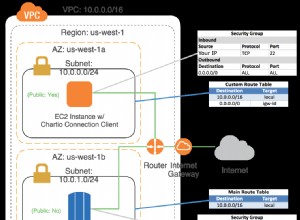
Stellen Sie sich Ihre Tabelle test vor enthält folgende Daten:
select id, email
from test;
ID EMAIL
---------------------- --------------------
1 aaa
2 bbb
3 ccc
4 bbb
5 ddd
6 eee
7 aaa
8 aaa
9 eee
Also müssen wir alle wiederholten E-Mails finden und alle löschen, außer der letzten ID.
In diesem Fall aaa , bbb und eee werden wiederholt, also möchten wir die IDs 1, 7, 2 und 6 löschen.
Um dies zu erreichen, müssen wir zuerst alle wiederholten E-Mails finden:
select email
from test
group by email
having count(*) > 1;
EMAIL
--------------------
aaa
bbb
eee
Dann müssen wir aus diesem Datensatz die neueste ID für jede dieser wiederholten E-Mails finden:
select max(id) as lastId, email
from test
where email in (
select email
from test
group by email
having count(*) > 1
)
group by email;
LASTID EMAIL
---------------------- --------------------
8 aaa
4 bbb
9 eee
Endlich können wir jetzt alle diese E-Mails mit einer kleineren ID als LASTID löschen. Die Lösung lautet also:
delete test
from test
inner join (
select max(id) as lastId, email
from test
where email in (
select email
from test
group by email
having count(*) > 1
)
group by email
) duplic on duplic.email = test.email
where test.id < duplic.lastId;
Ich habe mySql derzeit nicht auf diesem Rechner installiert, sollte aber funktionieren
Aktualisieren
Das obige Löschen funktioniert, aber ich habe eine optimiertere Version gefunden:
delete test
from test
inner join (
select max(id) as lastId, email
from test
group by email
having count(*) > 1) duplic on duplic.email = test.email
where test.id < duplic.lastId;
Sie können sehen, dass die ältesten Duplikate gelöscht werden, also 1, 7, 2, 6:
select * from test;
+----+-------+
| id | email |
+----+-------+
| 3 | ccc |
| 4 | bbb |
| 5 | ddd |
| 8 | aaa |
| 9 | eee |
+----+-------+
Eine andere Version ist das Löschen, das von Rene Limon bereitgestellt wird
delete from test
where id not in (
select max(id)
from test
group by email)