Willkommen zum dritten – und letzten – Teil dieser Blogserie, in dem untersucht wird, wie sich die Leistung von PostgreSQL im Laufe der Jahre entwickelt hat. Der erste Teil befasste sich mit OLTP-Workloads, dargestellt durch pgbench-Tests. Der zweite Teil befasste sich mit analytischen / BI-Abfragen, wobei eine Teilmenge des traditionellen TPC-H-Benchmarks (im Wesentlichen ein Teil des Leistungstests) verwendet wurde.
Und dieser letzte Teil befasst sich mit der Volltextsuche, d. h. der Möglichkeit, große Mengen von Textdaten zu indizieren und zu durchsuchen. Dieselbe Infrastruktur (insbesondere die Indizes) kann nützlich sein, um halbstrukturierte Daten wie JSONB-Dokumente usw. zu indizieren, aber darauf konzentriert sich dieser Benchmark nicht.
Aber lassen Sie uns zuerst einen Blick auf die Geschichte der Volltextsuche in PostgreSQL werfen, was wie eine seltsame Funktion erscheinen mag, die man einem RDBMS hinzufügen kann, das traditionell zum Speichern strukturierter Daten in Zeilen und Spalten gedacht ist.
Die Geschichte der Volltextsuche
Als Postgres 1996 Open Source wurde, hatte es nichts, was wir Volltextsuche nennen könnten. Aber Leute, die anfingen, Postgres zu verwenden, wollten intelligente Suchen in Textdokumenten durchführen, und die LIKE-Abfragen waren nicht gut genug. Sie wollten in der Lage sein, die Begriffe mithilfe von Wörterbüchern zu lemmatisieren, Stoppwörter zu ignorieren, die übereinstimmenden Dokumente nach Relevanz zu sortieren, Indizes zu verwenden, um diese Abfragen auszuführen, und vieles mehr. Dinge, die Sie mit den herkömmlichen SQL-Operatoren nicht vernünftigerweise tun können.
Glücklicherweise waren einige dieser Leute auch Entwickler, also begannen sie, daran zu arbeiten – und sie konnten, dank PostgreSQL, das auf der ganzen Welt als Open Source verfügbar ist. Im Laufe der Jahre haben viele an der Volltextsuche mitgewirkt, aber ursprünglich wurden diese Bemühungen von Oleg Bartunov und Teodor Sigaev geleitet, wie auf dem folgenden Foto zu sehen ist. Beide sind immer noch wichtige PostgreSQL-Beitragende und arbeiten an Volltextsuche, Indizierung, JSON-Unterstützung und vielen anderen Funktionen.

Teodor Sigaev und Oleg Bartunov
Ursprünglich wurde die Funktionalität als externes „contrib“-Modul (heute würden wir sagen, es ist eine Erweiterung) namens „tsearch“ entwickelt, das 2002 veröffentlicht wurde. Später wurde dies durch tsearch2 obsolet, wodurch die Funktion in vielerlei Hinsicht erheblich verbessert wurde, und in PostgreSQL 8.3 (veröffentlicht 2008) war dies vollständig in den PostgreSQL-Kern integriert (d. h. ohne dass überhaupt eine Erweiterung installiert werden musste, obwohl die Erweiterungen weiterhin für die Abwärtskompatibilität bereitgestellt wurden).
Seitdem gab es viele Verbesserungen (und die Arbeit geht weiter, z. B. um Datentypen wie JSONB zu unterstützen, Abfragen mit jsonpath usw.). aber diese Plugins führten die meisten Volltextfunktionen ein, die wir jetzt in PostgreSQL haben – Wörterbücher, Volltextindizierungs- und Abfragefunktionen usw.
Der Maßstab
Im Gegensatz zu den OLTP/TPC-H-Benchmarks ist mir kein Volltext-Benchmark bekannt, der als „Industriestandard“ gelten oder für mehrere Datenbanksysteme ausgelegt sein könnte. Die meisten Benchmarks, die ich kenne, sind für die Verwendung mit einer einzelnen Datenbank / einem einzelnen Produkt gedacht, und es ist schwierig, sie sinnvoll zu portieren, also musste ich einen anderen Weg einschlagen und meinen eigenen Volltext-Benchmark schreiben.
Vor Jahren habe ich Archie geschrieben – ein paar Python-Skripte, die das Herunterladen von PostgreSQL-Mailinglistenarchiven ermöglichen und die geparsten Nachrichten in eine PostgreSQL-Datenbank laden, die dann indiziert und durchsucht werden kann. Der aktuelle Snapshot aller Archive hat ~1 Mio. Zeilen, und nach dem Laden in eine Datenbank ist die Tabelle ungefähr 9,5 GB groß (die Indizes nicht mitgezählt).
Was die Abfragen betrifft, könnte ich wahrscheinlich einige zufällige generieren, aber ich bin mir nicht sicher, wie realistisch das wäre. Glücklicherweise habe ich vor ein paar Jahren eine Stichprobe von 33.000 tatsächlichen Suchanfragen von der PostgreSQL-Website erhalten (d. h. Dinge, nach denen die Leute tatsächlich in den Community-Archiven gesucht haben). Es ist unwahrscheinlich, dass ich etwas Realistischeres/Repräsentativeres bekommen könnte.
Die Kombination dieser beiden Teile (Datensatz + Abfragen) scheint ein guter Benchmark zu sein. Wir können die Daten einfach laden und die Suche mit verschiedenen Arten von Volltextabfragen mit verschiedenen Arten von Indizes ausführen.
Abfragen
Es gibt verschiedene Formen von Volltextabfragen – die Abfrage kann einfach alle übereinstimmenden Zeilen auswählen, sie kann die Ergebnisse ordnen (sie nach Relevanz sortieren), nur eine kleine Anzahl oder die relevantesten Ergebnisse zurückgeben usw. Ich habe Benchmarks mit verschiedenen ausgeführt Arten von Abfragen, aber in diesem Beitrag werde ich Ergebnisse für zwei einfache Abfragen präsentieren, die meiner Meinung nach das Gesamtverhalten recht gut darstellen.
- ID, Betreff FROM Nachrichten WÄHLEN, WHERE body_tsvector @@ $1
- SELECT id, subject FROM messages WHERE body_tsvector @@ $1
ORDER BY ts_rank(body_tsvector, $1) DESC LIMIT 100
Die erste Abfrage gibt einfach alle übereinstimmenden Zeilen zurück, während die zweite die 100 relevantesten Ergebnisse zurückgibt (dies ist etwas, das Sie wahrscheinlich für Benutzersuchen verwenden würden).
Ich habe mit verschiedenen anderen Abfragetypen experimentiert, aber alle verhielten sich letztendlich ähnlich wie einer dieser beiden Abfragetypen.
Indizes
Jede Nachricht hat zwei Hauptteile, in denen wir suchen können – Betreff und Text. Jeder von ihnen hat eine separate tsvector-Spalte und wird separat indiziert. Die Nachrichtenbetreffs sind viel kürzer als die Nachrichtentexte, daher sind die Indizes natürlich kleiner.
PostgreSQL hat zwei Arten von Indizes, die für die Volltextsuche nützlich sind – GIN und GiST. Die Hauptunterschiede werden in der Dokumentation erklärt, aber kurz gesagt:
- GIN-Indizes sind schneller für Suchen
- GiST-Indizes sind verlustbehaftet, d. h. erfordern eine erneute Überprüfung während der Suche (und sind daher langsamer)
Früher behaupteten wir, GiST-Indizes seien billiger zu aktualisieren (insbesondere bei vielen gleichzeitigen Sitzungen), aber dies wurde vor einiger Zeit aufgrund von Verbesserungen im Indexierungscode aus der Dokumentation entfernt.
Dieser Benchmark testet das Verhalten bei Aktualisierungen nicht – er lädt einfach die Tabelle ohne die Volltextindizes, baut sie auf einmal auf und führt dann die 33.000 Abfragen für die Daten aus. Das bedeutet, dass ich keine Aussagen darüber machen kann, wie diese Indextypen gleichzeitige Aktualisierungen auf der Grundlage dieses Benchmarks handhaben, aber ich glaube, dass die Änderungen in der Dokumentation verschiedene aktuelle GIN-Verbesserungen widerspiegeln.
Dies sollte auch recht gut zum Anwendungsfall des Mailinglistenarchivs passen, bei dem wir nur ab und zu neue E-Mails anhängen würden (wenige Updates, fast keine Schreibparallelität). Wenn Ihre Anwendung jedoch viele gleichzeitige Updates durchführt, müssen Sie dies selbst bewerten.
Die Hardware
Ich habe den Benchmark auf denselben beiden Maschinen wie zuvor durchgeführt, aber die Ergebnisse/Schlussfolgerungen sind nahezu identisch, daher präsentiere ich nur die Zahlen der kleineren, d. h.
- CPU i5-2500K (4 Kerne/Threads)
- 8 GB Arbeitsspeicher
- 6 x 100 GB SSD RAID0
- Kernel 5.6.15, ext4-Dateisystem
Ich habe bereits erwähnt, dass der Datensatz beim Laden fast 10 GB hat, also größer als RAM ist. Aber die Indizes sind immer noch kleiner als RAM, worauf es beim Benchmark ankommt.
Ergebnisse
OK, Zeit für ein paar Zahlen und Diagramme. Ich werde Ergebnisse sowohl für das Laden von Daten als auch für Abfragen präsentieren, zuerst mit GIN- und dann mit GiST-Indizes.
GIN / Daten laden
Die Belastung ist nicht besonders interessant, finde ich. Erstens hat das meiste davon (der blaue Teil) nichts mit Volltext zu tun, weil es passiert, bevor die beiden Indizes erstellt werden. Die meiste Zeit wird damit verbracht, die Nachrichten zu analysieren, die Mail-Threads neu aufzubauen, die Liste der Antworten zu pflegen und so weiter. Ein Teil dieses Codes ist in PL/pgSQL-Triggern implementiert, ein Teil davon außerhalb der Datenbank. Der einzige Teil, der möglicherweise für den Volltext relevant ist, ist das Erstellen der ts-Vektoren, aber es ist unmöglich, die dafür aufgewendete Zeit zu isolieren.
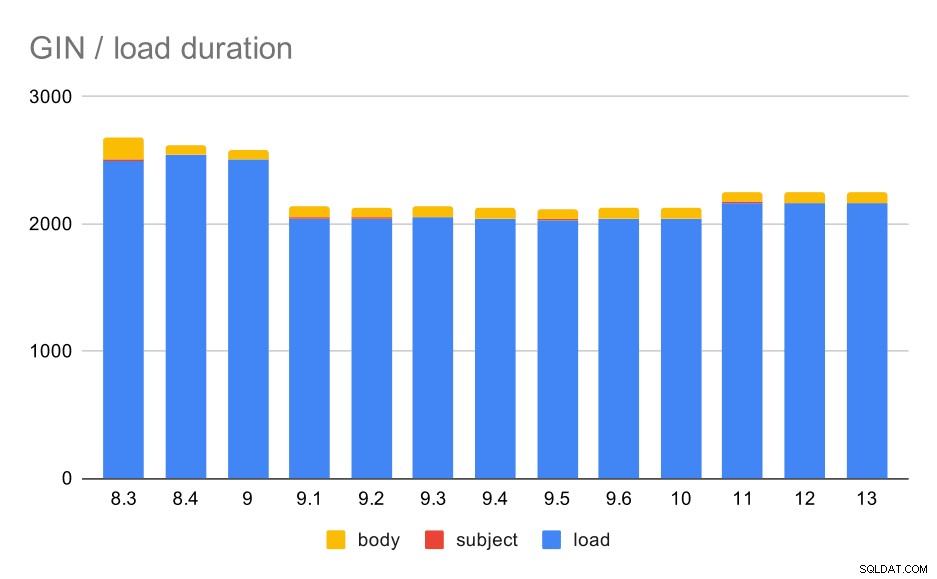
Datenladevorgänge mit einer Tabelle und GIN-Indizes.
Die folgende Tabelle zeigt die Quelldaten für dieses Diagramm – Werte sind Dauer in Sekunden. LOAD umfasst das Parsen der mbox-Archive (aus einem Python-Skript), das Einfügen in eine Tabelle und verschiedene zusätzliche Aufgaben (Neuaufbau von E-Mail-Threads usw.). Der SUBJECT/BODY INDEX bezieht sich auf die Erstellung des Volltext-GIN-Index für die Betreff-/Textspalten, nachdem die Daten geladen wurden.
| LADEN | THEMENINDEX | KÖRPERINDEX | |
| 8,3 | 2501 | 8 | 173 |
| 8.4 | 2540 | 4 | 78 |
| 9.0 | 2502 | 4 | 75 |
| 9.1 | 2046 | 4 | 84 |
| 9.2 | 2045 | 3 | 85 |
| 9.3 | 2049 | 4 | 85 |
| 9.4 | 2043 | 4 | 85 |
| 9.5 | 2034 | 4 | 82 |
| 9.6 | 2039 | 4 | 81 |
| 10 | 2037 | 4 | 82 |
| 11 | 2169 | 4 | 82 |
| 12 | 2164 | 4 | 79 |
| 13 | 2164 | 4 | 81 |
Die Leistung ist eindeutig ziemlich stabil – zwischen 9,0 und 9,1 gab es eine ziemlich deutliche Verbesserung (ungefähr 20 %). Ich bin mir nicht ganz sicher, welche Änderung für diese Verbesserung verantwortlich sein könnte – nichts in den 9.1-Versionshinweisen scheint eindeutig relevant zu sein. Es gibt auch eine deutliche Verbesserung beim Erstellen der GIN-Indizes in 8.4, was die Zeit etwa halbiert. Was natürlich schön ist. Interessanterweise sehe ich dafür auch keine offensichtlich verwandten Versionshinweise.
Was ist jedoch mit den Größen der GIN-Indizes? Es gibt viel mehr Variabilität, zumindest bis 9.4, an diesem Punkt sinkt die Größe der Indizes von ~1 GB auf nur etwa 670 MB (ungefähr 30 %).
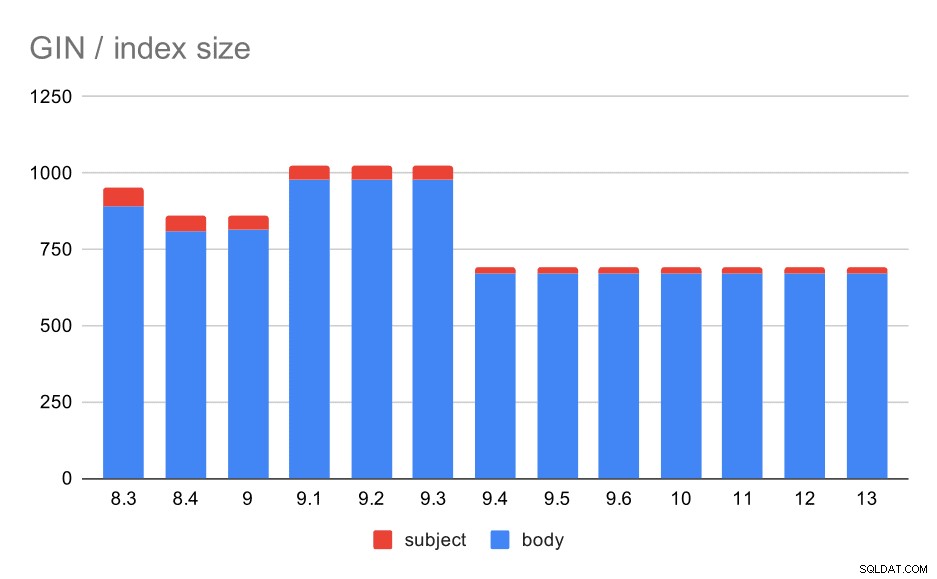
Größe der GIN-Indizes im Betreff/Text der Nachricht. Werte sind Megabyte.
Die folgende Tabelle zeigt die Größen von GIN-Indizes für Nachrichtentext und Betreff. Die Werte sind in Megabyte angegeben.
| BODY | BETREFF | |
| 8.3 | 890 | 62 |
| 8.4 | 811 | 47 |
| 9.0 | 813 | 47 |
| 9.1 | 977 | 47 |
| 9.2 | 978 | 47 |
| 9.3 | 977 | 47 |
| 9.4 | 671 | 20 |
| 9.5 | 671 | 20 |
| 9.6 | 671 | 20 |
| 10 | 672 | 20 |
| 11 | 672 | 20 |
| 12 | 672 | 20 |
| 13 | 672 | 20 |
In diesem Fall können wir sicher davon ausgehen, dass diese Beschleunigung mit diesem Punkt in den Versionshinweisen zu 9.4 zusammenhängt:
- Größe des GIN-Index reduzieren (Alexander Korotkov, Heikki Linnakangas)
Die Größenvariabilität zwischen 8,3 und 9,1 scheint auf Änderungen in der Lemmatisierung zurückzuführen zu sein (wie Wörter in die „Grundform“ umgewandelt werden). Abgesehen von den Größenunterschieden geben die Abfragen in diesen Versionen beispielsweise etwas unterschiedliche Anzahlen von Ergebnissen zurück.
GIN / Abfragen
Nun zum Hauptteil dieses Benchmarks – der Abfrageleistung. Alle hier vorgestellten Zahlen beziehen sich auf einen einzelnen Client – wir haben die Client-Skalierbarkeit bereits im Abschnitt über die OLTP-Leistung besprochen, die Ergebnisse gelten auch für diese Abfragen. (Außerdem hat diese spezielle Maschine nur 4 Kerne, sodass wir in Bezug auf Skalierbarkeitstests sowieso nicht sehr weit kommen würden.)
SELECT id, subject FROM messages WHERE tsvector @@ $1
Zuerst die Suche nach allen passenden Dokumenten. Für Suchen in der Spalte „Betreff“ können wir ungefähr 800 Abfragen pro Sekunde durchführen (und es fällt in 9.1 tatsächlich etwas ab), aber in 9.4 schießen sie plötzlich auf 3000 Abfragen pro Sekunde. Für die Spalte „Text“ ist es im Grunde dasselbe – anfänglich 160 Abfragen, ein Rückgang auf ~90 Abfragen in 9.1 und dann ein Anstieg auf 300 in 9.4.
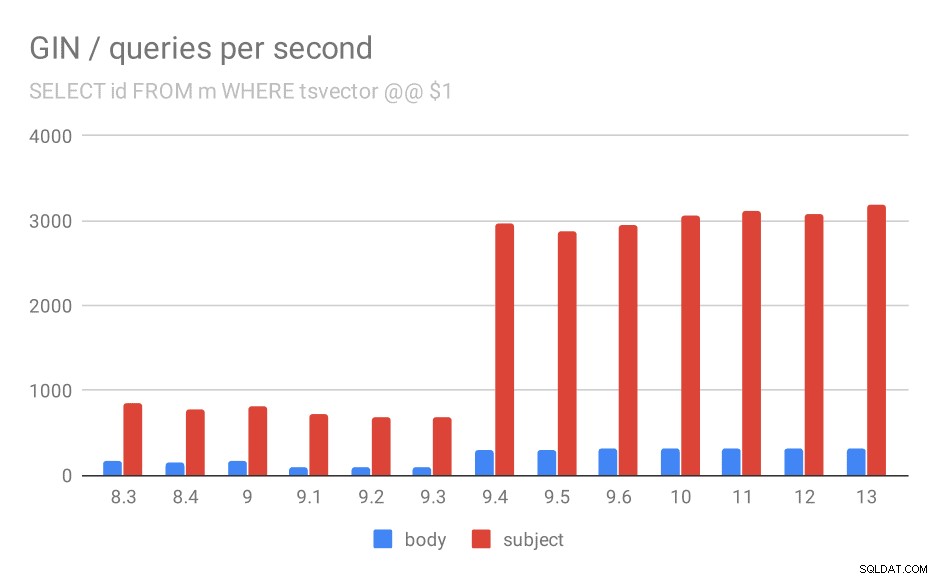
Anzahl der Abfragen pro Sekunde für die erste Abfrage (Abrufen aller übereinstimmenden Zeilen).
Und wieder die Quelldaten – die Zahlen sind der Durchsatz (Abfragen pro Sekunde).
| BODY | BETREFF | |
| 8.3 | 168 | 848 |
| 8.4 | 155 | 774 |
| 9.0 | 160 | 816 |
| 9.1 | 93 | 712 |
| 9.2 | 93 | 675 |
| 9.3 | 95 | 692 |
| 9.4 | 303 | 2966 |
| 9.5 | 303 | 2871 |
| 9.6 | 310 | 2942 |
| 10 | 311 | 3066 |
| 11 | 317 | 3121 |
| 12 | 312 | 3085 |
| 13 | 320 | 3192 |
Ich denke, wir können davon ausgehen, dass die Verbesserung in 9.4 mit diesem Punkt in den Versionshinweisen zusammenhängt:
- Verbessern Sie die Geschwindigkeit von GIN-Lookups mit mehreren Schlüsseln (Alexander Korotkov, Heikki Linnakangas)
Also, eine weitere 9.4-Verbesserung in GIN von denselben zwei Entwicklern – Alexander und Heikki haben in der 9.4-Version eindeutig viel gute Arbeit an GIN-Indizes geleistet 😉
SELECT id, subject FROM messages WHERE tsvector @@ $1
ORDER BY ts_rank(tsvector, $2) DESC LIMIT 100
Für die Abfrage, die die Ergebnisse nach Relevanz mit ts_rank und LIMIT ordnet, ist das Gesamtverhalten fast genau gleich, ich denke, es ist nicht nötig, das Diagramm im Detail zu beschreiben.
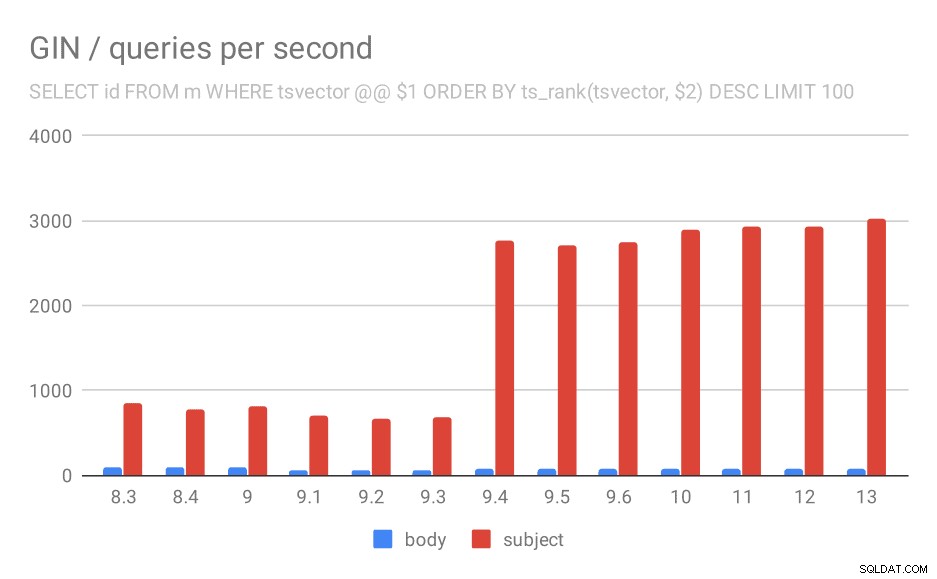
Anzahl der Abfragen pro Sekunde für die zweite Abfrage (Abrufen der relevantesten Zeilen).
| BODY | BETREFF | |
| 8.3 | 94 | 840 |
| 8.4 | 98 | 775 |
| 9.0 | 102 | 818 |
| 9.1 | 51 | 704 |
| 9.2 | 51 | 666 |
| 9.3 | 51 | 678 |
| 9.4 | 80 | 2766 |
| 9.5 | 81 | 2704 |
| 9.6 | 78 | 2750 |
| 10 | 78 | 2886 |
| 11 | 79 | 2938 |
| 12 | 78 | 2924 |
| 13 | 77 | 3028 |
Es gibt jedoch eine Frage:Warum ist die Leistung zwischen 9,0 und 9,1 gesunken? Es scheint einen ziemlich deutlichen Rückgang des Durchsatzes zu geben – um etwa 50 % bei der Körpersuche und um 20 % bei der Suche in Nachrichtenbetreffs. Ich habe keine klare Erklärung dafür, was passiert ist, aber ich habe zwei Beobachtungen …
Erstens hat sich die Indexgröße geändert – wenn Sie sich das erste Diagramm „GIN / Indexgröße“ und die Tabelle ansehen, sehen Sie, dass der Index für Nachrichtentexte von 813 MB auf etwa 977 MB gewachsen ist. Das ist ein deutlicher Anstieg und könnte einen Teil der Verlangsamung erklären. Das Problem ist jedoch, dass der Themenindex überhaupt nicht gewachsen ist, aber die Abfragen auch langsamer geworden sind.
Zweitens können wir uns ansehen, wie viele Ergebnisse die Abfragen zurückgegeben haben. Der indizierte Datensatz ist genau derselbe, also scheint es vernünftig, die gleiche Anzahl von Ergebnissen in allen PostgreSQL-Versionen zu erwarten, richtig? Nun, in der Praxis sieht es so aus:
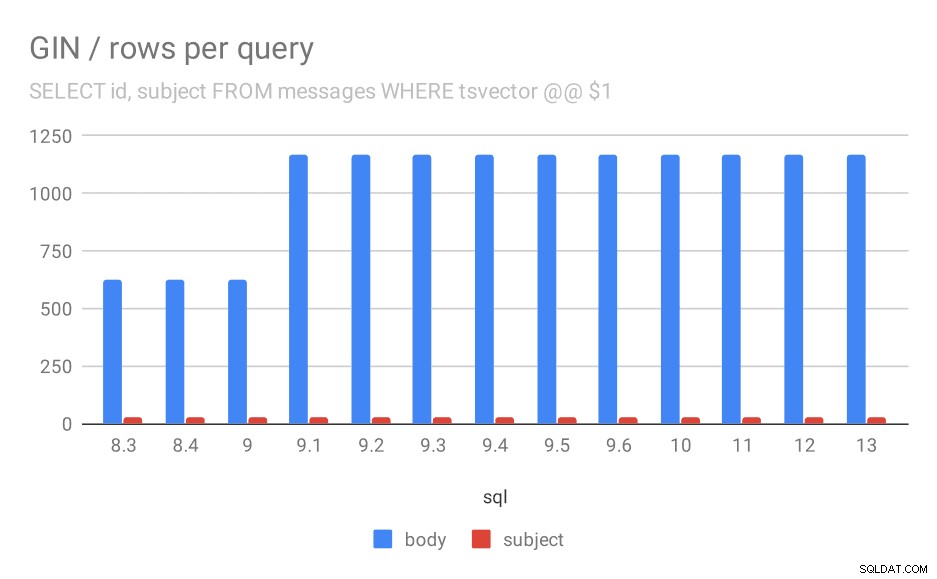
Anzahl der durchschnittlich für eine Abfrage zurückgegebenen Zeilen.
| BODY | BETREFF | |
| 8.3 | 624 | 26 |
| 8.4 | 624 | 26 |
| 9.0 | 622 | 26 |
| 9.1 | 1165 | 26 |
| 9.2 | 1165 | 26 |
| 9.3 | 1165 | 26 |
| 9.4 | 1165 | 26 |
| 9.5 | 1165 | 26 |
| 9.6 | 1165 | 26 |
| 10 | 1165 | 26 |
| 11 | 1165 | 26 |
| 12 | 1165 | 26 |
| 13 | 1165 | 26 |
Offensichtlich verdoppelt sich in 9.1 die durchschnittliche Anzahl der Ergebnisse für Suchen in Nachrichtentexten plötzlich, was fast perfekt proportional zur Verlangsamung ist. Die Anzahl der Ergebnisse für die Themensuche bleibt jedoch gleich. Ich habe keine sehr gute Erklärung dafür, außer dass sich die Indizierung so geändert hat, dass sie mehr Nachrichten zuordnen kann, aber etwas langsamer wird. Wenn Sie bessere Erklärungen haben, würde ich sie gerne hören!
GiST / Daten laden
Nun, die andere Art von Volltextindizes – GiST. Diese Indizes sind verlustbehaftet, d. h. erfordern eine erneute Überprüfung der Ergebnisse unter Verwendung von Werten aus der Tabelle. Daher können wir im Vergleich zu den GIN-Indizes einen geringeren Durchsatz erwarten, aber ansonsten ist es vernünftig, ungefähr das gleiche Muster zu erwarten.
Die Ladezeiten stimmen tatsächlich fast perfekt mit dem GIN überein – die Indexerstellungszeiten sind unterschiedlich, aber das Gesamtmuster ist das gleiche. Beschleunigung in 9.1, kleine Verlangsamung in 11.
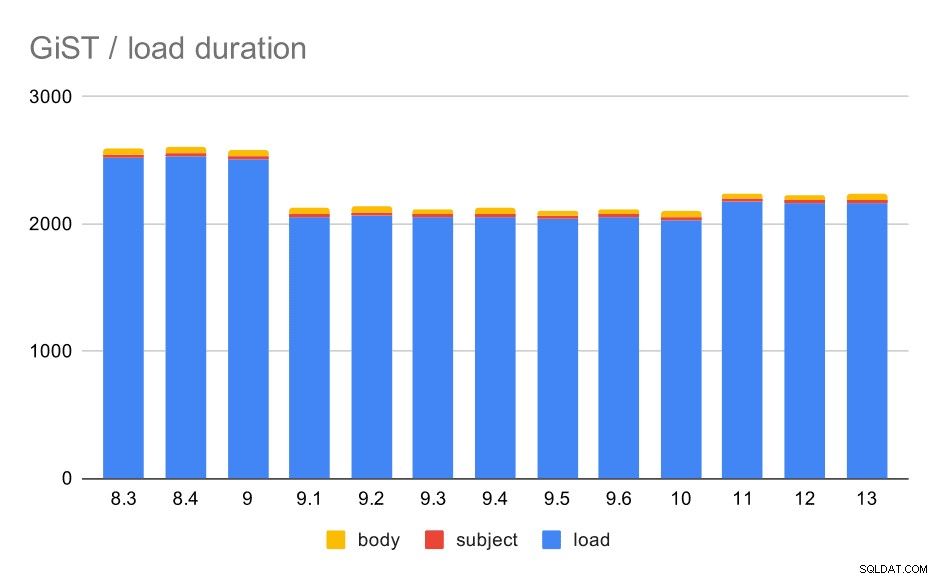
Datenladevorgänge mit einer Tabelle und GiST-Indizes.
| LADEN | BETREFF | BODY | |
| 8.3 | 2522 | 23 | 47 |
| 8.4 | 2527 | 23 | 49 |
| 9.0 | 2511 | 23 | 45 |
| 9.1 | 2054 | 22 | 46 |
| 9.2 | 2067 | 22 | 47 |
| 9.3 | 2049 | 23 | 46 |
| 9.4 | 2055 | 23 | 47 |
| 9.5 | 2038 | 22 | 45 |
| 9.6 | 2052 | 22 | 44 |
| 10 | 2029 | 22 | 49 |
| 11 | 2174 | 22 | 46 |
| 12 | 2162 | 22 | 46 |
| 13 | 2170 | 22 | 44 |
Die Indexgröße blieb jedoch nahezu konstant – es gab keine GiST-Verbesserungen ähnlich wie bei GIN in 9.4, wodurch die Größe um ~30 % reduziert wurde. Es gibt einen Anstieg in 9.1, was ein weiteres Zeichen dafür ist, dass die Volltextindizierung in dieser Version geändert wurde, um mehr Wörter zu indizieren.
Dies wird weiter dadurch unterstützt, dass die durchschnittliche Anzahl der Ergebnisse bei GiST genau gleich ist wie bei GIN (mit einem Anstieg um 9,1).
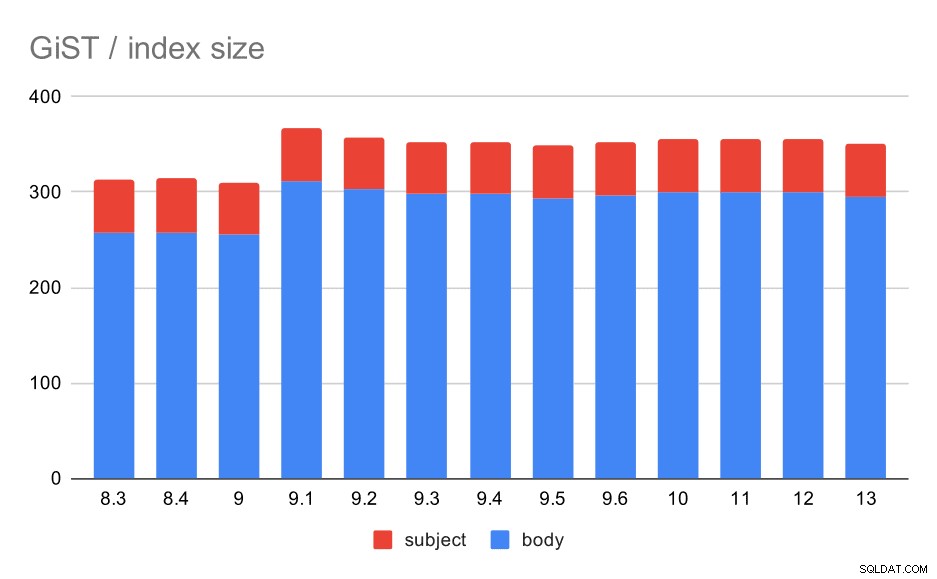
Größe der GiST-Indizes im Betreff/Text der Nachricht. Werte sind Megabyte.
| BODY | BETREFF | |
| 8.3 | 257 | 56 |
| 8.4 | 258 | 56 |
| 9.0 | 255 | 55 |
| 9.1 | 312 | 55 |
| 9.2 | 303 | 55 |
| 9.3 | 298 | 55 |
| 9.4 | 298 | 55 |
| 9.5 | 294 | 55 |
| 9.6 | 297 | 55 |
| 10 | 300 | 55 |
| 11 | 300 | 55 |
| 12 | 300 | 55 |
| 13 | 295 | 55 |
GiST / queries
Unfortunately, for the queries the results are nowhere as good as for GIN, where the throughput more than tripled in 9.4. With GiST indexes, we actually observe continuous degradation over the time.
SELECT id, subject FROM messages WHERE tsvector @@ $1
Even if we ignore versions before 9.1 (due to the indexes being smaller and returning fewer results faster), the throughput drops from ~270 to ~200 queries per second, with the main drop between 9.2 and 9.3.
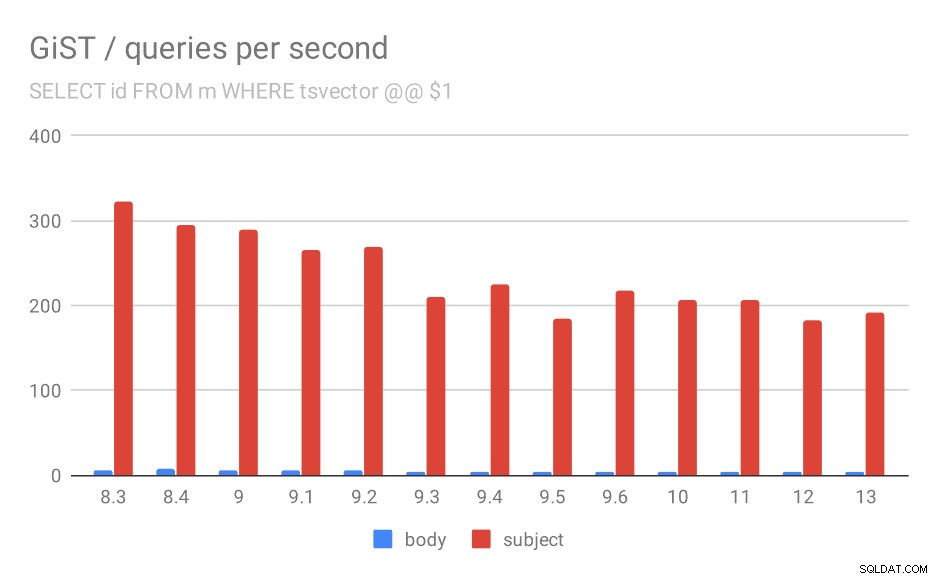
Number of queries per second for the first query (fetching all matching rows).
| BODY | SUBJECT | |
| 8.3 | 5 | 322 |
| 8.4 | 7 | 295 |
| 9.0 | 6 | 290 |
| 9.1 | 5 | 265 |
| 9.2 | 5 | 269 |
| 9.3 | 4 | 211 |
| 9.4 | 4 | 225 |
| 9.5 | 4 | 185 |
| 9.6 | 4 | 217 |
| 10 | 4 | 206 |
| 11 | 4 | 206 |
| 12 | 4 | 183 |
| 13 | 4 | 191 |
SELECT id, subject FROM messages WHERE tsvector @@ $1
ORDER BY ts_rank(tsvector, $2) DESC LIMIT 100
And for queries with ts_rank the behavior is almost exactly the same.
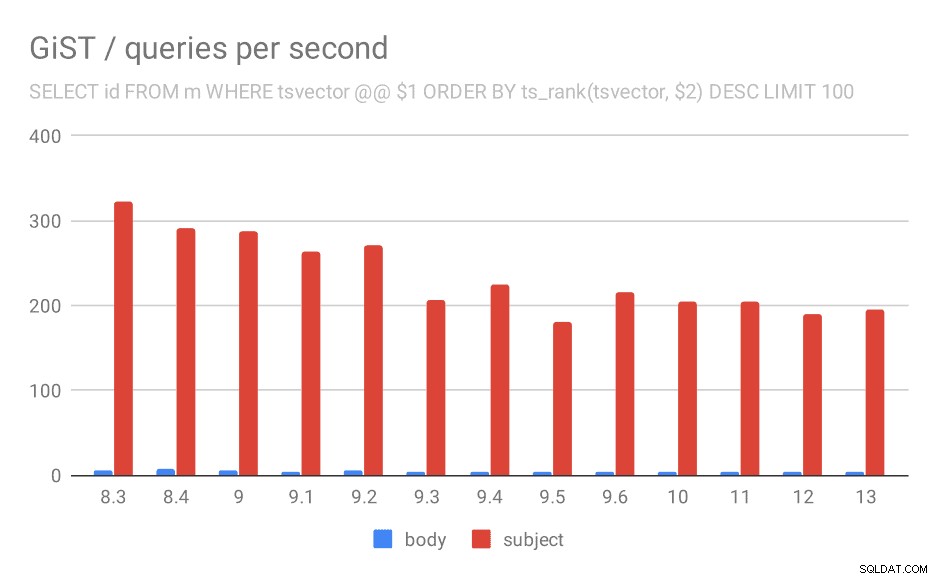
Number of queries per second for the second query (fetching the most relevant rows).
| BODY | SUBJECT | |
| 8.3 | 5 | 323 |
| 8.4 | 7 | 291 |
| 9.0 | 6 | 288 |
| 9.1 | 4 | 264 |
| 9.2 | 5 | 270 |
| 9.3 | 4 | 207 |
| 9.4 | 4 | 224 |
| 9.5 | 4 | 181 |
| 9.6 | 4 | 216 |
| 10 | 4 | 205 |
| 11 | 4 | 205 |
| 12 | 4 | 189 |
| 13 | 4 | 195 |
I’m not entirely sure what’s causing this, but it seems like a potentially serious regression sometime in the past, and it might be interesting to know what exactly changed.
It’s true no one complained about this until now – possibly thanks to upgrading to a faster hardware which masked the impact, or maybe because if you really care about speed of the searches you will prefer GIN indexes anyway.
But we can also see this as an optimization opportunity – if we identify what caused the regression and we manage to undo that, it might mean ~30% speedup for GiST indexes.
Summary and future
By now I’ve (hopefully) convinced you there were many significant improvements since PostgreSQL 8.3 (and in 9.4 in particular). I don’t know how much faster can this be made, but I hope we’ll investigate at least some of the regressions in GiST (even if performance-sensitive systems are likely using GIN). Oleg and Teodor and their colleagues were working on more powerful variants of the GIN indexing, named VODKA and RUM (I kinda see a naming pattern here!), and this will probably help at least some query types.
I do however expect to see features buil extending the existing full-text capabilities – either to better support new query types (e.g. the new index types are designed to speed up phrase search), data types and things introduced by recent revisions of the SQL standard (like jsonpath).