sind alle Schlüsseleinträge im Index eindeutig, während im anderen Fall der Primärindex auch einen duplizierten Schlüssel haben kann.
Ist es möglich, einen Primärschlüssel zu löschen?
Es ist möglich, einen Primärschlüssel zu löschen. Wenn Sie einen Primärschlüssel löschen, gehen der zugehörige Clustered-Index sowie die Eindeutigkeitseigenschaft dieser Spalte verloren.
ALTER TABLE `index_demo` DROP PRIMARY KEY;
- If the primary key does not exist, you get the following error:
"ERROR 1091 (42000): Can't DROP 'PRIMARY'; check that column/key exists"Vorteile des Primärindex:
- Primärindexbasierte Bereichsabfragen sind sehr effizient. Es besteht die Möglichkeit, dass der Festplattenblock, den die Datenbank von der Festplatte gelesen hat, alle zur Abfrage gehörenden Daten enthält, da der Primärindex gruppiert ist und die Datensätze physisch geordnet sind. So kann die Lokalität der Daten durch den Primärindex bereitgestellt werden.
- Jede Abfrage, die den Primärschlüssel nutzt, ist sehr schnell.
Nachteile des Primärindex:
- Da der primäre Index einen direkten Verweis auf die Datenblockadresse über den virtuellen Adressraum enthält und Festplattenblöcke physisch in der Reihenfolge des Indexschlüssels organisiert sind, führt das Betriebssystem jedes Mal, wenn das Betriebssystem aufgrund von
DMLOperationen wieINSERT/UPDATE/DELETE, muss auch der Primärindex aktualisiert werden. AlsoDMLOperationen üben einen gewissen Druck auf die Performance des Primärindex aus.
Sekundärindex:
Jeder andere Index als ein gruppierter Index wird als sekundärer Index bezeichnet. Sekundärindizes wirken sich im Gegensatz zu Primärindizes nicht auf physische Speicherorte aus.
Wann benötigen Sie einen sekundären Index?
Möglicherweise gibt es in Ihrer Anwendung mehrere Anwendungsfälle, in denen Sie die Datenbank nicht mit einem Primärschlüssel abfragen. In unserem Beispiel phone_no ist der Primärschlüssel, aber möglicherweise müssen wir die Datenbank mit pan_no abfragen , oder name . In solchen Fällen benötigen Sie Sekundärindizes auf diesen Spalten, wenn die Häufigkeit solcher Abfragen sehr hoch ist.
Wie erstelle ich einen sekundären Index in MySQL?
Der folgende Befehl erstellt einen sekundären Index im name Spalte in index_demo Tabelle.
CREATE INDEX secondary_idx_1 ON index_demo (name);
Struktur des Sekundärindex:
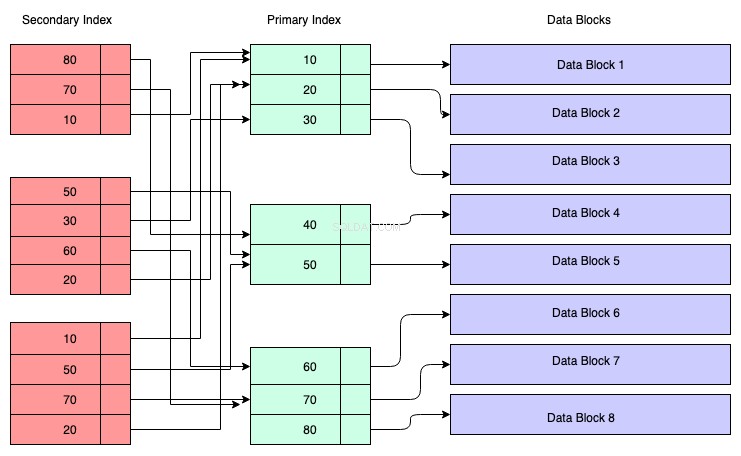
Im Diagramm unten repräsentieren die rot gefärbten Rechtecke sekundäre Indexblöcke. Der sekundäre Index wird ebenfalls im B+-Baum verwaltet und nach dem Schlüssel sortiert, auf dem der Index erstellt wurde. Die Blattknoten enthalten eine Kopie des Schlüssels der entsprechenden Daten im Primärindex.
Um das zu verstehen, können Sie also davon ausgehen, dass der Sekundärindex auf die Adresse des Primärschlüssels verweist, obwohl dies nicht der Fall ist. Das Abrufen von Daten über den sekundären Index bedeutet, dass Sie zwei B+-Bäume durchlaufen müssen – einer ist der sekundäre Index-B+-Baum selbst und der andere ist der primäre Index-B+-Baum.
Vorteile eines Sekundärindex:
Logischerweise können Sie beliebig viele Sekundärindizes anlegen. Aber wie viele Indizes tatsächlich benötigt werden, erfordert einen ernsthaften Denkprozess, da jeder Index seine eigene Strafe hat.
Nachteile eines Sekundärindex:
Mit DML Operationen wie DELETE / INSERT , muss auch der Sekundärindex aktualisiert werden, damit die Kopie der Primärschlüsselspalte gelöscht/eingefügt werden kann. In solchen Fällen kann das Vorhandensein vieler Sekundärindizes zu Problemen führen.
Auch wenn ein Primärschlüssel sehr groß ist wie eine URL , da sekundäre Indizes eine Kopie des Primärschlüsselspaltenwerts enthalten, kann dies in Bezug auf die Speicherung ineffizient sein. Mehr Sekundärschlüssel bedeuten eine größere Anzahl doppelter Kopien des Primärschlüsselspaltenwerts, also mehr Speicherplatz im Falle eines großen Primärschlüssels. Auch der Primärschlüssel selbst speichert die Schlüssel, sodass die kombinierte Auswirkung auf die Speicherung sehr hoch sein wird.
Bedenken Sie, bevor Sie einen Primärindex löschen:
In MySQL können Sie einen Primärindex löschen, indem Sie den Primärschlüssel löschen. Wir haben bereits gesehen, dass ein Sekundärindex von einem Primärindex abhängt. Wenn Sie also einen Primärindex löschen, müssen alle Sekundärindizes aktualisiert werden, damit sie eine Kopie des neuen Primärindexschlüssels enthalten, den MySQL automatisch anpasst.
Dieser Prozess ist aufwendig, wenn mehrere Sekundärindizes vorhanden sind. Auch andere Tabellen können eine Fremdschlüsselreferenz zum Primärschlüssel haben, also müssen Sie diese Fremdschlüsselreferenzen löschen, bevor Sie den Primärschlüssel löschen.
Wenn ein Primärschlüssel gelöscht wird, erstellt MySQL intern automatisch einen weiteren Primärschlüssel, und das ist eine kostspielige Operation.
EINZIGARTIGER Schlüsselindex:
Wie Primärschlüssel können auch eindeutige Schlüssel Datensätze eindeutig identifizieren, mit einem Unterschied – die eindeutige Schlüsselspalte kann null enthalten Werte.
Im Gegensatz zu anderen Datenbankservern kann eine eindeutige Schlüsselspalte in MySQL beliebig viele null enthalten Werte wie möglich. Im SQL-Standard null bedeutet einen undefinierten Wert. Also wenn MySQL nur einen null enthalten muss Wert in einer eindeutigen Schlüsselspalte, muss davon ausgegangen werden, dass alle Nullwerte gleich sind.
Aber logischerweise ist das nicht korrekt, da null bedeutet undefiniert – und undefinierte Werte können nicht miteinander verglichen werden, das liegt in der Natur von null . Da MySQL nicht behaupten kann, ob alle null sind s bedeuten dasselbe, es erlaubt mehrere null Werte in der Spalte.
Der folgende Befehl zeigt, wie Sie einen eindeutigen Schlüsselindex in MySQL erstellen:
CREATE UNIQUE INDEX unique_idx_1 ON index_demo (pan_no);
Zusammengesetzter Index:
Mit MySQL können Sie Indizes für mehrere Spalten definieren, bis zu 16 Spalten. Dieser Index wird als mehrspaltiger / zusammengesetzter / zusammengesetzter Index bezeichnet.
Nehmen wir an, wir haben einen Index, der auf 4 Spalten definiert ist – col1 , col2 , col3 , col4 . Mit einem zusammengesetzten Index haben wir eine Suchfunktion für col1 , (col1, col2) , (col1, col2, col3) , (col1, col2, col3, col4) . Wir können also ein beliebiges Präfix auf der linken Seite der indizierten Spalten verwenden, aber wir können keine Spalte aus der Mitte weglassen und diese wie folgt verwenden:(col1, col3) oder (col1, col2, col4) oder col3 oder col4 usw. Dies sind ungültige Kombinationen.
Die folgenden Befehle erstellen zwei zusammengesetzte Indizes in unserer Tabelle:
CREATE INDEX composite_index_1 ON index_demo (phone_no, name, age);
CREATE INDEX composite_index_2 ON index_demo (pan_no, name, age);
Wenn Sie Abfragen haben, die ein WHERE enthalten Klausel auf mehrere Spalten schreiben Sie die Klausel in der Reihenfolge der Spalten des zusammengesetzten Indexes. Der Index kommt dieser Abfrage zugute. Tatsächlich können Sie beim Festlegen der Spalten für einen zusammengesetzten Index verschiedene Anwendungsfälle Ihres Systems analysieren und versuchen, die Reihenfolge der Spalten zu finden, die den meisten Ihrer Anwendungsfälle zugute kommt.
Zusammengesetzte Indizes können Ihnen beim JOIN helfen &SELECT auch Anfragen. Beispiel:im Folgenden SELECT * Abfrage, composite_index_2 verwendet wird.

Wenn mehrere Indizes definiert sind, wählt der MySQL-Abfrageoptimierer den Index aus, der die meisten Zeilen eliminiert oder so wenige Zeilen wie möglich durchsucht, um die Effizienz zu verbessern.
Warum verwenden wir zusammengesetzte Indizes ? Warum nicht mehrere Sekundärindizes für die Spalten definieren, an denen wir interessiert sind?
MySQL verwendet nur einen Index pro Tabelle und Abfrage, mit Ausnahme von UNION. (In einer UNION wird jede logische Abfrage separat ausgeführt und die Ergebnisse werden zusammengeführt.) Das Definieren mehrerer Indizes für mehrere Spalten garantiert also nicht, dass diese Indizes verwendet werden, selbst wenn sie Teil der Abfrage sind.
MySQL verwaltet sogenannte Indexstatistiken, die MySQL dabei helfen, abzuleiten, wie die Daten im System aussehen. Die Indexstatistik ist zwar eine Verallgemeinerung, aber basierend auf diesen Metadaten entscheidet MySQL, welcher Index für die aktuelle Abfrage geeignet ist.
Wie funktioniert der zusammengesetzte Index?
Die in zusammengesetzten Indizes verwendeten Spalten werden miteinander verkettet, und diese verketteten Schlüssel werden mithilfe eines B+-Baums in sortierter Reihenfolge gespeichert. Wenn Sie eine Suche durchführen, wird die Verkettung Ihrer Suchschlüssel mit denen des zusammengesetzten Index abgeglichen. Wenn es dann eine Diskrepanz zwischen der Reihenfolge Ihrer Suchschlüssel und der Reihenfolge der zusammengesetzten Indexspalten gibt, kann der Index nicht verwendet werden.
In unserem Beispiel wird für den folgenden Datensatz ein zusammengesetzter Indexschlüssel durch Verketten von pan_no gebildet , name , age — HJKXS9086Wkousik28 .
+--------+------+------------+------------+
name
age
pan_no
phone_no
+--------+------+------------+------------+
kousik
28
HJKXS9086W
9090909090So erkennen Sie, ob Sie einen zusammengesetzten Index benötigen:
- Analysieren Sie Ihre Abfragen zuerst gemäß Ihren Anwendungsfällen. Wenn Sie feststellen, dass bestimmte Felder in vielen Abfragen zusammen angezeigt werden, sollten Sie erwägen, einen zusammengesetzten Index zu erstellen.
- Wenn Sie einen Index in
col1erstellen &einen zusammengesetzten Index in (col1,col2), dann sollte nur der zusammengesetzte Index in Ordnung sein.col1allein kann vom zusammengesetzten Index selbst bedient werden, da es sich um ein Präfix auf der linken Seite des Indexes handelt. - Berücksichtigen Sie die Kardinalität. Wenn Spalten, die im zusammengesetzten Index verwendet werden, zusammen eine hohe Kardinalität aufweisen, sind sie gute Kandidaten für den zusammengesetzten Index.
Abdeckungsindex:
Ein abdeckender Index ist eine besondere Art von zusammengesetztem Index, bei dem alle in der Abfrage angegebenen Spalten irgendwo im Index vorhanden sind. Der Abfrageoptimierer muss also nicht auf die Datenbank zugreifen, um die Daten abzurufen – er erhält das Ergebnis vielmehr aus dem Index selbst. Beispiel:Wir haben bereits einen zusammengesetzten Index für (pan_no, name, age) definiert , betrachten Sie also jetzt die folgende Abfrage:
SELECT age FROM index_demo WHERE pan_no = 'HJKXS9086W' AND name = 'kousik'
Die in SELECT erwähnten Spalten &WHERE Klauseln sind Teil des zusammengesetzten Index. In diesem Fall können wir also tatsächlich den Wert von age erhalten Spalte aus dem zusammengesetzten Index selbst. Mal sehen, was der EXPLAIN Befehl zeigt für diese Abfrage:
EXPLAIN FORMAT=JSON SELECT age FROM index_demo WHERE pan_no = 'HJKXS9086W' AND name = '111kousik1';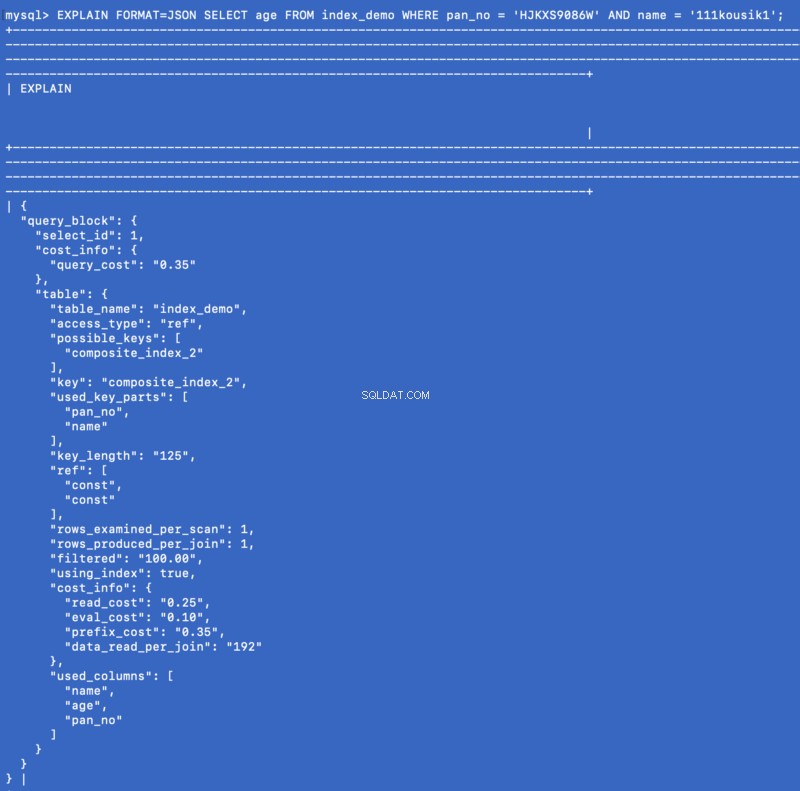
Beachten Sie, dass es in der obigen Antwort einen Schlüssel gibt – using_index die auf true gesetzt ist was bedeutet, dass der abdeckende Index verwendet wurde, um die Abfrage zu beantworten.
Ich weiß nicht, wie sehr abdeckende Indizes in Produktionsumgebungen geschätzt werden, aber anscheinend scheint es eine gute Optimierung zu sein, falls die Abfrage die Rechnung erfüllt.
Teilindex:
Wir wissen bereits, dass Indizes unsere Abfragen auf Kosten des Speicherplatzes beschleunigen. Je mehr Indizes Sie haben, desto größer ist der Speicherbedarf. Wir haben bereits einen Index namens secondary_idx_1 erstellt in der Spalte name . Die Spalte name kann große Werte beliebiger Länge enthalten. Auch im Index haben die Metadaten der Zeilenlokatoren oder Zeilenzeiger ihre eigene Größe. Insgesamt kann ein Index also eine hohe Speicher- und Arbeitsspeicherlast haben.
In MySQL ist es auch möglich, einen Index für die ersten Datenbytes zu erstellen. Beispiel:Der folgende Befehl erstellt einen Index für die ersten 4 Bytes des Namens. Obwohl diese Methode den Speicheraufwand um einen bestimmten Betrag reduziert, kann der Index nicht viele Zeilen eliminieren, da in diesem Beispiel die ersten 4 Bytes für viele Namen gleich sein können. Normalerweise wird diese Art der Präfixindizierung auf CHAR unterstützt ,VARCHAR , BINARY , VARBINARY Art der Spalten.
CREATE INDEX secondary_index_1 ON index_demo (name(4));Was passiert unter der Haube, wenn wir einen Index definieren?
Lassen Sie uns SHOW EXTENDED ausführen Befehl erneut:
SHOW EXTENDED INDEXES FROM index_demo;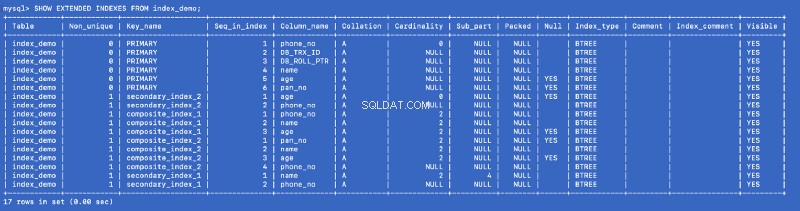
Wir haben secondary_index_1 definiert auf name , aber MySQL hat einen zusammengesetzten Index für (name , phone_no ) wobei phone_no ist die Primärschlüsselspalte. Wir haben secondary_index_2 erstellt auf age &MySQL erstellte einen zusammengesetzten Index am (age , phone_no ). Wir haben composite_index_2 erstellt auf (pan_no , name , age ) &MySQL hat einen zusammengesetzten Index erstellt auf (pan_no , name , age , phone_no ). Der zusammengesetzte Index composite_index_1 hat bereits phone_no als Teil davon.
Unabhängig davon, welchen Index wir erstellen, erstellt MySQL im Hintergrund einen unterstützenden zusammengesetzten Index, der wiederum auf den Primärschlüssel verweist. Das bedeutet, dass der Primärschlüssel ein erstklassiger Bürger in der Welt der MySQL-Indizierung ist. It also proves that all the indexes are backed by a copy of the primary index —but I am not sure whether a single copy of the primary index is shared or different copies are used for different indexes.
There are many other indices as well like Spatial index and Full Text Search index offered by MySQL. I have not yet experimented with those indices, so I’m not discussing them in this post.
General Indexing guidelines:
- Since indices consume extra memory, carefully decide how many &what type of index will suffice your need.
- With
DMLoperations, indices are updated, so write operations are quite costly with indexes. The more indices you have, the greater the cost. Indexes are used to make read operations faster. So if you have a system that is write heavy but not read heavy, think hard about whether you need an index or not. - Cardinality is important — cardinality means the number of distinct values in a column. If you create an index in a column that has low cardinality, that’s not going to be beneficial since the index should reduce search space. Low cardinality does not significantly reduce search space.
Example:if you create an index on a boolean (int1or0only ) type column, the index will be very skewed since cardinality is less (cardinality is 2 here). But if this boolean field can be combined with other columns to produce high cardinality, go for that index when necessary. - Indices might need some maintenance as well if old data still remains in the index. They need to be deleted otherwise memory will be hogged, so try to have a monitoring plan for your indices.
In the end, it’s extremely important to understand the different aspects of database indexing. It will help while doing low level system designing. Many real-life optimizations of our applications depend on knowledge of such intricate details. A carefully chosen index will surely help you boost up your application’s performance.
Please do clap &share with your friends &on social media if you like this article. :)
References:
- https://dev.mysql.com/doc/refman/5.7/en/innodb-index-types.html
- https://www.quora.com/What-is-difference-between-primary-index-and-secondary-index-exactly-And-whats-advantage-of-one-over-another
- https://dev.mysql.com/doc/refman/8.0/en/create-index.html
- https://www.oreilly.com/library/view/high-performance-mysql/0596003064/ch04.html
- https://www.unofficialmysqlguide.com/covering-indexes.html
- https://dev.mysql.com/doc/refman/8.0/en/multiple-column-indexes.html
- https://dev.mysql.com/doc/refman/8.0/en/show-index.html
- https://dev.mysql.com/doc/refman/8.0/en/create-index.html